目录
[1.explainable machine learning输入处理](#1.explainable machine learning输入处理)
[2.global explanation](#2.global explanation)
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是explainable machine learning如何处理输入,以及简单了解explainable machine learning分类中的global explanation。
1.explainable machine learning输入处理
人眼观察
如何处理输入?最直观的办法就是用人眼去看,以语音为例子,将输入拿出来降到二维,并画在二维平面上。在下图示例(MFCC)中,每一个点代表一小段声音讯号,每一个颜色代表某一个speaker。实际上有很多句子是重复的,但是在图中是不会体现出来的,不同的人念同样的句子特征也差了很多。但是当我们把network拿出来看时结果就不同了,在第八层的输出中,每一条中叠加了很多颜色,就意味着多个人说了同样内容的某个句子。

probing
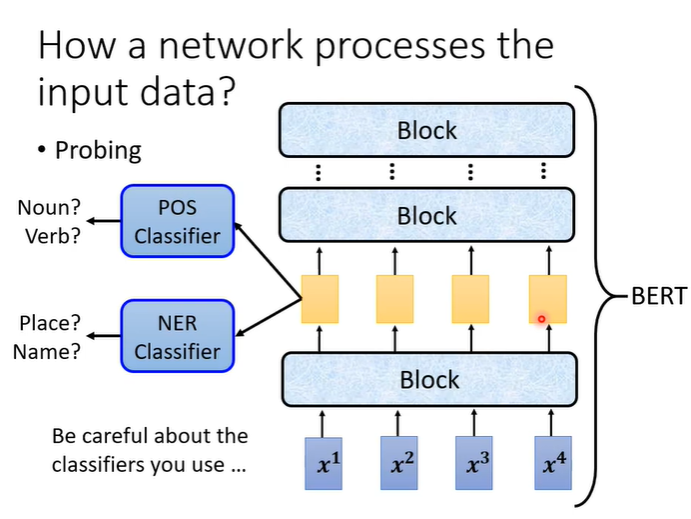
另一个技术叫做probing(探针),举例来说,假设想知道BERT到底学到了什么,我们可以训练一个探针,探针其实就是一个分类器,这个分类器是要根据一个向量决定一个词汇的词性,如果正确率高就说明embedding中有很多词性的资讯。但是我们需要小心分类器的强度,假设分类器的正确率很低,就无法保证embedding中有没有我们要的资讯。
2.global explanation
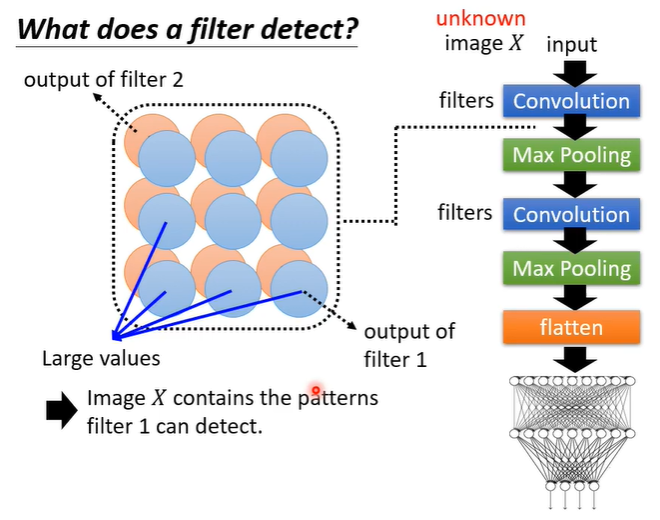
简单复习一下global explanation的概念,global explanation不针对特定的照片进行分析,而是根据我们训练好的模型去检查对这个network而言,一只猫长什么样子。举例来说,假设有一个convolutional neural network,它有很多的filter,把一张图片X作为输入convolutional layer会输出一个feature map,如果在feature map中(对应filter1)很多位置都有比较大的值,那么意味着图片X中有很多filter1负责侦测的特征。但我们想要知道,对于filter1对应的pattern是什么样,那么就需要机器去创造一张图片包含filter1对应的pattern。
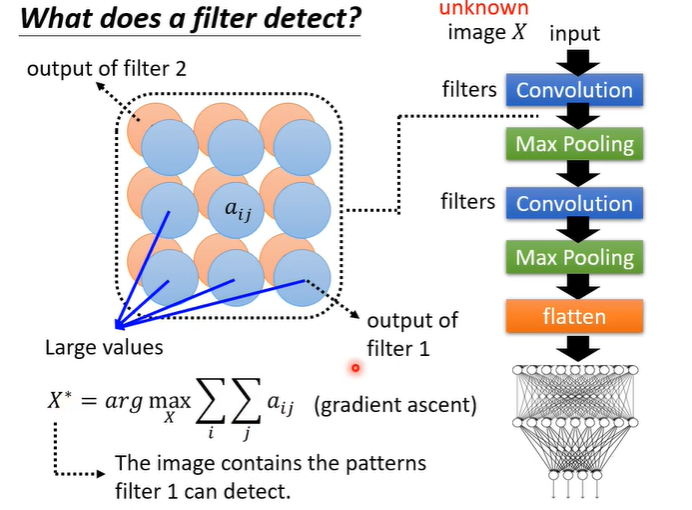
那么我们如何寻找这样的图片?假设filter1对应的feature map中矩阵元素为a_ij,我们去找一张图片,通过convolutional layer后filter1对应的feature map里的矩阵元素a_ij的总合越大越好。可以用gradient ascent的方法寻找最大值。
在实际的例子中如下图所示,有12个filter对应的pattern。这个例子是数字辨识,对应的filter看出想要的特征是横竖斜线之类的。

假设我们不是看filter,而是看最终的输出,会有什么现象呢?假设我们找到一个图片让某一个类别的分数越高越好,依旧是数字辨识,最终输出只要0-9,我们选一个数字出来,希望找到的图片输出是1的分数越高越好。但结果是我们只能看到一堆杂讯。这种现象可以用adversarial attack解释,在图片上加一些根本看不到的杂讯就会让机器看到各式各样的物件。所以想通过看最终的输出观察对机器而言某个对象是什么样子,并不是这么容易的。

如果想要看最终的输出去观察对机器而言某个对象是什么样子?我们需要在上面的方法加上更多的限制。举例来说,已经知道数字可能长什么样,那么可以把想要的限制加到optimization的过程中。那么现在我们需要的就不只是让某一个类别的分数(y_i)越高越好,还需要一个用来衡量这个图片多像一个数字的分数R(X)也越高越好。下图的例子中R(X)为减少白色的点。
