摘要:本文投稿自货拉拉国际化技术部 资深数据仓库工程师林海亮老师。内容分为以下几个部分:
1、业务简介
2、Flink 在业务中的应用与挑战
3、实时数仓架构的 Flink 驱动演进
4、未来展望
一、业务简介

Lalamove 于2013年在香港成立,是货拉拉的海外业务品牌,作为全天候即时送货平台,致力透过快速、灵活、经济的送货服务为社区注入动力。不论是个人客户、中小企和大型企业,经 Lalamove 手机应用程式即可与专业司机伙伴配对,提供各类车款选择。Lalamove 致力运用科技优势,紧密连系用户、司机伙伴、货物及道路,现时 Lalamove 的业务已覆盖亚洲、拉丁美洲以及欧洲、中东、非洲地区(EMEA)共13个市场,以科技物流满足各地社区的物流需求,为当地带来正面影响。
二、Flink 在业务中的应用与挑战
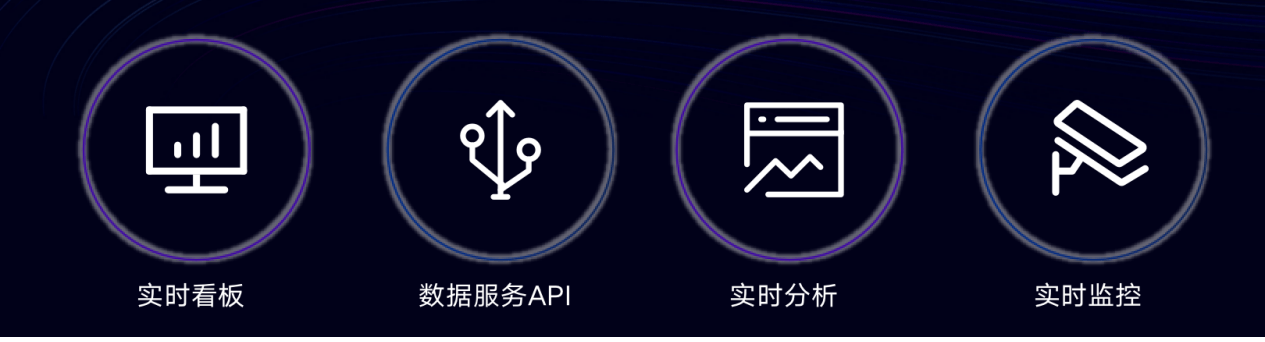
2.1 实时链路在Lalamove的应用
-
实时看板:为管理层和运营团队提供了全面且细致的核心指标实时展示。从全球各地区的不同价格品类,到最细化的车型维度,都能进行多维度组合展示。同时,还具备对部分核心指标的单独诊断功能,助力管理层迅速掌握业务动态,做出精准决策。
-
数据服务API:依托大数据自建的数据云平台,Flink 实时计算能力为订单服务和营销活动提供了强有力的支持。在订单下单过程中,根据司机、用户、片区供需等实时数据,Flink 能够快速计算并调整订单附加费用。目前,该功能已涵盖动态附加费、实时派券和实时订单风控等多个方面,显著提升了业务的灵活性和智能化水平。
-
数据监控:在实时数仓的业务核心指标层,通过上报至自研告警平台 LL-Monitor,实现了对业务指标的实时监控。这不仅为业务运营提供了及时的数据支持,还能有效监控实时数仓的数据质量,确保数据的准确性和可靠性。
-
数据分析:Flink 实时加工处理后的数据,借助 Doris 等 OLAP 引擎,极大地提升了数据查询速度。业务团队能够使用新鲜度更高的数据进行深入分析,及时发现业务中的潜在问题和机会,为业务优化提供了有力依据。
2.2 业务扩张带来的技术挑战
实时能力所面向的场景基本就是上面提及的4个部分,难点在于随着业务的发展数据量越来越大,上游所涉及的流数据也日趋增多,如何在数据新鲜度、成本和性能间作好权衡则是实时数仓的搭建需要综合考虑的要点,并且区别于国内业务,海外业务的数据建设面临的挑战也存在差异。

- 多个数据中心:与传统跨境电商业务不同,O2O 业务需要在各个市场配备运营团队,并遵循当地法律法规对数据进行监管。因此,Lalamove 在海外设立了东南亚、南美多个数据中心,并在多云服务上混合部署。这导致了数据隔离、延迟和一致性等问题,给 Flink 实时数仓的搭建和运行带来了巨大挑战。
- 多个时区数据:业务横跨 8 个时区,为了更好地服务当地团队,数据需要按照当地时间进行处理。而 Flink 的事件时间在实时数仓构建中起着关键作用,如何在数据模型设计中兼顾成本和复杂度,成为了一大难题。
- 上游改造频繁:近 4 年来,随着业务的迅猛发展,流数据上游订单系统经历了 3 次重大版本迭代。从最初的单一宽表,到 1.0 版本拆分为订单、运单、属性 3 张业务事实表,再到 2.0 版本进一步扩展至 20 多张事实表,且各表面向不同业务场景没有单一主表。在实时链路已对接多个业务需求的情况下,如何实现上游数据的兼容,对数据模型提出了严峻考验。
- 建设成本高企:相较于国内云厂商,海外云服务的单机成本要高出 N 倍,且数据跨 DC、跨云传输的流量费用也十分高昂。这就要求在实时数仓建设过程中,必须在使用成本、数据新鲜度和机器性能之间进行更为谨慎的权衡。
三、实时数仓架构的 Flink 驱动演进
围绕着这4个挑战,Lalamove 在 Flink 的基础上以更拥抱变化的态度不断迭代实时数仓的构建,新版本的特性、新技术的融入可以帮忙 Lalamove 更好的应对这些挑战。
-
数据中心问题上,在 Paimon 表进行湖仓的构建,通过 sequence 等机制确保了每条流数据本身的数据顺序,避免了跨DC数据传输数据延迟后导致的数据乱序问题。
-
时区问题上,在数据模型设计基于事件时间 event time 来构建DM层,既应用上了 Flink 的 TVFs 功能,也避免了不同时区数据量差异导致的数据倾斜问题。
-
上游改造问题上,通过搭建了 Paimon 湖仓来提高实时数据模型的兼容性,不管上游如何的变动,Paimon 上构建的 DWD 层提高了模型的兼容度,只需基于 PK Table 的主键进行列级更新即可。
-
成本问题上,由于对价格的敏感度相对国内业务线更高,从2022年升级到 Flink1.13 使用 TVFs 特性,2023年引入 Flink1.18 构建 K8S 云原生实现动态扩缩容,2024在对象存储搭建 Paimon 都有效减少了成本。
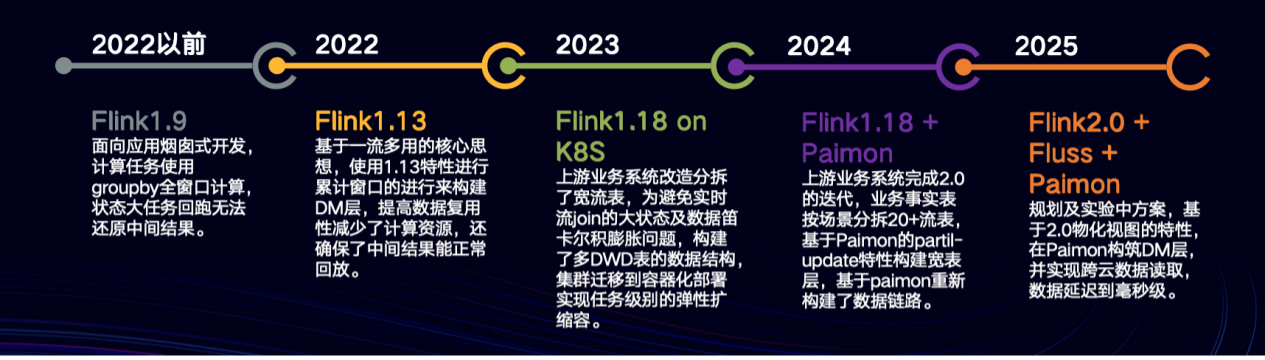
3.1 数仓分层架构演进
(1)2022 年前:采用 Flink1.9 版本,开发模式为面向应用的烟囱式,无分层设计。上游业务系统由单一宽表构成,下游通过消费单一流表进行核心指标开发。这种模式下,单个数据流被多次消费和重复计算,采用 groupby 全窗口计算方式,导致单个任务状态过大,需要大量计算资源。同时,由于实时看板需要进行可选日期相同时点环比,需保存大量历史数据的中间窗口数据,一旦数据出错,只能通过离线数据进行 T - 1 天的修复,资源维护成本较高。
(2)2022 年:基于一流多用的理念,搭建了从 ODS - DWD - DM 的实时数仓分层架构。ODS 层由业务数据 binlog、埋点数据以及后端数据统一输出到 kafka 构建;DWD 层则进行数据的ETL处理;DM 层运用 Flink 的 TVFs 窗口计算新特性,以面向时区的方式进行计算,大幅减少了计算资源的消耗。同时,采用累计窗口回跑中间结果的数据修复模式,提高了数据修复的效率。此外,这种面向时区的分拆计算模式还从数据结构上有效解决了不同时区市场数据量差异大带来的数据倾斜问题。
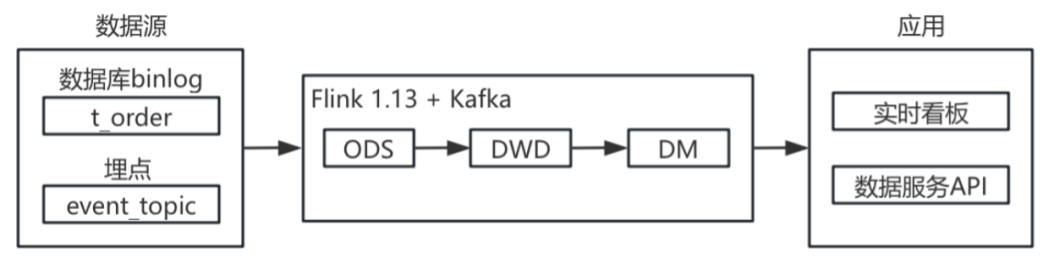
(3)2023 年:上游业务系统升级,从单一订单宽表改造为 3 张事实表。为避免实时流关联带来的资源消耗和数据重复问题设计了多 DWD 表结构,以满足不同维度指标的计算需求,包含了订单用户、订单司机、订单账单、订单需求多张业务宽表,以及埋点用户、埋点司机等埋点宽表。并随着业务量增长,埋点数据大幅增加且具有明显的高峰低谷特性,Lalamove 将集群升级到 Flink1.18,并部署为 Flink on K8S,建立了任务级自动扩缩容规则,确保埋点数据计算不会长时间占用大量集群资源。
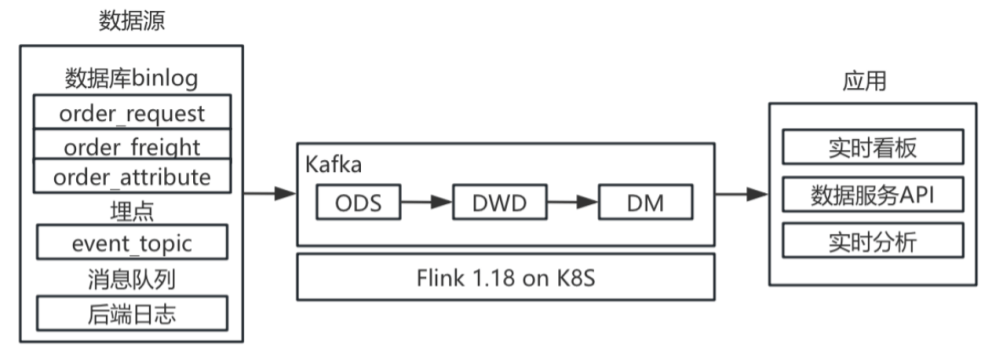
(4)2024 年:面临着上游业务订单、账单以及结算几个大业务系统的改造,其中订单业务将从 3 张订单实时表扩展为 20 多张业务事实表,各表更新时间不一致,后端状态保留时间难以预估;账单及结算同样基于业务做不同场景的事实表分拆。在此背景下,引入 Paimon 引擎。Paimon 既能作为 sink 目标组件,又能作为 source 消费其 change - log,其 partial - update 特性与新业务系统高度兼容。ODS 层依旧从canal直接输出到 kafka 不做任何处理,DWD 层在 Paimon 构建订单与埋点主题宽表,在 Flink 任务中按字段级别进行更新,并基于 sequence 机制保证数据顺序,在 Flink 任务中对数据进行 ETL 处理,实现数据的清洗、转换和整合。DWB 层关联 DIM 构建最终的大宽表。DM 层保持按时区基于事件时间进行处理,数据在 Paimon 做存储,Kafka 进下分发,特定场景也会存储在 OLAP 提供即席查询。
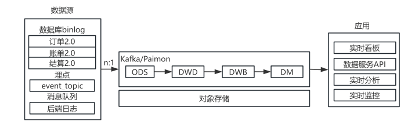
3.2 数仓架构现状
- 数据模型:实时侧数据模型与实时引擎技术紧密相关,基于不同版本的 Flink 和 Paimon 湖仓,数仓模型的构建方式也有所不同,因此也可以说相对离线在实时领域的数据模型相对并不"稳定"。目前,PRD 环境是基于 Flink1.18 + Paimon1.0 进行搭建。另外需要强调的是,在上下游协同方面,下游实时开发能积极参与上游业务系统改造,对上游在改造时提出合理的字段冗余诉求能够减少实时链路中的流关联,使数据模型更加轻量高效。
- 数据处理:统一基于自研平台 "飞流" 进行统一开发,自研的 SQL 解析引擎使得 90% 的任务为 FlinkSQL 任务,大大降低了任务的维护和开发难度,提高了开发效率。
- 数据监控:利用基于 Prometheus 研发的监控平台 LL-Monitor,对从 ODS 到 DM 层的 Flink 任务 metrics 以及业务指标进行实时上报和监控。通过预设的监控规则,能够及时发现任务和数据质量问题,保障系统稳定运行。
- 数据存储:Paimon 使用对象存储,数据应用方面则使用多种存储模式以应对不同的业务场景,基于 OLAP 进行查询加速、使用 KV 数据库支持接口毫秒级响应,使用 Kafka 方便多端分发。另外,跨云间的数据传输也使用了特定的算法对数据进行处理,使得存储成本及数据流量费用都尽可能最优。
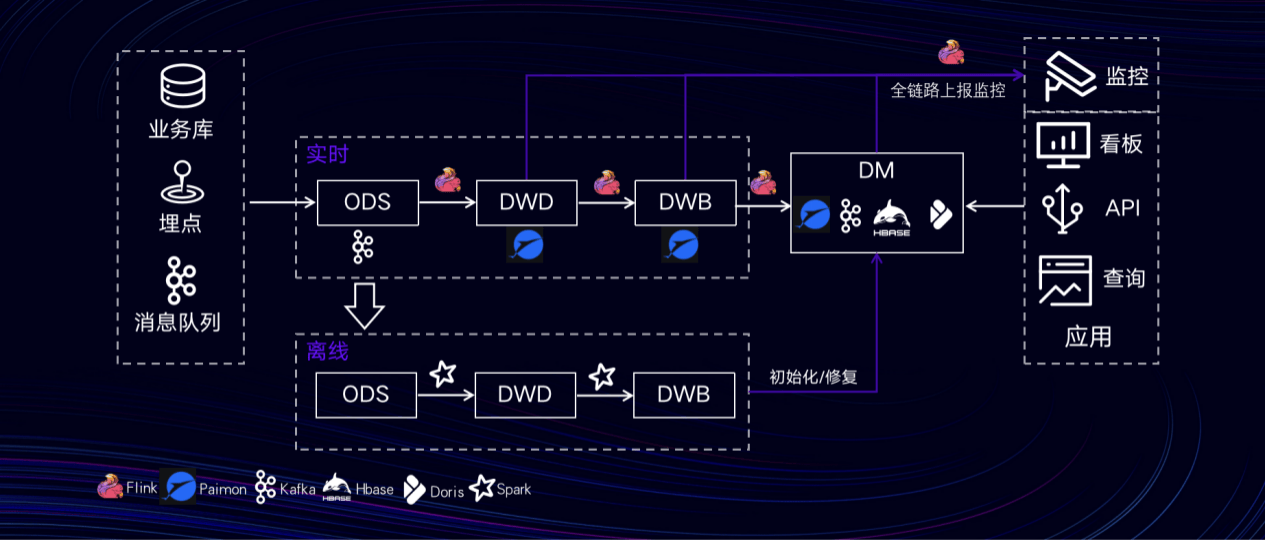
Lalamove现有实时湖仓架构
3.3 湖仓构建收益
-
驱动业务决策,通过在 Paimon 上核心指标流批一体的路线的演进,可以支持离线数仓现在可以通过跨云读取 Paimon 数据生成的核心报表,实现了离线与实时相同口径相同数据源的核心指标构建,效率上也支持基于实时数据小时/分钟级别去更新核心报表。
-
技术实现提效,基于 Paimon 进行湖仓构建后,让实时数仓的兼容性从以前的上游改造下游则同步改造,调整为上游改造 DWD 层进行兼容即可,DM 层不再受改造带来数据风险以及双写资源浪费,并有效的减少了开发人员的人力投入。未来上游业务系统还将迎来账单2.0改造,评估后预期未来一年只需轻量开发即可轻松兼容。
-
资源达成降本,从基于 kafka 构建的多 DWD 表实时链路切换到 Paimon 湖仓后,在业务从 5 个时区扩展到 8 个时区市场的情况下,按现有数据量预期 Paimon 链路所使用的计算资源相比基于 Kafka 链路开发方式仍然有了大幅下降。
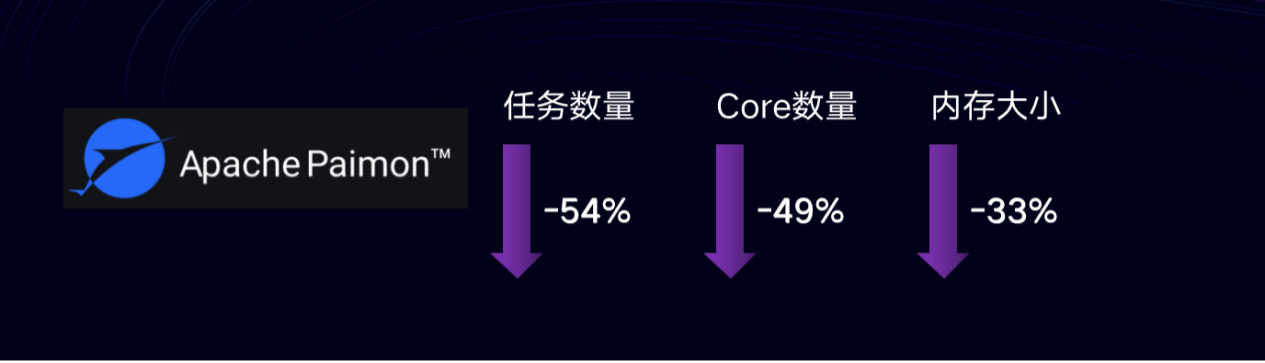
Paimon链路相对Kafka链路Flink计算资源预期对比
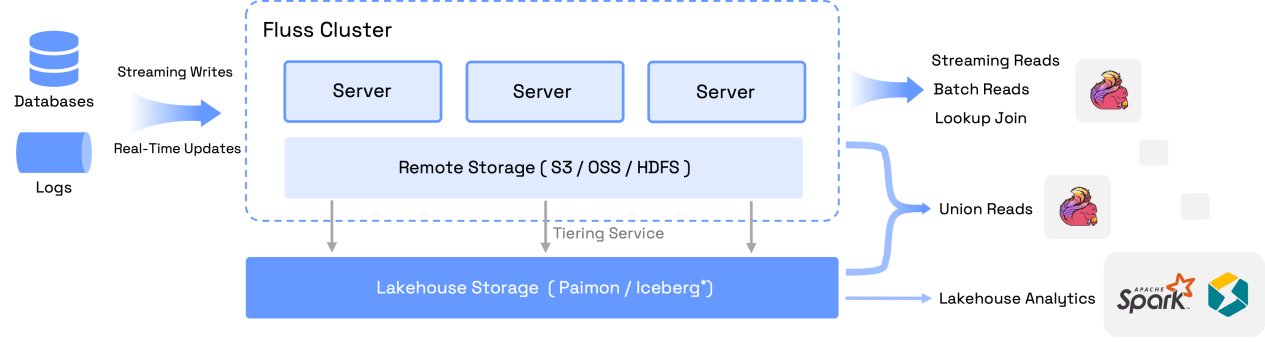
四、未来展望
尽管基于 Paimon 构建的链路在当前取得了显著成效,但仍存在一些局限性。Paimon 表文件合并会带来数据秒级延迟问题,同时维护 Kafka 及 OLAP 第三方组件也需要一定开销。为了进一步优化实时数仓架构,Lalamove 已经不断在尝试基于各种技术栈来加强湖流融合,目前社区生态中的 Fluss 所提供的能力恰好能解决现有架构所面临的痛点,下一步的实时数仓构建也会在 Fluss+Paimon 基础上不断地演进。
-
支持基于对象存储的 Paimon,兼容了现有的技术架构。
-
具备 CDC 订阅、数据层毫秒级延迟的特性,解决现在 Paimon 表秒级延迟问题。
-
支持实时数据点查提供了流分析能力,能一定程度上减少现有 OLAP 引擎的压力与依赖。