作者:来自 Elastic Eduard Martin
想获得 Elastic 认证?了解下一期 Elasticsearch Engineer 培训的时间!
Elasticsearch 拥有丰富的新功能,帮助你为你的使用场景构建最佳搜索解决方案。深入查看我们的示例笔记本以了解更多信息,开始免费云试用,或者立即在本地机器上尝试 Elastic。
UBI(User Behavioral Insights,用户行为洞察)是一个新兴标准,旨在帮助搜索工程师从前端到搜索引擎完整地捕获和追踪搜索应用的使用事件。本文将探讨 UBI 标准,并解释如何使用 Elasticsearch 插件捕获分析数据。
 Source: User Behavior Insights
Source: User Behavior Insights
UBI 详解
UBI 可以用来了解用户在应用上的行为,并提供关于用户在搜索什么、用户在站点的哪些位置进行交互(搜索栏、搜索结果、加入购物车按钮等)、用户点击了哪些结果、当时该查询返回了哪些结果,以及其他任何你认为有助于优化搜索体验的元数据的信息。
最常用的指标包括:
- 热门搜索查询:被搜索最多的内容
- 无结果查询:返回无结果的查询
- 最高点击:被点击次数最多的结果
UBI 的一些常见用途包括:
- 可视化:使用分析数据创建仪表盘,以做出战略决策
- 相关性调优 :根据无结果查询应用查询规则或同义词,或调整查询
- LTR :使用 UBI 创建 判断列表(judgment lists) 来训练 LTR 模型,并根据点击/浏览或其他业务需求提升结果
UBI 在 GitHub 上维护,采用 Apache 2.0 许可证。
UBI 模式
UBI 提出了用于查询(quries) 的 schema(在用户发起搜索时触发),以及用于**事件(events)**的 schema(在该次搜索上下文中的其他交互行为触发)。
例如,如果用户搜索 "shoe",就会捕获一个查询类型的文档。随后,当用户点击某个结果时,会创建一个事件类型的文档,并与之前的查询类型文档关联。
查询模式 - Query schema
查询模式用于存储搜索文本和展示给用户的结果。它包含以下字段:
- application
- query_id
- client_id
- user_query(必填)
- query_attributes
- object_id_field
- timestamp
- query_response_id
- query_response_hit_ids
一个好的起点是存储 user_query、timestamp、query_id,这能告诉你查询执行的时间,以及可用于关联搜索事件的 ID。
关于这些属性的更多详情,请查看最新的 schema。
事件模式
事件模式用于捕获所有搜索后的用户行为,例如点击和购买。它包含以下字段:
- application
- action_name(必填)
- query_id
- session_id
- client_id
- user_id
- timestamp(必填)
- message_type
- message
- user_query
- event_attributes
你可以在此处找到每个字段的定义。
在 Elasticsearch 中使用 UBI
由于 UBI 是一个标准,而不是工具或库,我们只需要两个组件就可以在 Elasticsearch 中实现它:
- 应用:我们需要从应用中生成符合 UBI 标准的使用事件
- 索引:我们需要 Elasticsearch 索引来存储这些数据,之后可以用 Kibana 可视化这些事件
UBI 团队创建了一个 Elasticsearch 插件,它会根据集群接收到的 _search 请求自动创建索引并存储查询。我们将使用这种方式。或者,你也可以自行构建事件收集器,并使用正确的 schema 将事件发送到 Elasticsearch。
为了开始捕获 UBI 事件,我们将进行以下步骤:
- 安装用于 UBI 的 Elasticsearch 插件
- 加载示例数据
- 测试插件
后续文章将介绍可视化部分,敬请关注!
安装用于 UBI 的 Elasticsearch 插件
Elasticsearch 的 User Behavior Insights(UBI)插件旨在捕获搜索查询,以更好地了解用户行为。该插件专注于捕获服务端的查询,而 o19s/ubi 仓库则用于客户端事件的捕获。
插件的工作方式是在搜索请求体中接受一个额外的 ext 参数,从而发送一个 UBI 事件。在搜索时,它会在内部创建一个文档,记录执行的查询以及你放在 ext.ubi 中的 schema 字段。你可以使用 query_id 字段来关联同一次搜索中的不同事件。
编译插件
首先克隆仓库:
git clone https://github.com/o19s/user-behavior-insights-elasticsearch.git使用插件构建 jar 包:
./gradlew build
该 bundle 会在 /build/distributions 文件夹下创建,是一个 zip 文件,例如 elasticsearch-ubi-1.0.0-SNAPSHOT.zip。请保存该文件以便后续使用。
安装插件
我们将在 Elastic Cloud 实例上安装该插件。对于自管理部署,你可以按照文档中的步骤操作。
1)登录 Elastic Cloud,然后进入 Extensions:
2)点击 "Upload extension",选择 elasticsearch-ubi-1.0.0-SNAPSHOT.zip 文件,并填写相关信息。撰写本文时,插件所对应的 Elasticsearch 版本是 8.15.2,因此你必须使用该版本,或者为其他版本重新编译。你可以通过查看 gradle.properties 文件,确认插件最新代码所使用的 Elasticsearch 版本。
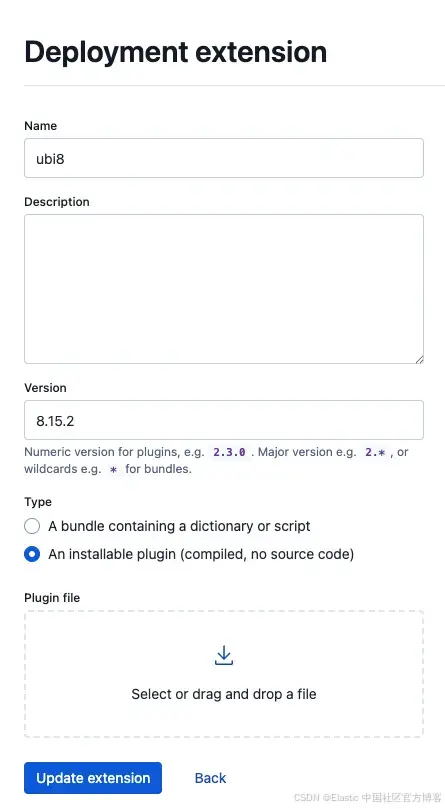
3)成功上传扩展后,点击 Elastic 标志进入 Elastic Cloud 主页面。
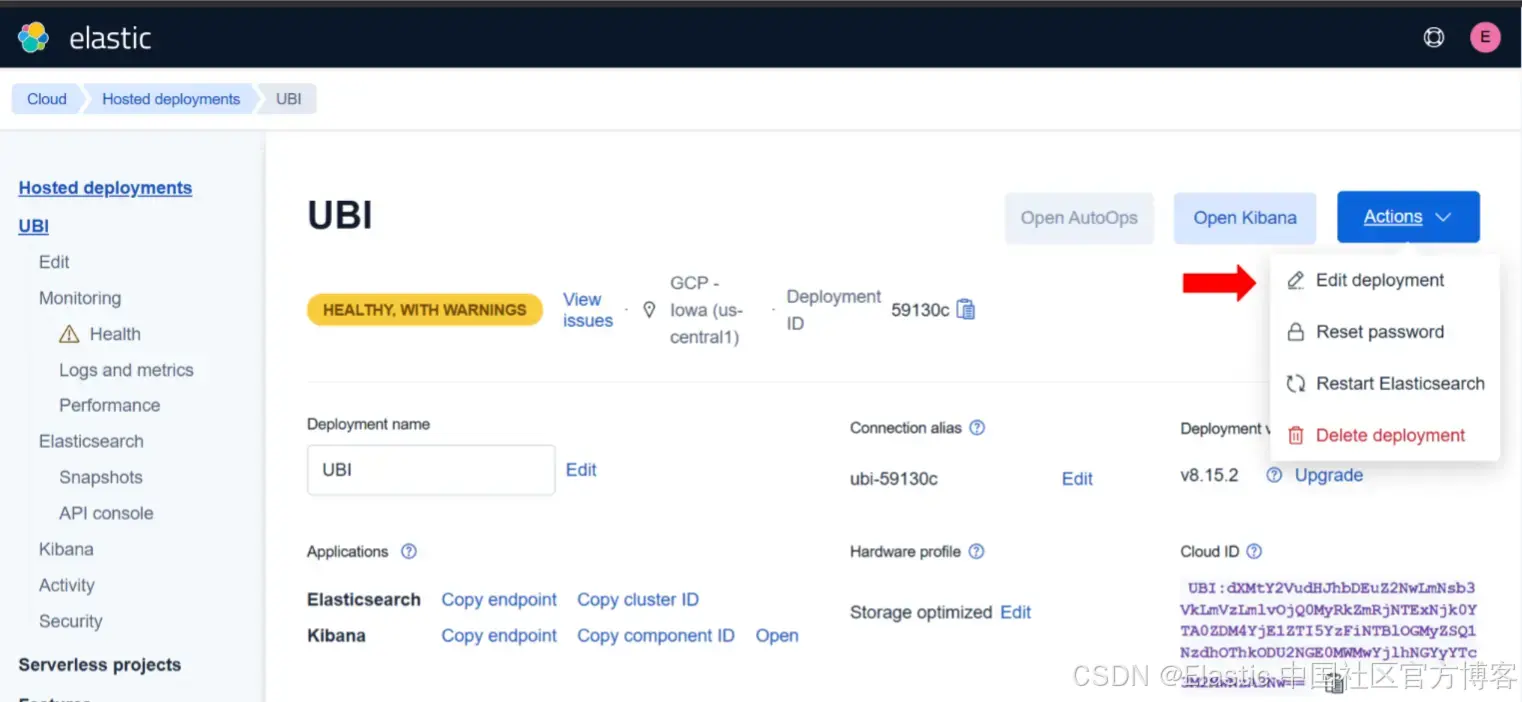
4)在你的工作部署上,点击 Manage。
5)点击 Actions 下拉菜单,然后点击 Edit deployment。
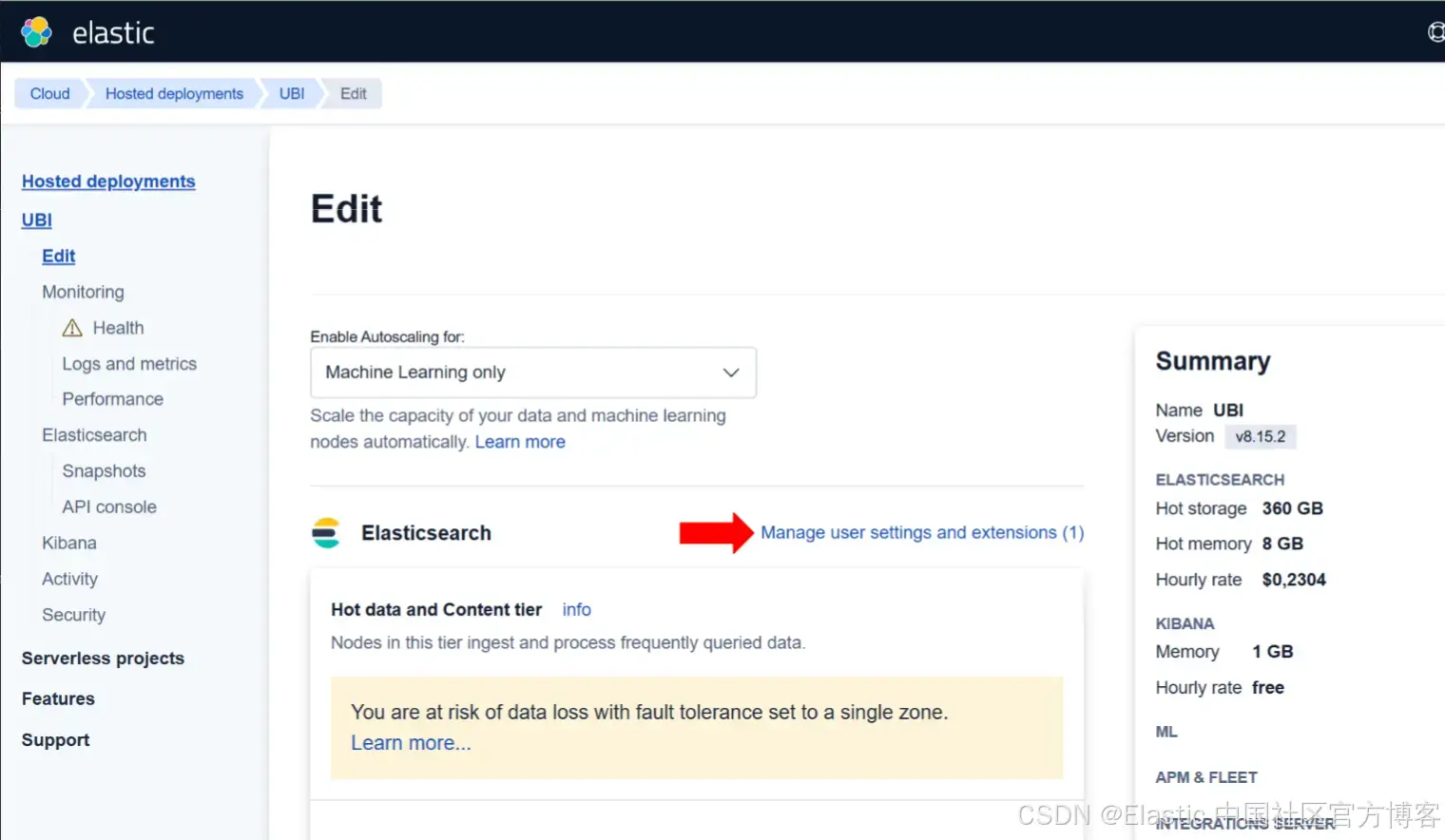
6)在 Elasticsearch 部分,点击 Manage user settings and extensions 链接。
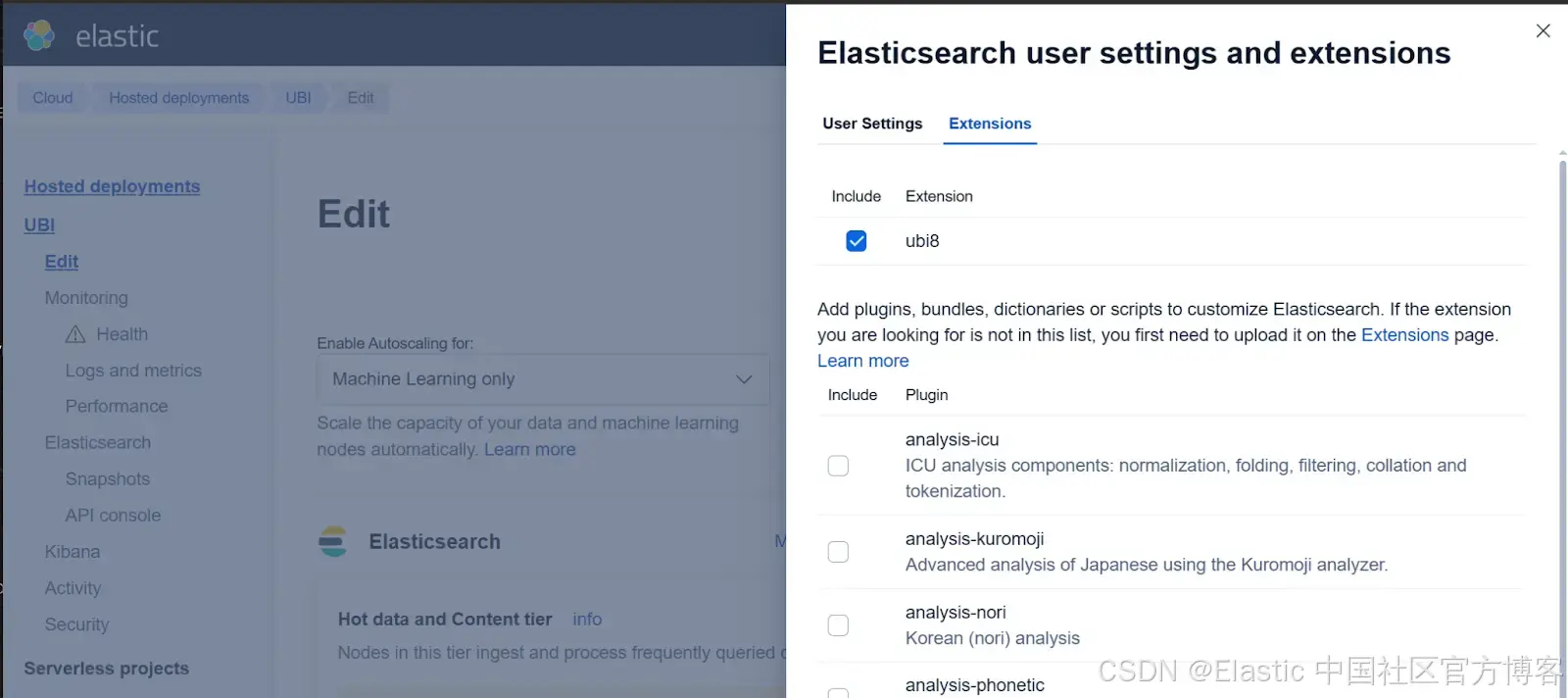
7)点击 Extensions 选项卡,选择最近安装的扩展,本例中是 ubi8。然后,点击 "Back" 并保存更改。
加载示例数据
在 Kibana DevTools 控制台中运行以下命令,加载几本书用于测试插件。此操作会创建一个名为 "books" 的新索引作为示例。
POST /_bulk
{ "index" : { "_index" : "books" } }
{"name": "Snow Crash", "author": "Neal Stephenson", "release_date": "1992-06-01", "page_count": 470, "price": 14.99, "url": "https://www.amazon.com/Snow-Crash-Neal-Stephenson/dp/0553380958/", "image_url": "https://m.media-amazon.com/images/I/81p4Y+0HzbL._SY522_.jpg", "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true}
{ "index" : { "_index" : "books" } }
{"name": "Revelation Space", "author": "Alastair Reynolds", "release_date": "2000-03-15", "page_count": 585, "price": 16.99, "url": "https://www.amazon.com/Revelation-Space-Alastair-Reynolds/dp/0441009425/", "image_url": "https://m.media-amazon.com/images/I/61nC2ExeTvL._SY522_.jpg", "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true}
{ "index" : { "_index" : "books" } }
{"name": "1984", "author": "George Orwell", "release_date": "1985-06-01", "page_count": 328, "price": 12.99, "url": "https://www.amazon.com/1984-Signet-Classics-George-Orwell/dp/0451524934/", "image_url": "https://m.media-amazon.com/images/I/71rpa1-kyvL._SY522_.jpg", "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true}
{ "index" : { "_index" : "books" } }
{"name": "Fahrenheit 451", "author": "Ray Bradbury", "release_date": "1953-10-15", "page_count": 227, "price": 11.99, "url": "https://www.amazon.com/Fahrenheit-451-Ray-Bradbury/dp/1451673310/", "image_url": "https://m.media-amazon.com/images/I/61sKsbPb5GL._SY522_.jpg", "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true}
{ "index" : { "_index" : "books" } }
{"name": "Brave New World", "author": "Aldous Huxley", "release_date": "1932-06-01", "page_count": 268, "price": 12.99, "url": "https://www.amazon.com/Brave-New-World-Aldous-Huxley/dp/0060850523/", "image_url": "https://m.media-amazon.com/images/I/71GNqqXuN3L._SY522_.jpg", "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true}
{ "index" : { "_index" : "books" } }
{"name": "The Handmaid's Tale", "author": "Margaret Atwood", "release_date": "1985-06-01", "page_count": 311, "price": 13.99, "url": "https://www.amazon.com/Handmaids-Tale-Margaret-Atwood/dp/038549081X/", "image_url": "https://m.media-amazon.com/images/I/61su39k8NUL._SY522_.jpg", "_extract_binary_content": true, "_reduce_whitespace": true, "_run_ml_inference": true}测试插件
调用 _search API 时,你可以发送一个额外的 ext 参数 ------ 一个包含本文开头所述字段的对象。
索引查询
我们来写一个查询,并使用插件捕获行为元数据。
GET books/_search
{
"query": {
"match": {
"name": "Snow"
}
},
"ext": {
"ubi": {
"object_id_field": "url",
"user_query": "snow",
"client_id": "web_application",
"query_attributes": {
"app_component": "global_header"
}
}
}
}- object_id_field:用于标识结果的字段,将作为结果集存储在 ubi_queries 索引中。
- user_query:用户在搜索框中输入的内容。
- client_id:查询的发起方。
- query_attributes:任意的键/值对。
在返回结果的同时,响应中会包含一个 query_id,我们可以用它来查看 ubi_queries 索引。
{
"ext": {
"ubi": {
"query_id": "cb26ba2c-27ab-4af3-905b-00aff928cf50"
}
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.5904956,
"hits": [
{
"_index": "books",
"_id": "Ep2h4ZcBDN5ljpdU06rw",
"_score": 1.5904956,
"_source": {
"name": "Snow Crash",
"author": "Neal Stephenson",
"release_date": "1992-06-01",
"page_count": 470,
"price": 14.99,
"url": "https://www.amazon.com/Snow-Crash-Neal-Stephenson/dp/0553380958/",
"image_url": "https://m.media-amazon.com/images/I/81p4Y+0HzbL._SY522_.jpg",
"_extract_binary_content": true,
"_reduce_whitespace": true,
"_run_ml_inference": true
}
}
]
}
}存储在 ubi_queries 中的文档看起来像这样:
{
"_index": "ubi_queries",
"_id": "HJ204ZcBDN5ljpdUKKo2",
"_score": 4.7303333,
"_source": {
"query_response_id": "59474463-5862-4941-992e-50cafc294274",
"user_query": "snow",
"query_id": "cb26ba2c-27ab-4af3-905b-00aff928cf50",
"query_response_object_ids": [
"https://www.amazon.com/Snow-Crash-Neal-Stephenson/dp/0553380958/"
],
"query": """{
"query": {
"match": {
"name": {
"query": "Snow"
}
}
},
"ext": {
"query_id": "cb26ba2c-27ab-4af3-905b-00aff928cf50",
"user_query": "snow",
"client_id": "web_application",
"object_id_field": "url",
"query_attributes": {
"app_component": "global_header"
}
}
}""",
"query_attributes": {
"app_component": "global_header"
},
"client_id": "web_application",
"timestamp": 1751838369845
}
}文档将包含 Elasticsearch 执行的查询、我们提供的元数据、匹配的文档列表,以及查询响应的额外标识符。
有了这些数据,我们现在可以分析趋势,比如热门查询、无结果的热门查询、结果集中的热门文档,并且可以对客户端应用、应用组件和时间过滤器等进行筛选。
捕获事件
假设在同一次搜索中,用户点击了某个结果,我们希望捕获该事件并将其与刚才索引的查询相关联。要捕获客户端事件(例如,点击结果),应用程序必须将事件发送到 ubi_events 索引:
POST ubi_events/_doc
{
"action_name": "click",
"query_id": "cb26ba2c-27ab-4af3-905b-00aff928cf50",
"client_id": "web_application",
"timestamp": "2025-05-09T19:56:55.579Z",
"message_type": "CLICK_THROUGH",
"message": "Clicked Snow Crash",
"user_query": "snow",
"event_attributes": {
"object": {
"object_id": "Ep2h4ZcBDN5ljpdU06rw"
},
"position": {
"ordinal": 1
}
}
}现在我们已经捕获了该文档、搜索中的点击、点击位置(position.ordinal)以及原始的 id 值(object_id)。
该事件使我们能够识别被点击最多的文档、产生最多点击的用户查询,以及用户是否点击了排名靠前的结果。
洞察分析
我们可以使用 ES|QL 来分析数据。下面通过统计 ubi_queries 索引中 user_query 的文档数量,找出排名前五的查询:
POST /_query?format=txt
{
"query": """
FROM ubi_queries
| STATS count = COUNT(*) BY user_query
| SORT count DESC
| LIMIT 5
"""
}你将获得格式化为表格的结果:
count | user_query
---------------+---------------
54 |fahrenheit
14 |snow
9 |summer books
4 |top seller
2 |alastair 总结
本文介绍了如何使用 Elasticsearch 插件捕获 UBI 查询和事件,以及如何使用提取有意义洞察所需的基本字段。
在下一篇文章中,我们将进一步介绍如何捕获更丰富的元数据、编写更高级的 ES|QL 查询,并构建 Kibana 仪表盘,以帮助我们更好地了解用户,提升搜索体验。
原文:Elasticsearch plugin for UBI: Analyze user behavior from search queries - Elasticsearch Labs