从零开始开发纯血鸿蒙应用
- 〇、前言
- [一、认识 speechRecognizer](#一、认识 speechRecognizer)
- 二、实现语音识别功能
- 三、总结
〇、前言
除了从图片中识别文本外,语音输入也是一种现代生活中较为普遍的数据输入方式。对于语音输入产生的数据,除了直接以声音模拟信号进行存储和传输外,就是将其转换为普通的文本数据即字符串类型的数据。
在鸿蒙系统中,想要集成通过语音输入文字的能力,比较简单,只需同上一篇一样,利用SDK中开箱即用的 AI 能力即可。
一、认识 speechRecognizer
在前面的语音朗读一篇中,我们利用鸿蒙 SDK 中 Core Speech Kit 里的 textToSpeech,完成了文本朗读功能。
实际上,在相同的 Core Speech Kit 里面,还有一个提供语音转文本能力的 speechRecognizer 。
1、使用方式
同 textToSpeech 一样,speechRecognizer 的使用,是通过引擎实例 SpeechRecognitionEngine 对象进行的,因此,集成语音识别能力的第一步,便是获得并持有 SpeechRecognitionEngine 实例。
SpeechRecognitionEngine 实例创建,也同样是一样工厂模式创建,而非直接 new 出来的。一般而言,获得 SpeechRecognitionEngine 对象实例之后,就可以开始进行语音识别了,而识别过程中,理所当然的需要写入一个音频数据。
2、依赖权限
音频数据,最直接的,就是利用麦克风去实时获取,而麦克风作为手机硬件资源,使用之前必须获得用户的授权,所以,就需要在合适的时机,向用户弹窗申请麦克风权限。
3、结果回写
语音识别结果,可以直接用字符串数据进行获取,只不过,结果的获取需要通过事件监听函数完成,而不是其他类型的方法返回。
二、实现语音识别功能
1、创建语音识别引擎
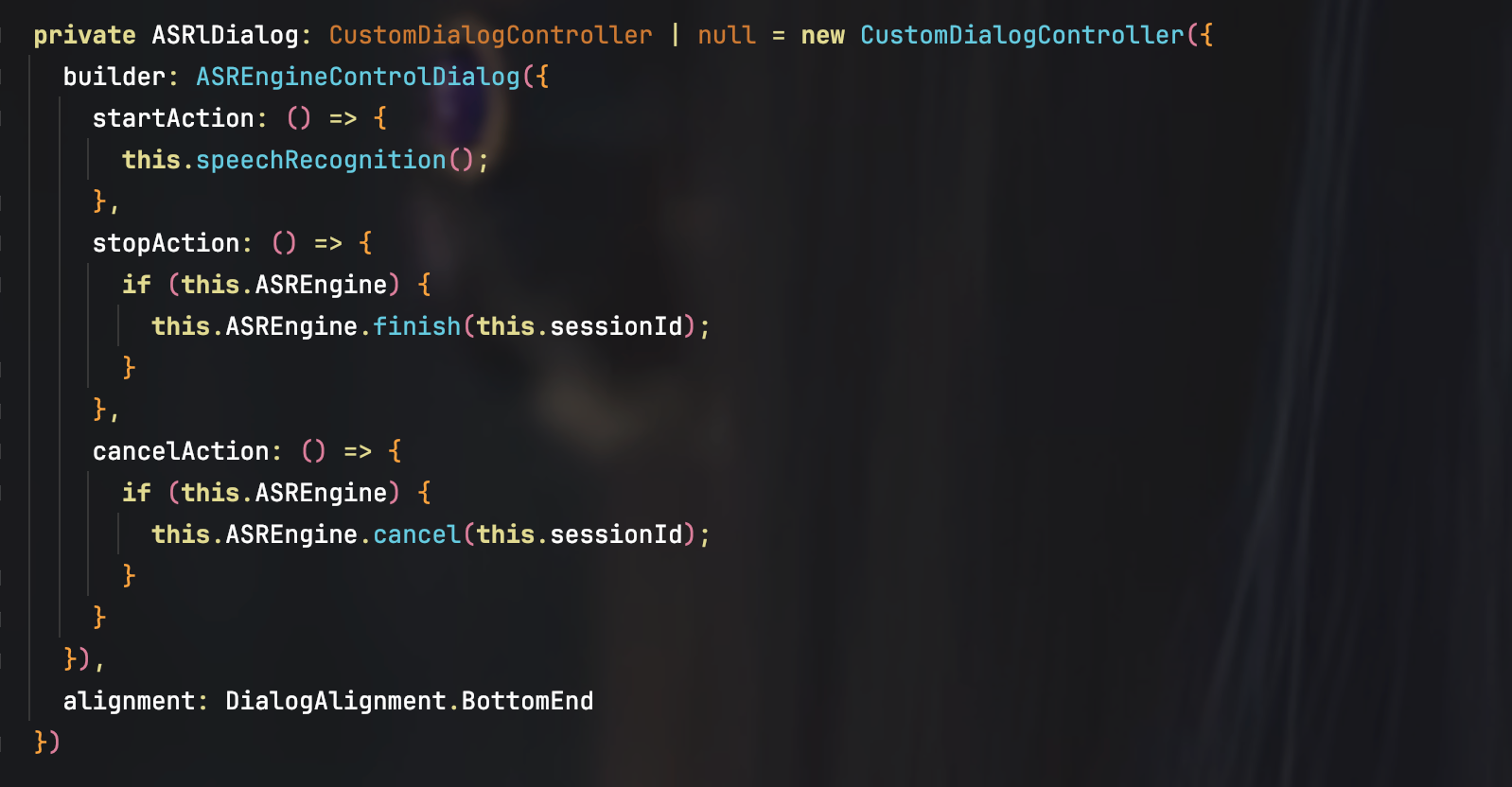
根据上面的理论,实现语音识别功能的第一步,就是获取和持有 SpeechRecognitionEngine,为此,可以在 EditPage 的 aboutToAppear 函数中,加上如下的一段代码:
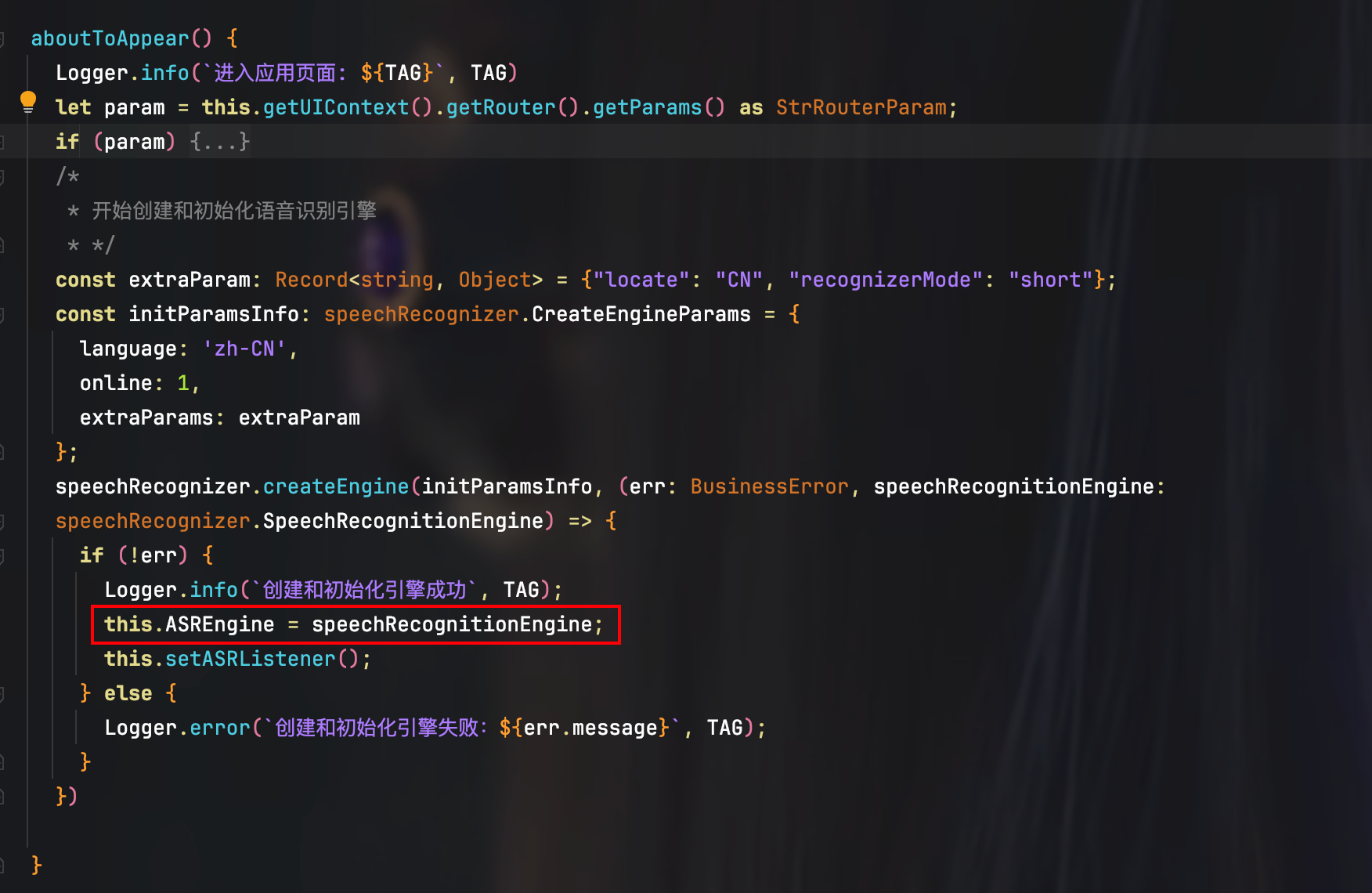
为了方便在其他地方调用 SpeechRecognitionEngine 对象,需要在 EditPage 中定义一个页面级全局有效的私有字段 ASREngine: private ASREngine: speechRecognizer.SpeechRecognitionEngine | null = null;,之所以要联合 null 类型,是为了在 EditPage 不可见时,将语音识别引擎实例所占用的内存资源及时释放掉。
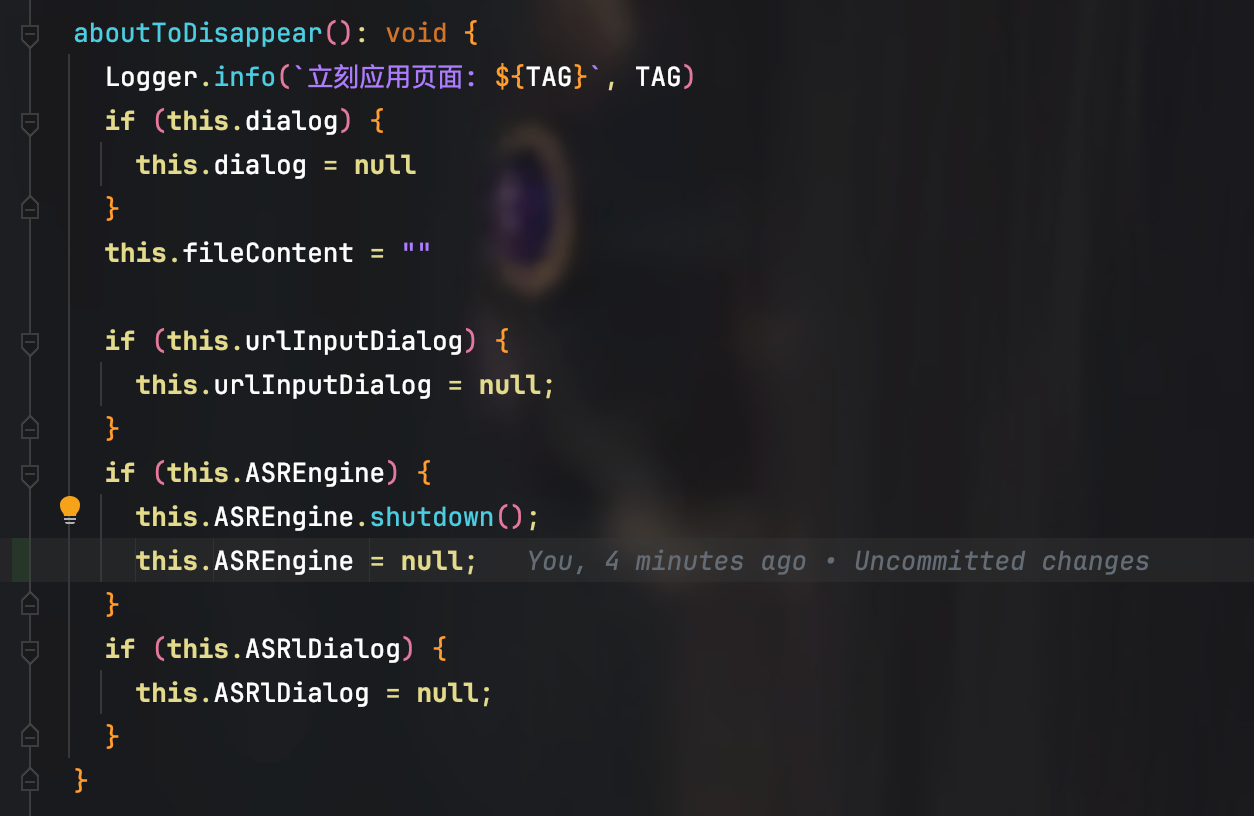
2、设置事件监听
一如前文所说,语音识别结果是通过事件监听函数返回的,因此,第二步就是准备好语音识别引擎的事件监听函数,并将其注册绑定到上面创建好的语音识别引擎实例对象上。

3、启动识别
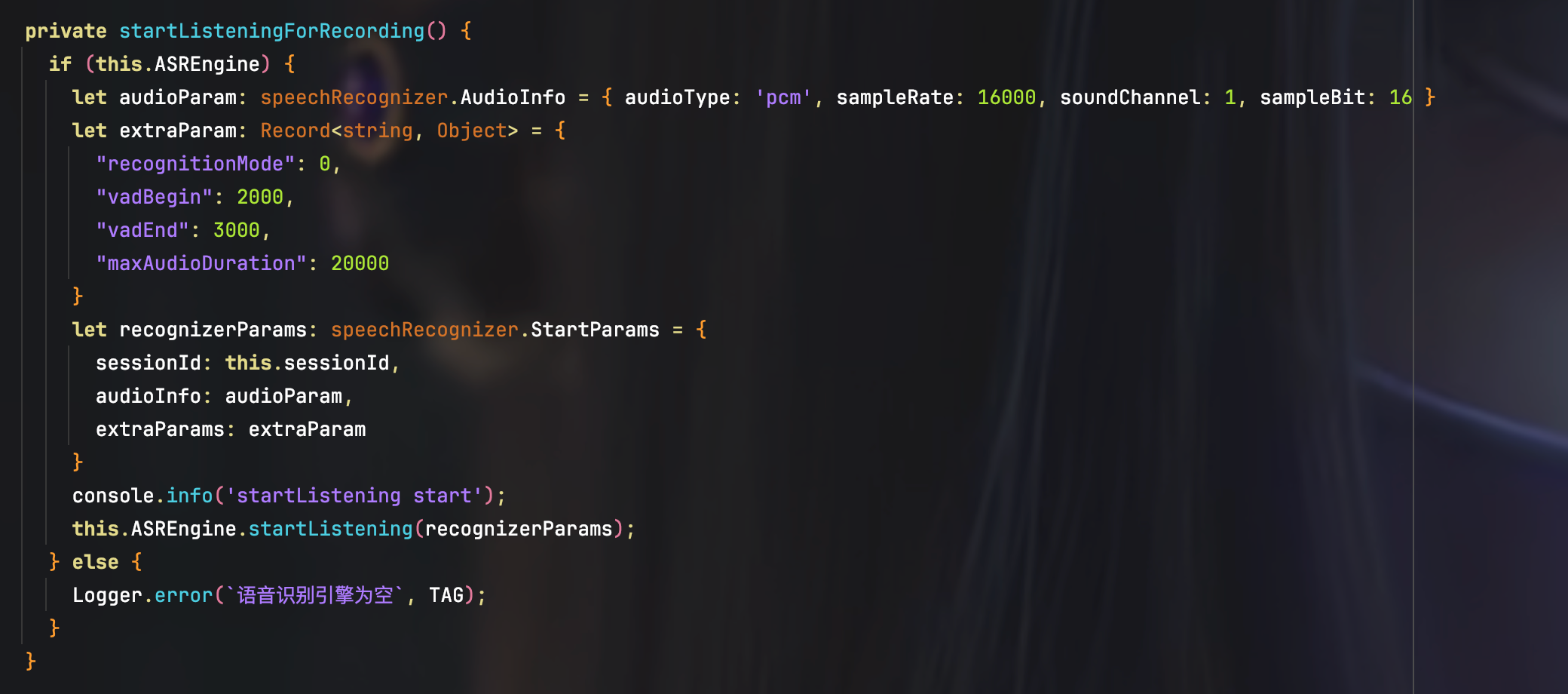
启动识别前,需要设置好相关参数,如待识别的音频规格信息,以及管理识别会话所需的会话ID 等等。
4、写入音频数据
启动识别后,语音识别引擎就会进入工作状态,等待写入具体的待识别的音频数据,这里,我是通过 AudioCapturer 去获取音频数据的,也就是调用麦克风实时获得用户的说话声音。

5、操作控制
为了方便暂停和继续语音识别,我这里专门创建了一个弹窗进行操作控制:
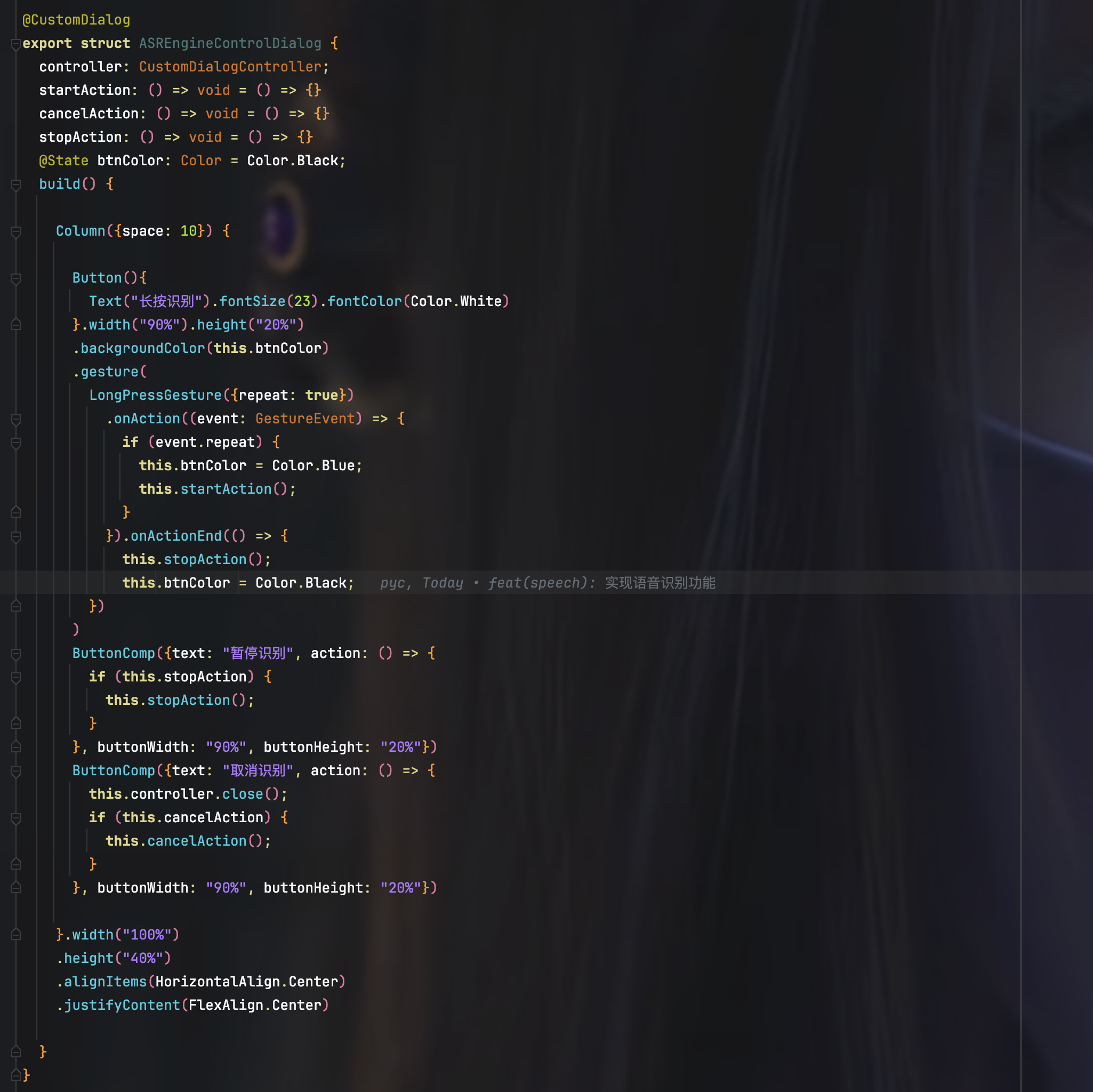
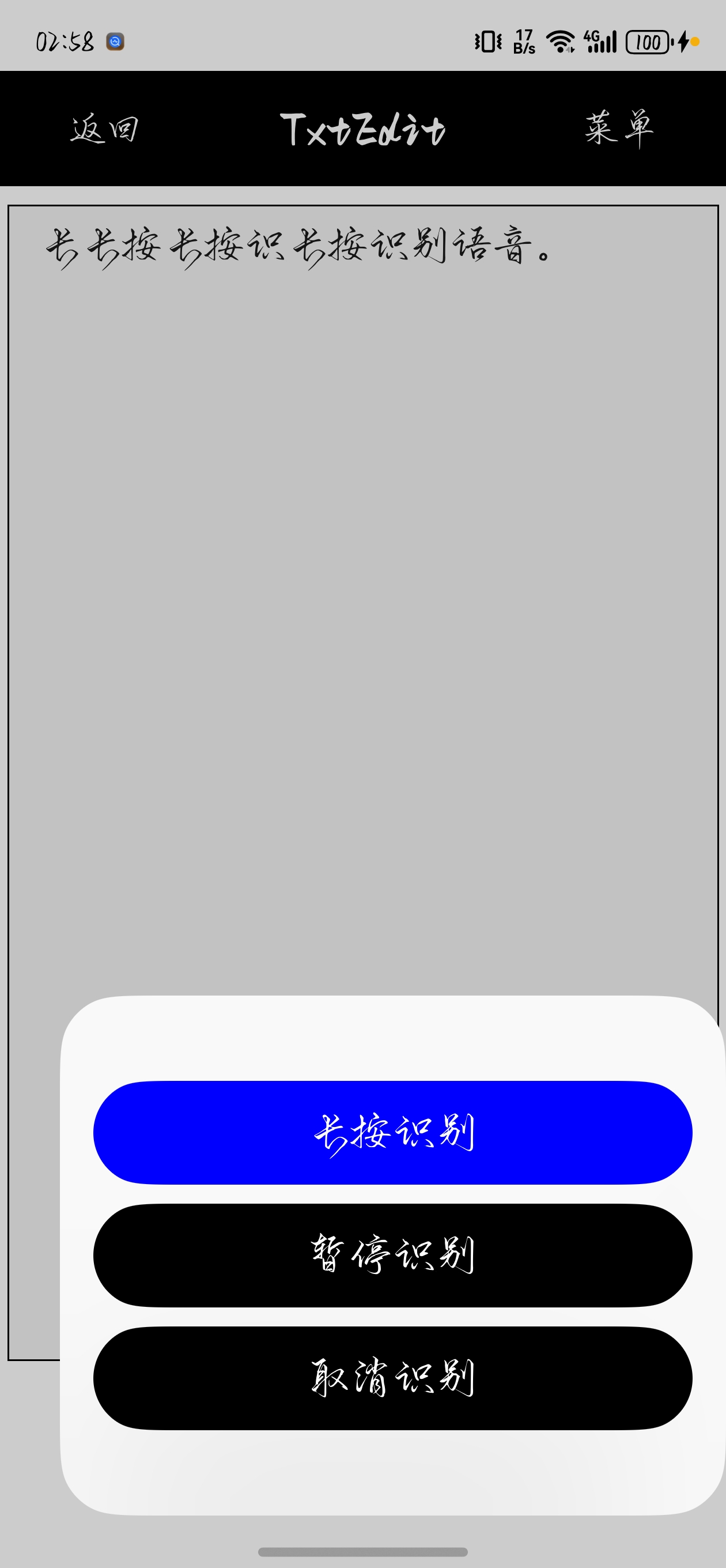
长按该弹窗上的"长按识别"按钮,就能触发语音识别功能,而识别结果会在松开按钮的时候,回写到编辑框上。
三、总结
单就集成语音识别能力来说,并不是一件特别难的事情,在鸿蒙应用开发中,比较困难的是进行结果校正,让最终产生的文本,不会出现一大串重复的文字或短语,而这种校正往往需要一定的模型算法,本文便不再展开探索,有兴趣的可自行了解。