本内容是对知名性能评测博主 Anton Putra Actix (Rust) vs Axum (Rust) vs Rocket (Rust): Performance Benchmark in Kubernetes 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准
在以下中,我们将比较 Rust 生态中最受欢迎的几个框架。我会将三个应用程序部署到 Kubernetes,并使用 Prometheus 和 Grafana 进行监控。
我们将测量每个应用程序的 CPU 使用率,相对于 Kubernetes 部署中设定的限制。同时,我们也会测量内存使用情况,相对于其设定的限制。当然,你也可以测量实际数值,比如应用程序使用了多少 MB 或 GB 的内存,但基于使用率百分比阈值设定告警会更加简单。
此外,我们还会测量每个应用程序可以处理的请求数量,最重要的是客户端延迟---即处理每个请求所需的时间。我们将使用 p99 百分位 进行测量(我在另一个视频里详细解释了百分位的概念)。
我们还会测量应用程序的 可用性 ,计算方式为:成功请求数 ÷ 总请求数 × 100 。最后,由于这些应用程序运行在 Kubernetes 中,我们还需要测量 CPU 限制节流(CPU Throttling)。
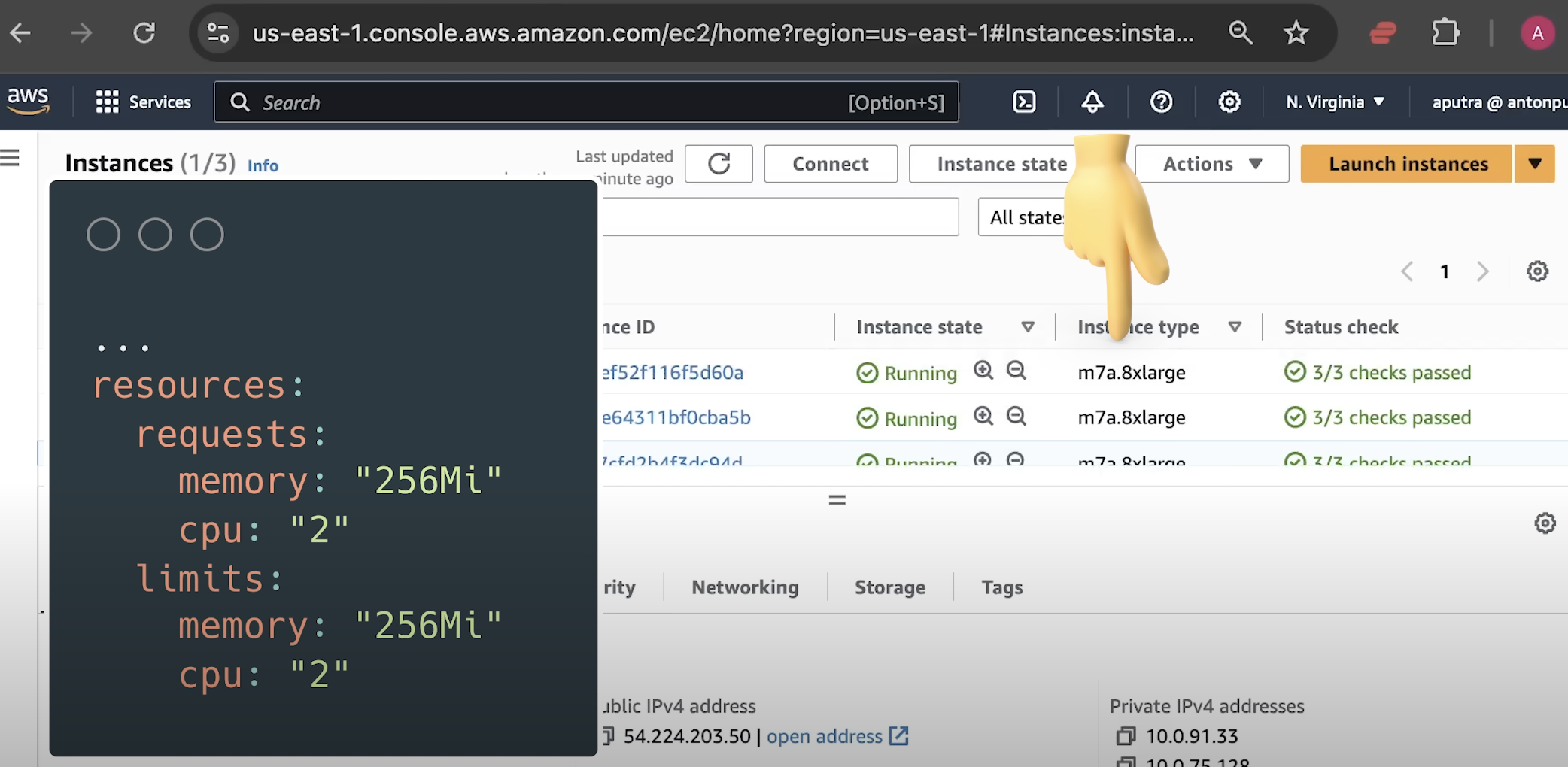
为了进行测试,我在 AWS 上创建了一个 生产级的 EKS 集群 。如果你感兴趣,我的频道里有完整的教程,教你如何搭建。我使用了最新的 m7a.8xlarge 实例,每个应用程序只获取一部分可用的 CPU 和内存,其余资源则用于其他基础设施和用于生成负载的客户端。
代码概览
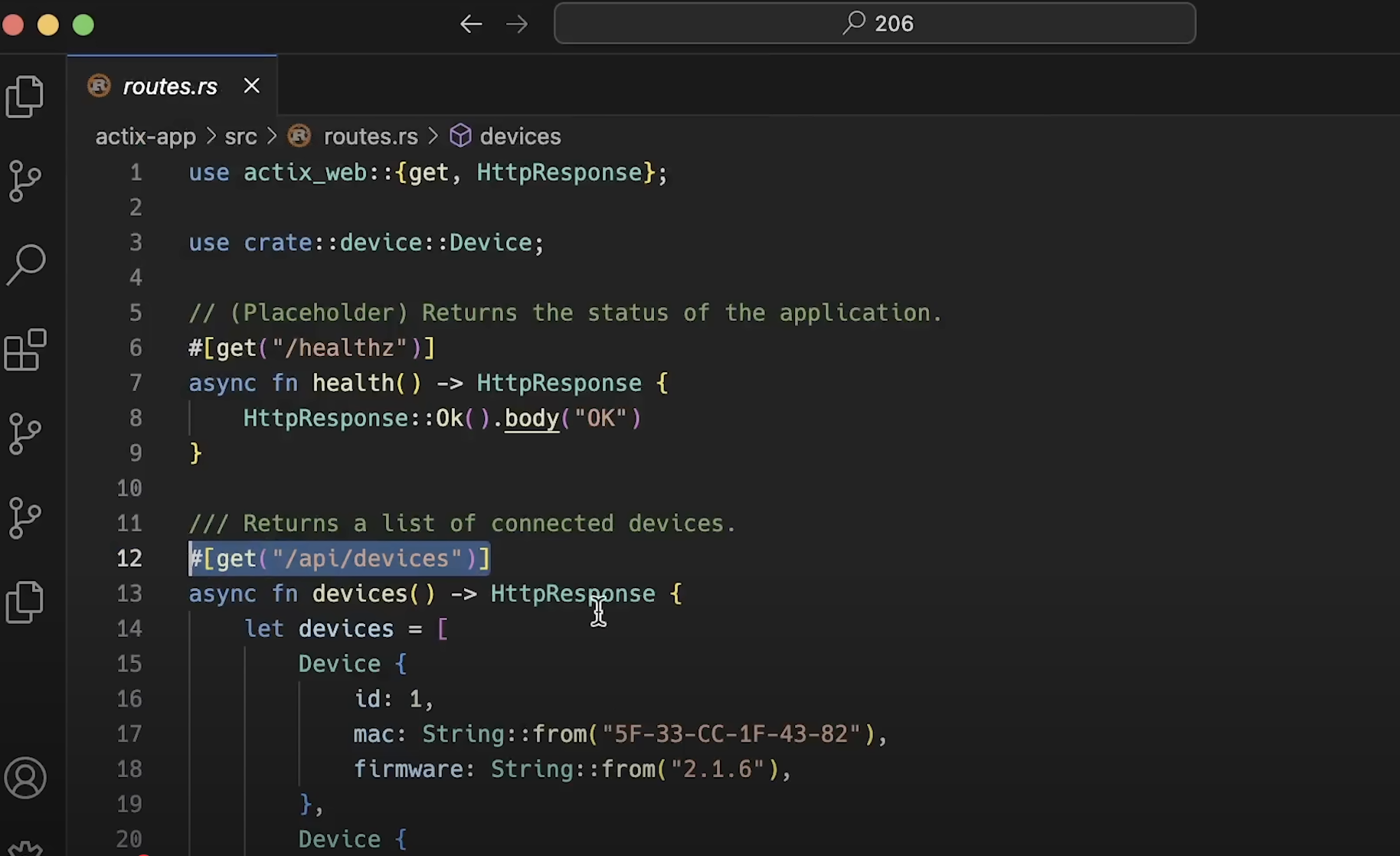
每个应用程序都包含一个 /api/devices 端点,返回 JSON 格式的数据给客户端。你可以在我的 GitHub 公开仓库 中找到源代码。如果你有任何改进建议,欢迎提供意见或提交 Pull Request!如果某些更改确实带来了影响,我会更新视频并展示新的测试结果。
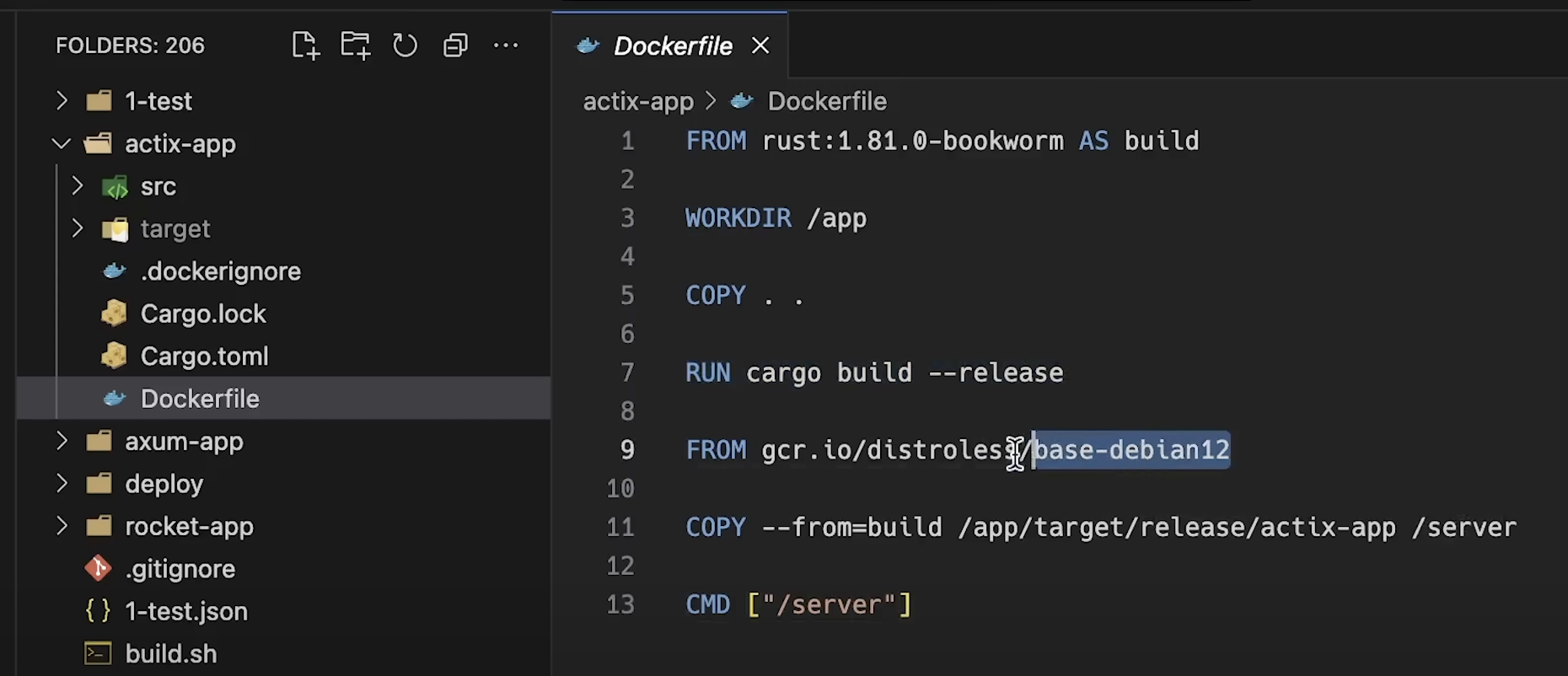
所有应用程序都使用了 Rust 的 标准优化 ,并以 release 选项构建。此外,我使用了 distroless Debian 镜像来构建 Docker 镜像。
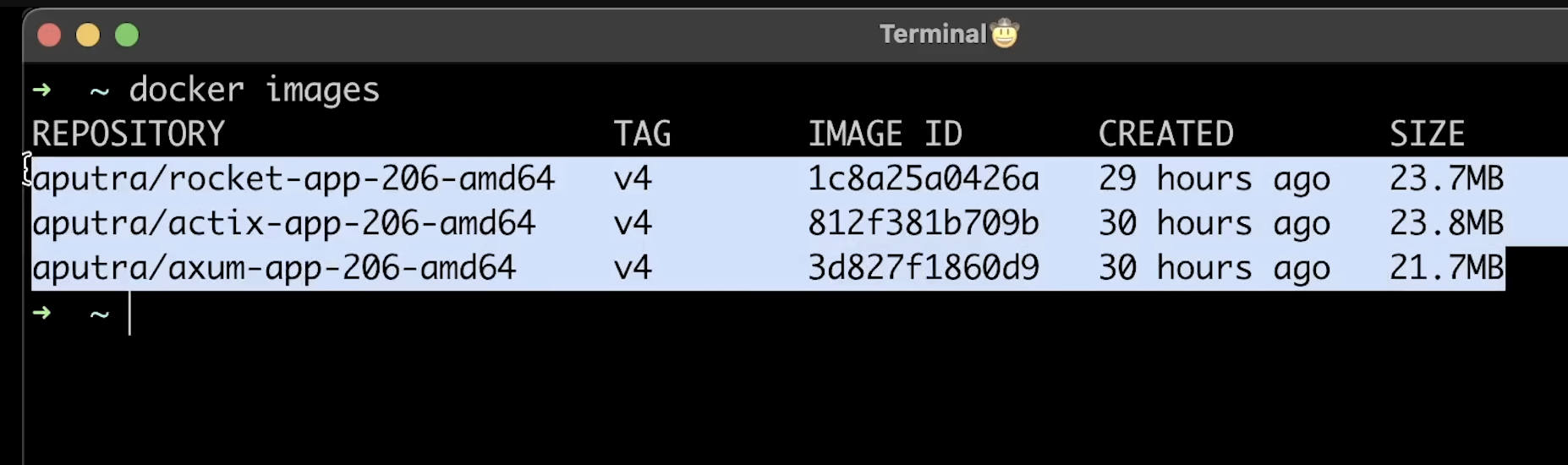
如果你感兴趣,以下是最终的镜像大小。我们可以使用 UPX 进一步压缩,就像我对 Go 语言的镜像所做的那样,使其减少到 3-4 MB。不过,在这次测试中,镜像大小并不会影响性能表现,因此不作进一步优化。
测试过程
现在,我们将所有三个应用程序部署到 Kubernetes ,并让它们在 空闲状态 下运行 15 分钟 。你会发现,各个框架的 CPU 使用率 存在一些轻微差异,但非常小,几乎可以忽略不计。另一方面,内存使用情况 也很小,但你可能会注意到不同的行为模式:

- Axum 的内存使用较为平稳;
- Actix 和 Rocket 则会出现 短暂的内存尖峰。
接下来,我们开始 测试 ,并部署 Kubernetes Jobs 来生成负载。整个测试持续了约 1.5 小时 ,但我在视频中将其缩短至几分钟。最后,我们会查看整个测试过程中的各项 监控图表。
我们将 每 3 分钟 增加 1000 个请求/秒 ,持续增加,直到这些应用程序开始 无法承受负载。
初步结果
在测试初期,负载较小,此时最重要的指标是 客户端延迟。你会发现:
- Rocket 框架 的延迟 从一开始就最高 ,并且 CPU 使用率 也高于其他框架;
- 然而,其内存使用保持稳定 ,因为 Rust 没有垃圾回收(Garbage Collection),并且测试时只返回了 硬编码的 JSON 数据,并未占用太多内存。
- Actix 和 Axum 在 CPU 和延迟方面表现相似。
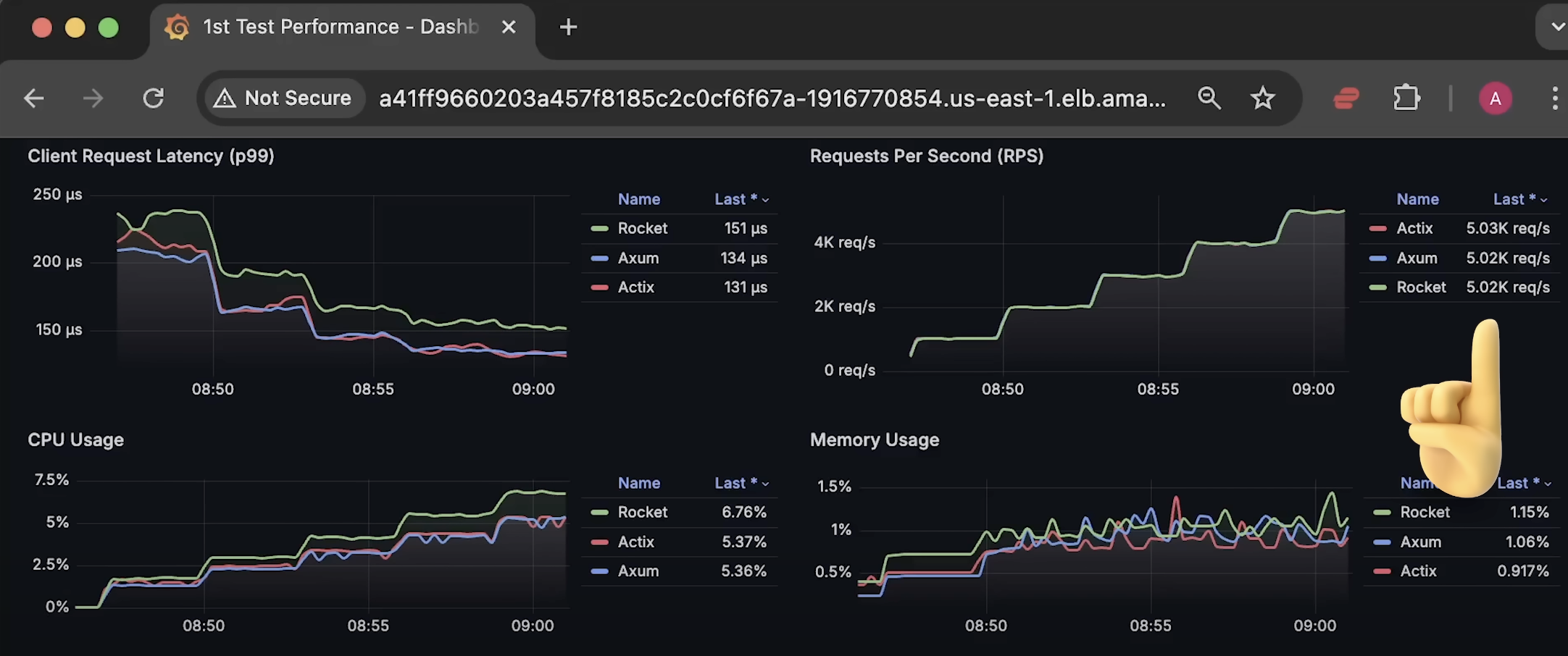
此时,测试负载仅为最大可承受负载的 20% ,因此我们可以得出结论:在低负载下,Actix 和 Axum 的性能几乎相同 。但在实际应用中,我们希望测试所有可能的场景,包括让应用程序承受 极限负载。
为了确保测试结果的稳定性,我在不同的 EC2 实例上多次运行了测试,结果始终一致。
增加负载后的结果
当负载达到 30%(仍属于轻负载)时,我们开始看到明显的区别:
- Actix 的延迟最低 ,其次是 Axum ,Rocket 依然是最慢的。
- 随着负载增加,Actix 和 Axum 之间的差距逐渐扩大 ,不仅表现在 延迟 ,还体现在 CPU 使用率 上(尽管差距较小,但可以观察到)。
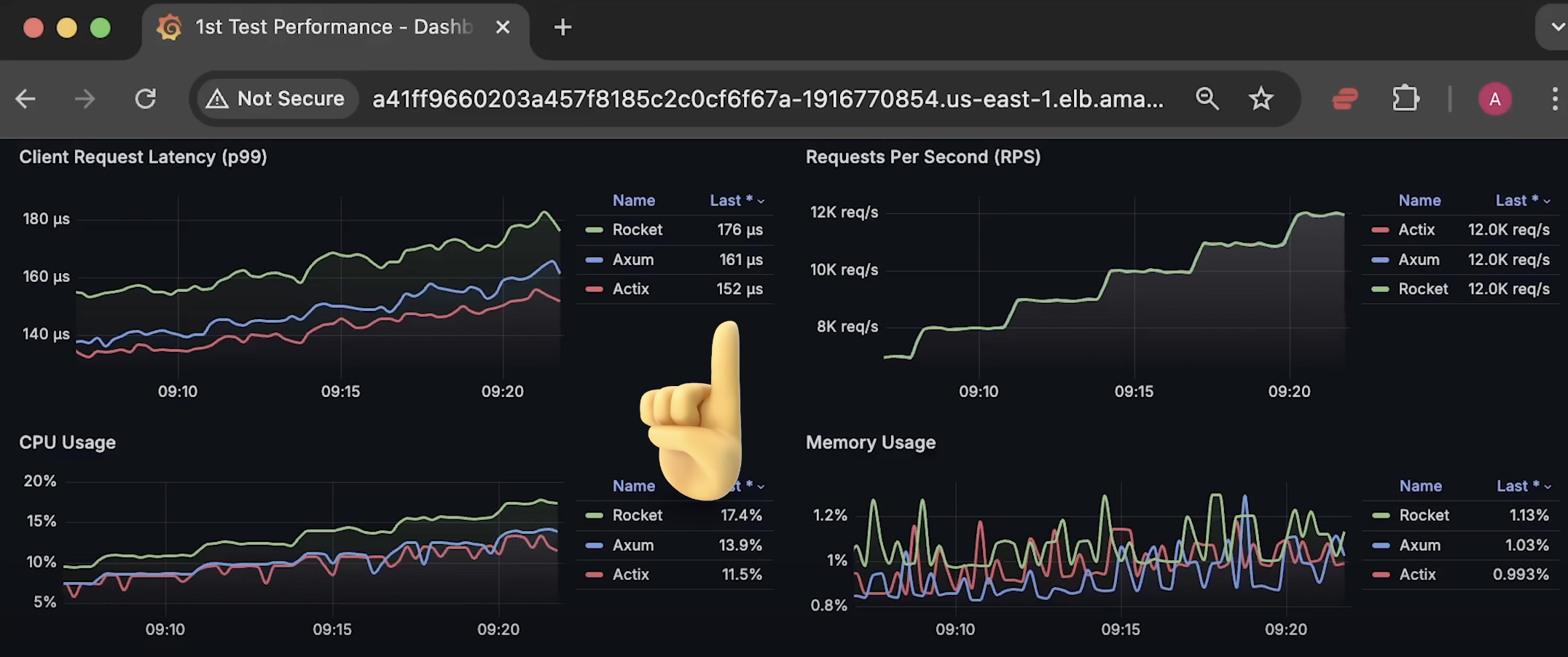
此时,平均请求处理时间仅为 100-200 微秒 (注意,不是毫秒)。我将 客户端超时时间 设为 200 毫秒 ,当请求超时时,客户端会收到 408 状态码 ,这会影响应用的 可用性。
需要注意的是,应用程序崩溃的原因并不一定是 CPU 或内存达到 100% 使用率 。应用程序可能会因 响应过慢、无法处理请求 而导致客户端超时。此外,Kubernetes 的健康检查(Readiness Probes) 也可能超时,导致应用被移出 服务池(Service Pool)。

在本次测试中,我们认为 可用性下降 并且 应用无法在 200 毫秒内处理请求 ,即视为 测试失败。
推至极限负载
在负载增加到 27,000 请求/秒 时,所有应用程序都开始 出现失败 。因此,我们可以认为 最大可承受的负载大约为 26,000 请求/秒 ,之后响应时间会 急剧恶化,应用将被移出服务池。
尽管三者的 延迟表现不同 ,但它们 几乎在同一时间开始崩溃。不过,在整个过程中:
- Actix 的延迟始终是最低的。

数据分析
接下来,我们查看各项图表:
- 每秒请求数(Requests Per Second)
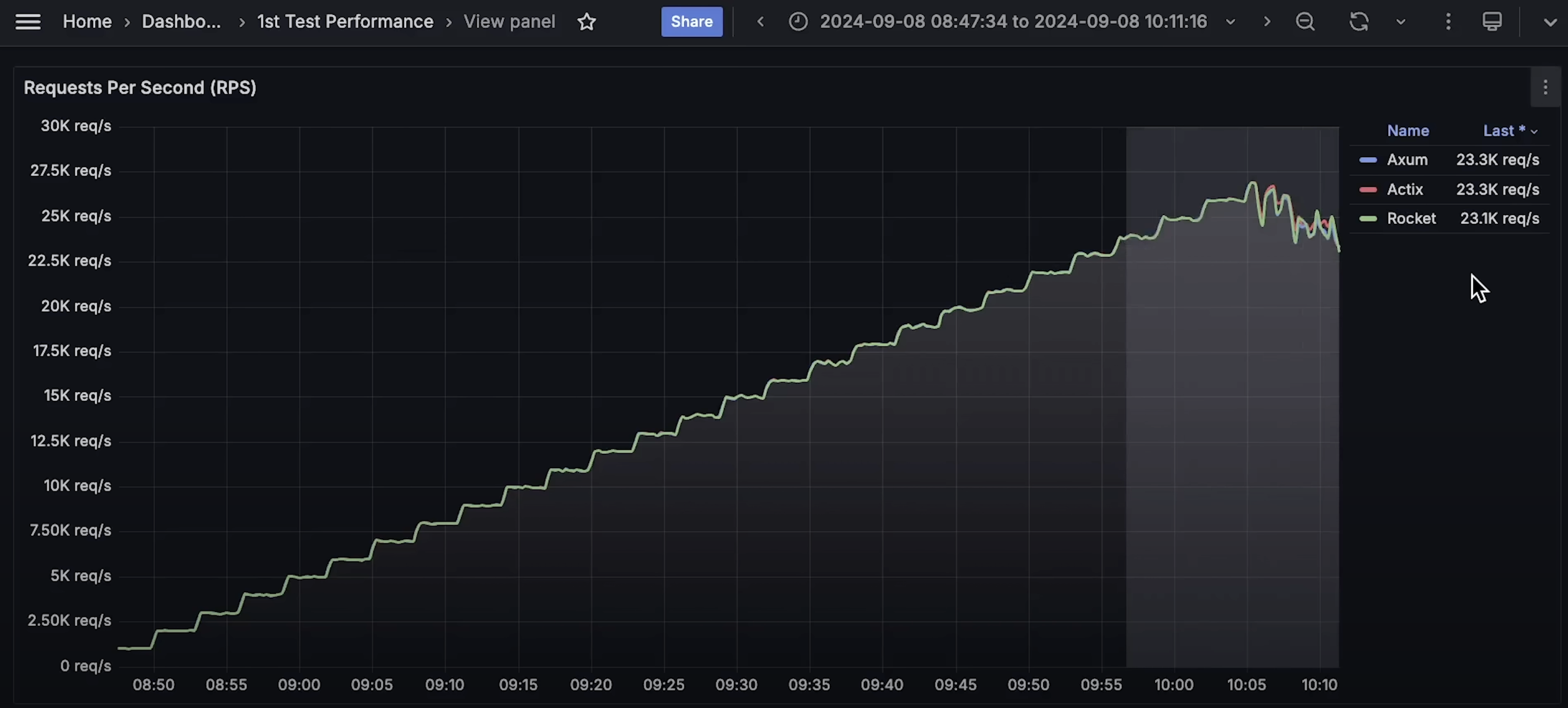
- 内存使用情况(Memory Usage)
- 当应用开始变慢,需要存储更多 待处理请求 时,内存使用出现尖峰。

- CPU 使用率(CPU Usage)
- Rocket 使用的 CPU 最高 ,Actix 的 CPU 使用率最低。

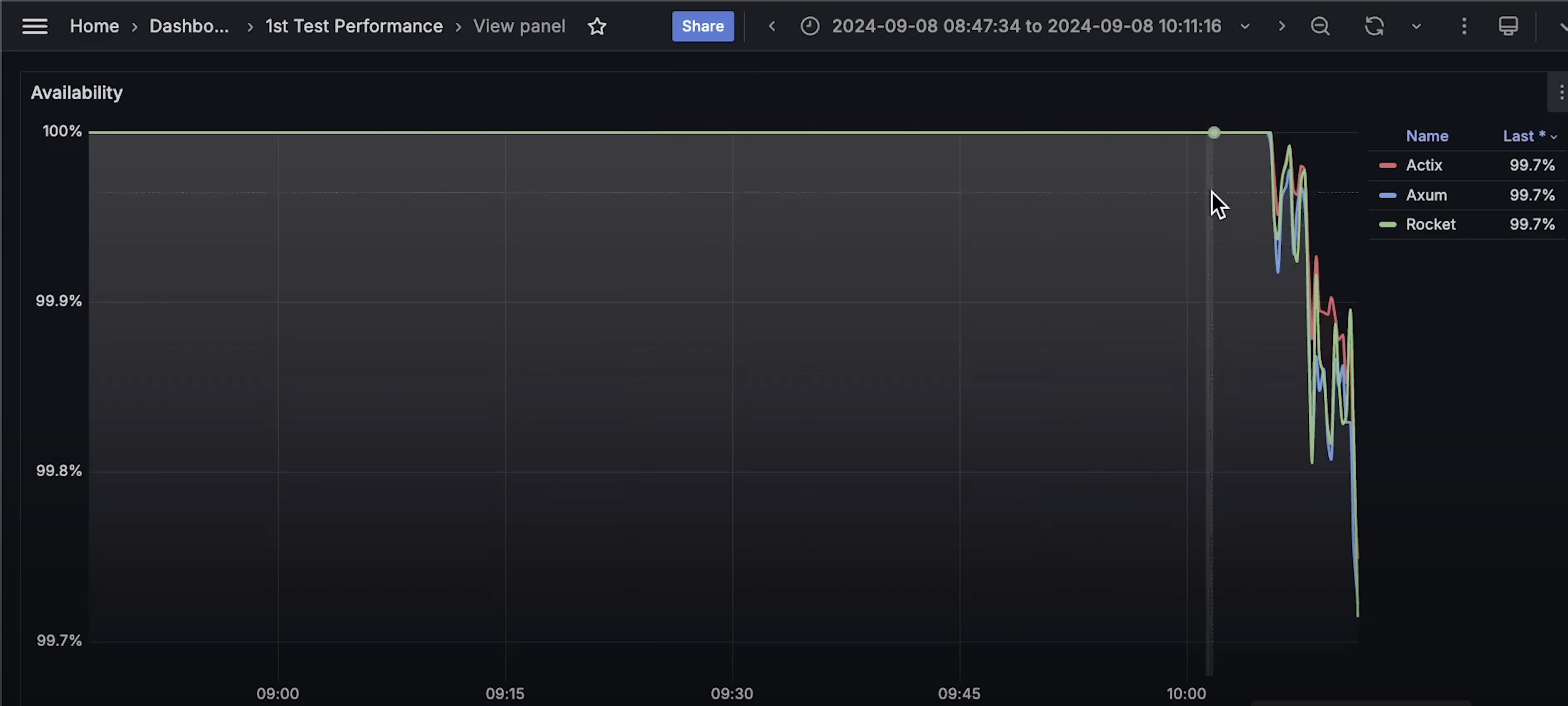
- 可用性(Availability)
- 虽然所有应用几乎在同一时间开始失败,但 Actix 的可用性更高 ,即:它在 更低的延迟下处理了更多请求。
- 下次测试时,我会 减少负载递增的幅度,看看哪一个框架能处理更多请求。
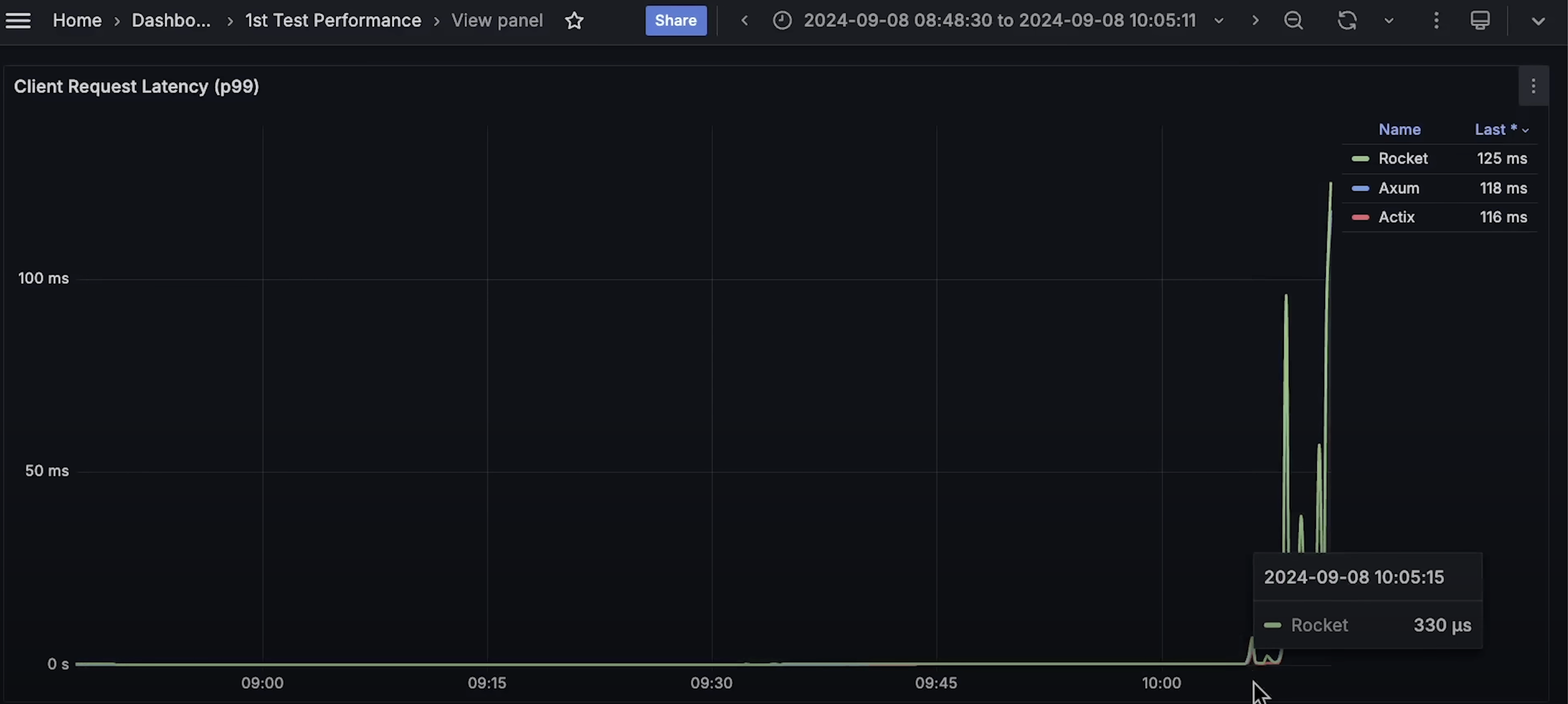
- 客户端延迟(Client Latency)
- 在测试后期,我们看到了一些延迟 尖峰,但它们并不是最重要的部分。
- 在应用程序仍然健康的阶段,Actix 的延迟最低,并且是最后一个失败的框架。

-
CPU 限制节流(CPU Throttling)
- 没有任何应用程序达到 100% CPU 使用率 ,因此没有发生 CPU 限制节流。