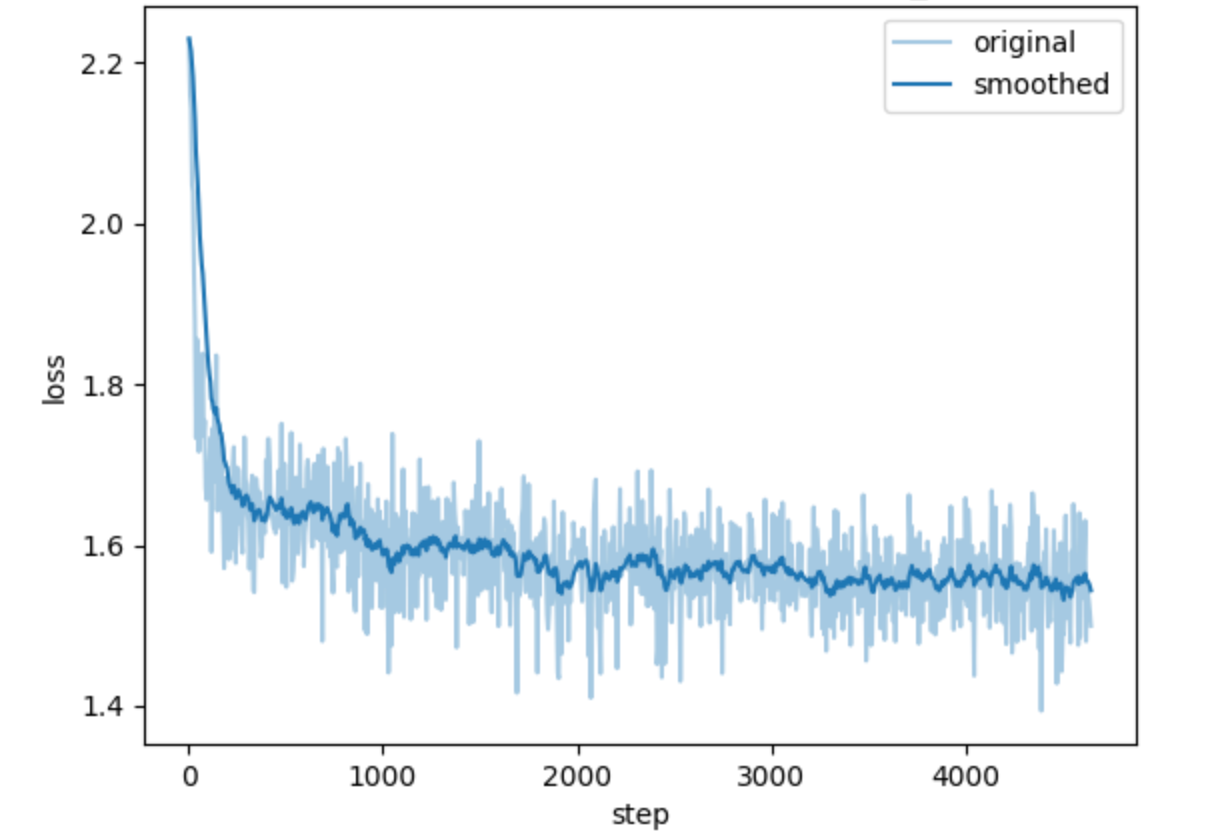
unsloth单卡4090微调DeepSeek-R1-Distill-Qwen-14B医学领域后,跑通一下多卡微调。
1,准备2卡RTX 4090


2,准备数据集
医学领域
pip install -U huggingface_hub
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --resume-download --repo-type dataset FreedomIntelligence/medical-o1-reasoning-SFT --local-dir FreedomIntelligence/medical-o1-reasoning-SFT
3,安装LLaMA-Factory 和下载模型
需要提前搭建好docker微调环境
下载模型 ,需要是 safetensors 权重文件
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".torch,metrics"
llamafactory-cli webui
llamafactory-cli version
INFO 04-12 04:48:24 init.py:190] Automatically detected platform cuda.
| Welcome to LLaMA Factory, version 0.9.3.dev0 |
| |
| Project page: https://github.com/hiyouga/LLaMA-Factory |
/workspace# python toShareGPT.py 转换数据集
4,注册数据集
cp /datasets/medical_sharegpt_format.json ./LLaMA-Factory/data/
修改 `data/dataset_info.json`,添加自定义数据集:
"medical_sharegpt_format": {
"file_name": "medical_sharegpt_format.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system"
}
}
5,llamafactory-cli webui训练