本文介绍在单作业模式下Flink提交作业的具体流程,如下图所示。
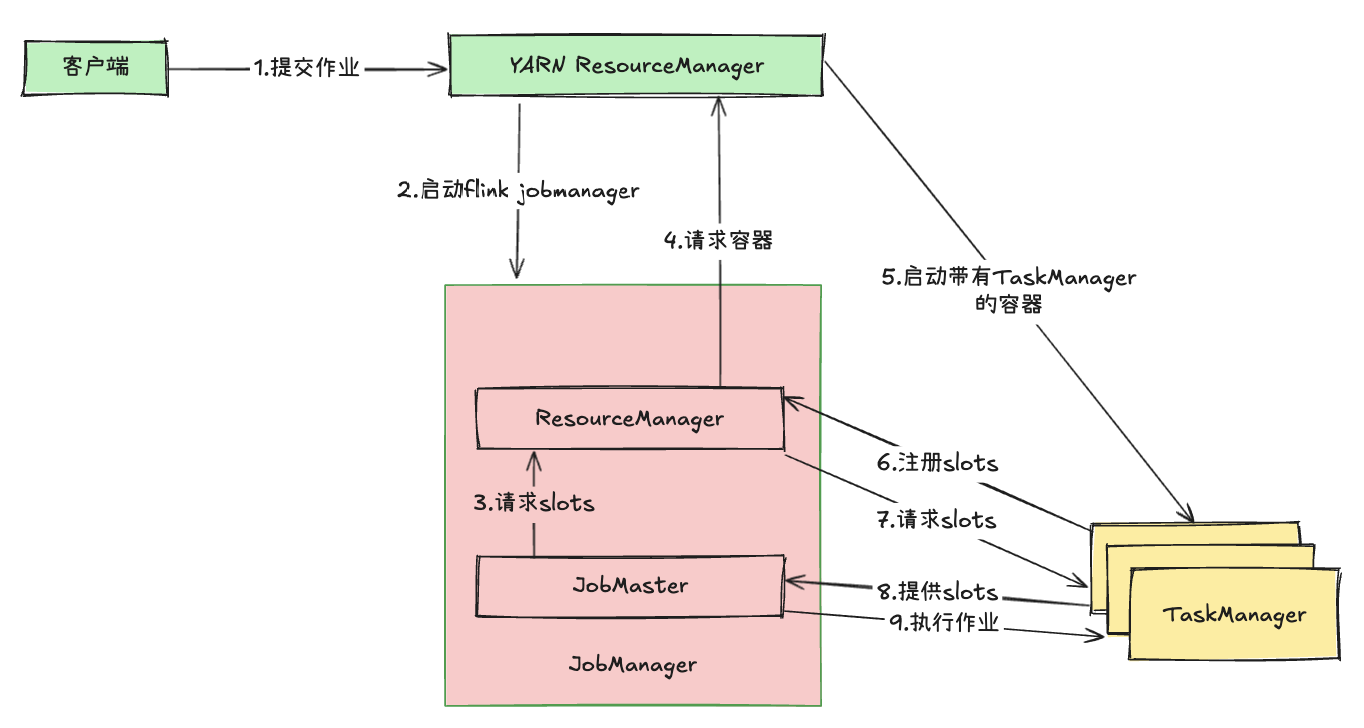
- 客户端将作业提交给YARN的RM;
- YARN的RM启动Flink JobManager,并将作业提交给JobMaster;
- JobMaster向Flink内置的RM请求slots;
- Flink内置的RM向YARN RM请求容器;
- YARN 启动带有TaskManager的容器;
- TaskManager启动之后,向Flink的RM注册自己的可用slots;
- Flink的RM通知TaskManager为作业提供slots;
- TaskManager连接到对应的JobMaster,并提供slots;
- JobMaster将需要执行的作业分发给TaskManager执行。