探秘Transformer系列之(26)--- KV Cache优化 之 PD分离or合并
toc
0x00 概述
在大模型的推理过程中,通常可以将任务分为两个阶段:Prefill 阶段处理所有输入的 Token,生成第一个输出 Token,并生成 KVCache。Decode 利用 KVCache 进行多轮迭代,每轮生成一个 Token。由于 Prefill 阶段并行处理许多 Token,因此是计算密集型的,其延迟通过首 Token 时延(TTFT)来衡量。相比之下,Decode 阶段由于频繁加载不断增长的 KV Cache 而成为内存密集型,其时延通过 TPOT 来衡量。
因为Pefill 阶段和Decode 阶段的特性迥异,很难找到完美的方案同时满足两个阶段的需求。研究人员也八仙过海,各显神通。本文就带领大家来学习下学术界和工业界的各种方案。
注:
- 本系列是对论文、博客和代码的学习和解读,借鉴了很多网上朋友的文章,在此表示感谢,并且会在参考中列出。因为本系列参考文章太多,可能有漏给出处的现象。如果原作者发现,还请指出,我在参考文献中进行增补。
0x01 背景知识
1.1 自回归&迭代
当执行文本生成任务时候,基于Transformer架构的自回归语言模型会接受一个文本序列作为输入,模型通过生成连续的输出标记来完成序列,这是一个迭代的过程。我们把模型从接受请求输入到输出一个token的操作定义为模型的一个迭代。对于每个请求,模型会逐步生成输出序列的各个部分,直到生成停止标记或达到最大序列长度为止。这意味着每次模型前向传递时,都会获得一个额外的输出token。例如,如果我们以句子"加利福尼亚的首府是什么:"作为提示,它将需要进行十次前向传递才能得到完整的响应,即"S", "a", "c", "r", "a", "m", "e", "n", "t", "o"。即LLM一个请求可能会包括多个迭代。
下图示例展示了一个三层GPT模型的架构,其中节点和边分别表示Transformer层和层间依赖关系。模型按照节点上的编号顺序执行Transformer层,同一层的节点使用相同的模型参数,以同一颜色(不同深浅颜色)填充。生成的输出标记反馈到模型中,生成下一个输出标记,形成顺序逐个推理的过程。
在示例中,推理过程包括三个迭代(对应图上三个绿色标号)。这三个迭代又可以分为两个阶段:
- 初始化阶段。该阶段通常只包括一个迭代,负责通过并行处理所有输入token来生成第一个输出token。对应图上就是第一次迭代("iter 1")一次性接受所有输入标记("I think this"),生成下一个标记("is")。其实可以看到,此处的迭代对应的就是prefill阶段。
- 增量阶段。该阶段通常包括多个迭代,每个迭代会接受前一次迭代的输出标记生成下一个标记(每次迭代只能处理一个标记)。对应下图,本阶段包括后两次迭代("iter 2"和"iter 3")。在这个示例中,"iter 3"是最后一个迭代,因为它生成特殊的结束标记"",终止输出生成。此处的每个迭代对应的就是decode阶段。

总结下,我们管请求做完prefill产出第一个token的过程叫1次iteration,请求每做一次decode也被称为1次iteration。
1.2 KV Cache
下图给出了prefill和decoding阶段KV Cache的作用。(a)的顶部是自回归LLM推理的示例,底部是transformer层中的模块。(b)给出了KV Cache的操作。在预填充阶段,所有输入token同时处理,并存储生成的中间KV张量,用深色标记。s和d表示输入序列长度和KV张量的隐藏维数。在解码阶段,存储的深色KV张量被检索出来。输入的Q、K、V张量由浅色标记。输入Q张量与输入K和存储的K张量的合并结果(concatenation )进行相乘,然后是整个注意力权重的softmax。注意力权重进一步与输入V和存储的V张量的合并结果(concatenation )进行相乘,以生成新的结果。然后,将输入的K和V张量再存储在KV Cache中。对每个token都重复此过程。
- Prefill 阶段会并行处理输入 prompt 的所有 token,输出第一个token,并生成用于未来解码的KV Cache。因为输入序列长度很长,所以计算开销大,很小的 batch size 就会让 GPU 打满。增大 batch size,prefill 阶段单个 token 开销几乎是不变的。
- (开启 KV Cache)的 decode 阶段使用先前的KV Cache以自回归方式逐步生成新的token。decode 阶段在每个自回归步仅仅会生成一个 token。虽然decode 阶段输入的序列长度一直是 1,但是需要反复读取 KV Cache,故而 IO 开销很大。Decode 时,单个 token 的开销显著大于 prefill 阶段。需要把 decode 阶段的 batch size 配置得非常大才有可能占满 GPU ,但会因为 KV Cache 读写开销太大而变得不现实,所以 decode 阶段的 GPU 利用率很低。

0x02 静态批处理
2.1 调度策略
前面提到,LLM 正在改变整个行业在其服务中采用 AI 技术的方式,但 LLM serving 的成本却仍然很高。为降低 serving 成本,目前许多公司专注于最大化整体 LLM serving 系统的整体吞吐量(throughput),即每秒服务的请求数量(或 rps)。几乎所有流行的 LLM serving 引擎都把吞吐量作为比较性能的主要指标。
为了提高吞吐率,人们会采用批处理技术。批处理是一种将多个数据样本一起传递给模型进行处理的技术。启用批处理后,执行引擎会将来自多个请求的输入张量合并成一个大的输入张量,然后将其送入模型进行推理。由于加速器更喜欢大型输入张量而不是小型张量,因此相比于逐个处理单个样本,批处理可以在一次计算中同时处理多个样本。这样可以更有效地利用计算资源,提高计算速度。在LLM推理中,批处理的优势主要体现在以下几个方面:
-
减少模型参数加载次数: 在不使用批处理的情况下,每次处理一个输入序列都需要加载一次模型参数,而加载模型参数通常会消耗大量的内存带宽。使用批处理可以在一次加载模型后多次使用这些参数来处理多个输入序列,从而减少了加载的次数。
-
提高内存带宽和计算资源的利用率: GPU的内存带宽是有限的资源,通过批处理,可以更有效地让这些内存带宽在计算过程中得到更充分的利用,从而可以更有效地利用计算资源,提高计算速度。
传统的批处理方法被称为静态批处理,是因为在这种方法中,批处理的大小在批次中有所请求的推理完成之前保持不变。在静态批处理中,当新请求在当前批次执行过程中到达时,引擎会保持这些新请求在请求队列中,直到当前批次中所有请求都完成。即服务系统和执行引擎之间的交互仅在以下两种情况下发生:当服务系统在空闲的引擎上安排下一批请求;或者当引擎完成当前批次的处理后。其具体流程如下:
- 如果当前执行引擎空闲,Scheduler(调度器)从队列中获取一批请求构建成一个batch(图中的 x1 :"I Think"和 x2 :"I love"),对于下图中标号1。
- Scheduler将batch交给Execution Engine(执行引擎)去做推理,对于下图中标号2。
- Execution Engine通过运行模型的多次迭代来处理接收到的batch,对于下图中标号3。
- 当Execution Engine把这个batch的请求都处理完之后(Execution Engine分别生成"this is great"和"you"作为请求 x1和 x2的响应。),会统一返回给Scheduler,对于下图中标号4。
- Scheduler会从请求队列中再次获取一批请求构建一个新batch。

2.2 问题
我们很容易发现静态批处理策略的劣势:它难以有效地处理不同生成长度的序列。静态批处理可能导致GPU在批处理中的不同序列的生成长度不同时被低效利用。因为不同的序列可能会在批处理中的不同迭代步骤中完成生成,而静态批处理会等待所有序列完成生成后才开始处理新的序列。这导致了在等待最后一个序列完成生成之前,GPU可能会被低效利用的情况。因为通过自回归方式处理单个请求时可能需要运行多次模型,而不同请求所生成的文本长度不一致,需要的迭代次数很可能不同,这就使得一些请求提前完成而其他请求仍在进行中。一旦有一个生成时间较长的序列存在,其他生成时间较短的序列将被迫等待、不能立即返回给客户端,即增加了给客户带来得延迟,也导致GPU的计算资源无法充分利用,浪费GPU的计算能力。如上图所示, x2提前完成,但是 x1 尚未完成迭代,所以 x2无法立即返回。而在上次分派之后到达的新请求( x3,x4)也必须等待当前batch中的 x1处理完毕才能继续分发,这显著增加了排队时间。
因此,我们目前需要解决的问题如下:
- 问题1:如何处理提前完成的请求(early-finished requests)。不同请求所生成的文本长度不一致,短文本请求只能等待长文本请求处理完毕。而因为不易预测生成文本长度,故此难以把相同长度的文本组成一个batch一并处理。因此需要一个将已生成结束的请求从Batch中移除并提前返回结果的机制。
- 问题2:如何释放资源、处理延迟加入的请求(late-joining requests)。队列中的新请求只能等到当前batch结束之后才能被scheduler进行分发,等待时间过长。因此需要一个将新请求插入到当前处理Batch中的机制。
需要注意的是,提前完成和延迟加入请求的问题在模型训练中并不会出现;训练过程通过使用Teacher Forcing技术在单次迭代中完成整个批次的处理。
2.3 原因分析
有两个原因导致出现上述问题,分别可以从宏观和微观角度来进行分析。
2.3.1 宏观
从宏观角度来说,问题本质在于"基于Transformer的生成模型的多迭代特性"和"以请求为粒度的调度策略"之间的冲突。多迭代特性意味着不同请求可能需要不同次数的迭代,某些请求的迭代次数可能会很少,可以提前处理完毕并返回给用户。而与静态批处理的这种特点对应,传统推理架构的调度策略是以请求为粒度的调度(Request-Level Schedule)。以请求为粒度的调度策略缺少灵活性,无法更改当前正在处理的请求batch,比批次中其他请求更早完成的请求无法返回客户端,而新到达的请求则必须等到当前批次完全处理完毕。这就导致当前的请求级调度机制无法有效处理具有多次迭代特性的工作负载。
对指标的影响
从指标角度来看更为清晰,即静态批处理通过牺牲TTFT和throughput的方式来确保TPOT。如前所述,在一个batch中,prefill阶段通常作为一个迭代通过并行处理所有输入标记来实现,这说明后续迭代都是decode阶段。因为必须把当前batch的请求全部处理完成才能返回,所以静态批处理可以确保Execution Engine始终在进行decode操作,这样TPOT时间可以得到保证。但是因为在这个batch做推理的过程中不能接受新的请求,导致吞吐量下降,进而导致新请求的TTFT指标下降(新请求只能在请求队列中等待,无法在第一时间执行prefill操作)。
对流水线的影响
另外,以请求为粒度的调度也会增加流水线中的气泡。当模型尺寸过大时,人们常常采用多张GPU进行并行推理,而流水线并行是常见方式之一。流水线并行的优势是只涉及层间激活的通信,对带宽要求相对较小。下图中,模型被切分为三层,分别部署在Partition1~3这三张GPU上。A和B是两个序列,下标代表本序列正在进行第几次模型迭代。假设A和B都在decode阶段,因为decode阶段是自回归逐一输出token,因此A和B需要在第一次迭代完成之后,才能进入下一次迭代。这样就造成了GPU上的空闲时间(气泡)。

2.3.2 微观
由于预填充和解码阶段共享LLM权重和工作内存,现有的LLM服务系统通常将这两个阶段放在一个GPU上,并通过批量处理预填充和解码步骤来最大化整个系统的吞吐量(每秒跨所有用户和请求生成的token数)。而出现问题的本质原因在于,当前的LLM系统对LLM预填充和解码阶段所展示的不同特征以及计算模式一无所知,也不清楚这些模型对SLO的不同影响。预填充阶段类似于计算密集型的批处理作业,而解码阶段类似于内存密集型、延迟关键的任务。静态批处理将这两种运算放到相同的 GPUs 上进行处理并不是实现高有效吞吐量的最佳策略。

注:此处说的是静态批处理中的对prefill和decoding进行处理,并非是我们接下来会讲到的融合方案。
阶段特点
前面章节从技术和流程特点分析了prefill和decode之间的差异,我们这里结合指标和资源利用来继续分析。
Prefill 和 Decode 请求有着不同的计算特性,并且需要满足不同的 SLO。
-
Prefill。主要满足 TTFT 指标。这是一种Compute Bound 的运算,对计算资源的需求量极大。其计算量随输入提示长度的平方增加。耗时超线性增加(吞吐量下降,如果耗时线性增加,那么平均吞吐量不变),哪怕是小批次的预填充任务,甚至单个较长的预填充任务,都可能使 GPU 的计算能力达到饱和,打满计算资源。一旦加速器达到饱和状态,预填充阶段的吞吐量就会保持不变(我们将其命名为加速器饱和阈值)。
-
Decode:主要满足 TPOT 指标。这是一种 Memory Bound 的运算,更容易受到 GPU 内存带宽限制的影响。对延迟敏感的任务,其资源使用量随生成的token长度呈次线性增长。Decode 计算需要大 batch 请求提高计算强度,充分利用计算资源。随着bs的增大,耗时略有增加(主要是因为数据增多导致传输耗时增多,计算耗时基本认为不变),吞吐量大概是线性增加。随着批量大小增加,解码阶段的吞吐量继续增加,但一旦内存带宽达到饱和状态,吞吐量就会达到峰值。
互相影响
Prefill 和 Decode 放在相同的 GPUs 上运行会导致它们之间相互干扰。我们看看当 GPU 在同时处理 Prefill 请求和 Decode 请求时,Prefill 和 Decode 如何互相影响性能。
- 对于 Prefill 请求,由于同一个 batch 有其它 Decode 请求,所以在 GPU 中计算耗时对比没有 Decode 请求时会略微增加,从而增加 Prefill 请求的 TTFT。
- 对于 Decode 请求,由于同一个batch 有 Prefill 请求,并且 Prefill 请求计算耗时通常会比 Decode 请求耗时大很多(一般是好几倍甚至几十倍的关系)。批处理中的解码任务必须等待更长的预填充作业完成,会造成 Decode 请求被 Prefill 请求拖慢,必须等待 Prefill 请求完成计算,Decode 请求才会开始下一个 token 的计算,从而大大增加了 Decode 请求的 TPOT。
这种干扰是经典的系统问题。
- 混合运行预填充请求会导致严重的减速,因为我们在已经饱和的硬件上继续添加计算密集型作业。
- 混合运行预填充和解码请求会对两者都产生负面影响,因为我们同时运行批处理和延迟关键的作业。
- 混合解码请求会导致吞吐量下降,因为我们不了解内存带宽和容量使用情况,从而导致争用和排队阻塞。
优先安排一个阶段可能会导致无法满足另一个阶段的延迟要求。比如,较高的到达率(req/s)会生成更多的预填充作业,如果优先考虑预填充作业,则需要更多的GPU时间来满足TTFT要求,这反过来会对TPOT产生不利影响。
合并预填充和解码也会耦合它们的GPU资源分配策略和并行策略,并阻止实现更适合满足每个阶段特定延迟要求的不同并行性策略。然而,每个阶段都具有其独特的计算特性和延迟要求,需要更多的异构资源分配。
- GPU 分配策略。如果希望同时满足 TTFT 和 TPOT 的 SLO,系统必须过度配置资源以满足时延目标,尤其是在 SLO 要求严格的情况下。这两种运算对 GPU 资源的需求不一样。相同数量的 request 输入,Prefill 需要更多的 GPU 满足 TTFT,而 Decode 可以需要更少的 GPU 满足 TPOT。但原有的服务架构中,Prefill 阶段和 Decode 阶段会共享 GPU 分配策略,因此,为了满足 Prefill 运算的 TTFT,会配置更多的 GPU,这对于 Decode 运算是超额的;为了支持一定总量的吞吐,需要降低每个 GPU 处理的 requests 数量,这样也需要超额配置 GPU 资源;随之而来的就是部署成本的上升,这种"充值"的方式并不是长久之策。
- 模型并行策略。不同的场景下,由于它们的计算模式和时延目标截然不同,那么 Prefill 和 Decode 的最优模型并行策略可能不同。假如服务对 TTFT 较严格,对 TPOT 需求较低,那么 Prefill 阶段更倾向使用 Tensor Parallelism(简称 TP)来满足严格的时延目标,而 Decode 阶段更倾向使用数据或流水线并行提高吞吐量。但现有的服务架构中,预填充和解码计算的并行策略(张量、流水线或数据并行)本质上是耦合的,Prefill 阶段和 Decode 阶段会共享模型并行策略。因此,无法针对不同阶段采用同时兼顾吞吐与SLOs更优的配置。
将预填充和解码作业解除批处理并按顺序调度并不能减轻干扰。由于解码作业需要等待GPU上正在进行的预填充作业,解码作业可能会经历更长的排队延迟。此外,专门用于解码的批次通常会导致GPU利用率降低。优先处理某个阶段的任务会对另一个阶段的延迟产生不利影响,从而使优先调度失效。
2.4 挑战
2.4.1 从宏观角度来应对
从宏观角度看。既然问题出自"基于Transformer的生成模型的多迭代特性"和"以请求为粒度的调度策略"之间的冲突,有研究人员就提出了采用迭代级别调度来促进各个阶段的并发处理。OSDI 2022 上发表的 Orca 是第一篇解决这个问题的论文。
对于静态批处理,其批次大小是在批次启动时候就确定的,批处理的大小在批次中有所请求的推理完成之前保持不变。而对于迭代级别调度,批次的大小是在每个迭代中动态确定的,而不是在推理过程的开始时就固定下来。这意味着一旦批次中的某个序列完成生成,就可以立即插入一个新的序列以继续利用GPU进行计算。这会让GPU不会因为等待批次中的所有序列完成生成而被浪费,让计算资源得到更高效的利用,从而可以实现更高的推理吞吐量,加快整个推理过程的速度。
2.4.2 从微观角度来应对
从微观角度看,目前的挑战就是如何权衡TTFT 和TPOT之间的balance。假设请求池里面是来自不同用户的不同状态的请求,有的请求等待做pefill,有的请求等待做decode,但是只有一个GPU。
问题1的挑战
针对问题1:如何处理提前完成的请求。
因为当前整个batch都没有完成,用户只能等待。因此有研究人员想到:是否可以让batch中已经做完推理的请求释放资源,让新来的请求执行prefill操作。原有的请求继续执行目前的操作(prefill或者decode)。
问题2的挑战
针对问题2:如何处理延迟加入的请求。
由于预填充和解码阶段具有不同的特征,MaaS提供商设置不同的指标来衡量它们对应的服务级别目标(SLOs)。具体来说,预填充阶段主要关注请求到达和生成第一个标记之间的延迟,即时间到第一个标记(TTFT)。另一方面,解码阶段关注同一请求连续标记生成之间的延迟,称为标记之间的时间(TBT)。
如何满足以上指标?有不同的思路。
- 当使用流水线并行时,有研究人员想到是否可以在气泡处插入新请求做prefill或者decode操作?这样可以在不影响当前请求的情况下填满气泡。
- 当不使用流水线并行时,接下来是处理等待prefill的请求?还是处理等待decode的请求?其实取决于在TTFT和TPOT两个指标中牺牲哪个,保全哪个。假设请求池有若干的prefill请求,如果优先处理等待prefill的请求,就可以快速给用户返回第一个token。但是需要连续处理好几个处理等待prefill的请求,无法做decode。这是在牺牲TPOT保全TTFT;如果为了让用户快速获取后续的token,让系统连续处理几个等待decode的请求,prefill请求就要等待,这样是在牺牲TTFT好全TPOT。
似乎无论调度策略怎么调整,TTFT和TPOT这两个指标都存在强耦合关系。是prefill和decode这两个阶段在本质上就无法共存,必须分开独立发展?还是可以做融合,共同进步?
2.5 派系
针对上面的疑问,处理Prefill和Decode有融合派和分离派两大流派。此处引用知乎大神方佳瑞的论断。
2.5.1 融合派
融合派的思路是将prefill放到Decode的间隙进行处理,或者把prefill和某个decode一起进行推理。开山之作是发布在2022年OSDI的Orca,其将Prefill和Decode融合,作为一个批次迭代(batching step)做前向传播。在这之后,以Sarathi(arxiv.org/pdf/2401.08...
融合派的优点是,prefill chunk和decode融合之后的处理时间和只做decode处理时间可能类似,这相当于prefill把decode没有用满的算力再利用起来。而且因为decode和prefill阶段都需要读一些固定的数据(比如模型权重),所以decode也可以搭上prefill的便车,把多次的数据读取合并起来,一次读取,多次使用。
融合派的缺点是,Prefill和Decode在相同设备上,二者并行度被绑定。如果prompt长度有限,则在请求的处理时间中,prefill阶段占比较小,尚可利用好算力。对于长序列,则prefill的占比提高,prefill并行度不够灵活的缺陷就暴露出来。
2.5.2 分离派
分离派:考虑Prefill/Decode性质差异,人们开始尝试把Prefill和Decode放到不同的设备来分别处理。比如,Splitwise(arxiv.org/abs/2311.18...
分离预填充和解码自然地解决了两个阶段之间的干扰,并使每个阶段都能专注于其优化目标 - TTFT或TPOT。每种类型的实例可以使用不同的资源和并行性策略来满足各种延迟要求。通过调整为两种类型的实例提供的GPU数量和并行性,我们可以最大化整个系统的每个设备的吞吐量,避免过度配置资源,最终实现符合服务质量的每个查询成本的降低。
分离派可以给Prefill和Decode设置不同的并行度,二者有更大的灵活性,使得整个系统朝着更好利用算力和更好利用带宽这两个不同方向对立发展,可以更好的对硬件进行优化。比如对于prefill和decode采用不同类型的GPU卡,或者可以针对长序列来分配多一些GPU进行处理,进而降低长序列的TTFT。
分离派遇到的最大挑战是如何在不同设备之间传输KVCache,这导致网络成本很大,从而需要比较高规格的网络硬件来在集群中进行互联。而如何处理长序列的并行,也是一个棘手问题。
接下来会看看两种派别如何处理这些问题。
0x03 融合派
融合派的思路是搭便车。尽管很多推理引擎采用了最先进的批处理和调度技术,但是decode阶段没有充分利用到GPU的计算资源,因此可以将prefill放到Decode的间隙进行处理,或者把prefill和某个decode一起进行推理。典型代表是:
- ORCA:把调度粒度从请求级别调整为迭代级别,并结合选择性批处理(selective batching)来进行优化。
- Sarathi-Serve:利用Chunked Prefill策略通过将不同长度的prompts拆分成长度一致的chunks来进行prefill,同时利用这些chunks间隙进行decode 操作。
注意:目前业界把依据ORCA思想实现的方案叫做Continuous Batching(连续批处理)。连续批处理是一种优化技术,它允许在生成过程中动态地调整批处理的大小。具体来说,一旦一个序列在批处理中完成生成,就可以立即用新的序列替代它,从而提高了GPU的利用率。这种方法的关键在于实时地适应当前的生成状态,而不是等待整个批次的序列都完成。
与静态批处理不同,连续批处理采用了迭代级别的调度。它并不等待每个序列在批次中完成生成后再进行下一个序列的处理。相反,调度程序在每个迭代中根据需要确定批次的大小。这意味着在每次迭代之前,调度程序检查所有请求的状态。一旦某个序列在批次中完成生成,就可以立即将一个新的序列插入到相同位置,同时删除已完成的请求。
3.1 ORCA
针对如何处理"提前完成和延迟加入的请求"这个挑战,ORCA给出的解决方案是用迭代级调度减少空闲时间,即以迭代为粒度(iteration-level)控制执行,而不是请求级粒度(request-level),并结合选择性批处理(selective batching)来进行优化。
3.1.1 迭代级调度
目标
迭代级调度的目标是:及时检测出推理完毕的请求,将其从batch中移出,以便新请求可以填补到旧请求的位置上,这样新请求和旧请求能接连不断组成新的batch。
调度
前文提到,Orca是第一篇提到迭代级别调度(Iteration-Level Schedule)的论文。具体来说就是:一个batch中的所有请求每做完1次iteration(prefill或者decode),scheduler就和engine交互一次,去检查batch中是否有做完推理的请求,以此决定是否要更新batch。这样就可以在每次GPU推理的空隙,可以插入调度操作,实现Batch样本的增删和显存的动态分配释放。
下图给出了请求粒度的调度和迭代粒度调度的区别。前者需在整批请求全部完成前对调度批次进行多次迭代,而对于ORCA,服务系统在调度任务时,每次只向 Execution Engine 提交一次迭代的计算,而非等到完成整个 Request才能处理。这样 ORCA 就可以在每个迭代都动态更改要处理的请求,新请求只需等待单次迭代即可被处理,从而避免early-finish的请求等待其他请求的结束。通过迭代级调度,调度器能够完全控制每个迭代中处理哪些请求以及处理数量。

方案
下图展示了采用迭代级调度的ORCA系统架构和整体工作流程。ORCA系统包括如下模块:
- Endpoint(端点)。用于接收推理请求并发送响应。
- Request Pool(请求池)。新到达的请求被放入请求池中,该组件负责管理系统中所有请求的生命周期。
- Scheduler(调度器)。调度器监控请求池,负责以下任务:从池中选择一组请求,调度执行引擎对这些请求执行模型迭代;接收执行引擎返回的执行结果(即输出token),并将每个输出token追加到对应请求中来更新请求池。
- Execution Engine(执行引擎)。执行引擎是执行实际张量操作的抽象层,可在跨多个机器分布的多个GPU上并行化。
我们接下来看看下图中的工作流程,其中,虚线表示组件之间的交互,交互发生在执行引擎的每次迭代中。 xij是第i个请求的第j个token。阴影token表示从客户端接收到的输入token,而非阴影token由ORCA生成。例如,请求 x1最初带有两个输入标记( x11, x12),到目前为止已经运行了两次迭代,其中第一次和第二次迭代分别生成了 x13和 x14。另一方面,请求 x3只包含输入标记 x31, x32,请求 x4包括 x41, x42, x43,因为它们还没有运行任何迭代。
工作流程分为如下几步:
- 调度器与请求池交互,以决定下一步运行哪些请求。对应下图标号➀。
- 调度器调用引擎为所选定的四个请求( x1,x2,x3,x4)执行一次迭代。此时,因为 x3和 x4还没有运行任何迭代,因此调度器为 x3移交 x31, x32给执行引擎,为 x4移交 x41, x42, x43给执行引擎。对应下图标号➁。
- 引擎对四个请求运行模型迭代,对应下图标号➂。
- 引擎把生成的输出token( x15, x23, x33, x44)返回给调度器,对应下图标号➃。调度器在每次引擎返回,接收该迭代的执行结果之后会检查请求是否完成。如果请求完成,请求池就会删除已完成的请求,并通知端点发送响应,返回给客户端。
- 对于新到达的请求,在当前迭代执行完毕后,它有机会开始处理(即调度器可能选择新请求作为下一个执行对象)。因为新到达的请求只需等待一次迭代,从而显著减少了排队延迟。
ORCA对于中止请求(Canceled Requests)并没有进行处理,实际上应该把这些请求会被及时从Batch中剔除并释放相应显存。

算法
下图详细描述如何在每次迭代中选择请求的算法。此算法中对KV Cache释放时机控制得不是很理想。在请求生成结束时就立即释放其K/V Cache。在多轮对话场景中,这个机制会导致冗余计算,即"上一轮对话生成K/V Cache → 释放K/V Cache显存 → 通过本轮对话的Prompt生成 之前的K/V Cache"。这样会恶化后续几轮对话的First Token Time(产生第一个Token的时延)指标。

3.1.2 选择性批处理
ORCA时代还没有Paged Attention,因此需要Selective Batching来将注意力计算从 Batching 中解耦。即,为了提高计算效率,需要想办法让引擎能够以批处理方式处理任何选定的请求集。
问题
在前面分析中,我们其实做了一个简化的假设,即所有请求序列具有相同的长度。这是因为GPU的特殊性,如果想批量执行多个请求,每个请求的执行应该包含相同的操作,且消耗形状相同的输入张量。然而,在现实中,请求序列的长度是不同的。诚然Padding+Masking的方法可以解决,但严重浪费算力和显存,对于算力和显存均有限的推理GPU是不利的。
当使用迭代级别调度时,上述挑战会愈发加剧。因为:
- 请求池中的请求可能具有不同的特征。
- prefill和decode的计算方式不同。
- prefill过程是长序列并行计算的,decode过程是token by token的。
- prefill过程不需要读取KV cache,decode过程需要读取KV cache。
- 对于prefill,各个请求的prompt长度是不一致的。
- 对于decode,不同请求的decode token的index不一样,意味着它们计算attention的mask矩阵也不一样。
- 迭代级调度方法可能导致同一个批处理中的不同请求的处理进度不一样,即输入张量的形状会因为已处理的token数量不同而不一致。
我们用上面架构图作为例子来进行分析,来看看即使对于一对请求 (xi,xj),也不能保证它们的下一次迭代可以合并、替换为批处理版本。有三种情况导致请求对不能合并批处理:
-
两个请求都处于初始化阶段,但输入token数量不同(如下图中的 x3和 x4)或者说输入张量的"长度"维度不相等,因此无法将两个请求进行批处理。
-
两个请求都处于增量阶段,但各自处理的token索引不同(如 x1和 x2)。由于每个请求处理的token索引不同,导致注意力键和值的张量形状不同,因此也不能合并批处理。
-
请求处于不同阶段:有的处于初始化阶段,有的处于增量阶段(如 x1和 x3)。由于不同阶段的迭代输入token数量不同(初始化阶段迭代并行处理所有输入token以提高效率,而增量阶段每次迭代仅处理一个token),因此无法合并批处理。
对于第二种情况,在典型的批处理机制中,每次迭代时,Transformer层都会接收一个由批中多个L,H请求输入张量拼接而成的三维输入张量B,L,H,其中B是批大小,L是一起处理的token数,H是模型的隐藏大小。
但是在下图中,"iter 1"(初始化阶段)接收形状为2,2,H的输入张量,而"iter 2"(增量阶段)接收形状为2,1,H的张量。然而,在上图中,当调度器决定对批(x1, x2, x3, x4)执行迭代时,初始化阶段请求(x3: 2,H和x4: 3,H)的输入无法合并成一个形状为B,L,H的单一张量,因为x3和x4的输入token数不同,分别为2和3。

上述关于批处理的主要问题在于,前述三种情况对应于形状不规则的输入(或状态)张量,这些张量无法合并成一个大的张量并输入到批处理操作中。因此,并非所有的请求都能在任意Iteration被Batching到一起。仅当两个选定请求处于同一阶段,且(在初始化阶段)具有相同数量的输入token或(在增量阶段)具有相同的token索引时,批处理才适用。这一限制大大降低了在实际工作负载中执行批处理的可能性,因为调度器需要同时找到两个符合批处理条件的请求。
思路
解决这些问题的一个好思路是:尽量找到这些请求计算时的共同之处,使得计算能最大化合并。对于有差异的部分再单独处理。我们先以一个transformer decode block为例,回顾一下序列要经过哪些计算。下图是decoder block的各种计算类型。可以看到,Transformer decoder block 在计算上可以看做六个操作的总和:pre-proj,attn,post-proj,ffn_ln1,ffn_ln2,others(比如 layer normalization,activation functions,residual connection)。Transformer 输出一个形状为 B, L, H 的张量。其中 B 是 batch size,L 是 input tokens length,H 是模型的 embedding size。每个 token 的 KV Cache 大小均为 1, H。

我们把上面的介绍稍作提炼,得到如下重要信息:Transformer 层中的操作可以分为两种类型: Attention 和 non-Attention,这两种模块的算子特点不同。
preproj/postproj/FFN1/FFN2:这几个模块中主要是Add、Linear、GeLU等算子,这些算子的特点是:- 不需要区分 token 来自于哪个请求。因此,虽然它们是
token-wise的,但可以使用批处理实现。 - 和输入序列长度无关。这意味着我们可以把一个batch中所有的tokens都展平成一行进行计算(维护好各自的位置向量就好),这样不同长度的输入也可以组成batch,从而进行计算。例如,上述x3和x4的输入张量可以组合成一个二维张量ΣL,H = 5,H,而不需要明确的批处理维度。
- 需要从显存读取模型权重。读取模型权重意味着我们应该尽量增大batch size,使得一次读取能就可以造福更多请求,以此减少IO次数。
- 不需要区分 token 来自于哪个请求。因此,虽然它们是
attn: 该模块的特点是:- 由于计算受各个序列的差异性影响(例如不同序列的mask矩阵不同、是否需要读取KV cache),因此需要将序列拆分开独立处理,即batch维度是重要的。而由于attn部分本身不涉及到权重读取,因此你把序列拆分开处理,也不会在这一方面上带来额外的IO开销。
- 对于注意力操作, 无论是
token-wise还是request-wise的 batching 都无法执行,这是因为 Attention 操作需要一个请求的概念来计算同一请求的 token 之间的注意力。 - 不对Attention层进行批处理对效率的影响很小,因为Attention层的操作不涉及到模型参数的重复使用,无法通过批处理来减少GPU内存读取。
方案
总结上述思路:Transformer Layer里,并非所有的算子都要求组成批次的输入具有相同的形状。基于上述思路,Orca 提出了第二点核心技术: Selective batching(选择性批处理),它不是对构成模型的所有张量操作(注意力和非注意力)都进行批处理, 而是有选择地将批处理仅应用于少数非注意力操作,即对于不同类型的请求应用于不同类型的操作来解决问题,具体如下:
- 单独处理每个注意力操作。即对于必须有相同Shape才能Batching的算子(例如Attention)会对不同的输入进行单独的计算。
- 对其他层(例如MLP层)则进行批处理。

上图展示了处理图4中描述的请求批(x1, x2, x3, x4)的选择性批处理机制。示意图描述的是,系统正在生成请求x3、x4的第1个Token(论文称为Initiation Phase),同时生成请求x1、x2的后续Token(论文称为Increment Phase)。因为产生第1个Token后才会有K/V Cache,所以从Attention K/V Manager那里看有没有request对应的K/V cache,就能分辨出每个request处于哪个phase。具体机制如下:
- 应用批处理。
- 该批有7个输入token要处理,因此我们将输入张量的形状设置为7,H,7,H的意义是:给定形状为
[(s1, h), (s2, h), ...]的输入,我们将它们堆叠成一个形状为(sum(si), h)的大矩阵。 - 对这个堆叠矩阵应用Linear这个非注意力操作。Linear的计算不涉及Token之间的交互,因此将输入的Batch维度和Seq维度Reshape成1个维度,即可完成Linear的Batch计算。
- 该批有7个输入token要处理,因此我们将输入张量的形状设置为7,H,7,H的意义是:给定形状为
- 将密集层的结果分割回
[(s1, h), (s2, h), ...]。在注意力操作之前,我们插入一个拆分(split)操作,目的是把batch中的每个请求的张量区分出来。(注:有的读者可能会疑惑为什么Linear的输入和输出维度分别是7,H和7,3H,为什么升维了?这是因为通过矩阵拼接可以实现用一个Linear同时计算出QKV,即输出包含了有H维的Q、H维的K和H维的V,合计3H维)。 - 对拆分后的张量中的每个请求分别运行注意力操作。Attention的计算涉及Token之间的交互,OCRA的操作是:将输入按Batch维Split,每个样本分别计算Attention。
- 然后,通过合并操作将注意力操作的输出合并回形状为7,H的张量,以恢复对其他操作的批处理功能。
虽然ORCA是把Prefill和decode阶段合并在一起处理,但其实它们的计算模式差很多,分开做能够更好地做优化(例如计算Linear时,Initiation Phase的计算Kernel更接近GEMM,Increment Phase的计算Kernel更接近GEMV)
后续有的工作就是将Initiation Phase的请求批量做完计算后,再这些请求与已在decode阶段的请求合并做批量计算,有的框架通过超参数来管理这个问题:等待已服务比和等待结束序列标记的请求比(waiting_served_ratio)。
3.1.3 流水线并行
另外,ORCA的调度器实现了引擎中工作线程对多个批次的流水线执行。
ORCA的调度器使引擎中worker的执行能够跨多个批次进行流水线处理。若当前已调度批次数n_scheduled达到工作线程数n_workers(算法1的第9-10行)时,调度器就不再等待。通过这种方式,调度器保持引擎中并发运行的批次数为n_workers,这意味着引擎中的每个工作线程都在处理一个批次,而不会处于空闲状态。
下图展示了3个ORCA工作线程的执行流水线,最大批次大小为2。假设请求A先于B到达,B先于C到达,以此类推。首先,调度器根据到达时间选择请求A和B,并调度引擎来处理包含A和B的批次(我们称之为AB批次),其中Worker1、Worker2和Worker3依次处理该批次。只有在调度器注入另外两个批次CD和EF之后,调度器才等待AB批次返回。一旦AB批次返回,请求A和B会再次被选中并调度,因为它们是请求池中最早到达的请求。

3.2 Sarathi-Serve
3.2.1 挑战
ORCA虽然很优秀,但是依然存在两个问题:GPU利用率不高,流水线依然可能导致气泡问题。
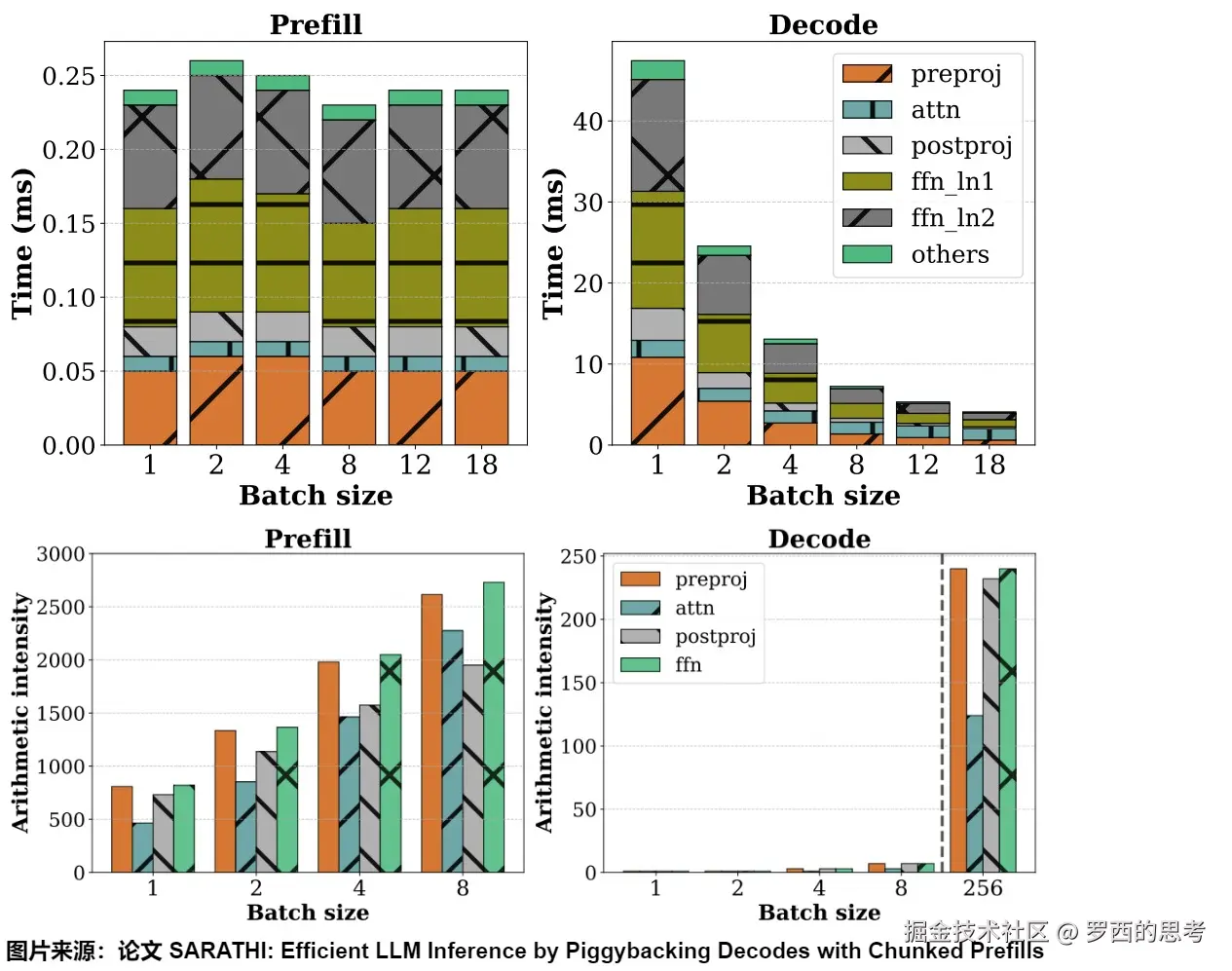
GPU利用率
我们来看sarathi-serve做的一个实验。左右两图分别刻画了在不同的batch size下,prefill和decode阶段的处理时间和计算强度。可以观察到如下:
- prefill:提升batch size时,速度的变化不明显。即使在批处理大小为1的情况下也会使GPU计算饱和,并导致跨批处理大小的每个token时间几乎恒定。
- decode:提升batch size时,处理速度降低的线性趋势非常明显。这是因为decode是memory-bound的,decode阶段的算力严重打不满,所以当增大batch size时,不仅能多利用算力,也能把多次读取合并成一次读取,降低处理速度。当batch size达到一定阈值时,速度的降低幅度也达到瓶颈。着批大小的增加,用于解码的线性算子的增量成本几乎为零。注意力成本不会从批处理大小中受益,因为它是内存受限的。
流水线
虽然Orca已经能在一定程度上改善pp气泡问题了,但是它仍然可能导致气泡问题,我们以下图为例:

观察到图中一共有3种类型的bubble:
PB1: 因为两个连续的微批中,prefill序列长度不一致而产生的bubble。PB2: 因为prefill和decode阶段计算时间的差异而产生的bubble。PB3: 不同微批的decode计算时间差异而产生的bubble,这是因为不同micro-batch在做decode时,要读取的KV cache的长度不一致,这也导致了在读取数据上所花费的时间不一致。
3.2.2 原因分析
产生以上问题的原因在于:ORCA组装batching的过程比较随机,一个batch中做prefill和做decode的请求有多少条是不确定的,只是大体按照先来后到的原则做动态组装。这就造成了一些问题。
- 如果一个batch中prefill的请求非常多,或者遇到非常长的 system prompts,那么prefill tokens会占据大量计算资源,使得整个batch变成compute-bound。
- 如果一个batch中做decode的请求非常多(比如当所有的请求都没做完推理时,或者请求队列中没有新序列可以调度时),这个batch就可能变成memory-bound的。
因此,我们需要一个机制来保证每个batch中prefill和decode请求的均衡程度。或者说,假设一个batch中能够容纳的token(即达到GPU计算能力的上限)是确定的,我们要找到一个方案来按照一定比例去分配做prefill的tokens和做decode的tokens,通过重叠这两种请求来让这个batch做到性能最大化,解决吞吐量和延迟之间的权衡。在这种思路下,prefill的序列是必定要拆开的,这就是Sarathi提出来的Chunked-prefills(分块预填充)。
3.2.3 Chunked-prefills
Chunked-prefills方案的核心思想是:将长序列的预填充请求拆分为几乎相等大小的小块,然后构建了由prefill小块和decode组成的混合batch。或者说,Chunked Prefill策略通过将不同长度的prompts拆分成长度一致的chunks来进行prefill,以避免长prompt阻塞其他请求,同时利用这些chunks的间隙进行decode的插入/捎带(piggyback)操作,从而减少延迟并提高整体的吞吐。
decode 阶段的开销不仅来自从 GPU 内存中获取 KV Cache,还包括提取模型参数。而通过这种 piggyback 方法,decode 阶段能够重用 prefill 时已提取的模型参数,几乎将 decode 阶段从一个以内存为主的操作转变为一个计算为主的操作。因此,这样构建的混合批次具有近乎均匀的计算需求(而且增加了计算密集性),使我们能够创建平衡的微批处理调度,缓解了迭代之间的不平衡,导致GPU的管道气泡最小化,提高了GPU的利用率。也最小化了计算新预填充对正在进行的解码的 TBT(Time-Between-Tokens)的影响,从而实现了高吞吐量和低 TBT 延迟。
对比
下图给出了传统方案,ORCA方案和Sarathi方案的时间线。
- 默认机制(下图(a))仅在请求级别进行批处理。在这种情况下,就绪请求被分批处理,但是只有当正在处理的批次的所有请求都完成之前,调度器才会接收新的批次。由于请求可能具有较长的token生成阶段,这可能会导致请求在其间到达的等待时间较长,从而导致高TTFT和高E2E延迟。
- 连续批处理(下图(b))是在默认机制上的优化。在这种情况下,调度决策是在模型的每次前向传递之前做出的。然而,任何给定的批处理要么只包含处于prompt(提示)阶段的请求,要么只包含decode阶段的请求。prompt阶段被认为更重要,因为它会影响TTFT。因此,等待的prompt请求可以抢占decode阶段。虽然这会导致TTFT缩短,但它会大大增加TBT,从而增加E2E延迟。
- 混合批处理(下图(c))就是Sarathi方案。通过这种批处理,在每次前向传播时都会做出调度决策,prefill和decode阶段可以一起运行。这减少了对TBT的影响,但并没有完全消除这种影响,因为与prompt阶段一起调度的decode阶段将经历更长的运行时间。

注意:这里的ORCA指的是后续的类ORCA优化方案。
实现
要使用预填充来附带解码,我们需要注意两件事。
- 首先,我们需要确定可以携带的解码的最大可能批量大小,并确定构成预填充块的预填充token的数量。
- 其次,为了真正利用混合批的GPU饱和预填充计算来提高解码效率,我们需要将预填充块和批解码的线性运算计算融合到一个操作中。
另外,动态分割的关键是将较长的预填充分成更小的块(chunk),从而通过将预填充块与多个解码任务组合形成批处理,并充分调动 GPU,这个过程称为捎带确认(piggybacking)。
要使用预填充来附带解码,我们需要注意两件事。首先,我们需要确定可以携带的解码的最大可能批量大小,并确定构成预填充块的预填充token的数量。其次,为了真正利用混合批的GPU饱和预填充计算来提高解码效率,我们需要将预填充块和批解码的线性运算计算融合到一个操作中。
该实现中很重要的一点就是如何确定chunk的大小,Sarathi提供了"固定"和"动态"两种chunk size策略。
- 固定策略:该策略会依据硬件和profilling实验计算出来一个可以最大限度把GPU利用起来的单batch中的tokens数量。这个是batch的token总配额,其在运行过程中会尽量保持不变,而prefill tokens数量会随着decode tokens的增减而变化,但是因为decode tokens数量一般也不多,所以prefill tokens数量和整体batch tokens配额也不会相差很多。
- 动态策略:该策略希望对于一个请求,其prefill tokens的数量能随着迭代次数的增加而减少。这是因为如果一个prompt特别长,它在每次迭代中都会占据很多计算资源,从而历史累积的decode序列和新来的请求受到影响。因此对于这种新进入batch的长序列请求,Sarathi会在开始多配置一些prefill tokens额度,后续随着迭代次数的增加,递减这个配额,降低它对其它迭代的影响。
两阶段流水线的chunked-prefills运作流程如下:

具体步骤是:
-
依据GPU的性能来确定每个batch中最多能处理的tokens数量。对应上图标号1。图上有4个请求(A,B,C,D),被分别拆分成小块(chunk)。
-
当整个系统刚启动时,batch中只有做prefill的序列。系统会依据整个prefill的长度预先分配好KV cache空间,这确保在这条prefill的后续迭代中,一定有充足的KV Cache空间。对应上图标号2。
-
往batch中添加需要做decode的序列,直到KV Cache空间不足(因为decode操作需要有对应的KV Cache)。对应上图标号3.1。同时也要根据这个batch中剩余的tokens预算,对需要做prefill的序列做chunk切割,把对应的prefill tokens添加进batch中。对应上图标号3.2。
比如上图中产生了 Ad1这个需要做decode的迭代。为了进一步处理 Ad1,此时需要在A所在batch中分配1 token的配额给 Ad1。同时也要去等待队列中按FCFS(先到先服务)的原则找出请求C,依据配额比例把C切分成 Cp1和 Cp2,然后把 Cp1放到batch中。
-
推理的每一步后,scheduler都会重新组建batch。因为Sarathi-Serve依然采用的是iteration-level schedules。
我们针对上图,再次看看当A做完prefill之后,Orca和Sarathi的区别。
- Orca在硬件资源允许的情况下,会让CD做prefill,AB继续做decode。但由于decode和prefill的完整序列绑定,也使得整个decode的计算时间变长了。所以这其实也算是一种decode暂停。
- sarathi-serve也允许decode和prefill一起做,但是它通过合理控制每个batch中prefill tokens的数量,使得decode阶段几乎没有延迟。这样即保了延迟,又保了吞吐。
分析
在 Linear 层,Decode 和 Prefil可以一起执行,在 Attention 阶段分开执行,不过在很多场景下,Attention 时间占比比较小。这样就可以将 Decode 和 Prefill 一起变成计算密集型任务。此时 Decode 应该是凑批越大越好。但是同时带来的问题就是,Decode 的时延会比较高。所以需要在吞吐和时延之间有个平衡。在 Prefill 上,达到 GPU 计算瓶颈之后,更长的序列会使得 Prefill 时延陡增,所以在遇到这个拐点之后,Perfill 吞吐不再增加。这个值就是我们需要找到的 Chunk Size 值,Decode + Prefill 的总 Token Size 应该小于等于这个 Chunk Size,但是这个 Chunk Size 不一定很好寻找。而且 Decode 和 Prefill 的请求密度,不一定能达到最完美的比例。最完美的比例就是:在 Prefill 的每一轮执行中,Decode 都能凑批执行。如果 Decode 的密度高,那么可能 Decode 会单独运行。如果 Prefill 密度高,那么 Prefill 会单独运行。
另外,做了 chunked prefill 后,prefill 的开销会略微增大。因为在计算后续 chunk 时,需要把这些 chunk' 对应的 KV 不断从GPU memory 中读到 kernel 中。不做 chunked prefill 时,这些 KV 始终在 kernel中。做chunked prefill的好处是,采用 piggyback 的方式捎带 decode 到 chunk 的 bubble 后,可以直接复用 prefill 阶段加载的 模型参数。这几乎可以让 decode 从一个 memory bound 操作转换为一个 compute bound 操作。
3.2.4 chunked-prefills VS 分离式推理架构
我们可以看到,在使用chunked-prefills的策略下,通过合理划分prefill tokens和decode tokens比例,似乎也能同时保全TTFT和TPOT/TBT,利用好GPU。那么在这样的前提下,分离式推理架构还有什么优势呢?
其实,由于 Chunked Prefill 的提出,Prefill 和 Decode 节点的边界已经模糊了起来。Mooncake 论文就指出,设计一个单独的弹性预填充池的必要性和最佳实践仍然存在争议。随着分块预填充的引入,这种分离是否仍然必要?因为 Chunked Prefill 有两个明显的好处:1)没有分离,所有节点都被平等对待,使调度更容易;2) 在解码批中嵌入分块预填充可以提高解码批的计算强度,从而获得更好的MFU。
Mooncake继续保留了分离架构(使用独立的 Prefill 节点)。只有当请求可以在不分块(比如特别短的 prompt,可以直接一次性加入到 decode 的 continues batch 里提升 MFU)、且不影响TBT SLO的情况下转发时,请求的预填充才会内联到解码批中。这一决定有两个主要原因:1)预填充节点需要不同的跨节点并行设置来处理长上下文。2)它提供了一个保存VRAM的独特机会。

另外也许还有如下几点原因:
- 分块预填充会导致预填充的计算开销,因此选择明显低于 GPU 饱和点的块大小会延长预填充任务的执行时间。
- 仍然存在prefill阶段无法最大化MFU的可能。因为在chunk-prefill中,我们只是用profiling估算出在特定设备上一个batch的最大tokens配额,这些tokens包括prefill和decode。这个size是对整体的,而不是单独对prefill或decode的。而且如果序列长度除不尽tiles尺寸,则又会产生额外的计算开销。
- 即使块大小被优化到几乎最大化 GPU 使用率,分块预填充也会显著增加预填充任务的内存访问量,因为需要将 KV Cache 从 GPU 的 HBM 加载到 SRAM 以用于每个后续块。而且长序列可能会持久地占据着KV cache的存储空间以及gpu的计算资源。
至于 TPOT,将预填充和解码在批次中合并实际上会降低所有这些解码任务的速度。
总之,分块预填充可能有助于最大化整体吞吐量,但由于动态分割无法完全解耦预填充和解码操作,会导致资源争用以及 TTFT 与 TPOT 之间的妥协。当应用程序无法在 TTFT 和 TPOT 之间进行权衡,而是要同时遵守这两者时,解耦就成为更好的选择。
所以,基于以上这些对chunked-prefills策略缺陷的猜想,或许使用分离式架构,对prefill阶段独立开发一套策略,可能可以更加针对性地解决以上问题。当然,这也取决于各策略的具体实现、业务场景和真实的实验效果。
我们接下来就看看分离式推理架构。
注:笔者并非说明分离式推理架构就一定比融合式更好,而是各有优劣。比如,论文"Injecting Adrenaline into LLM Serving: Boosting Resource Utilization and Throughput via Attention Disaggregation"就指出了LLM服务系统中的PD分离导致了严重的GPU资源浪费的问题。具体来说,运行计算密集型Prefill阶段的GPU的HBM容量和带宽的利用率较低。内存密集型的Decode阶段则面临算力资源利用率低的问题。该论文也给出了改进方案Adrenaline。
0x04 分离方式
4.1 总体思路
分离方案背后的逻辑很简单:将预填充(compute-bound)和解码(memory-bound)解耦到不同的 GPU 中,使得不管是在硬件分配还是在并行策略上,这两者都能朝着独立的方向优化,分别处理TTFT和TPOT/TBT,同时提升吞吐和降低延迟。而无需再像合并式推理架构那样,总是在这两者之间做trade off,这自然解决了上述两个问题:
- 预填充和解码之间没有干扰,使得两个阶段都能更快地达到各自的 SLO。Prefill 和 Decode 不会互相影响 TTFT 和 TPOT。
- 资源分配和并行策略解耦,从而通过为预填充和解码量身定制资源分配(GPUs 数量)、并行性策略和优化策略来独立地扩展每个阶段,借此确保最大化每个GPU的吞吐量。比如,对于长序列可以多配置些GPU,短序列少配置一些GPU。

我们以分离式架构为引子,讨论了解耦prefill和decode过程带来的好处:
4.1.1 框架
那分离式的框架长什么样呢?我们直接来看DistServe提供的一张架构简图,该图展示了请求在这种解耦系统中被处理的方式。在这种架构中,prefill和decode不再共享一块/一群gpu,而是被分布在不同的GPU上,这些GPU分别属于不同的实例(Prefill instance和Decoding instance)。一个prefill isntance中包含一个完整的模型,它可能占据1或多块gpu。decode instance也是类似配置,只是它与prefill实例不再共享gpu。这种服务架构的处理流程主要分为以下三步:
- Prefill:当一个请求进入系统时,它首先被发送到一个prefill isntance。Prefill isntance对新到达的请求执行 Prefill 运算,得到第一个 tokens 以及 prompt 对应的 KVCache;
- Migrate:将 Prefill 后的请求、对应的 KVCache 迁移至 Decode isntance;
- Decode: Decode isntance对迁移的请求循环执行 Decode 运算。一旦完成生成,请求就离开了系统。
三个阶段综合起来是一个流水线并行。把不同时期的 GPU 放在不同的分区去用,然后数据从prefill到KV Cache,再到decode。KV Cache用来传递中间结果。如果从大一统的角度看(把 KVCache 当做内存管理),这就是一个分布式系统。

从直觉上看,分离式架构相比于合并式架构,多加载了模型副本(耗显存),同时还涉及到gpu间的KV Cache传输(耗时间),似乎比合并式架构更差。那么为何人们还要采用这种架构呢?接下来,我们就来回答这个问题。
4.1.2 论证
我们接下来从不同角度来看看研究人员是如何论证的。我们首先看看DistServe和TetriInfer的观察和洞见,然后再从KV Cache角度进行分析。
DistServe
下图说明了在使用现有系统提供服务时,随着请求率的增加,P90(满足90%的SLO达成率) TTFT和TPOT如何变化。具体实验用1张A100 80G的gpu运行13B LLM,input_length = 512, output_length = 64。图中:
- 横轴表示每秒到达这块gpu上的请求数量,记为rps(requests per second)
- 蓝线采用PD合并的架构做实验。如果我们同时达到设定好的TTFT SLO和TPOT SLO,我们的最大rps = 1.6,我们也记这个指标为goodput。
- 黄线:只让GPU处理prefill的请求时,它的goodput=5.6。
- 绿线:只让GPU处理decode的请求时,它的goodput=10。
可以发现,一张卡只做prefill或者只做decode的goodput,都要比它既做prefill又做decode的goodput要高。所以我们可以估算:如果为预填充分配2个GPU和解码分配1个GPU,我们可以有效地提供模型的总体吞吐量(goodput )为10 rps,或者每个GPU的平均goodput 为3.3 rps,比合并式goodput(值为1.6)高2.1倍。
再换一个角度粗糙地看:分离式架构中,我们三张卡承受起了10 reqs/s的流量;而合并式架构中由于单卡流量承受为1.6 reqs/s,所以我们需要6张卡才能承受起10 reqs/s的流量。这说明为了满足延迟要求,合并式架构必须过度配置计算资源。

以上实验说明了把prefill和decode放在一起会导致强烈的互相干扰,而且会耦合它们的资源分配,并阻止实现更适合满足每个阶段特定延迟要求的不同并行性策略。
TetriInfer
与LLM交互的方式有很多种,从简单的聊天到更复杂的下游任务,如文档摘要、内容创建等。这些交互方式的性质往往各不相同。比如摘要任务具有较长的输入提示和较短的生成token,而上下文创建任务则相反。不同下游任务的token长度可以相差两个数量级以上。为了研究这些推理请求在同时运行时的性能如何,TetriInfer作者将推理请求分为两个维度(预填充和解码长度)和一个属性(轻量级或重量级),从而得到四种不同的请求类型:重量级预填充、轻量级预填充、重量级解码和轻量级解码。这里,重量级预填充指的是较长的token长度,而轻量级预填充指的是较短的token长度。轻量级解码是指生成少量token的解码请求,例如少于100个。重量级解码是指生成大量token的解码请求,例如大于512个token。
该论文混合了不同长度的 prefill 和 decode 请求,进行了广泛的测试,观察到所有组合都存在严重的互相干扰。下图展示了预填充和预填充,预填充和解码,解码和解码这几种组合的效果。
-
混合预填充请求。当批次中的token总数大于加速器饱和阈值时,再运行预填充请求会导致严重的减速,因为我们在已经饱和的硬件上继续添加计算密集型作业。
-
预填充和解码。混合运行预填充和解码请求会对两者都产生负面影响,因为我们同时运行批处理和延迟关键的作业。即使只有一个其他重量级预填充请求在同一连续批次中,其解码延迟也会增加5倍!一旦共运行的轻量级解码请求超过7个,prefill的延迟就会增加。两者的延迟大约都增加了2.5倍。
-
解码和解码(混合解码请求)。混合解码请求会导致吞吐量下降,因为我们不了解内存带宽和容量使用情况,从而导致争用和排队阻塞。而且,与全部轻量级解码请求的批次相比,增加重量级解码请求可能严重影响吞吐量和延迟。

根本原因很简单:当前的LLM系统对LLM预填充和解码阶段所展示的不同特征一无所知。预填充阶段类似于计算密集型的批处理作业,而解码阶段类似于内存密集型、延迟关键的任务。把两者混合推理,会让彼此干扰。
KV Cache
读者可能会有疑问:因为解耦,所以需要在预填充和解码 GPU 之间传输中间状态(即 KV Cache),这看起来是一种瓶颈,因为当模型过大的时候,可能单机无法完全放下一个 Prefill Worker 和 Decode Worker。对于这种模型,将KV Cache从预填充转移到解码实例会产生显著的开销,迁移耗时则会大幅增加。
我们接下来利用DistServe进行分析。针对KV Cache传输问题,为了避免迁移开销上升,需要合理放置 Worker。DistServe作者通过精心放置预填充和解码工作器来利用高带宽网络来有效地隐藏 KV Cache 传输开销。具体策略是:因为KVCache 按层存储,所以可以把模型按层划分多段,每段放到不同机器,不同段的模型采用 PP,然后再对同一段的模型进行单机的模型并行策略的搜索。这样可以保证:
- 跨机传输仅出现在 PP 层间。
- Prefill 和 Decode Worker 相同层的 KVCache 在同一个机器内,Prefill 和 Decode Worker之间可以使用节点内NVLINK带宽进行传输。
从而显著减少传输延迟。并且当模型越大、序列越长、多卡通信设备带宽越高,KVCache 迁移开销占比越低。
下图左:使用DistServe在ShareGPT数据集上提供OPT-175B时的延迟细分。右:三种OPT模型KV Cache传输时间的CDF效果。可以看到传输问题已经得到了极大的缓解。通过适当的放置(placement),KV Cache 传输开销可以有效地最小化,甚至低于一个解码步数的时间。

分别配置
Prefill 和 Decode 的特性很不同,所以参数配置上很多都是不同的。例如凑批策略,量化类型,TP 大小,PP 大小,任务超时时间,重试时间,显存申请策略,RDMA 软硬件队列大小,是否可回退执行等。我们用阿里RTP-LLM的经验来看看如何配置。
- batch size。分离之后,Prefill 本身的 Batch Size 仍然不会很大。为了充分发挥 Decode 的能力,我们应该配置更多的 Prefill,减少 Decode 实例个数,使得 Decode 能进行大 Batch 推理。
- 资源分配:Prefill 应该选择计算能力强的卡型,Decode 应该着重选择显存大的卡型。
- 量化方案:可以在 Prefill 机器部署 FP16 / W8A8 的模型文件,来获得相对不错的 Prefill 性能;而 Decode 机器则可以自由地选择 W4A16 / W4A8 的方案,来获得整体的更优性能。
我们接下来利用几篇论文来继续学习。
- DistServe:将预填充和解码计算分配至不同的 GPU,从而消除了二者之间的干扰。针对应用程序的总时延和每个 Token 运行时间的需求,DistServe 为每个阶段量身定制了资源分配和并行策略的优化方案。此外,DistServe 还根据服务集群的带宽来确定如何部署这两个阶段,以最小化由任务分解引起的通信。
- SplitWise:特点是分布式调度策略、PD分离、分层KV Cache传输,并且增设了第三个机器池,专门用于处理 Prefill 和 Decode 阶段的混合批处理,并且能够根据实时计算需求灵活调整其规模。
- MemServe:用统一的分布式视角对KV Cache进行管理。
- TetriInfer:结合了分块预填充和两阶段分离,以及预测性的两阶段调度算法来优化资源利用率,且仅针对 prefill 进行分块处理。SplitWise、DistServe 和 TetriInfer的静态并行性和分区策略并不灵活,无法处理动态工作负载。
- Mooncake:构建了以 KVCache 存储为中心、基于RDMA的 P-D 分离调度集群和推理架构,形成了 Prefill/Decode Pool 以及分布式异构介质 KVCache Pool;融合了缓存感知、负载均衡和以服务水平目标(SLO)为导向的决策机制。
4.2 DistServe
DistServe有如下几个特色:
- 将预填充和解码计算分配给不同的GPU,从而消除了二者之间的干扰。
- 根据应用程序的TTFT和TPOT要求,DistServe为每个阶段分别定制了资源分配和并行策略的共同优化策略。
- 根据服务集群的带宽来确定如何部署这两个阶段,以最小化由任务分解引起的通信。
4.2.1 分析
我们首先看看预填充和解码对于并行策略的述求。
并行划分
常见的并行技术如下:
- 数据并行:权重复制,输入数据分布在不同机器上
- 模型并行:将权重进行切分,根据权重切分的方式,输入数据有时候也要一起进行切分
- 流水线并行:把不同的子图放在不同的设备上运行,一起形成流水线,这需要对输入数据切分batch
Alpa提出了另外一个划分维度,即算子间、算子内并行划分方法,通过"是否切分了张量的维度"来区分不同的并行。
- 算子内并行:切分了tensor维度的并行方式,包括数据并行和算子并行。
- 算子间并行:不切分tensor,只是把子图进行不同的摆放分布,包括流水线并行。

prefill实例
针对prefill实例,我们的优化目标是使用最少的资源满足服务的TTFT延迟要求。
预填充步骤通常是计算密集型的。一旦GPU变为计算限制,批次中加入再多请求也不会提高GPU使用率,而是成比例地延长批处理的总处理时间,无意中延迟了所有的请求。对于预填充实例,需要事先对LLM和GPU进行分析,以确定关键的输入长度阈值。超过该阈值,预填充阶段将变为计算限制。只有当计划请求的输入长度低于阈值时,才应考虑在批处理中添加更多的请求。
因此,适合prefill实例的并行策略是:在较低的rate(req/s)下,执行时间是主要因素,因此,算子内并行(intra-op)更高效,而随着到达率的增加,排队延迟变得更加显著,此时算子间并行(inter-op)更优越。
decode实例
对于解码实例,我们的优化目标是以最小的计算资源满足应用的TPOT需求。
由于单个解码作业严重受带宽限制,批处理是避免低GPU利用率(因此高每个GPU的吞吐量)的关键。disaggregation(解聚)可以将多个预填充实例分配给单个解码实例。这种方法允许在专用GPU上积累更大的解码阶段批处理大小,而不会牺牲TPOT。在disaggregation之后,解码的批处理大小可能受到GPU内存容量的限制,因为需要为所有活动请求维护KV Cache。
intra-op减少了延迟,但随着通信和分区后利用率的降低而递减,而inter-op几乎可以线性地扩展吞吐量。因此适合decode实例的并行策略是:当TPOT SLO要求严格时,intra-op对于减少TPOT以满足延迟目标至关重要。而inter-op更适合线性增加吞吐量。
4.2.2 优化方向
因为prefill和decode的不同特点,使得在分离式框架下,有不同的优化方向。下表第一列是prefill的特点,第二列是decode的特点,第三列是优化方向。比如针对存储,我们可以使用不同型号的硬件;针对batch策略,我们对prefill和decode使用不同的策略,分别优化。
| prefill | decode | 优化方向 |
|---|---|---|
| 算完KV Cache,发给decode阶段后,可以使用策略来清除KV Cache。 | 逐token生成过程中频繁读取KV Cache,需要尽可能保存KV Cache。 | 计算和存储独立优化 |
| 因为prefill阶段是compute-bound,故随着batch size的增加,吞吐量的增长趋势趋于平缓。 | 因为decode阶段是memory-bound,故随着batch size的增加,吞吐量的增长趋势越来越显著。提升batch size就能提升计算强度,进而提升吞吐量。 | batch策略独立优化 |
| 在不同条件下,对并行方式有倾向性:rate (req/s)较小时,适合TP;rate较大时,适合PP。 | 随GPU数量的增加,PP方式可以产生更高吞吐量;TP方式可以产生更低延迟(处理单个请求更快)。 | 并行策略独立优化 |
因此,在给定模型、工作负载特性、延迟要求和SLO达成目标下,DistServe需要确定:
- 预填充和解码实例的并行性策略
- 部署每个实例类型的数量
- 如何将它们放置在物理集群上
终极目标是找到最大化每个GPU吞吐量的配置策略。
4.2.3 算法
接下来我们看看DistServe如何搜索 Prefill、Decode 最优模型并行配置。
在给定不同的集群设置的情况下,一个关键的设计考虑因素是管理分解的预填充和解码阶段之间的通信。DistServe使用了两种算法:一种用于具有高速跨节点网络的集群,另一种用于缺乏此类基础设施的环境,后者引入了额外的约束。总体思路是:在约束条件基础上,对于给定现有的 GPU 数量等硬件资源,罗列出TP和PP的可能性。然后用模型器来对每个可能性进行计算,得出该可能性下每张卡的 Goodput,选择可以让每个 Worker 最大化 Goodput 的 TP、PP 配置。
高节点亲和力的集群上如何放置
在具有高节点亲和力的集群上通常装有Infiniband,KV Cache在节点之间的传输开销可以忽略不计,DistServe可以在没有约束的情况下有效地部署预填充和解码实例。我们提出了一个双层放置算法用于这种情况:首先优化预填充和解码实例的并行性配置,以实现阶段级别的最大每个GPU吞吐量;然后,我们使用复制来匹配整体流量速率。
算法1概述了该过程。我们列举了在集群容量限制下的,预填充和解码实例的所有可行并行配置例如,对于特定的预填充阶段配置,我们使用simu_prefill来模拟并找到它们的最大吞吐量(类似于使用simu_decode进行解码)。在确定了预填充和解码实例的最佳并行配置后,我们根据它们的吞吐量来复制它们,以实现用户所需的总体流量率。

低节点亲和力集群的放置
上面的算法假设我们可以将预填充和解码放置在集群的任意两个节点之间,并且KV Cache传输利用了高带宽。然而,在许多真实的集群中,节点内的GPU通过高带宽NVLINK进行访问,而GPU的带宽又很有限。接下来,论文将开发一种算法来解决这个约束。
算法的关键是:中间状态的传输仅发生在预填充和解码实例的相应层之间。算法具体如下:
-
我们首先枚举层间并行性来获取所有可能的实例段。利用层间并行性,我们将层分组为阶段,并将每个实例划分为段,称为实例段,每个段维护一个特定的层间阶段。通过将同一阶段的预填充和解码段放置在同一节点上,我们强制中间状态的传输只通过NVLINK进行。但是对于大型模型,在一个8-GPU节点上可能无法承载甚至一个预填充和解码实例对。我们将这作为额外的放置约束,并与模型并行性一起进行优化。
-
鉴于每个节点通常只有8个GPU的限制,对于每个段,我们通过调用get_intra_node_configs来枚举所有可能的节点内配置。
-
然后,我们使用模拟器找到最佳配置并复制它以满足目标流量率。

4.3 SplitWise
SplitWise和DistServe思路类似,具体如下。
-
阶段识别:将LLM推理请求分为两个阶段,prompt计算和token生成。不同阶段放在不同机器上执行。
-
硬件适配:为每个阶段选择最适合的硬件,优化资源使用。
-
集群设计:设计了同质和异质集群,针对吞吐量、成本和功耗进行优化。
-
调度策略:使用两级调度系统,包括集群级调度器(CLS)和机器级调度器(MLS),以优化请求分配和机器资源管理。
因此我们只看看其特殊之处,或者说只看我们在DistServe中没有介绍的地方,藉此补齐。
4.3.1 调度方案
当到达请求的 prompt 长度有差异性的时候,预填充和解码就会出现压力的不均衡问题。因为整体的吞吐取决于 P 和 D 的全局资源利用,当 P 过载但 D 闲置,或者 P 闲置但 D 过载的时候,成本和性能都不是最优的。所以就需要考虑在 P 和 D 之间做负载均衡,要么从整个节点层面直接切换 P 和 D 的角色,要么 P 和 D 节点能够承担一些混杂的请求,比如通过 chunked prefill。
首先我们来看一下作者给出了什么样的解决方案。下图展现了SplitWise的整体架构图,
- 首先,架构图上有三个资源池,分别是Prompt Pool,Token Pool和Mixed Pool。在Prompt Pool中只做Prefill阶段,Token Pool中只做Decode阶段,实现了Prefill和Decode的分离部署。在Mixed Pool中以合并部署的方式执行Prefill和Decode混合的Batch,当请求负载变化剧烈、实例来不及伸缩或角色转换时,由Mixed Pool来执行混合的Batch。
- 其次,架构图上还有两个级别的调度器,分别是cluster-level scheduler (CLS)和machine-level scheduler (MLS) 。集群级调度程序(图上标号1)负责将传入的请求路由到特定的机器并重新分配机器。机器级调度程序(图上标号2)维护待处理队列并管理每个机器上的请求批处理。

集群级调度
集群级调度程序(图上标号1)负责将传入的请求路由到特定的机器并重新分配机器。主要功能如下:
- 请求路由。CLS针对请求采用"加入最短队列"的方法(Join the Shortest Queue (JSQ))的路由策略进行调度。在请求来的时候,CLS就决定后续要执行Prefill和Decode的实例。每台机器向CLS报告其内存容量或待处理队列的任何变化。
- 机器管理。CLS主要维护两个机器池:即时机器池和token机器池。Splitwise根据输入/输出token分布和预期负载(即每秒请求数)将机器初始分配给一个池。如果这些值与初始假设相差较大,Splitwise会对机器进行粗粒度重新分配,并在即时机器池和token机器池之间移动机器。
- 混合机器池。为了满足SLO并避免在负载较高时出现性能断崖,Splitwise维护一个特殊的混合池,混合池是一个中间缓冲。提示池或token池中的机器可以动态地移入和移出混合池,混合池根据请求速率和输入/输出token的分布动态增长和收缩,而且没有明显的池切换延迟。如果CLS尝试使用JSQ为请求分配即时机器和token机器,并发现所选机器的队列超过阈值,则会在混合池中寻找目标机器。混合池中的机器与非Splitwise机器完全相同,采用混合批处理方式运行。一旦混合请求队列被处理完毕,CLS会将机器过渡回其原始池。例如,当队列过长时,我们可以将即时机器移入混合池以运行token;一旦机器完成运行token,我们将机器过渡回即时池。
机器级调度(Cluster-level scheduling)
机器级调度程序(图上标号2)在每台机器上运行,负责跟踪GPU内存利用率,维护待处理队列,选择每次迭代的批量大小和批量请求,并向CLS报告相关状态。
-
Prompt 机器(Prompt machines)。MLS使用先到先服务(FCFS)调度算法来调度请求。因为token数目过了一定阈值之后,吞吐量开始下降。因此,MLS限制了将多个即时请求批量处理到总共2048个token。这是一个可配置的值,对于不同的模型或硬件可能会有所不同。
-
token机器(Token machines)。MLS使用FCFS调度算法尽可能地调度token和批量处理。token生成吞吐量随着批量大小的增加而增加,直到机器的内存耗尽。因此,当机器接近内存耗尽时,MLS会开始把token放到队列中。
-
混合机器(Mixed machines)。为了满足TTFT的SLO,MLS需要优先运行即时请求,并立即调度任何新的即时请求进入待处理队列。如果机器正在运行decode阶段并且没有容量,MLS将抢占token。为了避免由于抢占而导致decode阶段饥饿,我们增加较老token的优先级,并限制每个token可以进行的抢占次数。
4.3.2 KV Cache传输
在Splitwise中,我们需要将KV Cache从prompt机传输到token机以完成推理。KV Cache是在请求的提示阶段生成的,并在token生成阶段不断增长。因此作者提出,他们给出的这种分离架构的方案引入的最大开销就是把KV Cache从Prefill阶段迁移到Decode阶段的开销。这种传输延迟是与Splitwise相关的主要开销。在本节中,我们将讨论KVcache传输的影响以及如何优化它。

将活跃KV Cache从预填到解码实例的传输有两种方式:按层或按请求。
-
按请求方法是在预填阶段完成后传输KV Cache。上图左侧使用的是未经优化的以串行方式运行的线性KV Cache传输,单个请求批次所经历的时间就包括Prompt时间,等待KV Cache传输的时间和生成Token的时间。KV Cache传输仅在即时阶段完成且生成第一个token后才开始。此外,它需要在下一个输出token可以生成之前完成。这直接影响了推理的最大TBT和端到端延迟。传输所需的时间取决于KV Cache的大小(与即时token数量成正比)和即时机器与token机器之间的互连带宽。即使在机器之间使用快速的InfiniBand连接,对于大型即时大小,KV Cache的开销很容易成为TBT的显著部分。
-
按层方法在一层完成计算后传输KV Cache。右侧是SplitWise优化后的异步KV Cache传输。由于预填充是逐层处理的,在完成一层的计算以后,就可以将这一层的 KV Cache 发送出去。因此可以将KVCache的传输和转储与计算重叠。在每一层的注意力计算开始之前,模型等待该层的KVCache的异步加载完成,并触发下一层的异步KV Cache加载。在完成关注度计算后,启动该层的KVCache的异步存储。传输重叠允许预填充实例的执行时间大致等于KVCache加载时间或标准预填充时间,具体取决于前缀缓存的相对比例。Splitwise发现按层方式优于按请求方式,因为按层方式重叠了计算和通信。
由于批次中的token数量在计算开始时已知,Splitwise选择最佳的KV Cache传输技术。
- 一方面,对于较大的prompt,Splitwise使用逐层传输。逐层KV Cache传输与下一层的快速计算并行进行。这需要每层细粒度的同步以确保正确性。因此,可能会产生性能干扰并增加TTFT。
- 因此,对于小的prompt,Splitwise使用序列化的KV Cache传输。这是因为小的prompt的KV Cache很小,不需要支付由每层传输所需的细粒度层同步的开销。
4.4 MemServe
MemServe通过其MemPool系统跨服务实例管理分布式CPU DRAM和GPU HBM资源。通过一套全面的分布式内存池API来管理活跃KV Cache和历史KV Cache。MemServe为历史KV Cache检索提供了一个基于token的快速索引层,抽象出硬件异构性的跨实例数据交换机制,以及一个实现基于提示树的本地化策略的全局调度器,以增强缓存重用。这些策略相辅相成,共同显著提高了作业完成时间和首次token性能。
因为上下文缓存和分布式推理等技术优化扩展了KV Cache的寿命和领域,所以LLM服务已经从无状态转变为有状态系统,这迫切需要一种新的架构方法。针对这个问题,论文作者提出了MemServe(Memory-enhanced model Servin),借此在统一系统内处理请求间和请求内的优化。上下文缓存和分布式推理主要是从流水线角度进行优化,MemServe 方案是把 KVCache 当做分布式内存进行管理,这是统一的分布式系统视角,decode 机器和 prefill 机器都是和pool进行交互,不再是个单纯的流水线的逻辑了。
MemServe特点如下:
- 为了解决在分布式实例之间管理KV Cache的挑战,MemServe引入了一个跨服务的管理分布式内存和KV Cache的弹性内存池,或者称为MemPool,它是管理所有集群内存的基座,包括CPU DRAM和GPU HBM。或者说,MemServe将MemPool组件抽象出来,然后将分布式推理作为MemPool的一个用例来构建。
- MemPool提供了一套丰富的API用于管理分布式内存和KV Cache。利用这些API,MemServe将上下文缓存与分布式推理结合起来。
- 为了最大化KV Cache的重用,MemServe采用了一个全局调度器,该调度器使用新颖的全局提示树的局部感知策略来增强缓存重用。
4.4.1 动机
利用LLM中依赖关系来对KV Cache进行优化的技术可以分为两种类型:跨请求和请求内。
- 请求内优化:这种优化类型利用单个请求内的依赖关系以增强性能。两个显著的例子是分布式推理(将一个请求分成两个子请求以获得更好的调度)和序列并行(将一个请求分成多个子请求以分发负载)。
- 请求间优化:这种优化类型利用请求之间的依赖关系以获得更好的性能。上下文缓存(Context caching)是该类别中唯一已知的技术。为了构建上下文缓存,模型存储并重用自注意机制中的KV Cache,以避免在类似或重复请求之间进行冗余计算。这在多个请求共享公共前缀或上下文的情况下非常有用。
这些依赖利用技术中的一个共同主题是,它们需要新颖的逻辑来管理和传输KV Cache。
- 在请求内方法中,需要将KV Cache的作用域从单个实例扩展到分布式实例。这就需要有效的机制来在实例之间传输KV Cache,分布式推理和序列并行都是如此。
- 请求间方法需要将KV Cache的生命周期从单个请求延长到潜在无限,即跨请求。这依赖两种机制:首先,需要一个索引来找到请求之间的依赖关系,从而找到保留的KV Cache。其次,需要修改的推理引擎和注意力核心来重用历史KV Cache。
由于目前方案缺少机制来管理LLM的中间KV Cache数据,因此存在两个关键问题。
- LLM服务系统无法同时应用任何现有的请求间和请求内依赖性利用优化。当前的上下文缓存(请求间)方法设计时没有考虑到请求内场景。因此,分离的推理(请求内)无法从上下文缓存中受益,因为它缺乏利用KV Cache从解码返回到预填充实例以供将来重用的机制。同样,序列并行性将KV Cache分布到多个实例,但是缺乏保留和重用它所需的机制和算法。这个问题是由于请求内技术将一个紧密耦合的请求分解为多个松散耦合的子请求,使得在分布式环境中复杂化了KV Cache管理。
- LLM服务系统缺乏一个全面的、自上而下的设计来有效地利用现有的请求间技术。上下文缓存通过在同一服务实例中运行共享相同前缀的请求来重复使用历史KV Cache。然而,当前的LLM服务系统根据负载或会话ID跨多个服务实例调度请求,这未能最大化跨会话的KV Cache重用。
这些问题的出现是因为现有的LLM服务系统是建立在KV Cache仅仅是单个请求在单个实例上的中间数据的假设之上的。随着新兴的依赖利用技术的出现,KV Cache的生命周期已经延长,其管理范围也扩展到了分布式设置。这种范式转变需要对LLM服务架构进行根本性的重新思考。
4.4.2 方案
MemServe被设计为一个大规模的、可以高效处理请求间和请求内优化的LLM服务系统。它包括三个主要组件:全局调度器、多种类型推理实例和一个弹性内存池(MemPool),MemServe是这么介绍自己的:we propose Memory-enhanced model Serving, or MemServe, to handle inter-request and intra-request optimizations within a uniffed system.
这里有几个关键点:
- 统一系统。这里涉及了几种 instances 类型,P-only、D-only、PD-colocated 机器类型(PD 就是 prefill-decode 的意思),同时在运算时就分为 (1) PD-colocated(只用第三种 instances 的), (2) PD-colocated with caching, (3) PD-disaggregated (用前两种 instances、或者混着一起用), (4) PD-disaggregated with caching 。
- 内存增强(Memory-enhanced)。在分散推理的 setting 下引入了一个弹性内存池 MemPool,用于管理分布式内存和跨服务实例的 KVCache。

弹性内存池
MemPool是MemServe的核心组件,提供三种类型的API:内存、索引和分布式数据传输。它在每个推理实例内运行,使用固定大小的内存分配器管理所有本地内存。
内存池管理推理集群中的所有内存,包括CPU DRAM和GPU HBM。内存池在每个推理实例中运行,共同提供一组分布式内存池API。它管理正在进行的请求使用的活跃KV Cache以及请求完成后保留的历史KV Cache。
下图展示了MemPool启用的用例。圆1是上下文缓存。圆2是分解推理。圆3是序列并行性。灰色实线表示MemPool索引API调用。实线表示MemPool分布式API。MemPool在一个平台上支持所有用例。

索引
当 KVCache 越来越大的时候,内存池中的布局就是一个非常大的问题,所以MemPool使用内部索引将提示标记映射到KV历史缓存,管理正在进行的请求的活跃KV Cache以及请求完成后保留的历史KV Cache,确保高效检索缓存数据。
有了索引,内存的检索就靠索引了,其实也就是给 pagedattention 中的 page 加一个 id,可以通过其他的检索机制来优化这个检索过程。论文中给出的就是 global prompt trees 的结构机制来进行优化。
每当引擎调用插入、匹配、删除等操作时,MemPool都会遍历该索引。LLM服务世界有三种索引方法:标记、会话和文档ID。基于标记的索引通用性强,因为它适用于任何共享提示前缀情况。会话和文档ID索引更简单,但只能在聊天会话内或跨会话使用相同文档时重用共享提示。论文采用基于标记的索引方法,以实现广泛适用性。为了实现这个索引,MemPool利用了SGLang提出的基数树。
调度
MemServe 的全局调度器一方面负责整个框架和调度,另一方面还维护了 global prompt trees 全局提示树 和 locality-aware scheduling policy 本地感知调度等策略来优化内存管理和 KVCache 管理。每个节点上会有对全局树型缓存进行分布式维护。调度的时候,请求的提示词会通过对所有类型的树查询完成对全局的查询,就可以通过策略模块,针对分布式负载情况选择具有最长公共前缀(即最大保留历史KVCache)的实例,以达到最优的检索和访问效率了。

传输API
MemPool提供了一个简单的数据传输API,抽象了三种异构性:并行性、网络和内存介质。MemServe通过使用MemPool API在四个步骤中弥合了上下文缓存(请求间)和分布式推理(请求内)之间的差距:(a)首先使用分布式API来复制分布式推理,(b)然后使用索引API向仅预填充实例添加缓存,(c)将相同的缓存应用于仅解码实例,(d)最后我们启用解码到预填充数据传输。下图展示了使用MemPool API通过上下文缓存增强分解推理。引擎箱(engine box)是指一个经过调整的推理引擎,如vLLM。圆圈数字表示构建解决方案所采取的步骤。A-KV是活跃KV Cache。H-KV是历史KV Cache。

我们接下来看看如何在四个不同 level 的缓存设计机制中逐步构建一个完整的设计。
-
PD-Basic。这是naive/vanilla 的机制,其实就是 DistServe 和 Splitwise提出的基本的解聚推理架构。作为优化的 baseline 。
-
PD-Caching-1 只在 P-only instances 启用缓存。将活跃KV Cache退休为历史KV Cache,以便未来的推理可以利用保存的数据减少重计算(上图中的第2步)。这种缓存设计只保留了预填阶段产生的历史KV Cache,而没有保留解码阶段的缓存,因此适用于共享长公共前缀提示的工作负载,例如系统前缀。这种设计的主要缺点是,在多轮对话场景中(例如文档QA),预填实例需要重复地将相同的活跃KV Cache集转发给解码实例,浪费带宽并影响到第二个标记的时间。因此,我们提出下一个设计方案来解决这个问题。
-
PD-Caching-2 在 D-only 也就是 decoder 节点进行缓存。这个设计在解码实例中启用缓存,以减少重复的数据移动。我们在PD-Caching-1的基础上进行了两个关键改变。首先,预填实例现在调用transfer_with_insert而不是transfer,这样解码实例将预填阶段产生的传输的KV Cache插入到其本地索引中。其次,在请求完成后,解码实例调用insert将解码阶段产生的KV Cache保留到其本地索引中。借助于局部感知调度,预填实例现在只需要递增地传输新的KV Cache数据。尽管这种设计减少了从预填实例到解码实例的数据移动,但它并没有改善预填实例的上下文缓存,因为它缺乏来自解码阶段的历史KV Cache。因此,在多轮对话场景中,随着提示增加,上下文缓存的好处保持不变。因此,我们提出下一个设计方案来解决这个问题。
-
PD-Caching-3 允许P-only 和 D-only 的机器可以互相传输并维护两边的索引。这个设计实现了解聚推理架构的全面上下文缓存。我们在PD-Caching-2的基础上进行了一个改变:在请求完成后,解码实例调用transfer_with_insert将解码阶段产生的KV Cache传输到预填实例(上图中的第5步)。因此,预填实例保留的历史KV Cache增长,上下文缓存的好处随着轮数的增加线性增加。我们其实可以把这里的 Caching Pool 理解为一个不完全的同步所有数据的异步共享机制,各种类型的节点间即要维护自己的缓存也要按需推送和拉取部分远程数据。
传输操作
将活跃KV Cache从预填到解码实例的传输有两种方式:按层或按请求。按层方法在一层完成计算后传输KV Cache。按请求方法在预填阶段完成后传输KV Cache。Splitwise发现按层优于按请求,因为它重叠了计算和通信,从而加快了时间到第二个token(或TTST)。
当负载较低时,MemServe作者也观察到了同样现象。然而,随着负载的增加,两者都会产生非常大的开销,根本原因是(1)内存布局离散,(2)网络原语缺失。
-
基于分页的动态内存管理,如PagedAttention,是现在LLM服务系统中的事实标准。无论分页机制是在引擎 还是在驱动程序中实现,KV Cache都被分区并存储在固定大小的内存块中。块大小是可配置的,通常以token数量为单位。而现有的引擎以细粒度的方式管理KV Cache。例如,vLLM为每个LLM层分配两个块。对于具有L层和每个块8个token的LLM,引擎需要2∗ L块来存储8个token的KV Cache。尽管分页提高了利用率,但离散的内存布局在使用现有AI网络堆栈实现分布式推理时面临巨大挑战。
-
AI中的网络堆栈技术大多是诸如NCCL之类的集合通信库。这些库最适合使用张量或流水线并行处理的典型AI工作负载,但在支持LLM服务的请求内优化方面,如分布式推理或序列并行,集合通信库表现不佳。LLM服务的这些新模式需要在HBM或DRAM之间进行有效的点对点、收集和分散原语。但是由于KV Cache是离散的,因此无论使用按层还是按请求方法,网络API调用的数量等于离散内存块的数量,这就是为什么两者随着负载增加都会产生开销的根本原因。
为了解决分页和网络原语不足引起的挑战,我们提出通过将较小的KV块聚合成大块来减少碎片化,类似于使用大页。具体而言,我们将每层的两个块聚合成一个块:新的块大小等于 2∗ L 个较小的块。这有效地将网络API调用的数量减少了 2∗ L 倍。这种优化仅适用于按请求方法,因为按层方法不可避免地需要至少调用网络API 次。

上图比较了按层、按请求和按请求聚合(论文提出的优化)的跨内存布局和传输时间线。论文的测试表明,在低负载下,按层实现了最低的JCT(Job Completion Time),但在高负载下,因为减少了网络调用,通过层聚合(bylayer-agg)优于按层。
4.5 TetriInfer
论文"Inference without Interference: Disaggregate LLM Inference for Mixed Downstream Workloads"提出了TetriInfer,TetriInfer的意思是希望能像俄罗斯方块一样堆叠好空间,不要乱放出空当。
4.5.1 动机
避免干扰的一个简单解决方案是为每个下游任务静态地分配资源。鉴于LLM服务基础设施的高成本,这个解决方案是不实际的。因此,TetriInfer构建了一个分布式的LLM推理服务系统,通过根据请求特征仔细安排和分组来解决这些问题。TetriInfer作者的思路如下。
- 分离 prefill 与 decode 到不同的硬件。TetriInfer具有专用的预填充和解码实例,这两个是虚拟概念,每个实例可以独立扩展并在负载变化时翻转角色。TetriInfer将预填充请求仅调度到预填充实例,解码请求也是如此。预填充实例将预填充的KV Cache传输给解码实例。
- 限制 prefill 的 size,就是找到使得 batch 刚好处在 compute-bound 和 memory-bound 的临界点上。
- 为了避免预填充阶段的干扰,应该限制在单个预填充迭代中处理的token数量,以便充分利用硬件而不产生额外的惩罚。于是TetriInfer将输入提示分割并填充为固定大小的块,使预填充在一个固定大小的计算单元中运行,以便加速器始终接近其计算饱和限制。
- Sarathi也提出了用于相同目的的分块预填充(Chunked-prefills),但是Sarathi是将预填充-解码混合在一起。相比之下,TetriInferj仅涉及运行预填充块,因为TetriInfer已经将LLM的预填充和解码分解为单独的实例。
- 使用基于输出的长度预测来调度 decode 阶段任务,以避免调度热点。TetriInfer利用基于LLM的长度预测模型来推测解码请求的生成token数量,然后相应地进行调度。
- 在每个预填充实例上运行长度预测器,因此预填充实例可以根据解码实例的负载情况做出明智的决策,以确保某些解码请求具有足够的资源来运行。长度预测器使用小型LLM模型进行预测,并继续使用固定大小的批次,而不是分块预填充。这是由于该模型的小尺寸,其没有像较大模型那样明显的计算饱和阈值。
- 使用智能的两级调度算法,并结合预测的资源使用情况,以避免解码调度热点。
4.5.2 实现

TetriInfer具体分为四个主要模块。集中式控制平面、预填充实例、解码实例和长度预测模型。
-
集中式控制平面。它由全局调度器和集群监视器组成。全局调度器根据负载向预填充实例发送请求,并接收来自解码实例的流式输出。集群监视器从预填充和解码实例收集统计信息,并定期向预填充实例广播负载信息。它添加、删除和翻转预填充或解码实例。
-
预填充实例。它们只运行LLM推理请求的预填充阶段。每个预填充实例都有一个本地调度器、一个长度预测器、主LLM引擎和一个调度器。
- 为了避免预填充请求之间的干扰,我们使用预填充调度器和分块预填充来对所有提示进行排序和分区为固定大小的块。
- 预填充实例的调度器对提高预填充阶段的延迟和吞吐量至关重要。调度器维护一个原始请求队列,用于存储全局调度器的请求,以及一个已调度队列,用于存储排序后的请求。在这项工作中,我们设计并实现了三种调度策略:先到先服务(FCFS)、最短作业优先(SJF)和最长作业优先(LJF)。我们之所以可以使用后两种策略,是因为我们可以根据提示中的标记数量准确估计请求的预填充时间。
-
解码实例。它们在虚拟上与预填充实例分离,并且只运行LLM推理请求的解码阶段。每个解码实例可以接收来自任何预填充实例的请求。它运行一个本地调度器,具有三个预定义的策略,用于选择要在主LLM引擎中运行的解码请求。
-
长度预测模型。预测模型是一个经过离线微调的小型LLM模型,用于预测LLM推理请求的生成长度。TetriInfer的预填充调度器和解码实例的本地调度器利用推测的信息来调度解码实例,避免了在§2.2.3中测量到的热点问题。
4.6 Mooncake
Mooncake的核心理念是用存储资源换取计算效率,其采用了以KVCache为中心的分离架构,将预取和解码集群分开(将LLM服务的不同部分分解为专用资源池),并利用RDMA构建跨节点共享缓存。它还利用GPU集群的CPU、DRAM和SSD资源来实现KVCache的分层缓存。
4.6.1 洞见
论文的核心目标和主要洞见如下:
-
因为长上下文的需求始终存在,所以KVCache 的容量会长期保持高位。
-
尽可能多地重用 KVCache 以减少所需的计算资源和在节点间转移数据的耗时。
-
最大化每个批次中的token数量以提高模型 FLOPs 利用率。
-
远程调用 KVCache 会延长 TTFT,而大的batch size会导致更大的 TBT 。
-
存储在较低层级存储上的KVCache 会带来更多问题。
4.6.2 实现
分离式架构
如下图所示,Mooncake采用了分离式架构。这里分离有两层含义:不仅将预填充与解码节点分开,还将GPU集群的CPU、DRAM、SSD和RDMA资源分组,以实现分离的KVCache。这种分离的缓存利用了未充分利用的资源,提供了充足的缓存容量和传输带宽。
-
将Prefill与Decode计算资源分开。Prefill阶段优化目标是利用request间存在共同前缀的机会,尽可能复用KVCache,同时满足TTFT,最大化MFU,让KVCache小于CPU内存限制。Decode优化目标为最大化吞吐,满足TBT,让KVCache小于GPU显存限制。
-
将KVCache和计算分离开。Mooncake 将GPU集群的CPU、DRAM、SSD和RDMA资源分组组成Distributed KVCache Pool,通过共享缓存提升命中率,减少重复计算。KVCache也是分块以Paged方式管理。
所以,Mooncake 将单个同构 GPU 集群的资源打散并重新组织成三个可以独立弹性伸缩的资源池。
- prefill pool。 Prefill Pool 处理用户输入,主要对TTFT负责。因为 Prefill 相对计算密集,这一部分也承担着抬高整体资源利用率的任务。
- decoding pool。Prefill 处理完之后对应的 KVCache 会被送到 Decode Pool 进行自回归式的流式输出。虽然我们希望尽可能在一个 batch 中聚合更多 token 以提升 MFU,但这一部分主要需要对 TBT 负责。
- kv cache pool:利用每台 HGX 机器上组成了一个 KVCache Pool 来进行全局的 Prefix Cache。全局 Prefix Cache 通过全局的调度能够大幅度提升复用率从而提升总吞吐。由此带来了一系列如何调度,分配,复制 KVCache 的问题,而且必须和 Prefill/Decode 的调度共同设计,因此我们把 Mooncake 的架构称之为以 KVCache 为中心的架构。

我们接下来看看几种pool的设计思路。
prefill pool
为了设计一个单独的预填充节点池来无缝处理上下文长度的动态分配,Mooncake采用分块流水线并行机制(CPP/chunked pipeline parallelism)来扩展单个请求的处理跨多个节点。与基于传统序列并行的解决方案相比,CPP减少了网络消耗,并简化了对频繁弹性扩展的依赖,而且通过进一步逐层预填充(Layer-wise Prefill)补充后,KVCache的流传输可以重叠延迟。这对于降低长上下文输入的TTFT是非常必要的。
Layer-wise Prefill
分块/层完成 prefill,即 block/layer-wise 的设计,可以理解为对 pagedattention 中 page 的一种细化,也是使用一个统一视角的 pool 来统一维护 KVCache 的存储。
预填充阶段的主要目标是尽可能多地重用KVCache,以避免冗余计算。因此,使用最频繁的kvcache block应该复制到多个节点以避免获取拥塞,而不怎么使用的block应该被换出以降低预留成本。
由于预加载是逐层进行且受计算限制,因此可以重叠 KVCache 的传输和转储与计算,进一步降低其占用成本,从而有效降低长上下文请求的延迟。在 Mooncake 中,KVCache 的加载和存储通过启动和等待操作异步执行。在每个层的注意力计算开始之前,模型会等待该层的 KVCache 的异步加载完成,并触发下一层的异步 KVCache 加载。在注意力计算完成后,会启动该层 KVCache 的异步存储。一旦所有层的计算完成,进程会等待所有异步存储操作完成。传输重叠使预加载实例的执行时间大致等同于 KVCache 加载时间或标准预加载时间,具体取决于前缀缓存比例相对于输入长度的大小。
Multi-node Prefill
由于长上下文预填充中存在丰富的并行性,人们提出了很多并行策略。
-
数据并行:长序列Prefill的batch size是1,没法数据并行。
-
张量并行:虽然用多个GPU并行处理长上下文请求是可取的。然而,将张量并行性扩展到超过一个节点需要每层做两个昂贵的、基于RDMA的全局归约操作,这显著降低了预填充节点的MFU。所以张量并行难以拓展出节点。
-
序列并行。序列并行(SP)将请求的输入序列分区到不同的节点上,以实现加速。这些SP方法利用了注意力操作符的关联属性,在Ring Attention 或Striped Attention的实现过程中至少每层需要跨节点通信一次。这大大降低了网络消耗并改善了MFU。然而,采用SP仍然导致MFU较使用仅单节点TP时更差。而且,SP推理需要在每个卡上复制模型参数,对大模型来说是沉重的负担。而且,SP每层都要通信,占用宝贵的网络带宽,这些带宽更应该留给KV Cache的传输。
理想的部署应该将预填充节点组织成两组:一组仅使用TP,另一组使用SP。只有在需要满足TTFT SLO时才将请求分派给SP组。但是这种进一步的分解导致在动态调整每组节点数量时出现问题,因为静态并行设置可能导致整个集群的利用率降低。
为了解决这个问题,Mooncake利用了仅解码器模型的自回归属性,并为长上下文预填充实现了分块流水线并行(CPP)。Mooncake将预填充集群中的每X个节点分组成一个流水线预填充节点组。对于每个请求,其输入标记被分成块,每个块不超过预填充块。同一请求的不同块可以由不同节点同时处理,从而实现处理的并行化并减少TTFT。CPP提供了两个主要好处:1)类似于训练中的流水线并行,它仅在每个管道阶段的边界处需要跨节点通信,这可以很容易地与计算重叠。这导致更好的MFU和与KVCache传输的网络资源争用更少。2)它自然适用于短和长上下文,对于短上下文预填充没有明显的开销,并避免频繁地动态调整节点分区。
这种基于流水线的加速方法已经在训练系统中进行了探索,但Mooncake首次在推理阶段应用。
4.6.3 Decode Pool
Decode Pool 在业界的实践是最多的,此处略过。
4.6.4 KVCache pool
分布式KVCache设计支持多对话会话共享缓存,避免重复存储和计算;也提供分层存储管理:高频KVCache驻留DRAM,低频数据下沉至SSD。
PD 直连就是预填充节点直接将 KV Cache 发送给解码节点,它的好处是延迟低,但是会将P、D 节点耦合在一起。一旦解码节点出现了问题,重新调度时无法仅调度 D 节点,需要重新进行整个预填充、解码过程,导致代价太高。使用 KV Cache Store/Pool 是在 P 和 D 之间增加了一个中间存储,预填充节点先将 KV Cache 写到中间存储,解码节点从中间存储读。这样做数据会多传输一次,增加了延迟和实现复杂度。好处是将P和D节点进行解耦合,容错性更好。预填充阶段也可以利用这个中间存储做 Prefix Caching。
根据请求模式,KVCache pool可以使用缓存驱逐算法,如LRU(最近最少使用)、LFU(最不频繁使用)或基于请求特征的缓存淘汰算法来进行调整。这些KVCache块在CPU和GPU之间的传输由一个单独的(GPUDirect)基于RDMA的组件Messenger处理。这种架构还使我们能够为外部用户提供上下文缓存API,以实现对KVCache的更高重用。
下图显示了CPU内存中的KVCache池,以及KVCache块的存储和传输逻辑。每个块都附有一个哈希值,该哈希值由其自身的哈希值和用于重复数据删除的prefix决定。

4.6.5 工作流
为了调度所有这些分散的组件,Mooncake实现了一个名为Conductor的全局调度程序。Conductor负责根据当前的KVCache分布和工作负载分派请求。如果对未来的推理有益,它还会复制或交换某些KVCache块。
因为Mooncake 利用了 GPU 集群中未充分利用的 CPU、DRAM 和 SSD 资源希望可以得到充分利用。再简单说就是GPU和CPU、内存等资源尽量打满。那么就需要判断当前推理瓶颈在什么地方?若是计算瓶颈,但所有的GPU打满了,那么是不是可以放到CPU进行计算。若是存储瓶颈,但是显存已经占满了,那么是不是可以放到内存中。若是传输瓶颈,是不是可以进行量化或者其他方式。
对于每个新请求,Conductor根据请求长度和prefix_len(因实例而异)估计相应的执行时间。然后将该请求的估计等待时间相加,以获取该实例上的TTFT。Conductor将请求分配给TTFT最短的实例,并相应地更新该实例的缓存和队列时间。为了预测请求的预填充阶段的计算时间,Mooncake使用了从离线测试数据派生的预测模型。该模型基于请求的长度和前缀缓存命中长度来估计预填充计算时间。请求的排队时间是通过汇总所有排队请求的预填满时间来计算的。
由于较高的实例负载,请求可能不总是被定向到具有最长前缀高速缓存长度的预填充实例。在这种情况下,如果估计的额外prefilling时间短于传输时间,则Conductor将高速缓存的位置和请求转发到替代实例。如果最佳远程前缀匹配长度不大于当前本地可重复使用的前缀乘以阈值,则我们更愿意直接计算输入token。

上图展示了请求的典型工作流程。当一个请求到达之后,Conductor选择一对预处理节点和一个解码节点,并启动包含四个步骤的工作流程:
- KVCache重用。这是一种以KVCache为中心的调度。所选的预填充节点(组)接收到一个包含三个部分的请求:原始输入、可重用的前缀缓存块ID和分配给请求的完整缓存块ID。Conductor根据前缀缓存块ID将前缀缓存从远程CPU内存加载到GPU内存,以启动请求。如果不存在前缀缓存,则跳过此步骤。这种选择平衡了三个目标:尽可能多地重用KVCache、平衡不同预填充节点的工作负载,并保证TTFT SLO。
- 增量预填充。预填充节点(组)使用前缀缓存完成预填充阶段,并将新生成的增量KVCache存储回CPU内存。如果未缓存的输入token数量超过一定阈值(prefill_chunk),则将预填充阶段分成多个块并以流水线方式执行。此阈值被设定为一个可以充分利用相应GPU的计算能力的数值,通常大于1000个token。
- KVCache传输。每个节点上都部署一个Messenger服务,以管理和传输这些缓存。每个Messenger作为其相应推理实例中的独立进程运行。Messanger将每个模型层生成的KVCache流式传输到目标解码节点的CPU内存,此KV Cache的传输是异步执行的,并与上述增量预填充步骤重叠,这样可以减少等待时间。
- 解码。当解码节点的CPU DRAM中接收到所有KVCache后,Mooncake会以连续批处理的方式加入下一批请求。Conductor根据解码节点当前的负载预先选择解码节点,以确保不违反TBT SLO。然而,本地调度器(local scheduler)会再次检查这个SLO,因为在预填阶段之后,预期的负载可能已经发生变化。这种双重检查可能会导致请求被拒绝,这种情况下对应的预填成本就浪费了。
4.6.6 调度
Mooncake实现了基于KVCache的、平衡了实例负载和用户体验的请求调度算法。
下面的算法1详细介绍了缓存感知预填充调度机制。对于每个新请求,其输入token被划分为几个块,并为每个块计算哈希键。这涉及在一个块中生成一个与前一个块的哈希键连接的token哈希键(如果可用)。然后将请求的块键逐一与每个预填充实例的缓存键进行比较,以识别前缀匹配长度(pref ix_len)。
为何可以进行全局调度?这是因为对于每 X byte 的 KVCache,其重新生成所需的算力正比于 X*hd 再乘以一个较大的常数,hd 是模型的 hidden dimension。因此只要每卡算力和每卡通讯带宽的比值小于 hd 乘以这个常数,那么相比原地重算,从远端传输 KVCache 不仅仅减少了计算量,还减少了 TTFT。
另外,下面还涉及到一个早期拒绝策略。Mooncake估计了两阶段的负载,在开始时处理前对于可能超出负载的请求直接退回或延迟处理,优化服务器超载问题。早期拒绝策略减少了过载场景中计算资源的浪费。如果在预填充阶段之后没有可用的解码时隙,我们需要提前拒绝某些请求,以节省浪费的计算资源。

0xFF 参考
Orca: A Distributed Serving System for Transformer-Based Generative Models
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
手抓饼熊:Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving
手抓饼熊:MemServe: Context Caching for Disaggregated LLM Serving with Elastic Memory Pool
手抓饼熊:CachedAttention(原AttentionStore)
手抓饼熊:大模型Prefix场景Attention优化(三)
聊聊大模型推理服务中的优化问题 刀刀宁
大模型推理新突破:分布式推理技术探索与实践 大模型推理新突破:分布式推理技术探索与实践 极客邦科技InfoQ
基于 chunked prefill 理解 prefill 和 decode 的计算特性 Chayenne Zhao
zhuanlan.zhihu.com/p/718715866
zhuanlan.zhihu.com/p/278366257...
Splitwise: Efficient generative llm inference using phase splitting
DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
hao-ai-lab.github.io/blogs/dists...
Inference without interference: Disaggregate llm inference for mixed downstream workloads
Mooncake阅读笔记:深入学习以Cache为中心的调度思想,谱写LLM服务降本增效新篇章 方佳瑞
Mooncake:基于KVCache的LLM服务架构设计与分析 常华Andy
大模型推理新突破:分布式推理技术探索与实践 QCon InfoQ
Injecting Adrenaline into LLM Serving: Boosting Resource Utilization and Throughput via Attention Disaggregation Yunkai Liang, Zhangyu Chen, Pengfei Zuo, Zhi Zhou, Xu Chen, Zhou Yu