注:VMware16 + CentOS8.5 虚拟机尝试,不能实现GPU直通,训练不能成功。需要单独服务器直接安装linux系统。还要查看自己的显卡是否支持CUDA
魔搭社区下载模型需要安装:
pip install modelscope使用量化需要安装:
pip install bitsandbytes下载模型
模型库:模型库首页 · 魔搭社区
找到你需要的模型
例如:Llama-3.2-3B-Instruct
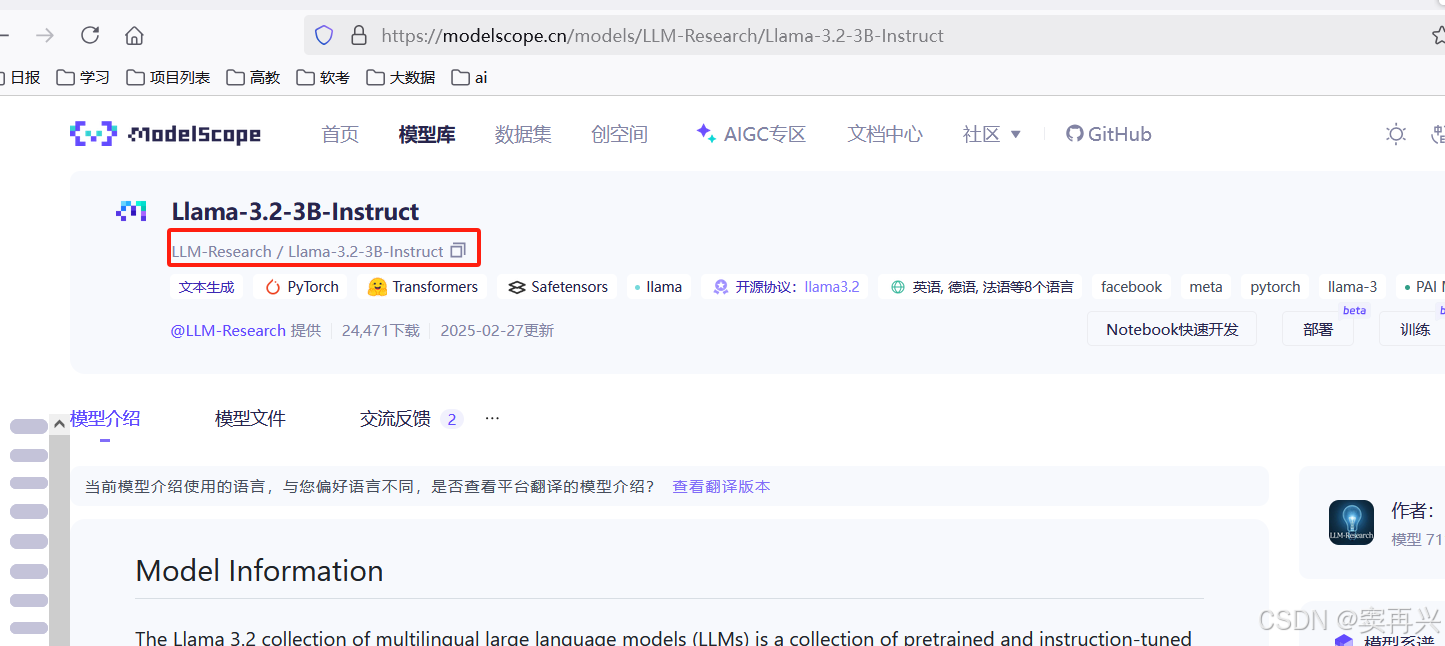
使用命令下载:
modelscope download --model LLM-Research/Llama-3.2-3B-Instruct默认下载的模型目录:
用户目录下的.cache/modelscope/hub/models/(cache前的点不要忽略)
LLaMA-Factory放入模型
cd ~/LLaMA-Factory/
mkdir models/
cp -r ~/.cache/modelscope/hub/models/ ~/LLaMA-Factory/models/运行LLaMA-Factory页面
conda activate llamafactory
llamafactory-cli webui配置页面属性

本地模型需要填写全路径:
/root/LLaMA-Factory/models/models/LLM-Research/Llama-3.2-3B-Instruct
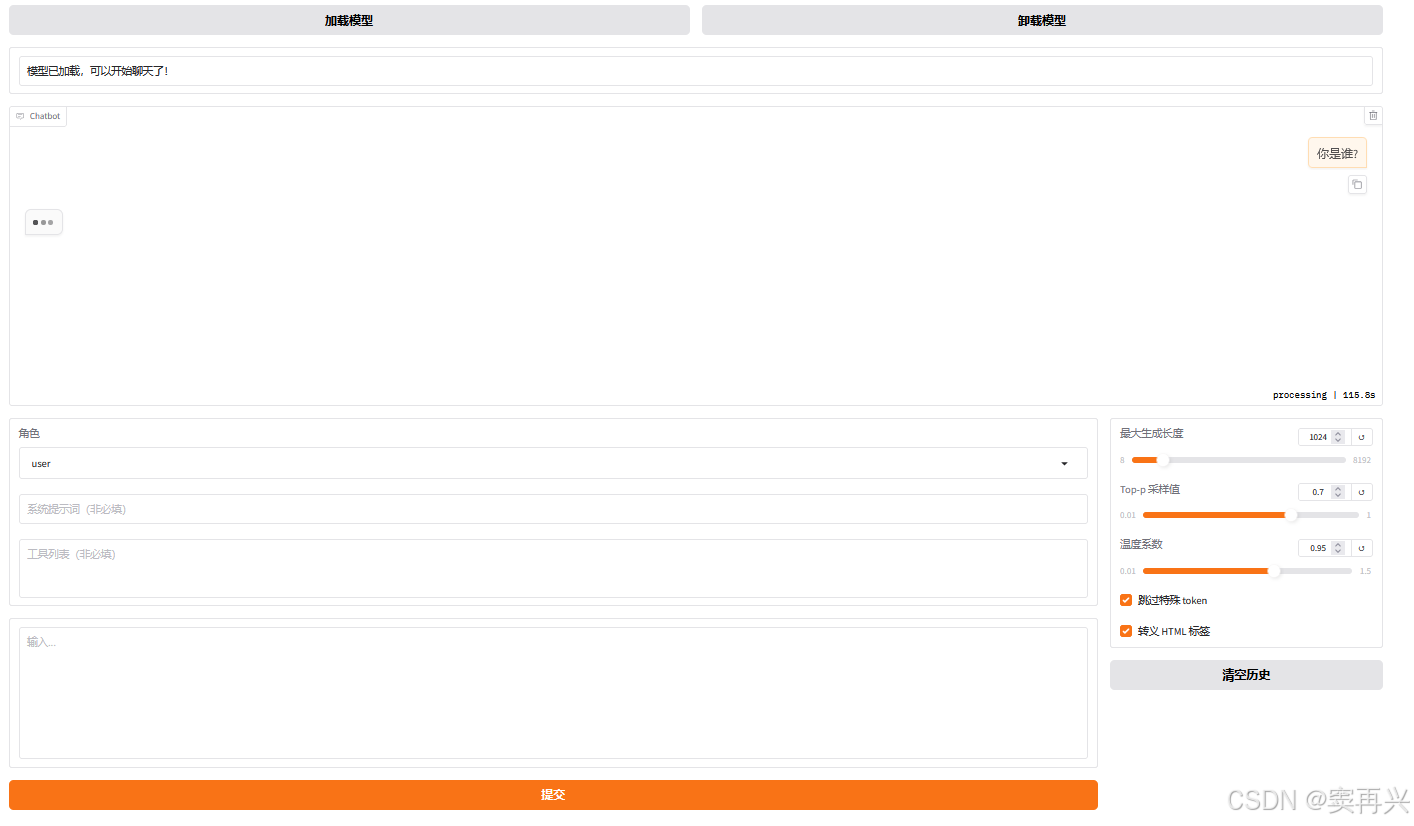
此时就表示,我们的模型可用了。
自定义数据集准备
下载示例数据集
以下是使用示例数据集的步骤,假设您使用的是PAI提供的多轮对话数据集:
cd LLaMA-Factory
wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama_factory/data.zip
mv data data.bak
unzip data.zip -d data查看数据集
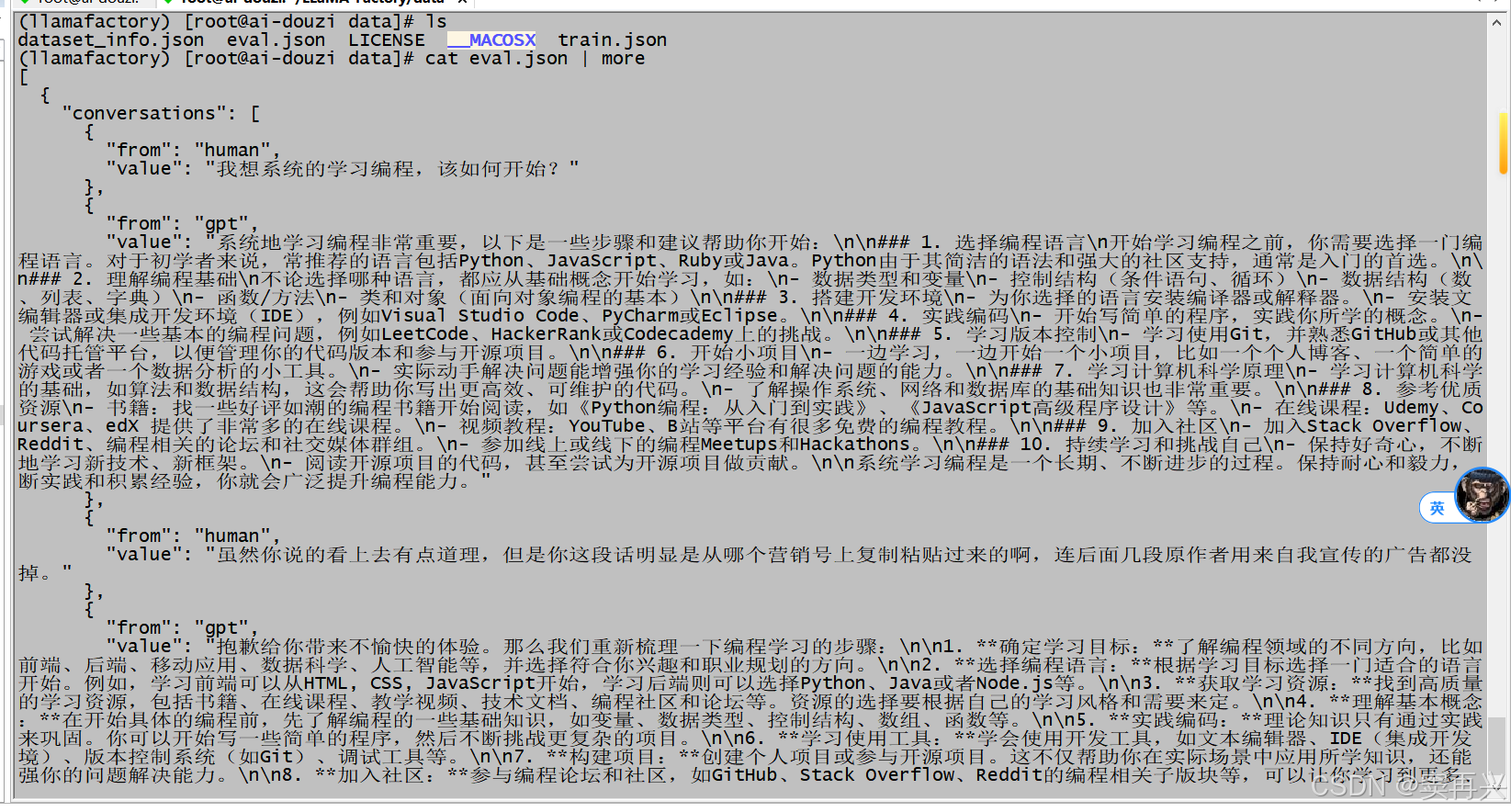
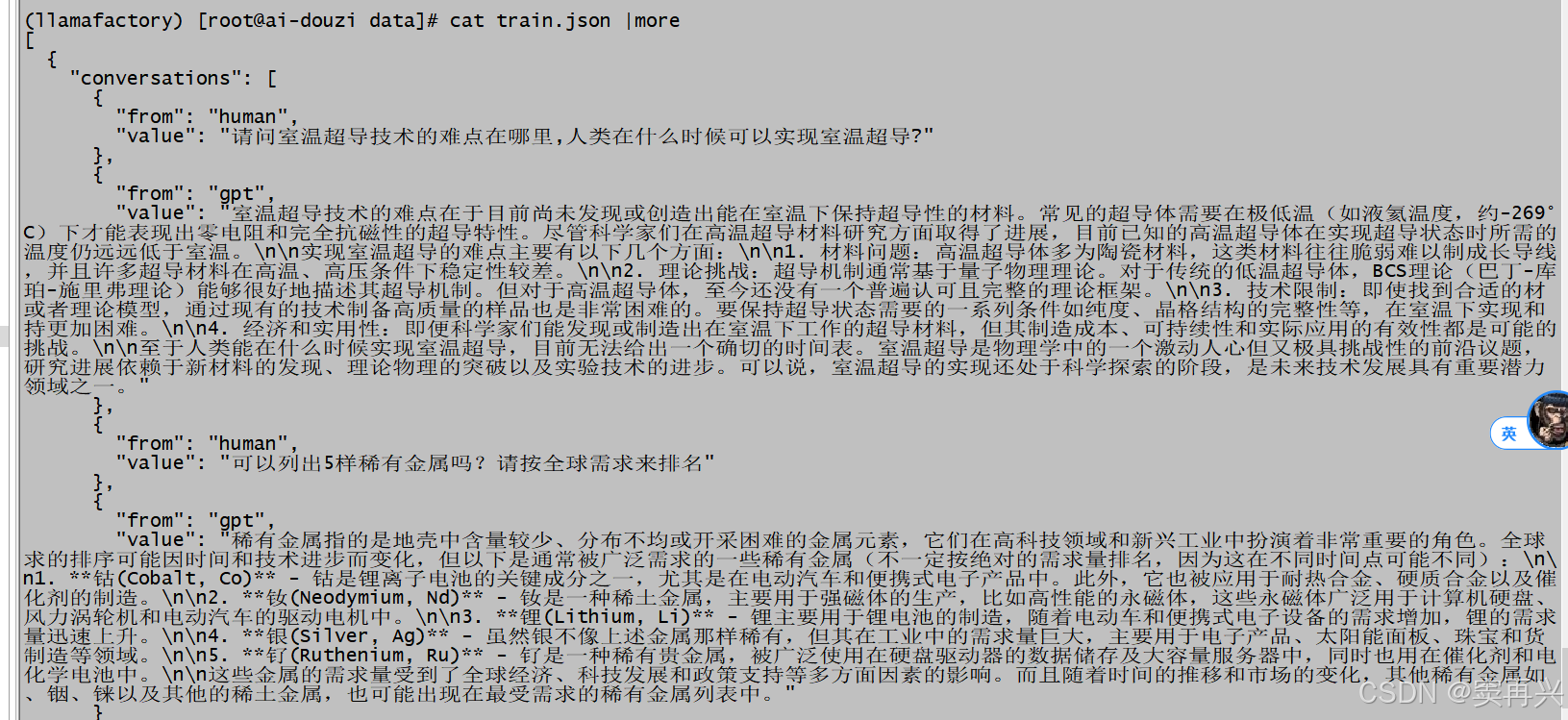
设置训练参数

可以打开量化进行加速;
下方数据集是选择出现的,不是自己填进去的,如果不行,就把数据路径搞成全路径。
开始微调
在Web UI中设置好参数后,您可以开始模型微调过程。微调完成后,您可以在界面上观察到训练进度和损失曲线。

启动微调后需要等待大约20分钟,待模型下载完毕后,可在界面观察到训练进度和损失曲线。当显示训练完毕时,代表模型微调成功。

评估模型
未完成,待继续