简介
Selenium 是一个广泛使用的自动化测试工具,主要用于 Web 应用程序的自动化测试。它能实现的功能是网页的自动化操作,例如自动抢票刷课等。同时你应该也见到过有些网站在打开之后并没有直接加载出网站的所有内容,比如一些图片等等,这可能就是网站在构造时使用了AJAX技术,实现了不刷新的和后端交互式的Web页面。这种页面我们使用简单的requests、urllib等并不能加载出来网页的所有内容,因为与传统的网页相比较,这些网站的资源例如图片、视频是藏在js的脚本中,因此之前学过的beautifulsoup和xpath提取url的方法基本上没有用武之地,re(正则表达式)在面对这种问题时也没有那么得心应手。Selenium可以为我们实现动态爬虫,让我们直接从html文件中提取数据即可,而不需要再逆向js来获得数据。
selenium和request获取网页的代码的区别

在网页中我们点击右键,就会发现页面上的选项有查看页面源代码和检测两个选项,查看页面源代码会显示给我们当前url对应的真正的代码,它会跳转到一个新的界面,这是我们使用requests向url发送请求时得到的代码。而如果点击检测,这会打开浏览器自带的抓包工具,在这里显示的代码通常不是存储在服务器端,而是通过服务器发来的源码通过js脚本加载的界面,这里的标签直接存储了图片、视频等的路径在获得这个代码以后我们就可以用之前的方法来提取想要的属性了,而这篇文章的动态爬虫就会教你怎么获得这些代码。
配置
安装python的Selenium包
在终端输入
bash
pip install selenium如果下载过慢或者直接超时报错,我们可以向ai询问一下国内的镜像源。
bash
pip install selenium -i https://mirrors.aliyun.com/pypi/simple/这是python的一个包,使用它可以让我们的python代码操控浏览器。
安装浏览器驱动
在本篇中,我将使用edge浏览器,大家也可以自己去查找chrome,Firefox等浏览器的驱动,代码只有初始化的时候略有不同,其余代码一致。

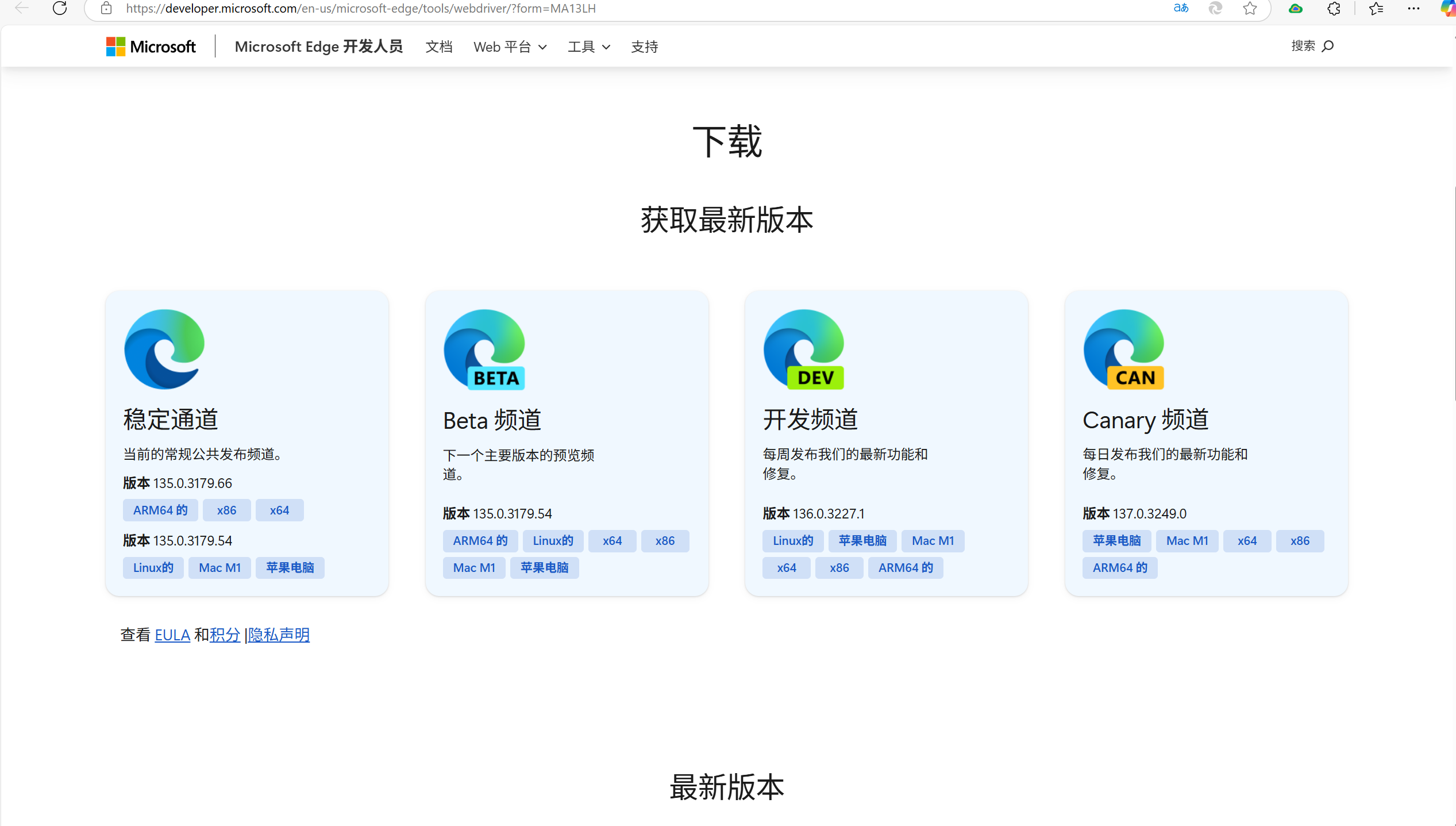
在设置中找到自己的浏览器版本,根据浏览器的版本下载驱动,下载好以后是一个exe文件打开后会显示successful。

python使用selenium基本语法
创建webdriver类
python
from selenium import webdriver
from selenium.webdriver.edge.service import Service
def main():
option = webdriver.EdgeOptions()
option.service = Service('msedgedriver.exe')
driver = webdriver.Edge(options=option)
main()在使用不同的浏览器时,只需要把Edge改成Chrome...即可。在设置浏览器的驱动选项时,Service里面传入的参数是下载的浏览器驱动的位置,可以传入全局路径,或者把文件放入当前的目录中,或者把文件的路径设置成全局变量。
webdriver查看当前界面的属性
在某个页面中常见的属性有url,title,html代码等,接下来我们以百度的网页为例获取一下该界面的这些属性。
我们使用get来控制webdriver发送请求,前往新的界面。
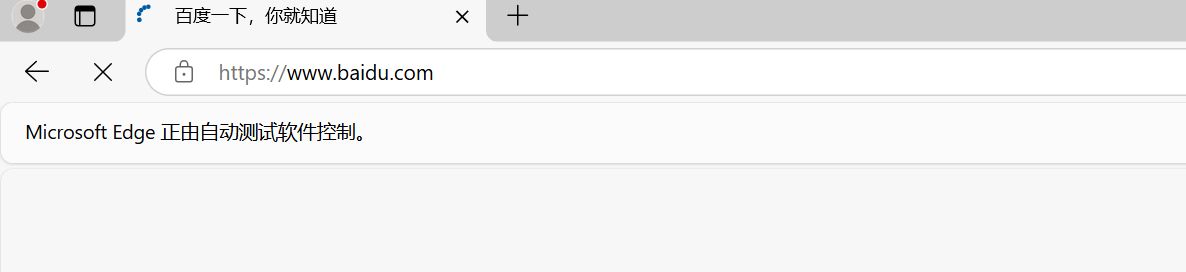
在进入浏览器以后,会提示我们浏览器正在被自动化测试软件控制。这就代表我们已经成功了。
python
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
import time
def main():
service = Service('msedgedriver.exe')
option = webdriver.EdgeOptions()
option.service = service
driver = webdriver.Edge(options=option)
driver.get('http://www.baidu.com')
time.sleep(1)
#当前网页的html代码
print(driver.page_source)
#当前网页的标题
print(driver.title)
#当前网页的URL
print(driver.current_url)
main()直接运行代码就可以直接查看里面的属性了。
学到这里,我们已经可以使用webdriver的get方法访问网页,如果网页的有些资源是动态加载的,我们已经可以获取动态加载的元素了。如果你只想解决在前面的爬虫中遇到的一些问题,那么到这里就可以结束了,但是如果你对网页自动化感兴趣或者不局限于只爬取一个网页,那么我们接下来继续介绍它的一些更多的功能。
webdriver类控制屏幕
最大化窗口:
python
driver.maximize_window()最小化窗口:
python
driver.minimize_window()设置窗口大小:
python
driver.set_window_size(1000, 700) #设置窗口大小为1000x700像素全屏模式:
python
driver.fullscreen_window()webdriver定位标签
在模拟用户操作浏览器的过程中,我们常常会为了和页面交互而在input标签中输入或者点击按钮,但是在网页中一般输入框和按键又比较繁多,那么我们应该先找到我们想要的按键,才能对它进行操作。
我们能想到的寻找标签的方式:
1.通过标签的名字来查找:
我们继续以百度的界面为例。
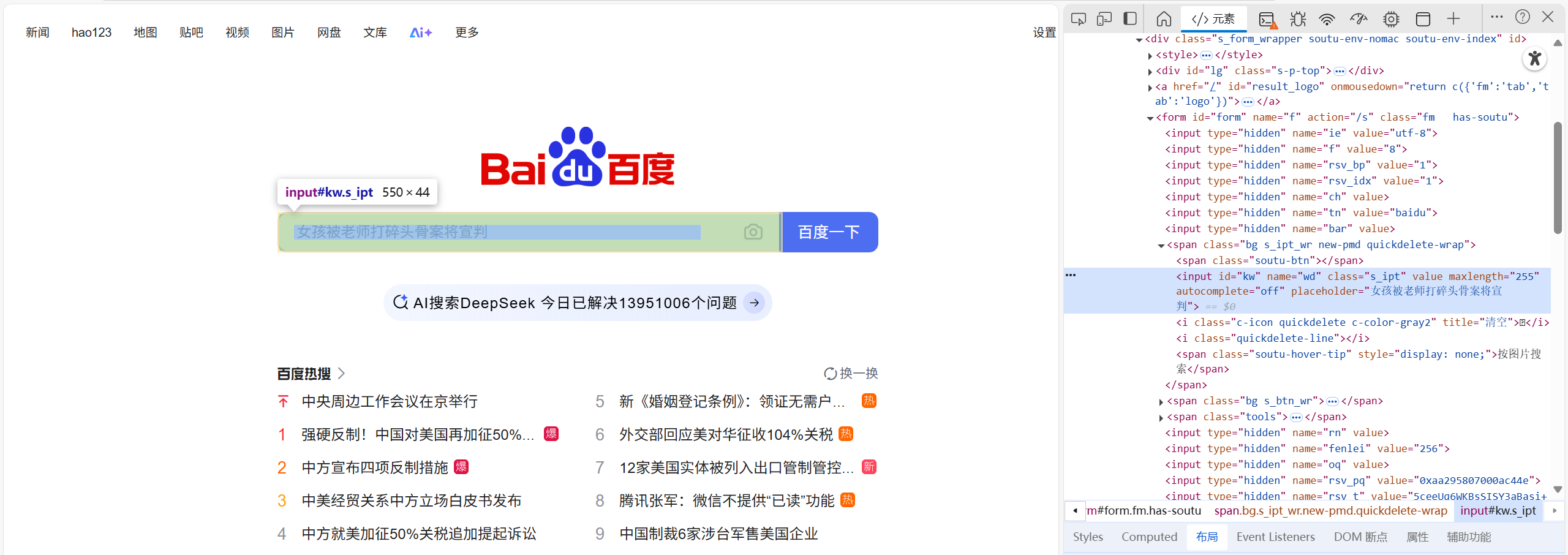
虽然我们轻而易举的发现了这个input标签,但是这个网页中有不少的input标签,所以这个方法很显然是不太可行的。
2.类似于第一个,我们还可以通过标签的name属性,标签的class属性来查找,但是这同样不能让我们定位到某一个专属的标签。
3.在html中我们知道id选择器是唯一的,于是我们可以通过这种方法来定位标签。
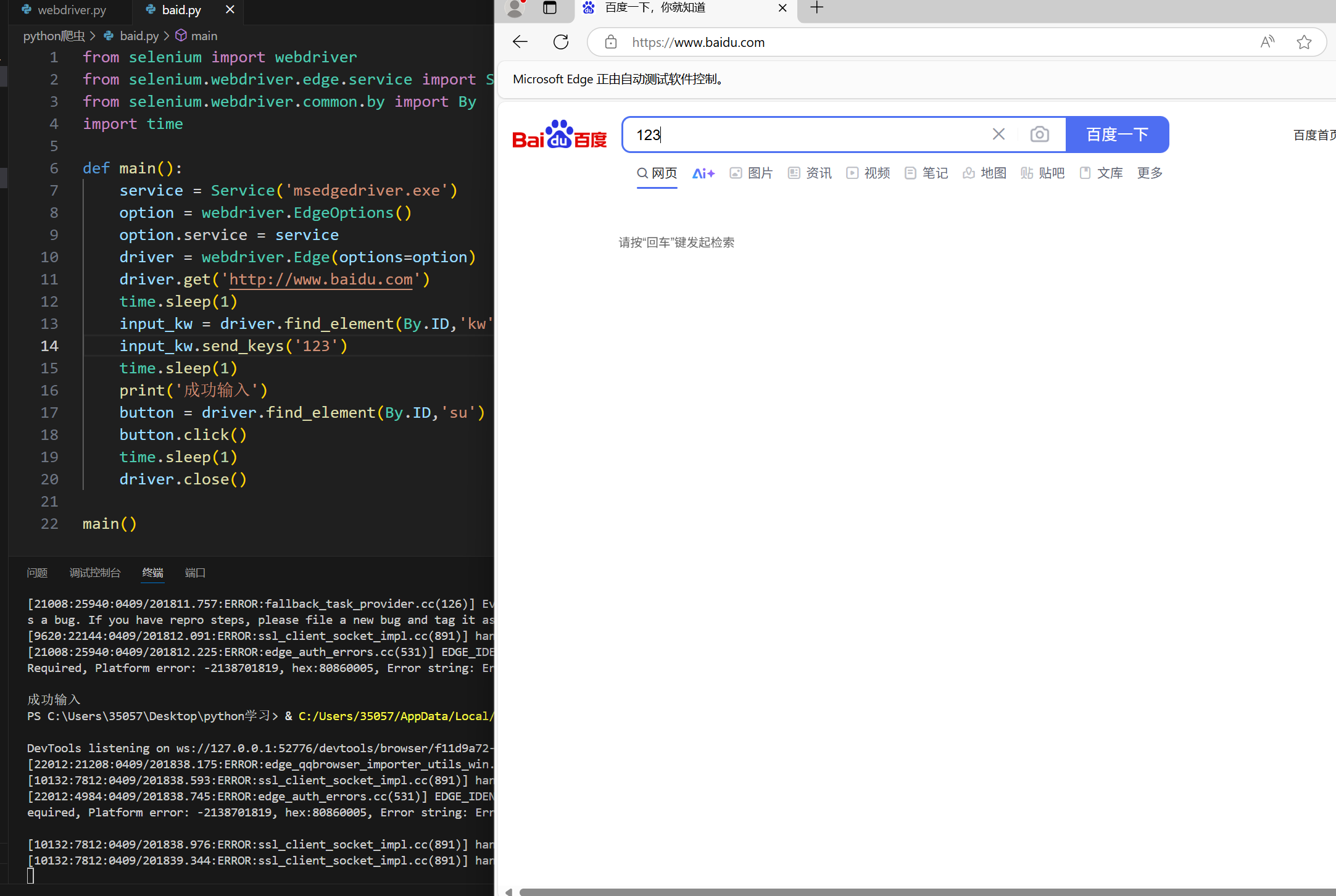
通过By类,我们选择By.ID。然后输入id的名字就可以了。

在源代码中,输入栏和搜索按钮的id分别是kw和su。接下来我直接给出源码:
python
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
import time
def main():
service = Service('msedgedriver.exe')
option = webdriver.EdgeOptions()
option.service = service
driver = webdriver.Edge(options=option)
driver.get('http://www.baidu.com')
time.sleep(1)
input_kw = driver.find_element(By.ID,'kw')
input_kw.send_keys('123')
time.sleep(1)
print('成功输入')
button = driver.find_element(By.ID,'su')
button.click()
time.sleep(1)
driver.close()
main()可以看到它成功给了我们输入了send的内容同时点击了搜索。
4.Xpath方法定位,如果你会一点爬虫,那么这个词你应该并不会感到陌生,我们可以手动的寻找输入某个标签的xpath路径,同样的如果你不是傻子,可以直接从网页上复制,直接使用或者稍作修改。
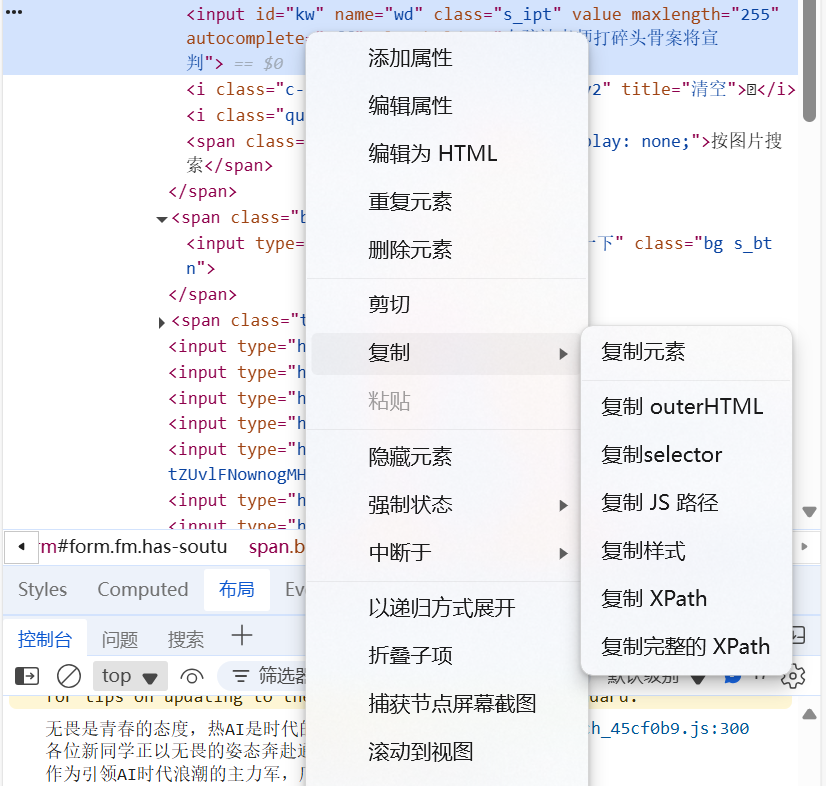
可以看到这里能复制完整的Xpath路径。
python
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
import time
def main():
service = Service('msedgedriver.exe')
option = webdriver.EdgeOptions()
option.service = service
driver = webdriver.Edge(options=option)
driver.get('http://www.baidu.com')
time.sleep(1)
input_kw = driver.find_element(By.XPATH,'/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input')
input_kw.send_keys('123')
time.sleep(1)
print('成功输入')
button = driver.find_element(By.XPATH,'/html/body/div[1]/div[1]/div[5]/div/div/form/span[2]/input')
button.click()
time.sleep(1)
driver.close()
main()修改一下之前代码的find_element里面的参数,运行代码以后,我们发现代码还是可以正常使用的,虽然这种方法也可以,但是我还是更习惯使用id,因为id更加简单方便一些。
selenium的其它小技巧
无头浏览模式
如果你要写动态爬虫爬取一些网站的信息,但是网站的内容你并不想呈现出来,或者网页加载的时候损耗比较大,那么你可以设置开启无头浏览模式,这种模式下,你不会打开浏览器,而是在后台偷偷地进行数据搜集地工作。
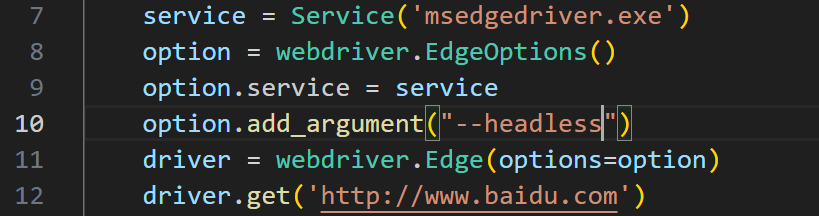
我们只需要添加一行option.add_argument("--headless")即可。
等待机制
Selenium 提供了多种等待机制来处理动态内容,包括隐式等待(Implicit Wait)和显式等待(Explicit Wait)。
隐式等待:设置一个全局的等待时间,Selenium 会在查找元素时等待指定的时间。如果在指定时间内找到元素,则继续执行;否则抛出异常。
driver.implicitly_wait(10) # 等待10秒
显式等待:针对特定的元素设置等待条件,直到条件满足或超时。显式等待更加灵活,适用于处理复杂的动态内容。