
背景
我的毕业设计是《Development of an AI-Powered Mobile Application for Animal Identification and Information》,开发一个可以识别动物的移动软件,在跟导师沟通后打算用Yolo作为深度学习识别模型,移动端软件使用原生的iOS开发,即在XCode上使用Swift+SwiftUI进行iOS开发,原本就一直对iOS开发很感兴趣,借这次机会好好学习一下原生的iOS开发。
在上次实现模型识别接口后,这次我训练了自己的模型,并部署在app中。
自主模型训练
要训练自己的YOLO模型,需要有自己的数据库,并根据使用场景选择合适大小、版本的yolo模型,并且最好在有CUDA环境下的环境进行训练,得出训练结果后要手动把.pt模型导出为.mlpackage文件即为Coreml格式的模型,再部署在app中。
数据集寻找
数据集我是在Kaggle上找的,找到的是一个名字叫做Open Image V7 Animals YOLO的数据集。
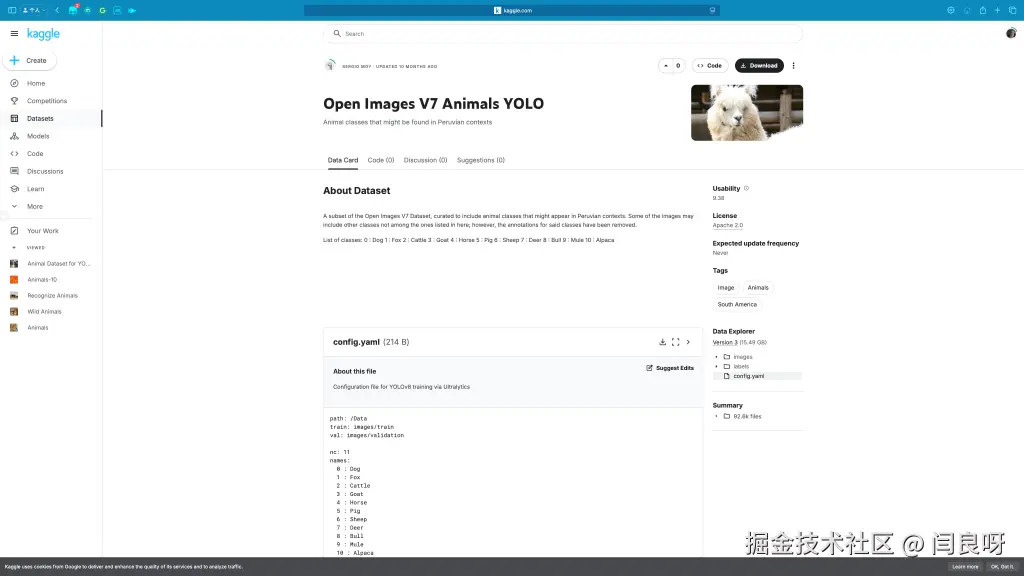
在找数据集的过程中需要注意的是,本项目用的是Yolo框架,而yolo采用的标注数据集的格式是每一张图片用一个txt文件文件,其中txt的每一行包含一个目标,每一行用空格分开5个值,其中第一个值为类别ID,接下来四个值是以xywh格式的四个0到1之间的数,分别代表左上角的xy值,以及wh大小。
这样子描述是不是一头雾水,一开始我也搞不懂,按我的理解是这样描述的,我试着更具体表示出来。
| 名称 | 含义 |
|---|---|
| Class id | 该物体在模型中对应的ID |
| X | 横坐标与图像宽度的⽐值 |
| Y | 纵坐标与图像⾼度的⽐值 |
| Width | 物体宽度与图像的宽度的⽐值 |
| Height | 物体⾼度与图像的⾼度的⽐值 |
一个txt文件可能内容如下
txt
0 0.503125 0.70729167 0.38125 0.5604167
...
6 0.3 0.4 0.5 0.6总之,我们找yolo数据集的时候需要找这样格式label的数据集,当然也有其他格式的数据集,如果是那样的话我们还需要手动写脚本将其转换为如此,那就很麻烦了。
在找完数据集后,将其下载到训练机本地,并按照格式使其能被yolo发现并正常训练。
模型训练
至于训练过程应该没有很大的问题,只要指定数据集为我们的这个就行,我们暂时不对yolo模型做什么其他的处理。
shell
python train.py --data <我们的数据集描述文件>.yaml --epochs 300 --weights yolo11m.pt --batch-size 128模型训练完后得到一个.pt模型文件,以及一些训练结果图,严格意义上来讲我这个数据集不是很合理,因为不同类别的数量很不平衡,通过图片可以看到Dog很多,其他相比之下就少了,但是少的也有很少的。





我们可以用yolo detect对其验证一下。

 !file(Maximum upload size exceeded; nested exception is java.lang.IllegalStateException: org.apache.tomcat.util.http.fileupload.FileUploadBase$SizeLimitExceededException: the request was rejected because its size (14891419) exceeds the configured maximum (2097152))
!file(Maximum upload size exceeded; nested exception is java.lang.IllegalStateException: org.apache.tomcat.util.http.fileupload.FileUploadBase$SizeLimitExceededException: the request was rejected because its size (14891419) exceeds the configured maximum (2097152))
可以看到效果其实、好像、也许、应该、也、还算可以,吧。总之至此模型训练部分就完成啦。
模型转化为CoreML
想哟啊部署在iOS平台,那么模型就必须转为CoreML格式的,在YOLO官方导出CoreML文档中可以看到导出方案,不过好像必须要在苹果电脑上才能导出。
不过在这里出现了一个BUG,我不知道是我的问题还是yolo导出coreml的问题,在导出命令中有一个参数是nms,这个的意思是在模型最后一层加一个导出格式设置,自动将导出的结果设为id和对应的可信度,否则需要我们自己从tensor格式的数据中提取。
但是我自己的模型导出后效果就不好,识别就像乱码,我又试着导出yolo官方的模型,一样的配置效果又是好的,后面我在训练的时候手动把训练的类改为80,就像官方模型内置的80个类一样,这样操作曲线救国使得我的模型结果也不错了。
之所以确定不是我代码的问题是因为我又用了苹果官方例程,同时调用了所有模型,只有我的模型有问题,但是设置为80类就没问题了,很奇怪很想提个issue但是不知道要如何总结这个问题。
总之最后就得到了一个coreml文件,可以用Xcode打开,可以查看该模型的基本信息,在导出nms为True之后,就可以在这里的Preview里上传图片进行测试。
 !file(Maximum upload size exceeded; nested exception is java.lang.IllegalStateException: org.apache.tomcat.util.http.fileupload.FileUploadBase$SizeLimitExceededException: the request was rejected because its size (14943999) exceeds the configured maximum (2097152))
!file(Maximum upload size exceeded; nested exception is java.lang.IllegalStateException: org.apache.tomcat.util.http.fileupload.FileUploadBase$SizeLimitExceededException: the request was rejected because its size (14943999) exceeds the configured maximum (2097152))
至此,自主训练模型部分全部结束了。
自主模型识别
原本这时只要把代码中的模型改为咱们自己的就行了,但是嘞我发现自己的模型图片输入是侧着的,也就是说我们必须把手机侧过来拍到的图片才能正着进入模型,否则识别效果就会很差。
按照正常逻辑应该要对app做方向监控和自适应,确保怎么转都有好的效果,但是我实在是折腾不动了,就索性把输入框也改成侧面的,让整个摄像头显示界面需要用户把手机侧过来看,就有了如下效果。
!file(Maximum upload size exceeded; nested exception is java.lang.IllegalStateException: org.apache.tomcat.util.http.fileupload.FileUploadBase$SizeLimitExceededException: the request was rejected because its size (15483405) exceeds the configured maximum (2097152))
这样子,实时识别效果就不错了。
动物识别记录
除了识别,本项目还需要对识别的物种进行具体的介绍,所以我就设计了一个拍摄按钮,按下后就可以将识别到的图片记录下来,并且在识别结果中可以查看详情。
在有识别结果时,按下按钮,就可以将识别部分截图出来存在内存当中(是的没有数据库,直接存内存吧,累了)。
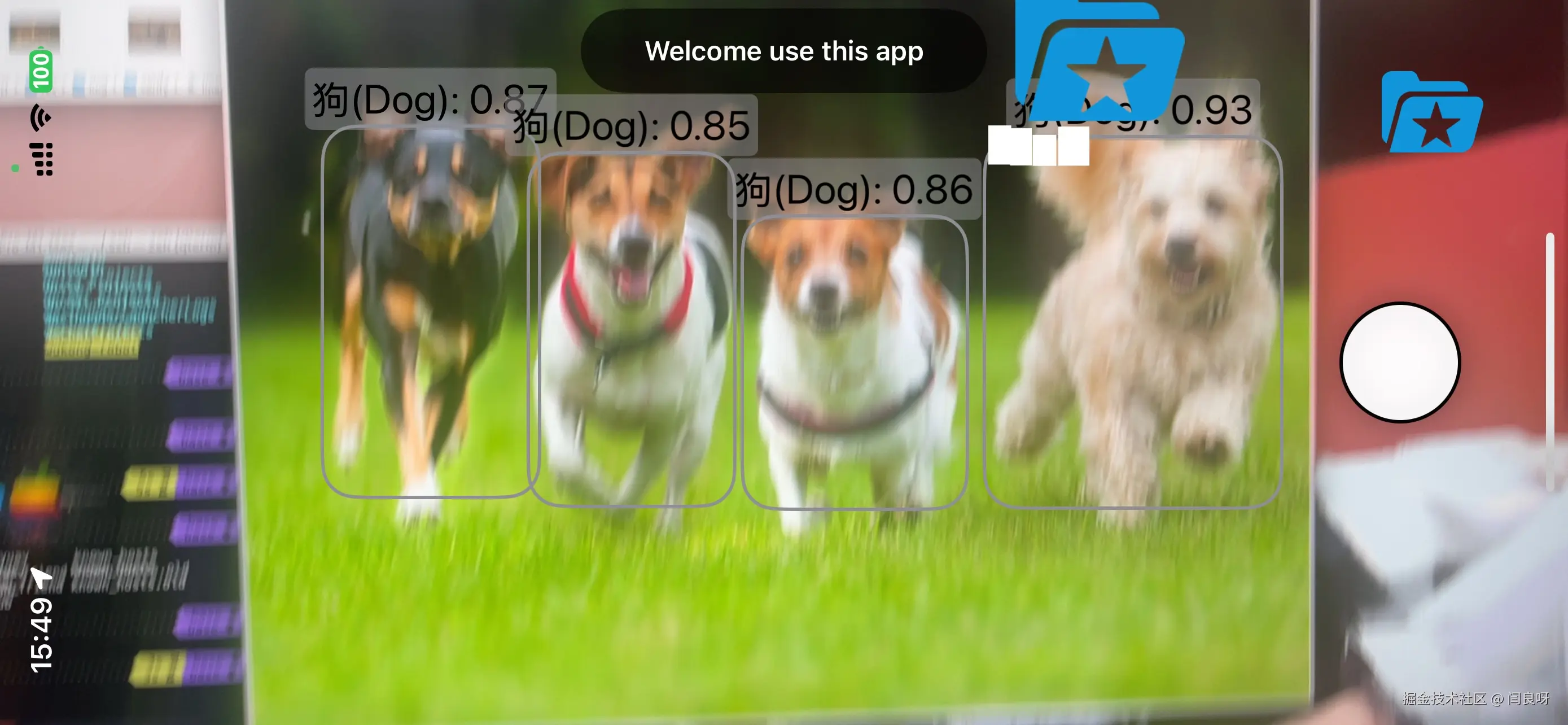
按下按钮后,会有动画显示存在了右上角的文件夹中。
点击右上角的蓝色文件夹就进到了识别记录页面。
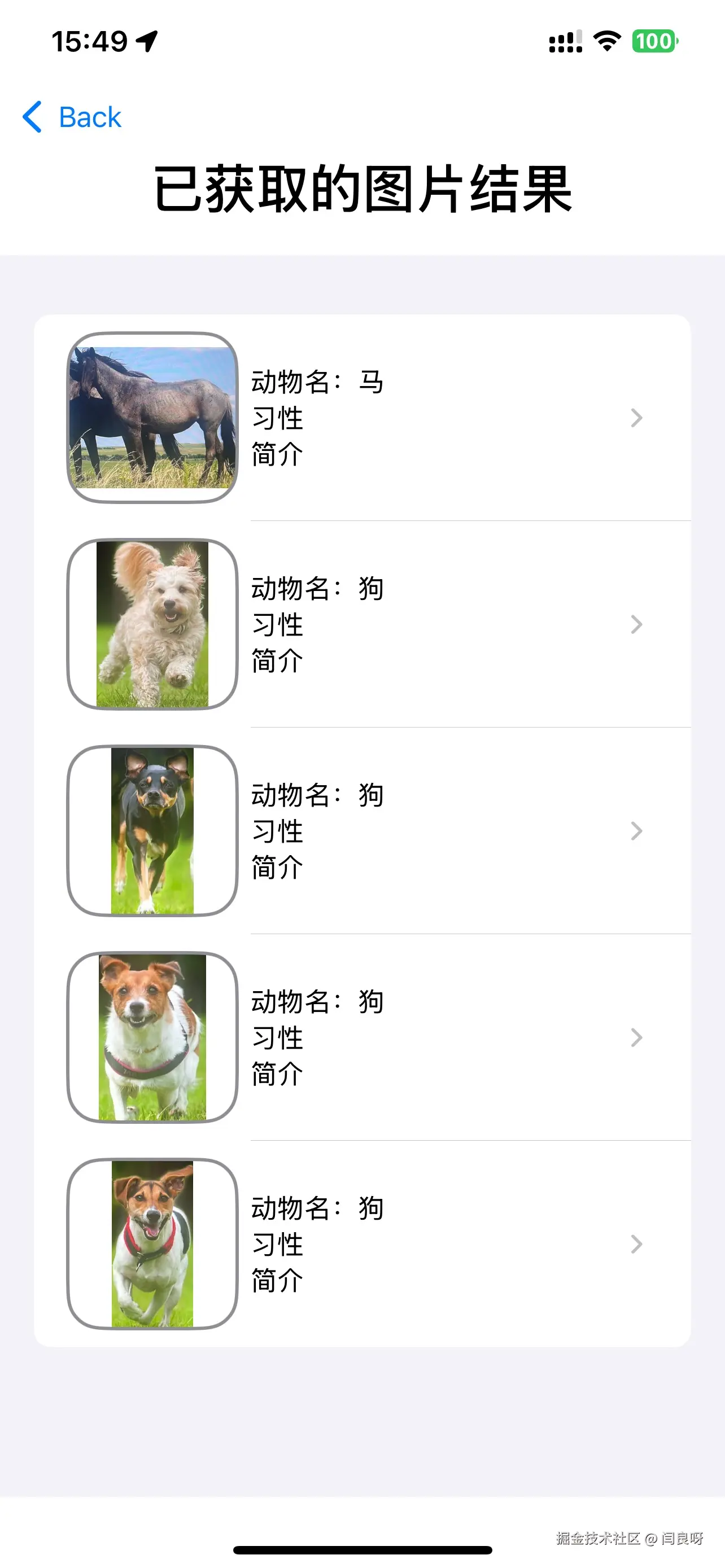
值得注意的是,预览框左侧就是识别结果的裁剪图,对于裁剪也有一个大坑。
swift
Button(action: {
//NotificationCenter.default",允许APP中的不同部分传递消息,全局共享对象,用于广播消息
if(self.predictObject?[0].classId != -1) {
self.isFlashing = true
NotificationCenter.default.post(name: .takePhoto, object: nil)
}
}) {
Circle()
.fill(Color.white)
.frame(width: 70, height: 70)
.overlay(Circle().stroke(Color.black, lineWidth: 2))
.shadow(radius: 10)
}
.padding(.bottom, 30)在拍照按钮中,按下后会判断现在是否有识别出结果的动物,有的话就会发送一个拍下照片的信息,执行回调函数takePhoto。
swift
@objc private func takePhoto() {
print("接收到拍照通知")
let settings = AVCapturePhotoSettings()
settings.flashMode = .auto
photoOutput.capturePhoto(with: settings, delegate: self)
}在takePhoto函数中执行拍照设置,并调用photoOutput函数中的capturePhoto方法进行拍照。
swift
func photoOutput(_ output: AVCapturePhotoOutput, didFinishProcessingPhoto photo: AVCapturePhoto, error: Error?) {
autoreleasepool {
guard let imageData = photo.fileDataRepresentation(),
let image = UIImage(data: imageData) else { return }
print("拍好照片了")
self.coordinator?.didCapturePhoto(image)
}之后将拍好的照片传到coordinator里的didCapturePhoto函数,在这个函数里,将会结合当前预测的所有结果,以及当前的图片将图片中的结果截图出来。
swift
func didCapturePhoto(_ image: UIImage) {
print("接收到图片:\(image)")
if let predictObjectList = self.parent.predictObject {
for object in predictObjectList {
if let croppedImage = cropImage(image: image, object: object) {
let gotObject: GotObject = GotObject(predictObject: object, image: croppedImage)
self.parent.gotObjectList.append(gotObject)
}
}
}
DispatchQueue.main.asyncAfter(deadline: .now() + 1.0) {
self.parent.isFlashing = false
}
}问题主要出在cropImage,也就是具体裁剪的函数中。
swift
func cropImage(image: UIImage, object: PredictObject) -> UIImage? {
guard let cgImage = image.cgImage else {
return nil
}
let height = CGFloat(cgImage.width)
let width = CGFloat(cgImage.height)
let w: CGFloat = CGFloat(object.width) * width
let h: CGFloat = CGFloat(object.height) * height
let x: CGFloat = CGFloat(object.xCenter) * width - (w / 2)
let y: CGFloat = CGFloat(object.yCenter) * height - (h / 2)
let cropRect = CGRect(x: x, y: y, width: w, height: h)
return cropImageCore(image: image, to: cropRect)
}
func cropImageCore(image: UIImage, to rect: CGRect) -> UIImage? {
guard let cgImage = image.cgImage else {
return nil
}
let adjustedRect = CGRect(
x: rect.origin.y,
y: CGFloat(cgImage.height) - (rect.origin.x + rect.size.width),
width: rect.size.height,
height: rect.size.width
)
if let croppedCGImage = cgImage.cropping(to: adjustedRect) {
let croppedImage = UIImage(cgImage: croppedCGImage, scale: image.scale, orientation: image.imageOrientation)
print("Cropping successful")
return croppedImage
} else {
print("Cropping failed")
}
return nil
}这里我们主要用到了一下几个数据,rect:模型返回的目标位置,cgImage:当前截图的图片,包含width和height,cgImage.cropping(to: adjustedRect)函数:用于输入裁剪后的数据进行图片裁剪。
乍一看没啥毛病,但是问题在以上数据的坐标系不一样!!!,为了统一以下描述的手机方向为正着拿,rect中原点在左上角,x轴在上面,y轴在左边;cgImage的width是1920,height为1080;cropping函数接受的adjustedRect是原点在右上角,x轴再右边,y轴在上面。
总之就是非常混乱,再加上只能一次一次编译测试,花了我很长时间才搞清楚,浓缩为上面的代码。
至此,图片裁剪也成了。
图片预览
接下来我想要点击预览图可以有大图出来,供参考细节,首先我为预览图单独写了个View,输入图片在其中预览。
swift
struct FullScreenZoomedImage: View {
var image: UIImage
var onDismiss: () -> Void
@State private var scale: CGFloat = 1.0
@State private var offset: CGSize = .zero
@State private var lastOffset: CGSize = .zero
var body: some View {
ZStack {
Color.white.edgesIgnoringSafeArea(.all) // 设置背景为白色
Image(uiImage: image)
.resizable()
.scaledToFit()
.scaleEffect(scale)
.offset(offset)
.frame(width: UIScreen.main.bounds.width, height: UIScreen.main.bounds.height)
.gesture(
SimultaneousGesture(
MagnificationGesture()
.onChanged { value in
scale = value
}
.onEnded { finalValue in
withAnimation {
scale = max(1.0, finalValue)
}
},
DragGesture()
.onChanged { value in
offset = CGSize(
width: lastOffset.width + value.translation.width,
height: lastOffset.height + value.translation.height
)
}
.onEnded { _ in
// 拖动结束后恢复偏移
withAnimation(.spring()) {
offset = .zero
}
lastOffset = .zero
}
)
)
.onTapGesture {
onDismiss()
}
.rotationEffect(.degrees(270))
}
}
}然后在主页中使用一个sheet来点击显示。
swift
struct ResultView: View {
@Binding var gotObjectList: [GotObject]
@State var zoomedImage: UIImage? = nil
var body: some View {
VStack {
Text("已获取的图片结果")
.font(.largeTitle)
.fontWeight(.medium)
ResultDetailView(gotObjectList: gotObjectList, zoomedImage: $zoomedImage)
Spacer()
}
.sheet(item: $zoomedImage) { image in
FullScreenZoomedImage(image: image) {
zoomedImage = nil
}
}
}
}这样点击图片的时候,image有值,就自动显示大图,并且在大图里可以实现放缩,移动等功能。



类别详情
本项目希望可以查看识别出来的物种的详情信息,所以需要一个界面展示,我的思路就是点击卡片就跳转到对应的详情页面。
swift
struct ResultDetailView: View {
var gotObjectList: [GotObject]
@Binding var zoomedImage: UIImage?
@State private var selectedItem: GotObject? = nil // 新增状态来记录当前被选中的物品
var body: some View {
List {
ForEach(gotObjectList, id: \.Id) { object in
HStack {
Image(uiImage: object.image)
.resizable()
.scaledToFit()
.frame(width: 100, height: 100)
.clipShape(RoundedRectangle(cornerRadius: 20)) // 裁剪图片为圆角
.overlay(
RoundedRectangle(cornerRadius: 20)
.stroke(Color.gray, lineWidth: 2)
)
.rotationEffect(.degrees(270))
.onTapGesture {
zoomedImage = object.image
}
Spacer()
NavigationLink(
destination: ObjectDetailView(object: object),
tag: object,
selection: $selectedItem
) {
VStack(alignment: .leading) {
Text("动物名:\(LabelList11[object.predictObject.classId])")
Text("习性")
Text("简介")
}
}
Spacer()
}
}
}
}
}使用的是NavigationLink方法,但是呢IDE报warning,NavigationLink+destination的方法有点out了,但是为了稳定性我还是先用了这个,这样子点击后就可以打开一个新的界面了。

至此,除了数据获取和展示的功能全部完毕了,接下来只需要将结果的部分功能实现就基本上大功告成啦。
总结
这部分的开发还是很复杂的,要考虑的东西更多,包括手机使用方向,图片格式,动画,Navigation等,感觉还是缺少系统性的学习,开发缺少了整体的规划,都是跟打游击一样,我认为还是需要静下来来慢慢设计。