目录
Elasticsearch生态非常丰富,包含了一系列工具和功能,帮助用户处理、分析和可视化数据,Elastic Stack是其核心部分:
Elastic Stack 也称 ELK Stack, 由以下几个部门组成:
- Elasticsearch:核心搜索引擎,负责存储、索引和搜索数据
- Kibana:可视化平台,用于查询、分析和展示Elasticsearch中的数据
- Logstash:数据处理管道,负责数据收集、过滤、增强和传输到Elasticsearch。
- Beats:轻量级的数据传输工具,收集和发送数据到Logstash或Elasticsearch。
Elasticsearch核心概念
索引Index:类似数据库中的表,数据存储和搜索的基本单位,每个索引可以存储多条文档数据。
文档 Document:索引中的每条记录,类似数据库中的行,文档以JSON格式存储。
字段 Field:文档中的每个键值对,类似数据库中的列。
映射 Mapping:用于定义Elasticsearch索引中文档字段的数据类型及其处理方式,类似与关系型数据库中的Schema表结构,帮助控制字段的存储、索引和查询行为。
集群 Cluster:多个节点组成的集群,用于存储数据并提供搜索功能。集群中的每个节点都可以处理数据。
分片 Shard:为实现横向扩展,ES将索引拆分为多个分片,每个分片可以分布在不同节点上。
副本Replica:分片的复制品,用于提高可用性和容错性。
Elasticsearch实现全文检索的原理
1、分词:Elasticsearch的分词器会将输入文本拆解成独立的词条(tokens),方便进行索引和搜索。分词的具体过程有以下几步:
字符过滤:去除特殊字符、HTML标签或进行Italy文本清理。
分词:根据指定的分词器(analyzer),将文本按规则拆分成一个个词条。例如,英文按照空格分,中文使用专门的分词器处理。
词汇过滤:对分词结果进行过滤,如去掉 停用词"the""is" 或进行词形归并。
2、倒排索引
倒排索引是Elasticsearch实现高效搜索的核心数据结构。它将文档中的词条映射到文档ID,实现快速查找。
工作原理:
- 每个文档在被索引时,分词器会将文档内容拆解为多个词条。
- Elasticsearch为每个词条生成一个倒排索引,记录改词条在哪些文档中出现。
例如:
- 文档1:小俱是美女
- 文档2:小俱是好人
中文分词后,生成的倒排索引大致如下:
|----|------|
| 词条 | 文档ID |
| 小俱 | 1,2 |
| 是 | 1,2 |
| 美女 | 1 |
| 好人 | 2 |
通过这种结果,可以快速找到包含该词的所有文档。
Elasticsearch打分规则
打分规则是用于衡量每个文档与查询条件的匹配度的评分机制。搜索结果默认排序方式是按照相关性得分,从高到底。Elasticsearch使用 BM25算法 来极端每个文档的得分,基于词频、反向文档频率、文档长度等因素来评估文档和查询的相关性。
打分的主要因素:
1.词频:查询词在文档中出现的次数,次数越多,得分越高。
2.反向文档频率:查询词在所有文档中出现的频率。词在越少的文档中出现,IDF 值越高,得分越高。
3.文档长度:较短的文档往往被认为更相关,因为查询词在短文档中占的比例更大。
常用的查询语法
DSL查询(Domain specific Language)
基于 JSON 的查询语言,它是 Elasticsearch 中最常用的查询方式。
{
"query": {
"match": {
"message": "Elasticsearch 是强大的"
}
}
}这个查询会对message字段进行分词
ES数据同步方案
一般情况下,如果做查询搜索功能,使用 ES 来模糊搜索,但是数据是存放在数据库 MySQL 里的,所以说我们需要把 MySQL 中的数据和 ES 进行同步,保证数据一致(以 MySQL为主)。
数据流向:MySQL=>ES(单向)
数据同步一般有2个过程:全量同步(首次)+增量同步(新数据)
总共四种:
1、定时任务
比如1分钟1次,找到 MySQL 中过去几分钟内(至少是定时周期的2倍)发生改变的数据,然后更新到 ES。
优点:
- 简单易懂,开发、部署、维护相对容易。
- 占用资源少,不需要引入复杂的第三方中间件。
- 不用处理复杂的并发和实时性问题。
缺点:
- 有时间差:无法做到实时同步,数据存在滞后。
- 数据频繁变化时,无法确保数据完全同步,容易出现错过更新的情况。
- 对大数据量的更新处理不够高效,可能会引入重复更新逻辑。
应用场景:
- 数据实时性要求不高:适合数据短时间内不同步不会带来重大影响的场景。
- 数据基本不发生修改:适合数据几乎不修改、修改不频繁的场景。
- 数据容忍丢失。
2、 双写
写数据的时候,必须也去写 ES;更新删除数据库同理。
可以通过事务保证数据一致性,使用事务时,要先保证 MySQL写成功,因为如果 ES 写入失败了,不会触发回滚,但是可以通过定时任务 +日志+告警进行检测和修复(补偿)。
优点:
- 方案简单易懂,业务逻辑直接控制数据同步
- 可以利用事务部分保证 MySQL 和 ES 的数据一致性。
- 同步的时延较短,理论上可以接近实时更新 ES。.
缺点:
- 影响性能:每次写 MySQL时,需要同时操作 ES,增加了业务写入延迟影响性能。
- 一致性问题:如果 ES 写入失败,MySQL事务提交成功后,ES 可能会丢失数据;或者 ES 写入成功,MySQL事务提交失败,ES 无法回滚。因此必须额外设计监控、补偿机制来检测同步失败的情况(如通过定时任务、日志和告警修复)。
- 代码复杂度增加,需要对每个写操作都进行双写处理。
应用场景:
- 实时性要求较高
- 业务写入频率较低:适合写操作不频繁的场景,这样对性能的影响较小。
3、使用Logstash数据同步管道
一般要配合 kafka 消息队列 + beats 采集器:
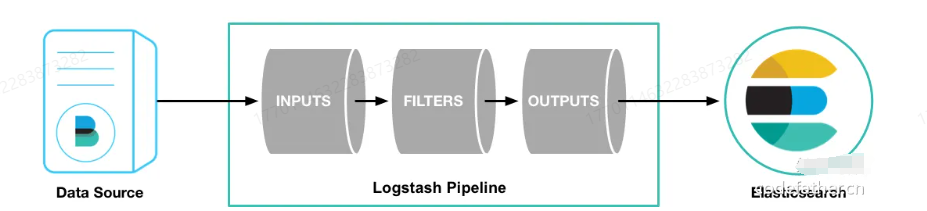
优点:
- 配置驱动:基于配置文件,减少了手动编码,数据同步逻辑和业务代码解耦。
- 扩展性好:可以灵活引入 Kafka 等消息队列实现异步数据同步,并可处理高吞吐量数据
- 支持多种数据源:Logstash 支持丰富的数据源,方便扩展其他同步需求。
缺点:
- 灵活性差:需要通过配置文件进行同步,复杂的业务逻辑可能难以在配置中实现,无法处理细粒度的定制化需求。
- 引入额外组件,维护成本高:通常需要引入 Kafka、Beats 等第三方组件,增加了系统的复杂性和运维成本。
应用场景:
- 大数据同步:适合大规模、分布式数据同步场景。
- 对实时性要求不高:适合数据流处理或延迟容忍较大的系统。
- 系统已有 Kafka 或类似的消息队列架构:如果系统中已经使用了 Kafka 等中间件,使用 Logstash 管道会变得很方便。
4、监听 MysQL Binlog
有任何数据变更时都能够实时监听到,并且同步到 Elasticsearch。一般不需要自己监听,可以使用现成的技术,比如 Canal。
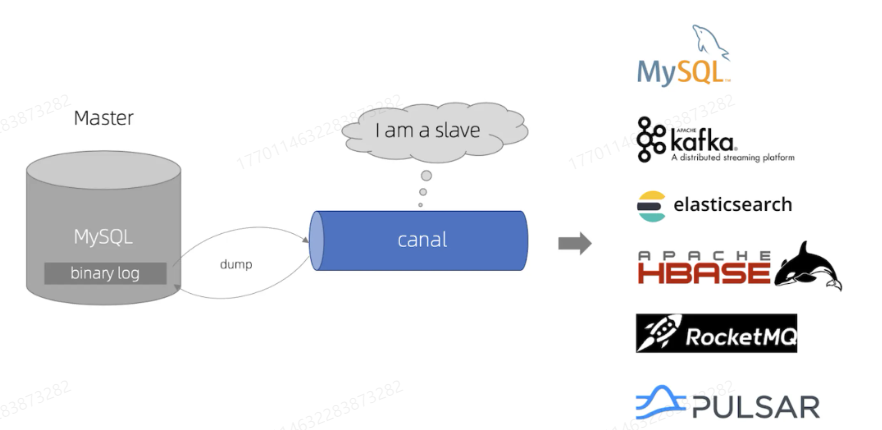
Canal 的核心原理:数据库每次修改时,会修改 binlog 文件,只要监听该文件的修改,就能第一时间得到消息并处理。
优点:
- 实时性强:能够在 MySQL数据发生变更的第一时间同步到 ES,做到真正的实时同步。
- 轻量级:Binlog 是数据库自带的日志功能,不需要修改核心业务代码,只需要新增监听逻辑。
缺点:
- 引入外部依赖:需要引入像 Canal 这样的中间件,增加了系统的复杂性和维护成本。
- 运维难度增加:需要确保 Canal 或者其他 Binlog 监听器的稳定运行,并且对 MySQL 的 Binlog 配置要求较高。
- 一致性问题:如果 Canal 服务出现问题或暂停,数据可能会滞后或丢失必须设计补偿机制。
应用场景
- 实时同步要求高:适合需要实时数据同步的场景,通常用于高并发、高数
- 据-致性要求的系统。
- 数据频繁变化:适合数据变更频警目需要高效增量同步的场景