opus编码的格式概念:
Opus是一个有损声音编码的格式,由Xiph.Org基金会开发,之后由IETF(互联网工程任务组)进行标准化,目标是希望用单一格式包含声音和语音,取代Speex和Vorbis,且适用于网络上低延迟的即时声音传输,标准格式定义于RFC 6716文件。Opus格式是一个开放格式,使用上没有任何专利或限制。
Opus集成了两种声音编码的技术:以语音编码为导向的SILK和低延迟的CELT。Opus可以无缝调节高低比特率。在编码器内部它在较低比特率时使用线性预测编码在高比特率时候使用变换编码(在高低比特率交界处也使用两者结合的编码方式)。Opus具有非常低的算法延迟(默认为22.5 ms),非常适合用于低延迟语音通话的编码,像是网上上的即时声音流、即时同步声音旁白等等,此外Opus也可以透过降低编码码率,达成更低的算法延迟,最低可以到5 ms。在多个听觉盲测中,Opus都比MP3、AAC、HE-AAC等常见格式,有更低的延迟和更好的声音压缩率。
需求场景:
最近我在对接一个可以接收声音的 硬件设备,通信模式为 websocket。
通过测试 ,接收到的音频格式为 :opus 格式。
我接收到这个格式的 音频后,首先需要给这个格式的音频进行解码,然后得到PCM编码格式的数据。
解码后的 PCM 数据则是还原后的音频信号,是原始音频的近似表示,可以直接输出音频信号。
PCM解释:
PCM(脉冲编码调制,Pulse Code Modulation)编码是一种将模拟信号转换为数字信号的方法,广泛用于音频、视频和通信系统中。PCM编码的主要目的是将模拟信号的幅度表示为一系列的数字值,这样可以在数字系统中更容易地存储、处理和传输。
PCM编码的基本过程 :
采样 :首先,将模拟信号按一定的时间间隔进行采样。每次采样得到的值称为"采样点"。
量化 :将每个采样点的模拟信号值转换成最接近的数字值。量化的精度由量化位数(通常是8位、16位或更高)决定,位数越高,表示的数字精度越高,信号的失真越小。
编码 :将量化后的数字信号进行二进制编码,即将每个采样点的数字值转化为二进制形式,形成一串二进制代码。
PCM的常见应用 :
音频 :例如CD音质的音频数据就是使用PCM编码的,通常采用44.1kHz的采样率和16位的量化深度。
通信 :PCM也用于电话通信和其他语音传输领域。
视频:PCM有时也用于视频信号的音频部分编码。
对于做网站开发的我,也是第一次处理关于音频的数据,这篇文章就把我遇到的一些问题做一个分享,希望能帮助看到这篇文章的你。
这个设备提供的代码是python版本的。
但是我是使用 java语言,springboot 框架 来处理数据的。
在调试的过程中 遇到了一个问题:opus格式的音频解码的问题?
对于python来说 这个语言 有现成的包 opuslib 还是比较好处理的
bash
# Opus音频解码
import opuslib
import opuslib.api.encoder
import opuslib.api.decoder
class OpusDecoder():
def __init__(self, samplerate: int, channels: int, seq_time: float) -> None:
self.samplerate = samplerate
# 创建解码器
self.decoder = opuslib.Decoder(fs=self.samplerate, channels=channels)
self.seq_length = int(seq_time*self.samplerate*2)
def decode(self, input_bytes: bytes):
# 直接解码opus数据
dec_output = self.decoder.decode(bytes(input_bytes), self.seq_length)
# print('decode seq len: {}'.format(len(dec_output)))
return dec_output当我来使用java的时候 发现 网上java对于这个格式音频处理的相关文章非常的少,相关依赖也非常的少,至于找到的可以用的依赖,也没找到相关文档怎么使用。
通过我在 github上的搜索和 maven仓库里的寻找,终于找到了java对于 opus格式的音频的解决方案。
下面就直接上代码了:
第一步引入依赖:
bash
<dependency>
<groupId>club.minnced</groupId>
<artifactId>opus-java</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.1.0</version>
</dependency>第二步封装 工具类:
bash
package com.agentai.base.utils;
/***
* opus 解码器工具类
* User: Json
* Date: 2025/4/11
**/
import club.minnced.opus.util.OpusLibrary;
import com.sun.jna.ptr.PointerByReference;
import tomp2p.opuswrapper.Opus;
import java.io.IOException;
import java.nio.IntBuffer;
import java.nio.ShortBuffer;
import java.util.Base64;
public class OpusDecoder {
private int samplerate;
private int seqLength;
private PointerByReference opusDecoder;
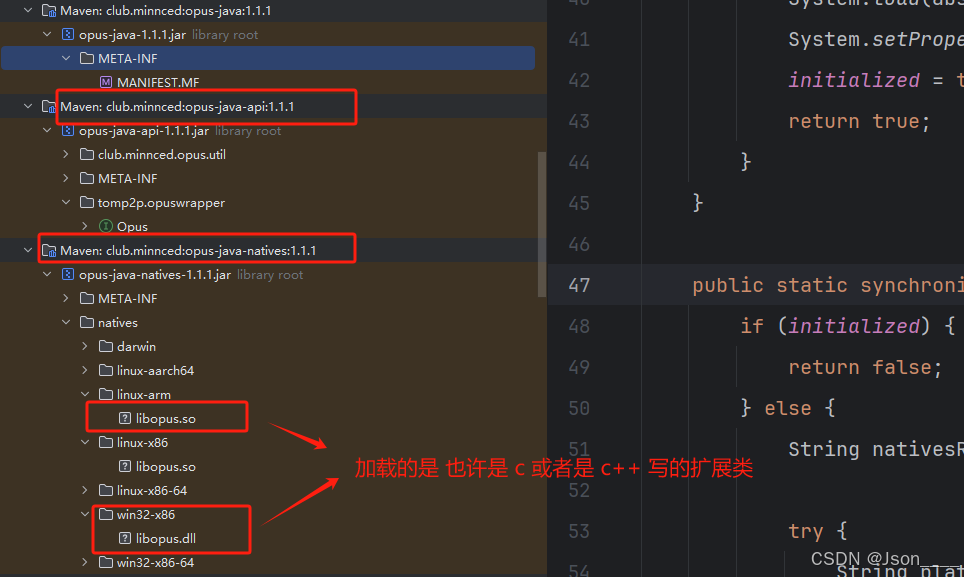
// 加载 Opus 库 对于这个加载 opus库的 写法 文章下方 有截图的解释。
static {
try {
// 尝试通过 OpusLibrary 加载 JAR 内的本地库
if (!OpusLibrary.loadFromJar()) {
throw new UnsatisfiedLinkError("未加载到 opus处理文件!");
}
} catch (IOException e1) {
try {
// 如果失败,尝试通过默认的 System.loadLibrary() 加载 找本地系统的
System.loadLibrary("opus");
} catch (UnsatisfiedLinkError e2) {
e1.printStackTrace();
}
}
}
public OpusDecoder(int samplerate, int channels, float seqTime) {
this.samplerate = samplerate;
// 创建 Opus 解码器
IntBuffer error = IntBuffer.allocate(4);
this.opusDecoder = Opus.INSTANCE.opus_decoder_create(samplerate, channels, error);
this.seqLength = (int) (seqTime * this.samplerate * 2);
}
public short[] decode(String base64Audio) {
// 1. 解码 Base64 音频数据
byte[] audioBytes = Base64.getDecoder().decode(base64Audio);
// 2. 创建用于存储解码后的数据的 ShortBuffer
ShortBuffer decodedData = ShortBuffer.allocate(1024 * 1024);
// 3. 解码 Opus 数据
int decoded = Opus.INSTANCE.opus_decode(opusDecoder, audioBytes, audioBytes.length, decodedData, seqLength, 0);
// 4. 返回解码后的短音频数据
short[] result = new short[decoded];
decodedData.get(result, 0, decoded);
return result;
}
public byte[] decodeToBytes(String base64Audio) {
// 1. 解码 Base64 音频数据
byte[] audioBytes = Base64.getDecoder().decode(base64Audio);
// 2. 创建用于存储解码后的数据的 ShortBuffer
ShortBuffer decodedData = ShortBuffer.allocate(1024 * 1024);
// 3. 解码 Opus 数据
int decoded = Opus.INSTANCE.opus_decode(opusDecoder, audioBytes, audioBytes.length, decodedData, seqLength, 0);
// 4. 转换 short[] 为 byte[]
short[] shortData = new short[decoded];
decodedData.get(shortData, 0, decoded);
byte[] byteData = convertShortToByte(shortData);
return byteData; // 返回 byte[] 类型的音频数据
}
private byte[] convertShortToByte(short[] shortArray) {
byte[] byteArray = new byte[shortArray.length * 2];
for (int i = 0; i < shortArray.length; i++) {
byteArray[i * 2] = (byte) (shortArray[i] & 0xFF); // 低字节
byteArray[i * 2 + 1] = (byte) ((shortArray[i] >> 8) & 0xFF); // 高字节
}
return byteArray;
}
// 销毁解码器,释放资源
public void close() {
Opus.INSTANCE.opus_decoder_destroy(opusDecoder);
}
// 测试解码功能
public static void main(String[] args) {
// 假设这是接收到的 Base64 编码的音频数据
// 因为我的音频是先base了一下 所以我需要先用base64 解码,
//如果你的音频没有 base64 这个步骤跳过即可
String base64Audio = ""; // 你的音频数据流
// 创建解码器对象
OpusDecoder decoder = new OpusDecoder(16000, 1, 0.02f);
// 解码音频
byte[] decodedAudio = decoder.decodeToBytes(base64Audio);
// 打印解码结果长度
System.out.println("Decoded audio length: " + decodedAudio.length);
// 关闭解码器
decoder.close();
}
}这个工具类的封装 也是我找的依赖 看他们的源码 自己封装的,
因为 开源的相关依赖没有提供非常完整的 使用文档,所以只能自己看源码 。
下面就是我在源码里看到的:
我的理解:
java 没有现成处理这种opus格式音频的能力,也许这就是为啥网上关于java处理这个音频的的文章比较少的原因。
看到源码后,这个依赖的解决方案就是,把可以处理 opus格式的 扩展打包到 java的jar里,然后通过java 来加载 这些 扩展,然后通过java调用这些扩展里的方法从来 实现 opus格式的音频解码。