写这个的主要作用是梳理一下Starrocks的索引效率以及使用场景。
Starrocks
Bitmap索引
原理:
Bitmap 索引是一种使用 bitmap 的特殊数据库索引。bitmap 即为一个 bit 数组,一个 bit 的取值有两种:0 或 1。
每一个 bit 对应数据表中的一行,并根据该行的取值情况来决定 bit 的取值是 0 还是 1
引用官网:
选择 Bitmap 索引的首要考虑因素是列的基数和 Bitmap 索引对查询的过滤效果。与普遍观念相反,Bitmap 索引比较适用于较高基数列的查询和多个低基数列的组合查询,
此时 Bitmap 索引对查询的过滤效果比较好,至少可以过滤掉 999/1000 的数据,能够过滤较多的 Page 数据什么是 基数?
假如说有10万个数字,如果是从1到10万 和 10万个1,那对应的基数分别是10万和1所以说如果基数小的话,其实过滤的时候,效果不大,因为搞不好过滤完后还有几万的数据,
所以说Starrocks官网后续也会说明:
如果是单个低基数列的查询,那么 Bitmap 索引过滤效果不佳,待读取的数据行较多并且散落在较多 Page 中
然而如果基数过于高,也会带来其他问题,比如占用较多的磁盘空间,并且因为需要导入时需要构建 Bitmap 索引,导入频繁时则导入性能会受影响。
并且还需要考虑查询时加载 Bitmap 索引的开销。因为查询时候只会按需加载 Bitmap 索引,即 查询条件涉及的列值数量/基数 x Bitmap 索引。这一值越大,则查询时加载的 Bitmap 索引开销也越大而且bitmap是不是使用,还是自适应选择的:
StarRocks 判断是否使用 Bitmap 索引的逻辑:因为一般情况下查询条件涉及的列值数量/列的基数,这一值越小,说明 Bitmap 索引过滤效果好。
所以 StarRocks 采用 bitmap_max_filter_ratio/1000作为判断阈值,当过滤条件涉及比较值的数量 /列的基数 < bitmap_max_filter_ratio/1000 时才会用 Bitmap 索引。bitmap_max_filter_ratio 默认为 1。优势:
能够快速定位查询的列值所在的数据行号,适用于点查或是小范围查询
适用于交并集运算(OR 和 AND 运算),可以优化多维查询
其中适用于 OR 和AND运算是因为可以把对应的bitMap向量进行按bit进行或与操作,如 where col = 'a' and colb ='b'
全局字典
StarRocks 2.0+后的版本默认会开启低基数字典优化
这里专门有一个文章StarRocks 技术内幕 | 基于全局字典的极速字符串查询介绍了全局字典
这里注意一个点:
对于 Agg 操作,如果使用了字典编码,我们在聚合中可以使用编码之后的值作为聚合的 Key。如此一来,在聚合操作的 Hash 表构建和查找过程中,
可以减少 Hash 表中 Key 的比较代价,同时也能够加快 Hash 值计算,节省内存空间,可以提升聚合操作的速度Interger的hashCode 是内部的int值,而String的hashcode是会进行计算的。
Bloom filter 索引
相对于 Bitmap索引 的自适应选择,Bloom filter 索引可以快速判断表的数据文件中是否可能包含要查询的数据,如果不包含就跳过,从而减少扫描的数据量,
Bloom filter 索引空间效率高,适用于基数较高的列,如 ID 列。如果一个查询条件命中前缀索引列,StarRocks 会使用前缀索引快速返回查询结果。
但是前缀索引的长度有限,如果想要快速查询一个非前缀索引列且该列基数较高,即可为这个列创建 Bloom filter 索引。
如果 Bloom filter 索引判断一个数据文件中可能存在目标数据,那 StarRocks 会读取该文件确认目标数据是否存在。注意,这里仅仅是判断该文件中可能包含目标数据。
Bloom filter 索引有一定的误判率,也称为假阳性概率 (False Positive Probability),即判断某行中包含目标数据,而实际上该行并不包含目标数据的概率。
总体来看 bloom filter是在文件层级进行过滤,减少文件IO,而BitMap是在文件内存进行快速查找对应的数据。
Hologres
Bitmap索引
在Hologres中,bitmap_columns属性指定位图索引,是数据存储之外的独立索引结构,
以位图向量结构加速等值比较场景,能够对文件块内的数据进行快速的等值过滤,适用于等值过滤查询的场景
适合将等值查询的列设置为Bitmap,能够快速定位到符合条件的数据所在的行号。但需要注意的是Bitmap对于基数比较高(重复数据较少)的列会有比较大的额外存储开销。
基数原理:
设置了Bitmap索引之后,系统会将列对应的数值生成一个二进制字符串,用于表示取值所在位置的Bitmap,当查询命中Bitmap时,会快速定位到数据所在的行号(Row Number),从而快速过滤出数据。但Bitmap并不是没有开销的,对于以下场景需要注意事项如下:
列的基数较高(重复数据较少)场景:假如列的基数较高,*那么就会为每一个值生成一个Bitmap*,当非重复值很多的时候,就会形成稀疏数组,占用存储较多。
大宽表的每一列都设置为Bitmap场景:如果为大宽表的每一列都设置为Bitmap,那么在写入时每个值都需要构建成Bitmap,会有一定的系统开销,从而影响写入性能。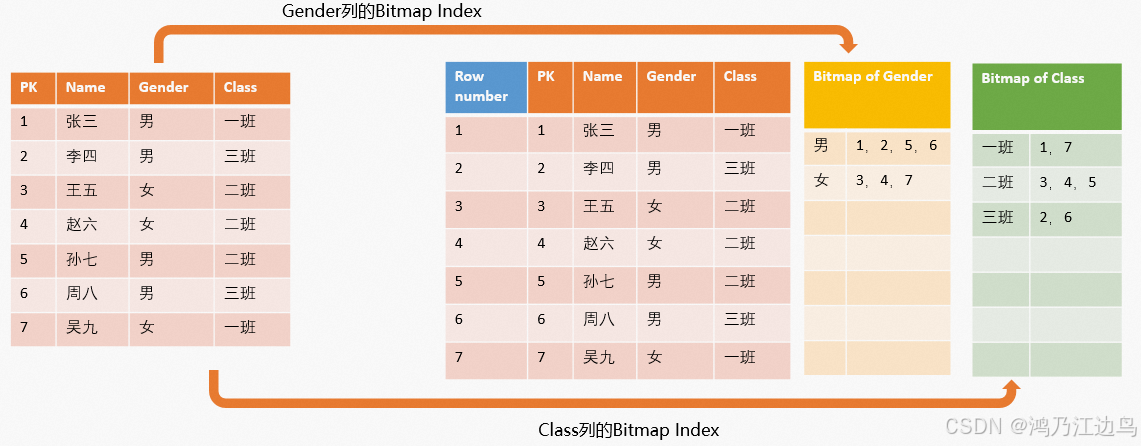
其中为了便于理解,可以参考位图索引:原理(BitMap index)
字典编码
摘抄hologre的官网:
如果数据表中字段的基数相对较小,使用字典编码可以提高数据的压缩率,以减少数据存储量和提高查询性能。
字典编码可以将字符串的比较转成数字的比较,加速Group By、Filter等查询,同时也会提升数据的压缩比,
进一步降低存储。在Hologres中可以对指定字段进行字典编码,即为指定字段的值构建字典映射
技术原理:
Dictionary Encoding是一种压缩存储的技术,系统会将原始数据编码为数值类型存储,同时也会维护对应的编码表结构,在数据读取时,会根据编码表进行数据解码操作,因此在字符串比较的场景中,
尤其是对基数小的列,有加速作用,常用于Group By、Filter等过滤查询场景中。
系统会默认将TEXT数据类型的字段设置Dictionary Encoding。但是解码会带来额外的计算开销,尤其是基数大的列(数据的重复度较低,比如一列里一半值都不相同)和用于Join的字段,
字典编码会带来更多额外的编码、解码开销,因此不建议所有的列都设置为Dictionary Encoding。
在Hologres V0.9及之后版本中,所有TEXT数据类型字段的dictionary_encoding_columns属性默认取值auto。
当表有数据写入时,如果字段里数值的重复度大于等于90%,那么系统就会对该字段开启字典编码。区别
hologres bitMap索引的存储和Starrocks的bitMap索引存储是一样的
都是是把每个值建立一个bitMap,其中每一个bit对应每一个行,如果存在则是把对应的bit位置位某个值(大概率是1),
但是starrocks有自适应选择,在执行的时候可能不会经过bitMap索引,而hologres如果没有特殊情况的话,都会经过bitMap索引(除非有cluster filter)
所以说基数比较高的时候,会有额外的开销存储,对于数据分布比较均衡的列有较高的性价比。
但是Starrocks考虑的是能否过滤更多的数据(也就是过滤的效果)
而Hologres考虑的是存储和顾虑效果的综合(bitmap缓存文件和数据在一起,bitmap也是当做普通数据一样去做内存cache的)。