公共资源速递
5 个数据集:
* 302 例罕见病病例数据集
* DRfold2 RNA 结构测试数据集
* NaturalReasoning 自然推理数据集
* VenusMutHub 蛋白质突变小样本数据集
* Bird Vs Drone 鸟类与无人机图像分类数据集
2 个模型:
* Qwen2.5-0mni
* Llama-4-Scout-17B-16E-Instruct
4 个教程:
* CSM 双人对话语音生成 Demo
* 一键部署 Qwen2.5-VL-32B-lnstruct
* Stable Virtual Camera 图像秒变 3D 视频
* 谛韵 DiffRhythm:1 分钟即可生成完整音乐 Demo
访问官网立即使用: openbayes.com
公共数据集
1. 302 例罕见病病例数据集
该数据集包含 302 种罕见病,这些罕见病是从 Orphanet 数据库中 33 种类型的 7k+ 种罕见病中选出的,Orphanet 数据库是欧盟委员会共同资助的综合罕见病数据库。
* 直接使用:
https://go.openbayes.com/JreTB
2. DRfold2 RNA 结构测试数据集
该数据集是为了客观评估研究中 DRfold2 的性能而构建的独立测试数据集。其中包含 28 种 RNA 结构,它们的序列长度均小于 400 nts,并来源于以下 3 个类别:最新的 RNA-Puzzles 目标序列、CASP15 竞赛中的 RNA 目标序列、截至 2024 年 8 月 1 日,Protein Data Bank (PDB) 数据库中最新发布的 RNA 结构。
* 直接使用:
https://go.openbayes.com/pN0Oi
3. NaturalReasoning 自然推理数据集
该数据集包含 280 万个挑战性问题,这些问题覆盖了多个领域,如 STEM 领域(例如物理、计算机科学)、经济学、社会科学等。该数据集旨在通过利用预训练语料库和大型语言模型 (LLMs) 来生成多样化且具有挑战性的推理问题及其参考答案,而无需额外的人工标注。
* 直接使用:
https://go.openbayes.com/KAQyB
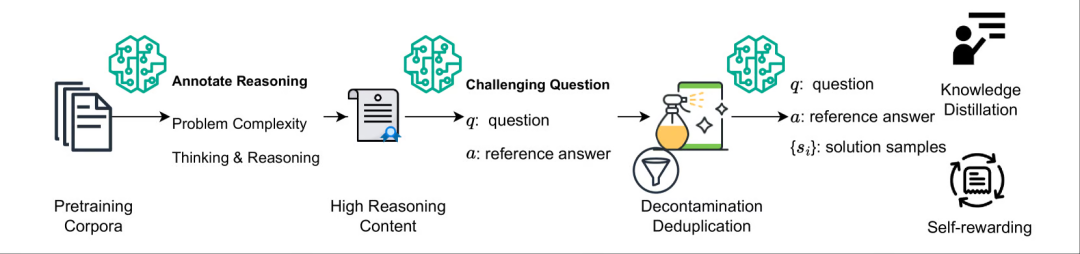
数据集构建示意图
4. VenusMutHub 蛋白质突变小样本数据集
VenusMutHub 是首个针对真实应用场景蛋白质突变小样本数据集,含 905 个真实应用场景的小样本实验突变数据,覆盖 527 种蛋白质(其中 98% 的蛋白的突变数量在 5-200 个之间),涵盖了稳定性、活性、结合亲和力与选择性等多种功能测量数据。所有数据均采用直接生化测量,而非替代性荧光读数,确保了评估的准确性。
* 直接使用:
https://go.openbayes.com/Y4B73
5. Bird Vs Drone 鸟类与无人机图像分类数据集
数据集包含来自 Pexel 网站的多种图像集合,代表运动中的鸟类和无人机。这些图像是从视频帧中捕获的,经过分割、增强和预处理以模拟不同的环境条件,从而增强模型的训练过程。
* 直接使用:
https://go.openbayes.com/2tCNM
公共模型
1. Qwen2.5-0mni
*** 发布机构:**阿里巴巴通义千问团队
Qwen2.5-Omni 是阿里巴巴通义千问团队发布的最新端到端多模态旗舰模型,专为全面的多模式感知设计,无缝处理包括文本、图像、音频和视频在内的各种输入,同时支持流式的文本生成和自然语音合成输出。
* 直接使用:
https://go.openbayes.com/EIpHB
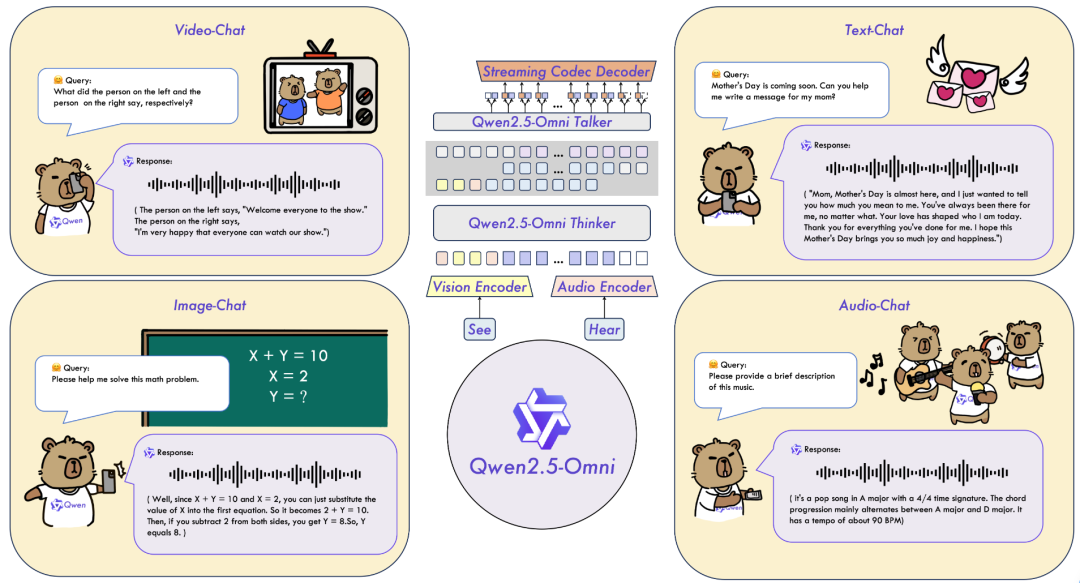
模型应用
2. Llama-4-Scout-17B-16E-Instruct
*** 发布机构:**Meta
Llama-4-Scout-17B-16E-Instruct 是由 Meta 于 2025 年 4 月开发的一款混合专家 (MoE) 语言模型,属于 Llama 4 系列模型的一部分,支持文本和多模态体验。该模型利用专家的混合架构,在文本和图像理解方面提供行业领先的性能。
* 直接使用:
https://go.openbayes.com/EsnVz
公共教程
1. CSM 双人对话语音生成 Demo
CSM (Conversational Speech Model) 旨在通过自然、连贯的语音生成技术提升语音助手的情感交互能力。该模型基于多模态学习框架,结合文本和语音数据,采用端到端的 Transformer 架构直接生成自然且富有情感的语音,可根据文本和音频输入生成 RVQ 音频代码。
该教程使用 CSM-1B 模型即可实现两人对话生成,算力资源采用 RTX 4090。
* 在线运行:
https://go.openbayes.com/zrpWM
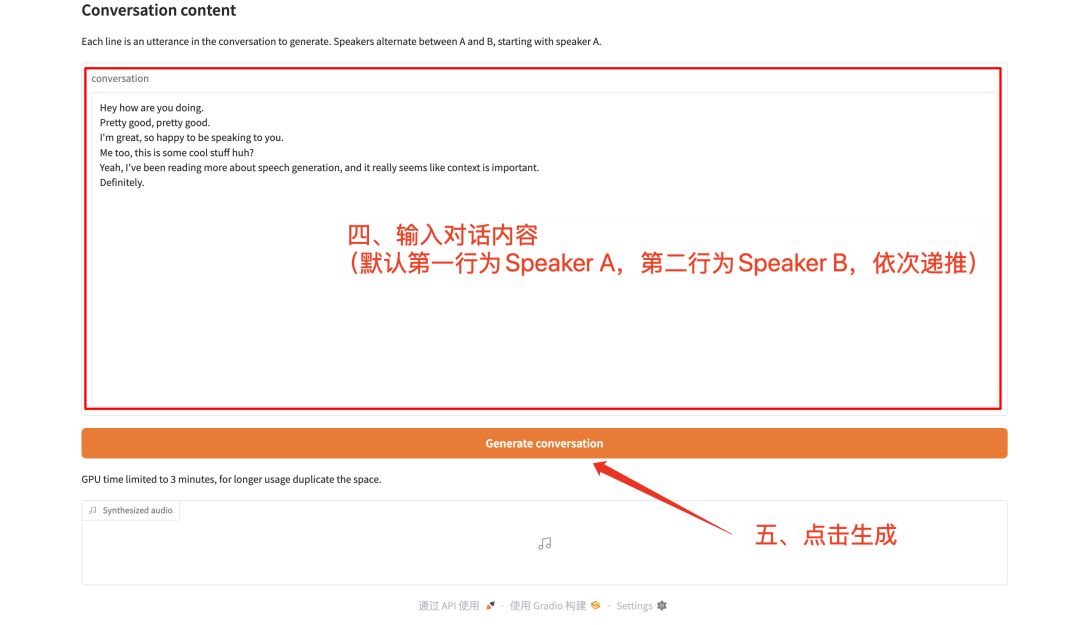
模型界面示例
2. 一键部署 Qwen2.5-VL-32B-lnstruct
Qwen2.5-VL-32B-Instruct 是阿里巴巴通义千问团队于 2025 年 3 月 24 日开源的多模态大模型,基于 Apache 2.0 协议发布。该模型在 Qwen2.5-VL 系列的基础上,通过强化学习技术优化,以 32B 参数规模实现了多模态能力的突破。
进入官网克隆并启动容器,打开 API 地址即可体验模型。
* 在线运行:
https://go.openbayes.com/bOYvX
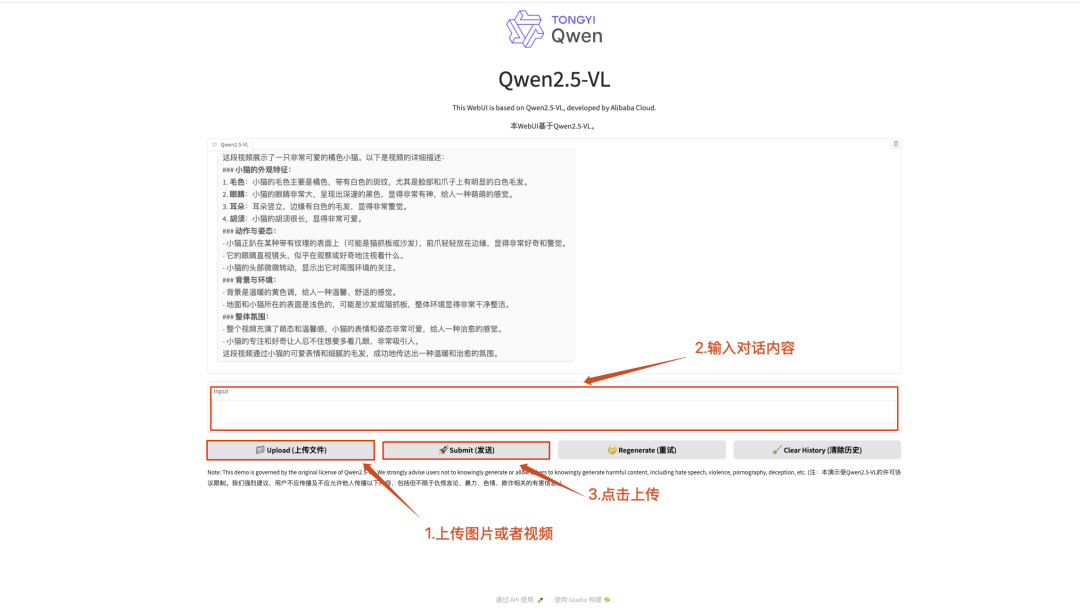
模型示例
3. Stable Virtual Camera 图像秒变 3D 视频
Stable Virtual Camera 能够根据任意数量的输入视图和目标相机,生成场景的新视图。其设计克服了现有方法在生成大视角变化或时间上平滑样本方面的局限性,同时无需依赖特定的任务配置。该模型的一个显著特点是无需额外的 3D 表示学习,即可保持高一致性的样本生成,从而简化了实际应用中的视角合成流程。
相关代码已配置完成,克隆容器进入 API 地址即可生成 3D 视频。
* 在线运行:
https://go.openbayes.com/qBENf

模型示例
4. 谛韵 DiffRhythm:1 分钟即可生成完整音乐 Demo
DiffRhythm 是首个能够创作完整歌曲的基于扩散的歌曲生成模型。它能够在短时间内生成长达 4 分 45 秒的完整歌曲,包含人声和伴奏。
只需为模型提供歌词和风格提示,DiffRhythm 就能自动生成与歌词匹配的旋律和伴奏,还支持多语言输入。
* 在线运行:
https://go.openbayes.com/uK2X2

模型工作流程
以上就是小贝上周在 OpenBayes 的全部更新内容啦~