项目中有一个客户列表,要求每页显示1000条,并且字段很多,接口返回大概要10秒钟,进行优化.
原本逻辑:使用mybatisplus构建查询条件,分页查询客户表,查出数据库DO对象,然后for循环转化成回显的VO对象.在转化的过程中出现了查库代码,导致当每页条数1000时,每一个客户转化都需要查询一次,造成了几千次的IO.
前提条件,已经构建了相关的索引.
首次优化,避免在转换VO的过程中出现查库代码,提前收集客户id列表,查询相关的员工信息,部门信息等等,并根据关联id转成一个map,把map直接放到转换代码中,这样只查一次,多次使用
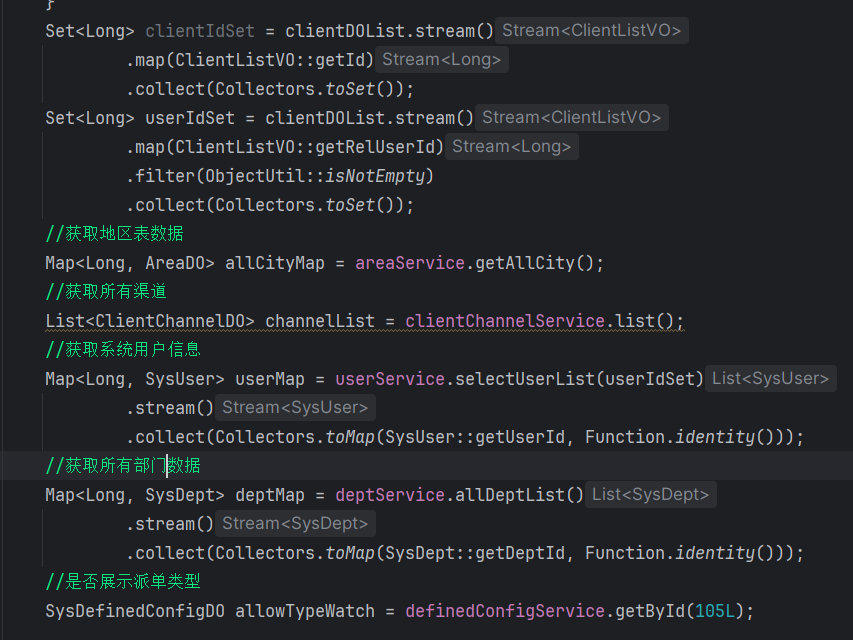
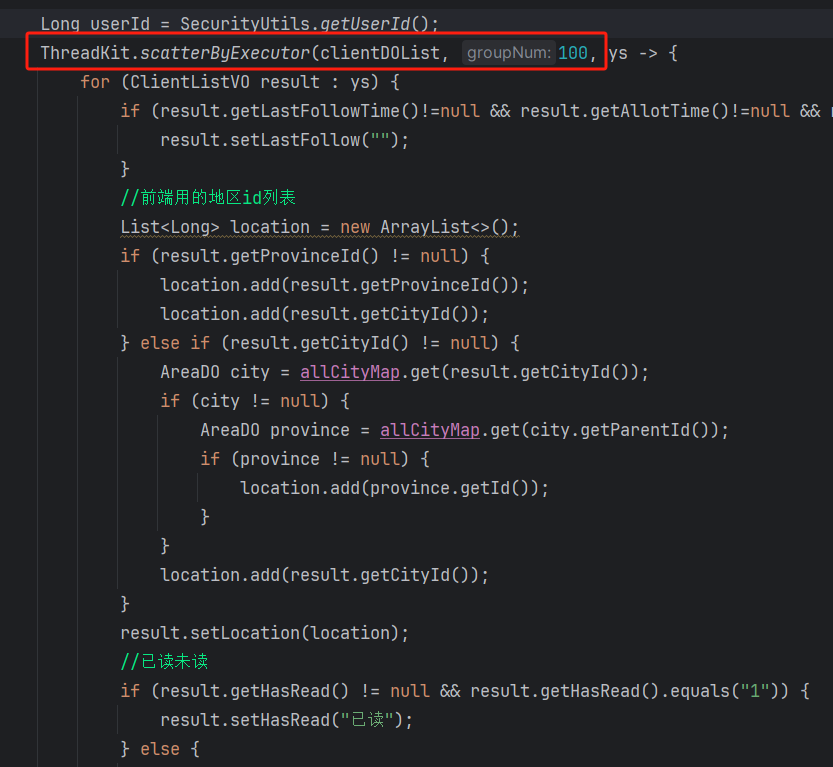
第二点优化:如果数量大于100条时,每个线程100条,多个线程同时执行
第三处优化:其实查询sql并不算很慢,但是因为对象很大,转换的过程比较慢,直接使用mybatis查询mybatisplus构建的条件,使查出的结果直接是客户VO而不是客户DO,省略了复制转换的过程
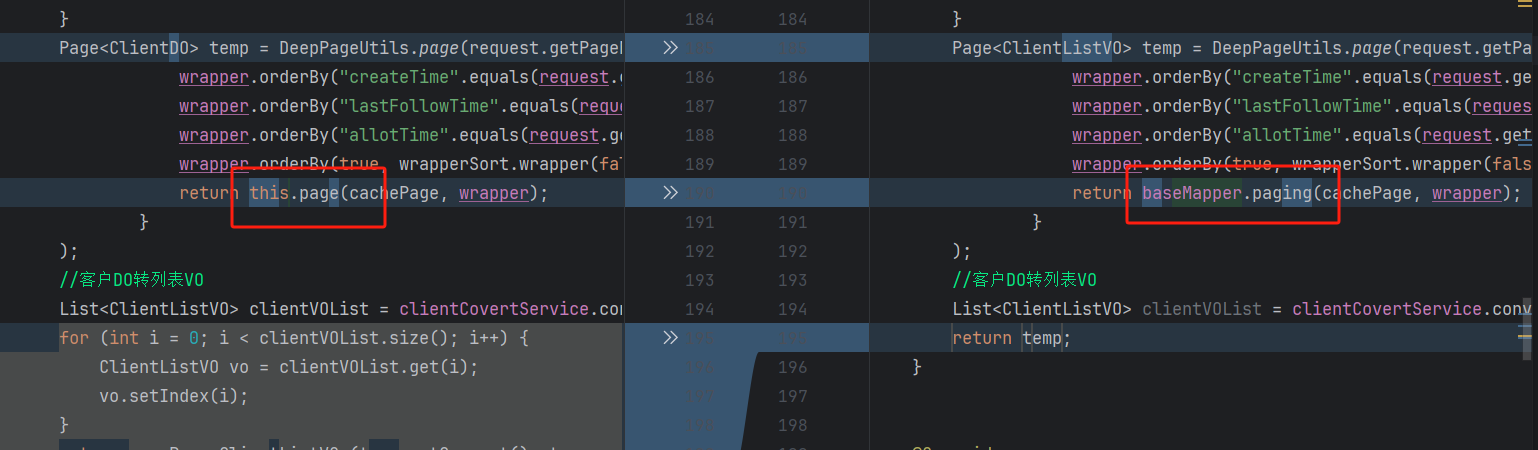
csharp
Page<ClientListVO> paging(@Param("page") Page<ClientListVO> cachePage, @Param(Constants.WRAPPER) LambdaQueryWrapper<ClientDO> wrapper);
csharp
<select id="paging" resultType="com.ruoyi.system.domain.vo.ClientListVO">
select * from client ${ew.getCustomSqlSegment}
</select>为什么能直接在 MyBatis XML 中使用 Wrapper?
MyBatis-Plus 在底层做了以下处理:
参数绑定:通过 @Param(Constants.WRAPPER) 注解,将 wrapper 对象绑定到 ew 变量名。
SQL 解析:Wrapper 内部会解析你调用的方法(如 eq(), orderBy()),生成对应的 SQL 片段。
变量替换:在 XML 中,${ew.getCustomSqlSegment} 会调用 wrapper.getCustomSqlSegment() 方法,返回生成的 SQL 片段。
经过多次优化以后接口查询1000条仅用时几百毫秒.