名人说:路漫漫其修远兮,吾将上下而求索。------ 屈原《离骚》
创作者:Code_流苏(CSDN) (一个喜欢古诗词和编程的Coder😊)
订阅专栏 :《Python星球日记》目录
- 一、引言
- 二、数据分组与聚合
- 三、排序与排名
- [1. 数据排序](#1. 数据排序)
- [按值排序 - sort_values()](#按值排序 - sort_values())
- [按索引排序 - sort_index()](#按索引排序 - sort_index())
- [2. 数据排名](#2. 数据排名)
- 四、时间序列分析
- [1. 时间戳与时间段](#1. 时间戳与时间段)
- [2. 创建时间序列数据](#2. 创建时间序列数据)
- [3. 时间序列索引与切片](#3. 时间序列索引与切片)
- [4. 重采样](#4. 重采样)
- [5. 移动窗口函数](#5. 移动窗口函数)
- 五、实战练习:销售数据分析
- [1. 准备数据](#1. 准备数据)
- [2. 分组分析](#2. 分组分析)
- [3. 时间序列分析](#3. 时间序列分析)
- [4. 数据可视化](#4. 数据可视化)
- 六、总结与拓展
- [1. 关键知识点回顾](#1. 关键知识点回顾)
- [2. 实际应用场景](#2. 实际应用场景)
- [3. 学习资源推荐](#3. 学习资源推荐)
👋 专栏介绍 : Python星球日记专栏介绍(持续更新ing)
✅ 上一篇 : 《Python星球日记》第24天:Pandas 数据清洗
🌟引言 : 欢迎来到Python星球🪐的第25天!
今天我们将深入学习Pandas的高级数据分析功能,包括数据分组、聚合操作、排序与排名以及时间序列分析。这些是数据分析工作中的核心技能,掌握它们将大大提升你的数据处理能力。
一、引言
在前面的学习中,我们已经了解了Pandas 的基础知识,包括Series 和DataFrame的创建、基本操作和数据清洗等。今天,我们将进一步探索Pandas提供的高级数据分析功能,学习如何从数据中提取更深层次的信息和洞察。
数据分析 是数据科学工作流程中的核心环节,而Pandas提供了丰富的工具和函数来支持各种分析需求。通过本文的学习,你将掌握如何对数据进行分组分析 、排序排名 以及时间序列处理,这些都是实际数据分析项目中经常用到的技能。
首先,让我们导入必要的库:
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False二、数据分组与聚合
数据分组和聚合是数据分析 中最常用的操作之一,它允许我们按照某一列或多列的值将数据分为多个组,然后对每组数据应用聚合函数。

1. 分组操作基础
分组操作的核心 是groupby()函数,它根据指定的一个或多个列将DataFrame分割成不同的组。
让我们创建一个销售数据示例:
python
# 创建示例销售数据
data = {
'日期': pd.date_range(start='2023-01-01', periods=20, freq='D'),
'产品': ['A', 'B', 'A', 'B', 'C', 'A', 'B', 'C', 'A', 'B',
'C', 'A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C'],
'区域': ['东部', '东部', '南部', '南部', '东部', '西部', '西部', '南部', '东部', '南部',
'西部', '东部', '南部', '西部', '东部', '南部', '西部', '东部', '南部', '西部'],
'销售额': np.random.randint(1000, 5000, size=20),
'数量': np.random.randint(10, 100, size=20)
}
df = pd.DataFrame(data)
print(df.head())输出结果:
日期 产品 区域 销售额 数量
0 2023-01-01 A 东部 3416 56
1 2023-01-02 B 东部 4713 67
2 2023-01-03 A 南部 2965 31
3 2023-01-04 B 南部 1743 25
4 2023-01-05 C 东部 4350 78按单列分组
最简单的分组是按单个列进行分组:
python
# 按产品分组并计算销售额总和
product_sales = df.groupby('产品')['销售额'].sum()
print(product_sales)输出结果:
产品
A 14986
B 20165
C 17354
Name: 销售额, dtype: int64按多列分组
我们也可以按多个列进行分组:
python
# 按产品和区域分组,计算销售额总和
product_region_sales = df.groupby(['产品', '区域'])['销售额'].sum()
print(product_region_sales)输出结果:
产品 区域
A 东部 9874
南部 2965
西部 2147
B 东部 4713
南部 11709
西部 3743
C 东部 4350
南部 4219
西部 8785
Name: 销售额, dtype: int642. 聚合函数
聚合函数是对分组后的数据执行计算的函数。Pandas提供了多种内置的聚合函数:
单一聚合函数
python
# 按产品分组,计算销售额的平均值
avg_sales = df.groupby('产品')['销售额'].mean()
print(avg_sales)输出结果:
产品
A 2997.2
B 4033.0
C 3470.8
Name: 销售额, dtype: float64多个聚合函数
python
# 按产品分组,同时计算销售额的多个统计量
sales_stats = df.groupby('产品')['销售额'].agg(['sum', 'mean', 'count', 'max', 'min'])
print(sales_stats)输出结果:
sum mean count max min
产品
A 14986 2997.2 5 4217 1983
B 20165 4033.0 5 4713 1743
C 17354 3470.8 5 4350 2631对不同列应用不同的聚合函数
python
# 对不同列应用不同的聚合函数
agg_result = df.groupby('产品').agg({
'销售额': ['sum', 'mean'],
'数量': ['count', 'max', 'min']
})
print(agg_result)输出结果:
销售额 数量
sum mean count max min
产品
A 14986 2997.2 5 89 21
B 20165 4033.0 5 92 25
C 17354 3470.8 5 94 323. 转换与过滤
除了聚合,groupby对象还支持转换 和过滤操作:
转换操作
转换操作会返回与原DataFrame形状相同的结果:
python
# 计算每个产品的销售额占该产品总销售额的百分比
df['销售额百分比'] = df.groupby('产品')['销售额'].transform(
lambda x: x / x.sum() * 100
)
print(df[['产品', '销售额', '销售额百分比']].head(10))过滤操作
过滤操作用于筛选满足条件的组:
python
# 筛选出平均销售额大于3000的产品组
filtered_groups = df.groupby('产品').filter(lambda x: x['销售额'].mean() > 3000)
print(filtered_groups['产品'].unique())三、排序与排名
数据分析中,排序 和排名是非常常用的操作,可以帮助我们更好地理解数据的分布和相对位置。
1. 数据排序
Pandas提供了两种主要的排序方法:按值排序和按索引排序。
按值排序 - sort_values()
python
# 按销售额降序排序
df_sorted = df.sort_values(by='销售额', ascending=False)
print(df_sorted[['产品', '区域', '销售额']].head())
# 按多列排序:先按产品排序,再按销售额降序排序
df_multi_sorted = df.sort_values(by=['产品', '销售额'], ascending=[True, False])
print(df_multi_sorted[['产品', '销售额']].head())按索引排序 - sort_index()
python
# 先将产品设为索引,然后按索引排序
df_idx = df.set_index('产品')
df_idx_sorted = df_idx.sort_index()
print(df_idx_sorted.head())2. 数据排名
排名是一种将数据值转换为其相对位置的方法。Pandas的rank()函数提供了灵活的排名功能:
python
# 对销售额进行排名
df['销售额排名'] = df['销售额'].rank(ascending=False) # 降序排名,销售额最高的排名为1
print(df[['产品', '销售额', '销售额排名']].sort_values('销售额排名').head())处理并列情况
当存在相同值时,rank()函数提供多种处理方式:
python
# 创建包含重复值的Series
s = pd.Series([7, 2, 7, 3, 7, 4])
# 不同的处理并列的方式
print("默认(average):", s.rank())
print("min方法:", s.rank(method='min'))
print("max方法:", s.rank(method='max'))
print("first方法:", s.rank(method='first'))
print("dense方法:", s.rank(method='dense'))输出结果:
默认(average): [4.0, 1.0, 4.0, 2.0, 4.0, 3.0]
min方法: [3.0, 1.0, 3.0, 2.0, 3.0, 3.0]
max方法: [5.0, 1.0, 5.0, 2.0, 5.0, 3.0]
first方法: [3.0, 1.0, 4.0, 2.0, 5.0, 3.0]
dense方法: [3.0, 1.0, 3.0, 2.0, 3.0, 2.0]四、时间序列分析
时间序列数据 是按时间顺序索引的数据,在金融、气象、销售等领域非常常见。Pandas提供了强大的时间序列处理功能。
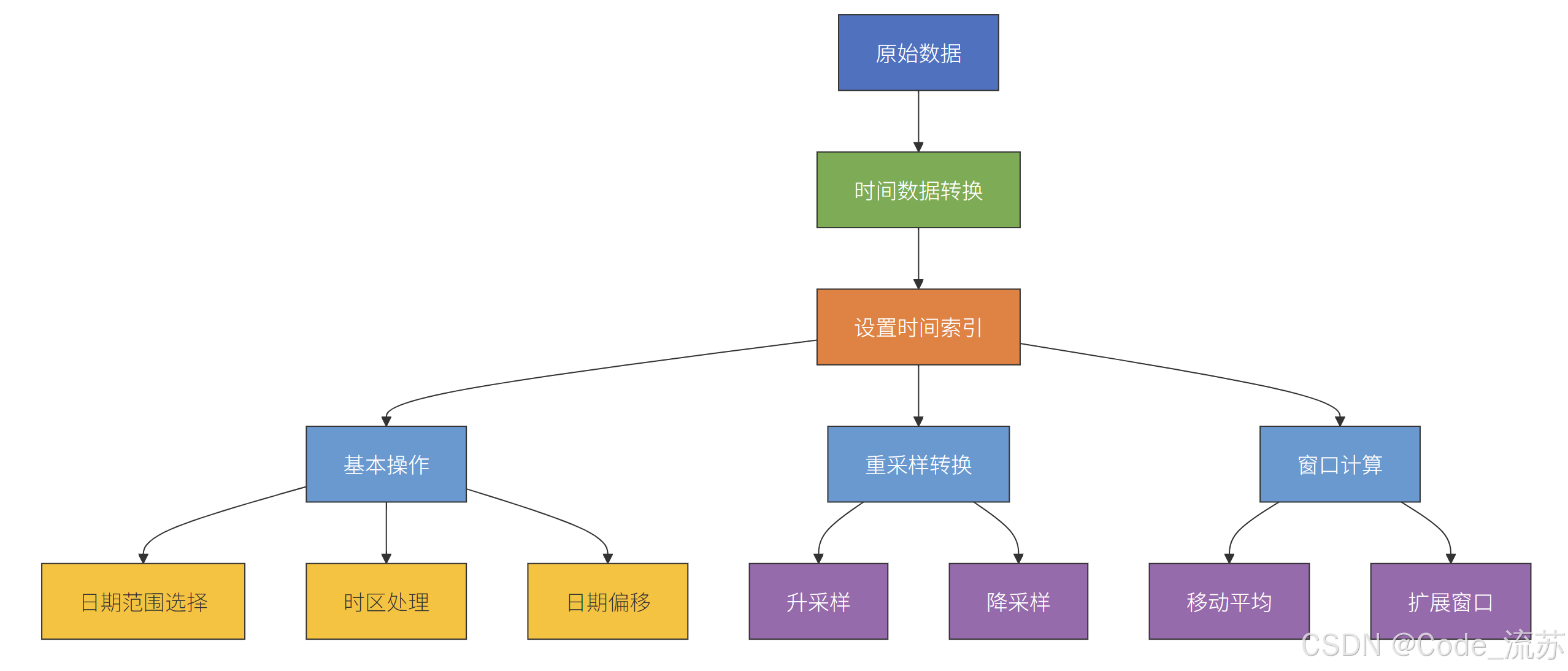
1. 时间戳与时间段
Pandas有两种主要的时间相关对象:
- Timestamp :表示时间点,类似于Python的
datetime - Period:表示时间段,如"2023年1月"或"2023年第一季度"
python
# 创建时间戳
ts = pd.Timestamp('2023-01-15 12:30:00')
print(ts)
# 创建时间段
period = pd.Period('2023-01', freq='M') # 月度频率
print(period)2. 创建时间序列数据
我们可以通过多种方式创建时间序列数据:
python
# 创建日期范围
date_range = pd.date_range(start='2023-01-01', periods=10, freq='D')
print(date_range)
# 创建带时间序列索引的数据
ts_data = pd.Series(np.random.randn(10), index=date_range)
print(ts_data)3. 时间序列索引与切片
时间序列数据可以使用时间进行索引和切片:
python
# 准备一年的每日数据
daily_data = pd.Series(
np.random.rand(365),
index=pd.date_range(start='2023-01-01', periods=365, freq='D')
)
# 使用时间索引
print(daily_data['2023-02-14']) # 查看特定日期的数据
# 时间范围切片
print(daily_data['2023-03-01':'2023-03-07']) # 查看一周的数据
# 使用年、月、日等属性进行筛选
march_data = daily_data[daily_data.index.month == 3] # 筛选3月的数据
print(march_data)4. 重采样
重采样是改变时间序列频率的过程:
- 升采样:从低频到高频(如月→日)
- 降采样:从高频到低频(如日→月)
python
# 准备每日销售数据
daily_sales = pd.Series(
np.random.randint(100, 500, size=365),
index=pd.date_range(start='2023-01-01', periods=365, freq='D')
)
# 降采样:日→月,求和
monthly_sales = daily_sales.resample('M').sum()
print(monthly_sales)
# 降采样:日→周,求平均
weekly_sales = daily_sales.resample('W').mean()
print(weekly_sales.head())
# 升采样:月→日,填充
monthly_data = pd.Series(
[1000, 1200, 1500, 1800, 2100, 2400],
index=pd.date_range(start='2023-01-31', periods=6, freq='M')
)
daily_filled = monthly_data.resample('D').ffill() # 前向填充
print(daily_filled.head())5. 移动窗口函数
移动窗口函数是时间序列分析中非常有用的工具:
python
# 7天移动平均
sales_7d_ma = daily_sales.rolling(window=7).mean()
print(sales_7d_ma.head(10))
# 30天移动平均
sales_30d_ma = daily_sales.rolling(window=30, min_periods=1).mean()
print(sales_30d_ma.head())
# 累计统计
cumulative_sales = daily_sales.expanding().sum()
print(cumulative_sales.head())五、实战练习:销售数据分析
现在,让我们综合运用所学知识,对销售数据进行分析和可视化。
1. 准备数据
python
import pandas as pd
import numpy as np
# 创建更完整的销售数据
np.random.seed(42) # 设置随机种子以确保结果可重现
# 创建日期范围:2023年全年
dates = pd.date_range(start='2023-01-01', end='2023-12-31', freq='D')
# 产品类别
products = ['电子产品', '服装', '食品', '家居']
# 创建空的DataFrame
sales_data = []
# 生成数据
for date in dates:
# 为每个产品生成销售记录
for product in products:
# 模拟周末销量增加
weekend_factor = 1.5 if date.dayofweek >= 5 else 1.0
# 模拟季节性变化:夏季(6-8月)电子产品和食品销量增加,冬季(11-2月)服装和家居销量增加
seasonal_factor = 1.0
if product in ['电子产品', '食品'] and date.month in [6, 7, 8]:
seasonal_factor = 1.3
elif product in ['服装', '家居'] and date.month in [11, 12, 1, 2]:
seasonal_factor = 1.4
# 生成销售量
quantity = int(np.random.randint(10, 50) * weekend_factor * seasonal_factor)
# 生成销售额 (价格在100-500之间)
price = np.random.randint(100, 500)
amount = quantity * price
# 添加到列表
sales_data.append({
'日期': date,
'产品': product,
'销量': quantity,
'单价': price,
'销售额': amount
})
# 创建DataFrame
sales_df = pd.DataFrame(sales_data)
# 显示数据样本
print(sales_df.head())
print(f"数据集大小: {sales_df.shape}")输出结果:

2. 分组分析
python
# 按产品分组,计算总销售额和平均销售额
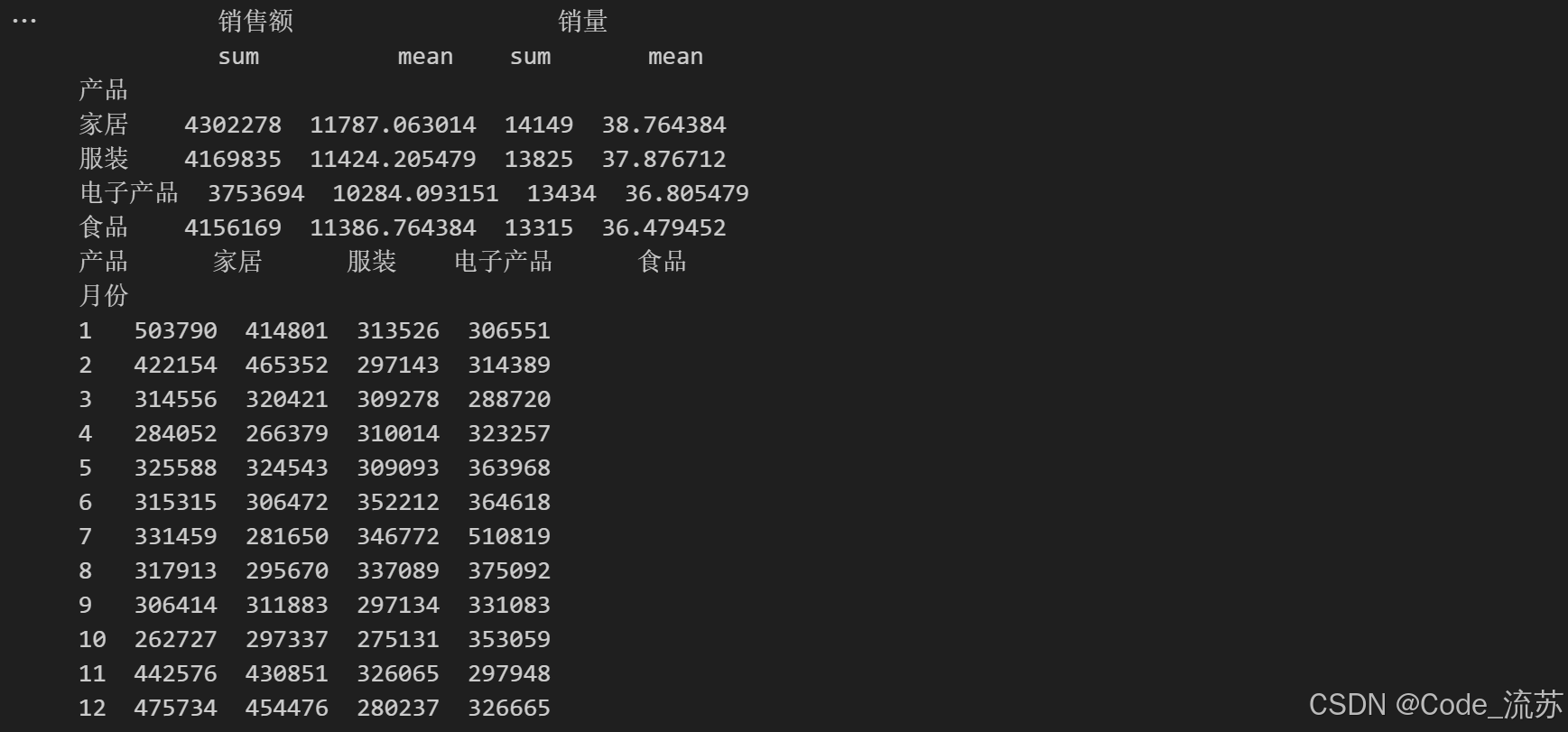
product_summary = sales_df.groupby('产品').agg({
'销售额': ['sum', 'mean'],
'销量': ['sum', 'mean']
})
print(product_summary)
# 按月份和产品分组,计算每月每种产品的总销售额
sales_df['月份'] = sales_df['日期'].dt.month
monthly_product_sales = sales_df.groupby(['月份', '产品'])['销售额'].sum().unstack()
print(monthly_product_sales)输出结果:
3. 时间序列分析
python
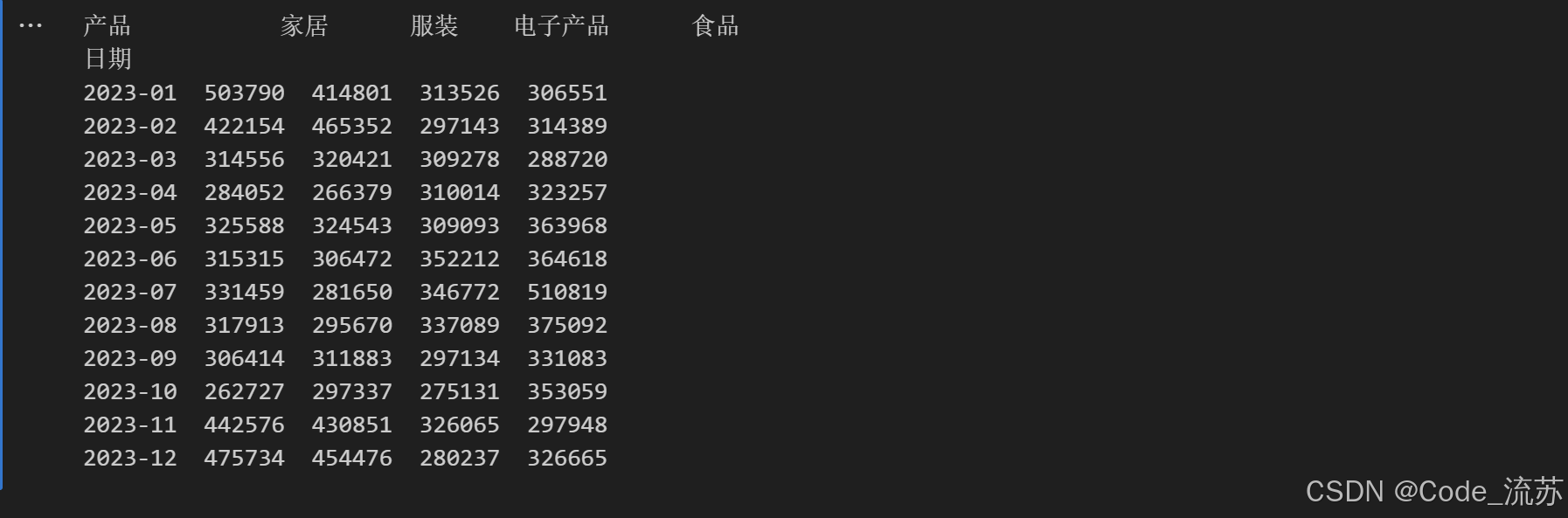
# 将数据按日期和产品分组,计算每日每种产品的总销售额
daily_product_sales = sales_df.groupby(['日期', '产品'])['销售额'].sum().unstack()
# 计算7天移动平均
moving_avg = daily_product_sales.rolling(window=7).mean()
# 每月销售额趋势
monthly_sales = sales_df.groupby([sales_df['日期'].dt.to_period('M'), '产品'])['销售额'].sum().unstack()
print(monthly_sales)输出结果:
4. 数据可视化
python
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文显示(防止中文注释出错,实际图表无中文)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置图表风格
plt.style.use('seaborn-v0_8-darkgrid')
plt.figure(figsize=(14, 8))
# 绘制每月产品销售额趋势(Monthly Sales Trend by Product)
monthly_sales.plot(kind='line', marker='o')
plt.title('Monthly Sales Trend by Product in 2023', fontsize=14)
plt.xlabel('Month', fontsize=12)
plt.ylabel('Sales Amount', fontsize=12)
plt.legend(title='Product Category')
plt.grid(True)
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('monthly_sales_trend.png', dpi=300)
plt.show()
# 绘制产品销售额占比饼图(Sales Proportion by Product)
plt.figure(figsize=(10, 8))
product_total = sales_df.groupby('产品')['销售额'].sum()
plt.pie(product_total, labels=product_total.index, autopct='%1.1f%%',
startangle=90, shadow=True, explode=[0.05, 0, 0, 0])
plt.title('Sales Proportion by Product', fontsize=14)
plt.axis('equal')
plt.savefig('product_sales_pie.png', dpi=300)
plt.show()
# 绘制季节性变化热力图(Heatmap of Monthly Average Sales by Product)
plt.figure(figsize=(12, 8))
pivot_table = sales_df.pivot_table(
index=sales_df['日期'].dt.month,
columns='产品',
values='销售额',
aggfunc='mean'
)
sns.heatmap(pivot_table, annot=True, fmt='.0f', cmap='YlGnBu')
plt.title('Heatmap of Monthly Average Sales by Product', fontsize=14)
plt.xlabel('Product Category', fontsize=12)
plt.ylabel('Month', fontsize=12)
plt.tight_layout()
plt.savefig('monthly_product_heatmap.png', dpi=300)
plt.show()输出结果:


六、总结与拓展
通过本文的学习,我们掌握了Pandas中的数据分组与聚合 、排序与排名 以及时间序列分析等高级数据分析技能。这些技能对于从数据中提取有价值的信息至关重要。
1. 关键知识点回顾
- 数据分组 :使用
groupby()按一个或多个列对数据进行分组 - 聚合函数 :通过
sum()、mean()、count()等函数对分组数据进行聚合计算 - 排序 :使用
sort_values()和sort_index()对数据进行排序 - 排名 :使用
rank()对数据进行排名,支持多种处理并列情况的方法 - 时间序列处理:包括时间索引、重采样、移动窗口等操作
2. 实际应用场景
python
- 销售数据分析:按产品、地区、时间等维度分析销售趋势和模式
- 金融数据分析:股票价格时间序列分析,计算移动平均线和波动性
- 用户行为分析:按用户群体分组,分析不同群体的行为特征
- 传感器数据处理:对高频采集的传感器数据进行降采样和异常检测3. 学习资源推荐
- 官方文档 :Pandas官方文档
- 书籍:《Python for Data Analysis》by Wes McKinney
- 在线课程:Coursera的"Data Analysis with Python"
练习题:
- 使用本文介绍的销售数据,按产品和月份分组,计算销售额最高的前3个产品-月份组合。
- 实现一个函数,对时间序列数据检测异常值(比如超过3个标准差的值)。
- 尝试使用groupby和transform计算每个产品的销售额占该产品总销售额的百分比。
希望这篇文章能帮助你更好地理解Pandas的高级数据分析功能。如有问题,欢迎在评论区留言,在下一篇文章中,星球之旅的第26天,我们将探索 Matplotlib 可视化,敬请期待!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!