我们学习编程语言的时候,第一个程序就是打印一下 "hello world" ,对于大数据领域的第一个任务则是wordcount。那我们就开始我们的第一个spark任务吧!
下载spark
官方下载地址:Apache Download Mirrors 下载完毕以后,直接tar解压即可。
本地启动spark集群
环境只是为了让我们能够运行我们的程序,所以我们的任务是写任务而不是搭建环境。搭建环境的部分,可能运维比我们更专业。
安装官网我们启动一个standalon模式 ,Spark Standalone Mode - Spark 4.0.0 Documentation。
启动完以后master我们就可以在8080端口上看到我们的spark集群了。
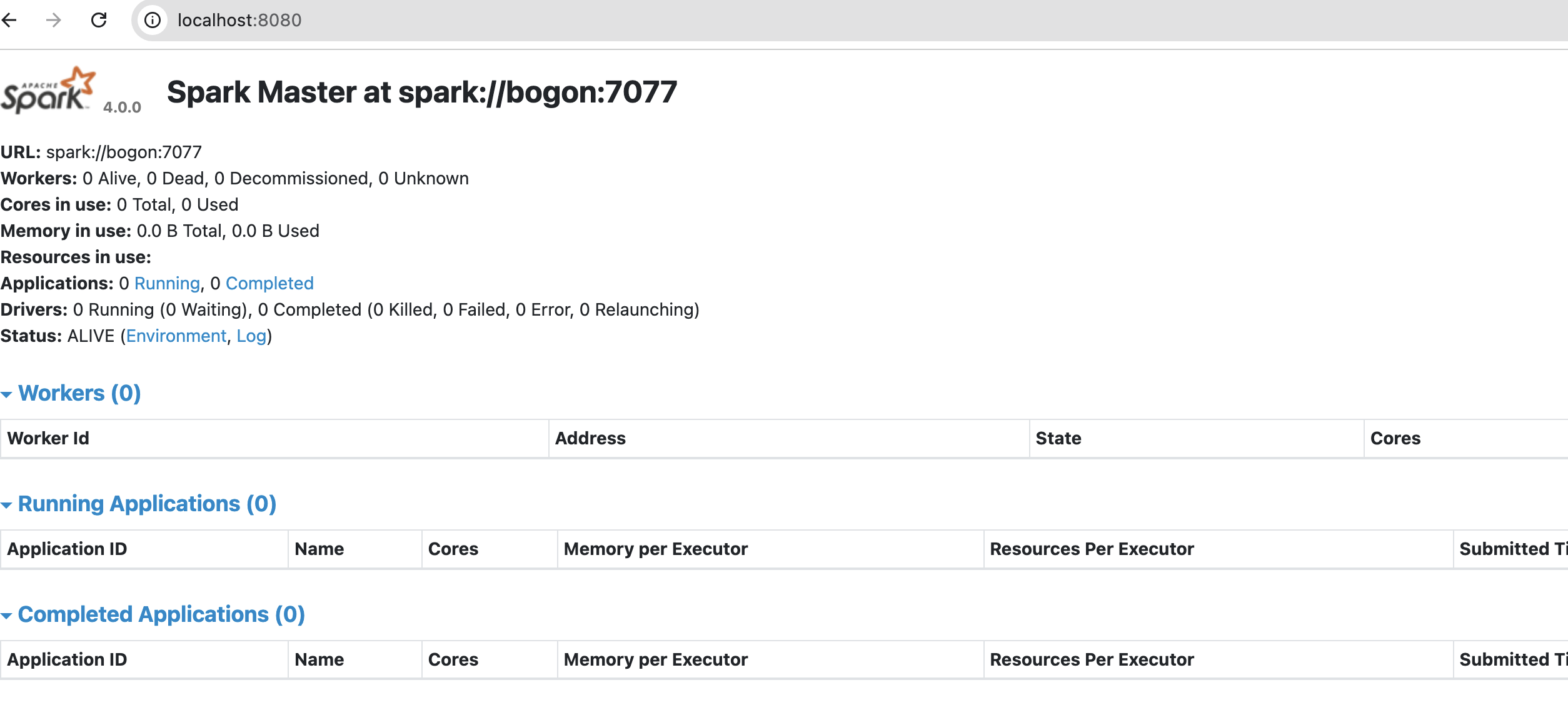
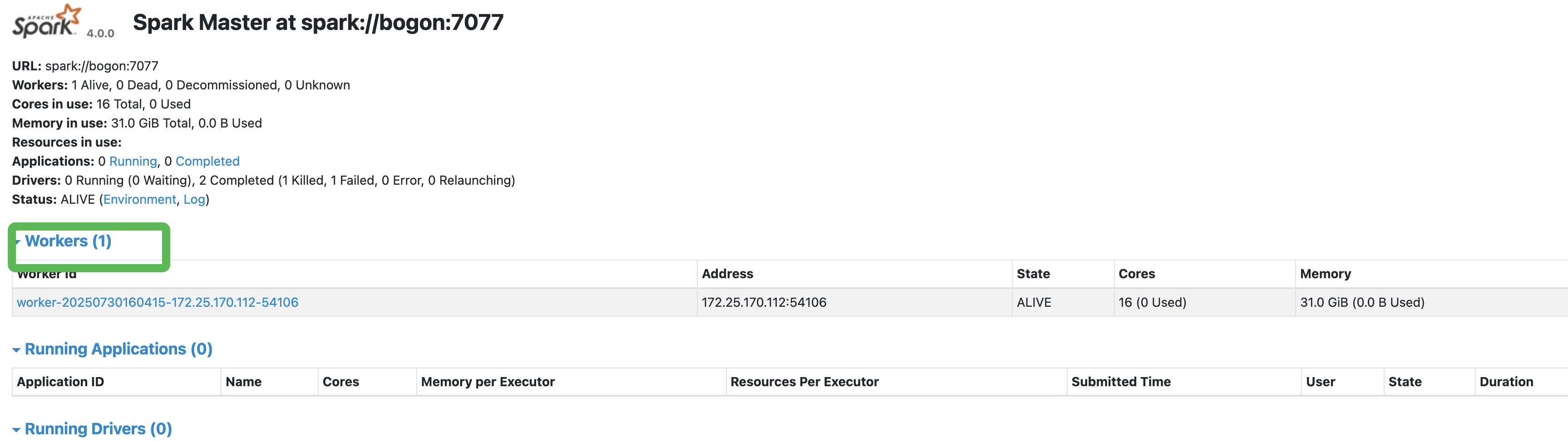
接着启动一个worker,启动的时候需要master的地址。我们本地启动的,所以localhost就可以了。./sbin/start-worker.sh spark://bogon:7077 ,master的url可以从master 8080的界面看到,这个记得一定要写正确,要不启动worker的时候就有问题了。否则这个worker节点不现实worker个数的。
构建我们的jar程序
我们直接参考官网的代码(注意:这是学习的方式方法,看到别人博客直接写的入门代码。其实官方是第一手资料)Spark Streaming - Spark 4.0.0 Documentation
代码
Scala
def main(args: Array[String]): Unit = {
println("======== start ==========")
val conf = new SparkConf().setAppName("test")
val ssc = new StreamingContext(conf, Seconds(1))
val source = ssc.socketTextStream("localhost", 9999)
val words = source.flatMap(_.split(","))
val paris = words.map(word => (word, 1))
val wordCounts = paris.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}编译打包jar,然后提交submit
bash
./bin/spark-submit \
--class demo.WordCount \
--executor-memory 512M \
--total-executor-cores 2 \
--master spark://localhost:7077 \
--deploy-mode client \
--verbose \
/path/spark-task-1.0-SNAPSHOT.jar Submitting Applications - Spark 4.0.0 Documentation
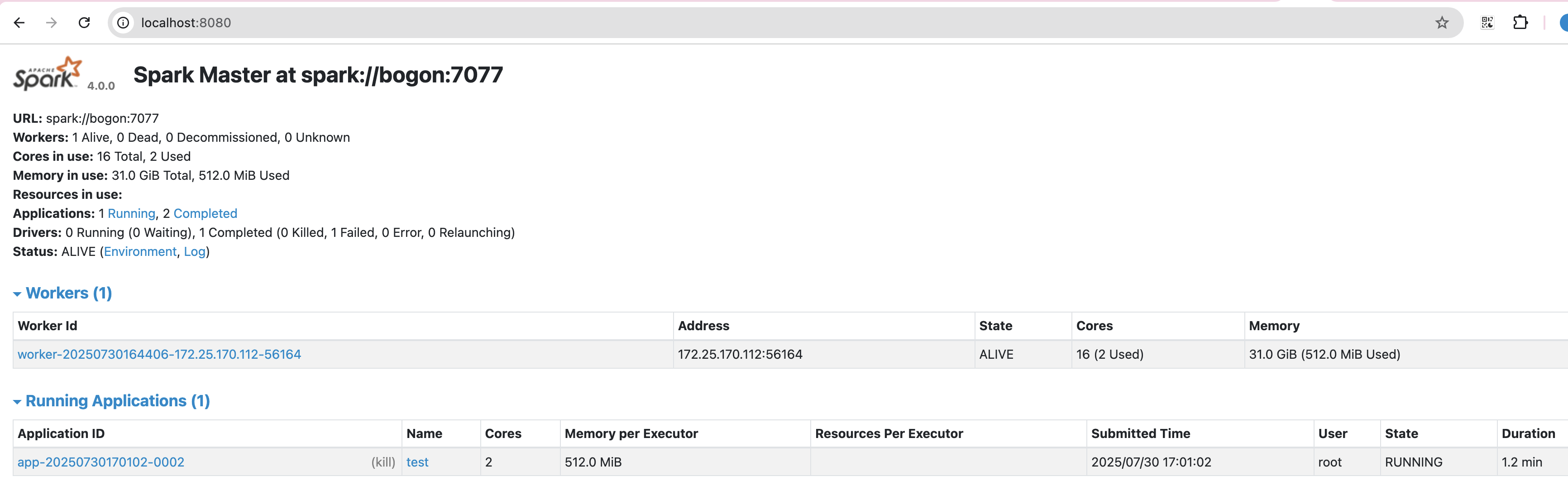
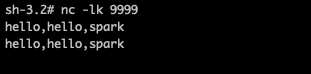
查看日志打印

总结
小结一下,其实看似很简单的一个demo。过程也是遇到了很多的问题,1、是启动 worker的时候需要制定master的url地址,这个需要从8080端口查看。2、发现自己的代码无法提交到集群中,结果发现是代码里面setMaster了,所以去掉。3、打包的时候提示找不到class,因为是maven构建的java程序。自己添加的scala包,所以需要打包的时候指定一下scala路径,把下面的class打包进去。
多实践才能发现问题,有时候只是知道了理论,看似懂了,其实离懂了还是差了一些。