目录
[1. 项目需求](#1. 项目需求)
[2. 模型解析](#2. 模型解析)
[2.1 网络模型](#2.1 网络模型)
[2.2 准备数据](#2.2 准备数据)
[2.3 双向循环神经网络](#2.3 双向循环神经网络)
[3. 代码解析](#3. 代码解析)
[4. 完整代码](#4. 完整代码)
[5. 结果](#5. 结果)
1. 项目需求
对名字的分类,几千个名字,总共来自于18个国家

2. 模型解析
对于自然语言处理来说,输入是一个序列, 需要编码成one-hot的形式
由于其是一个高维的稀疏的向量,所以通常经过embed层变成稀疏的稠密的向量
经过RNN循环神经网络后,对其分类
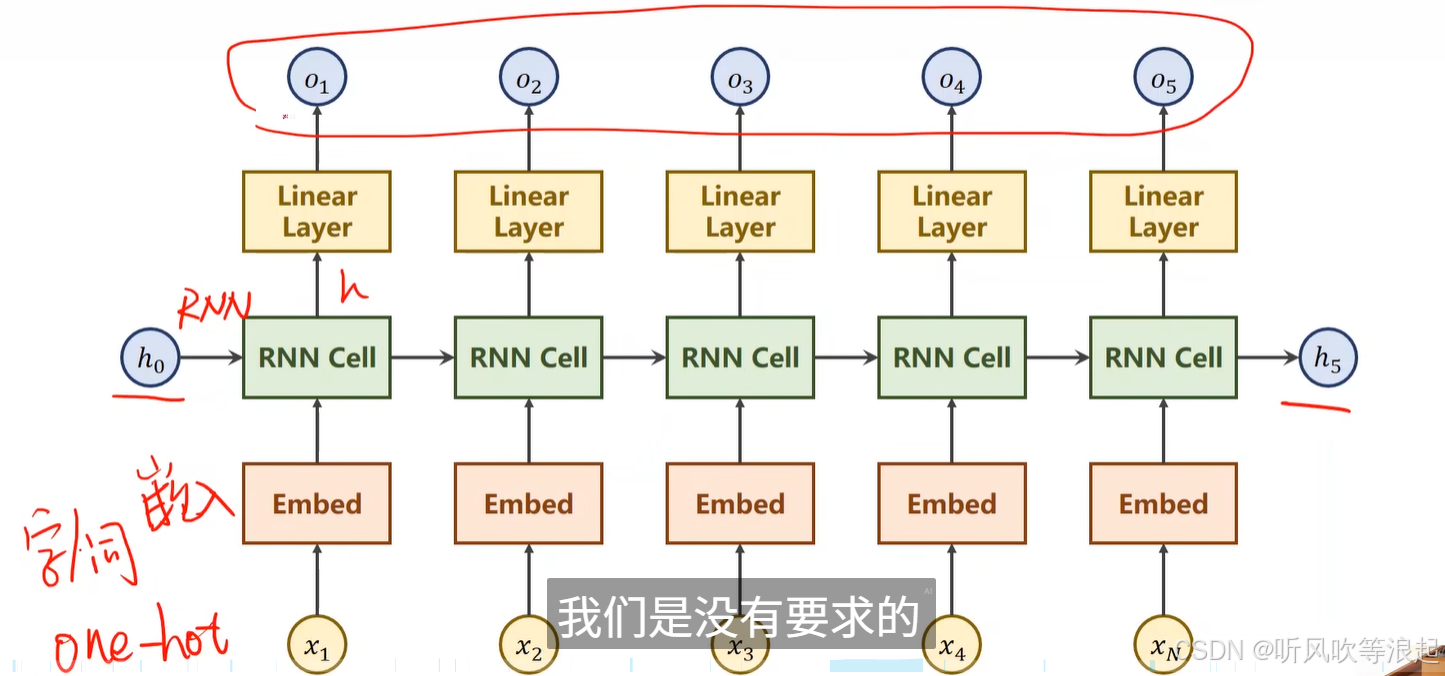
但是对本文的任务,输出的o1、o2我们不在乎,因为这是序列的分类形式,而不是对自然语言的序列进行字词的重组等
所以网络可以进行优化
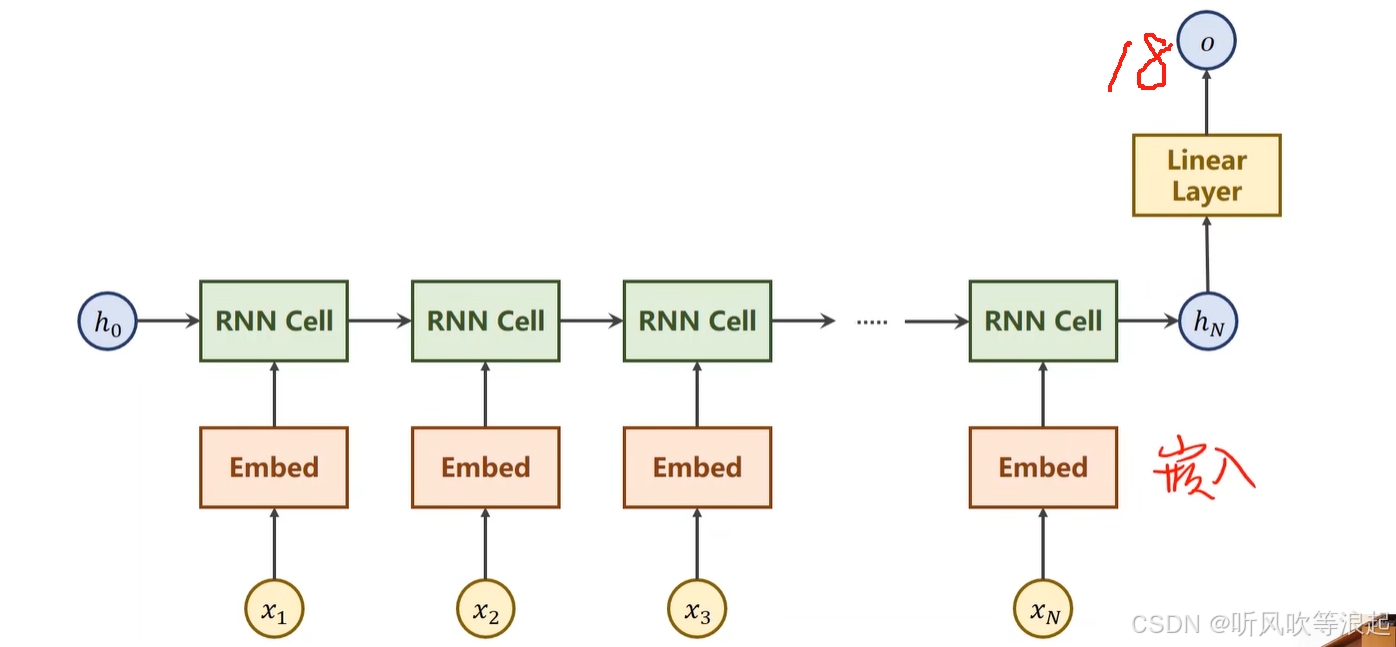
网络的结构:
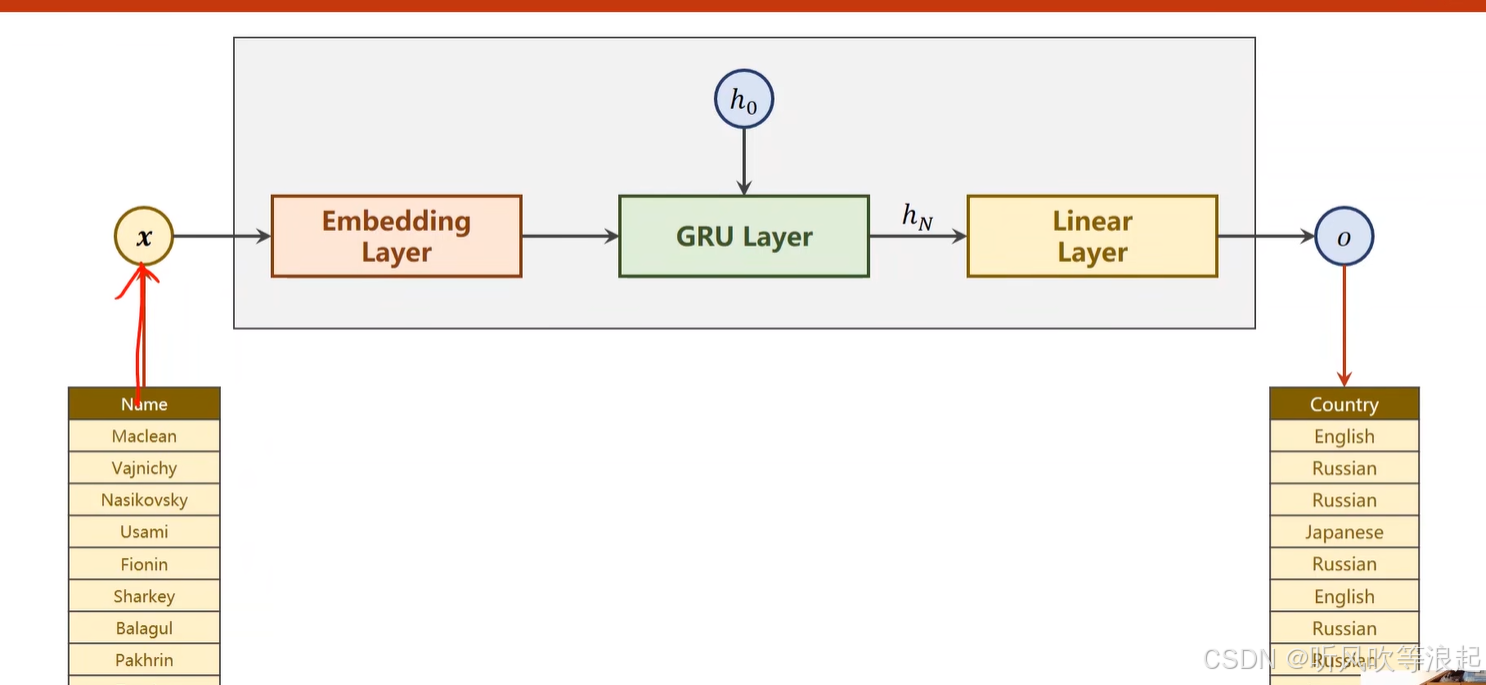
2.1 网络模型
输入虽然是单个名字,但是因为名字的长短不一样,因此要进行处理
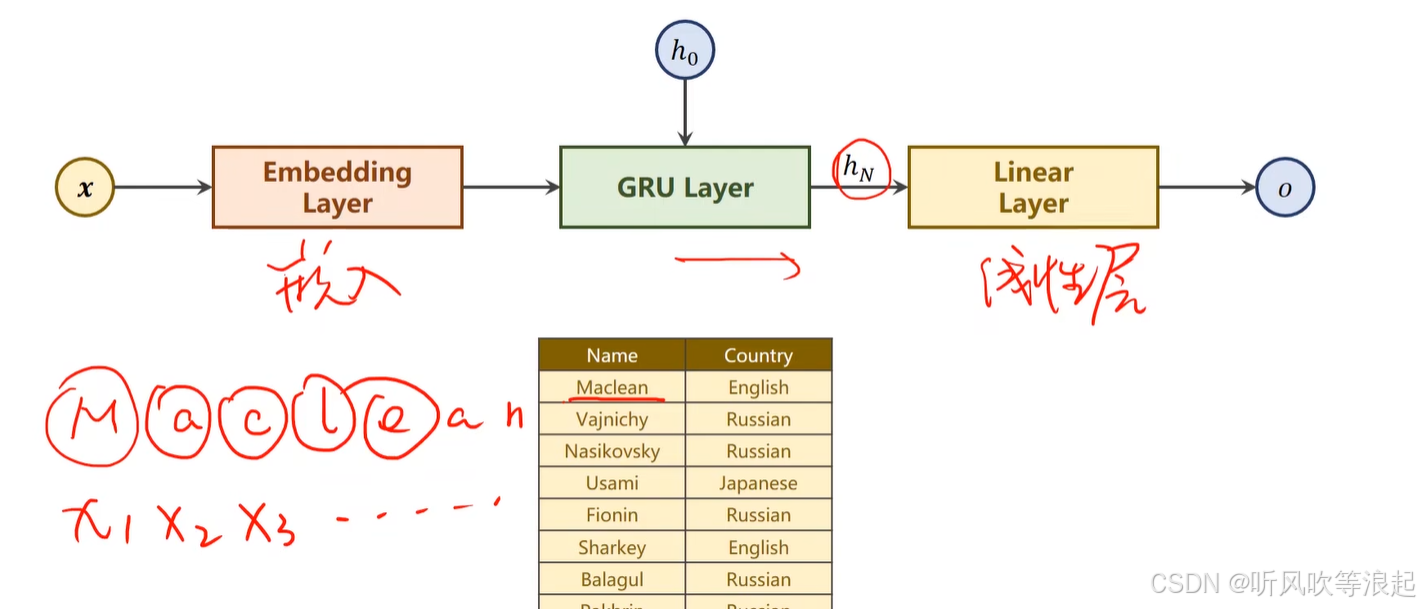
2.2 准备数据
这里通过ASCII变成字符序列
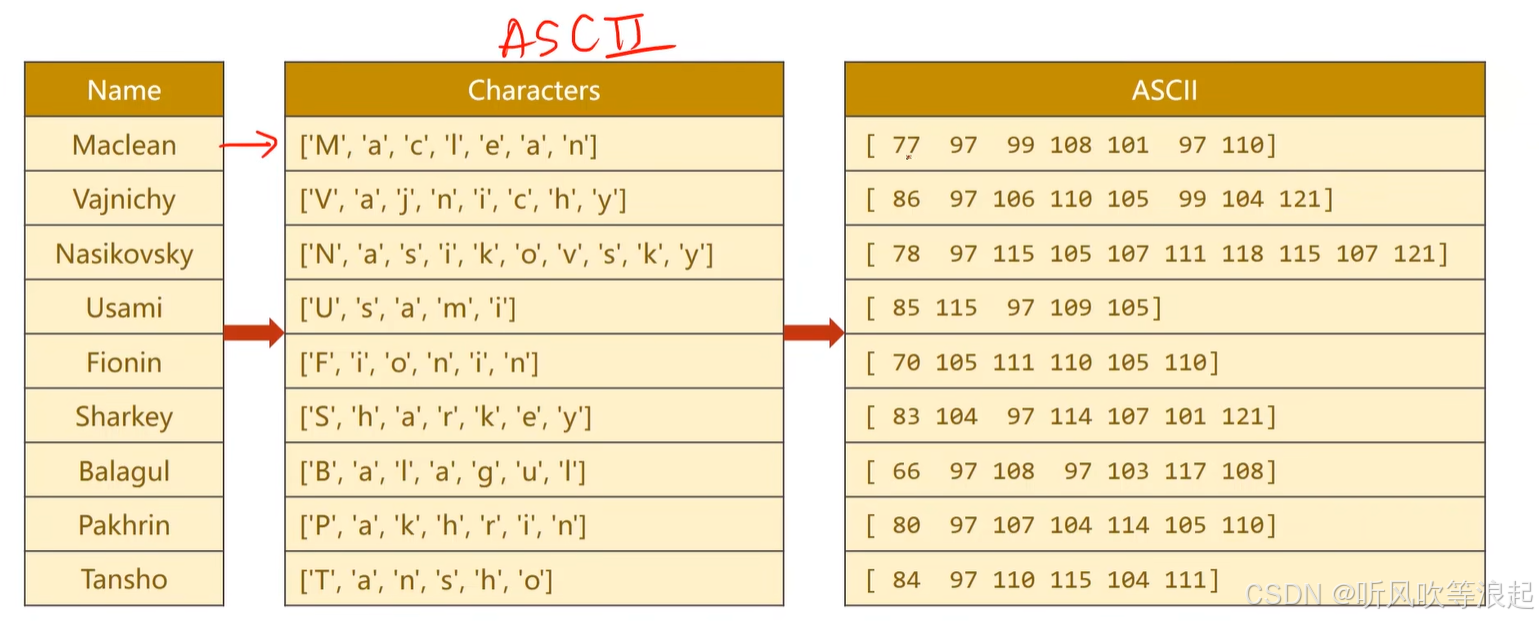
因为数据的长短不一,要进行padding

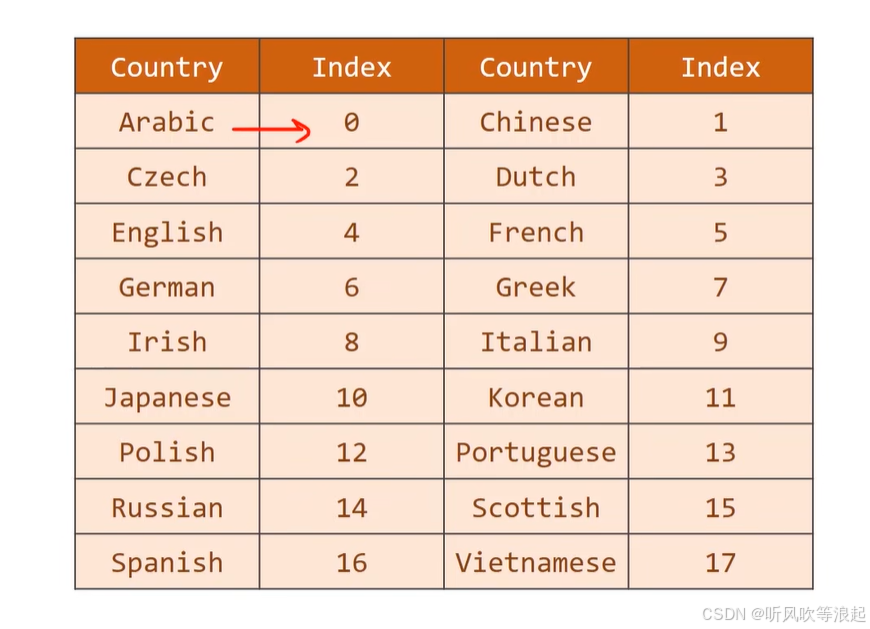
分类的类别索引:18类别
2.3 双向循环神经网络
一般的RNN,Xn-1 只是和之前的信息有关
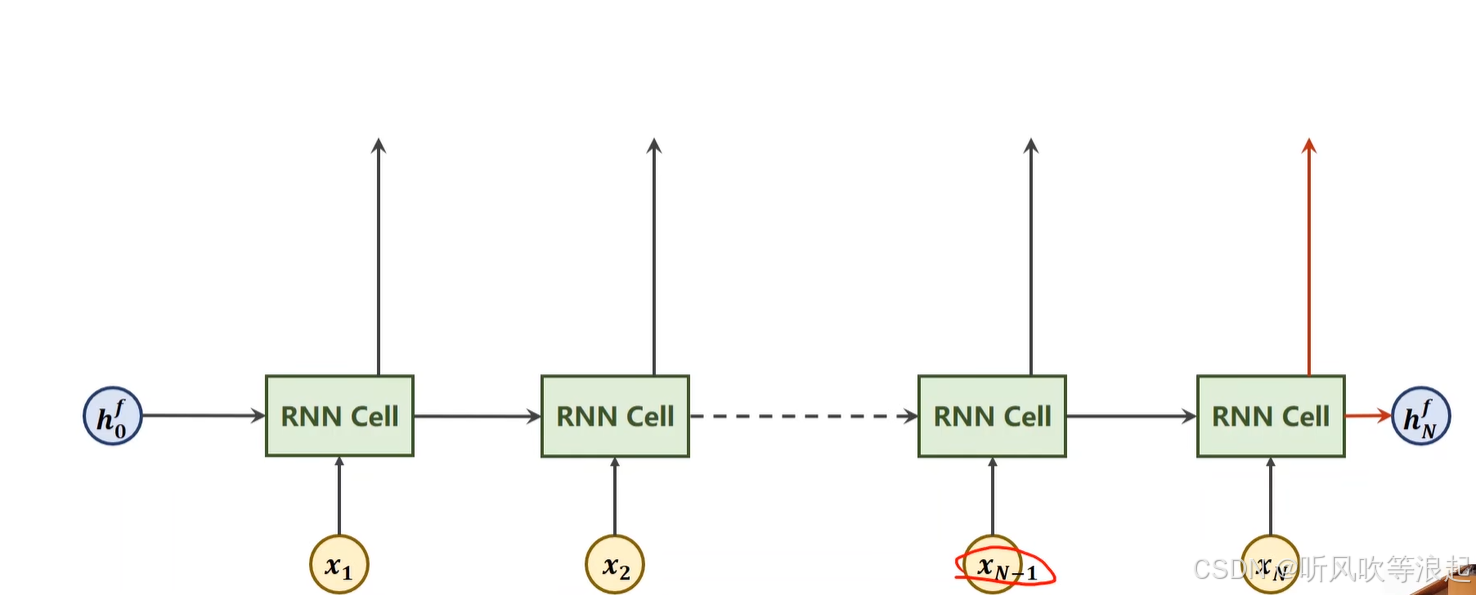
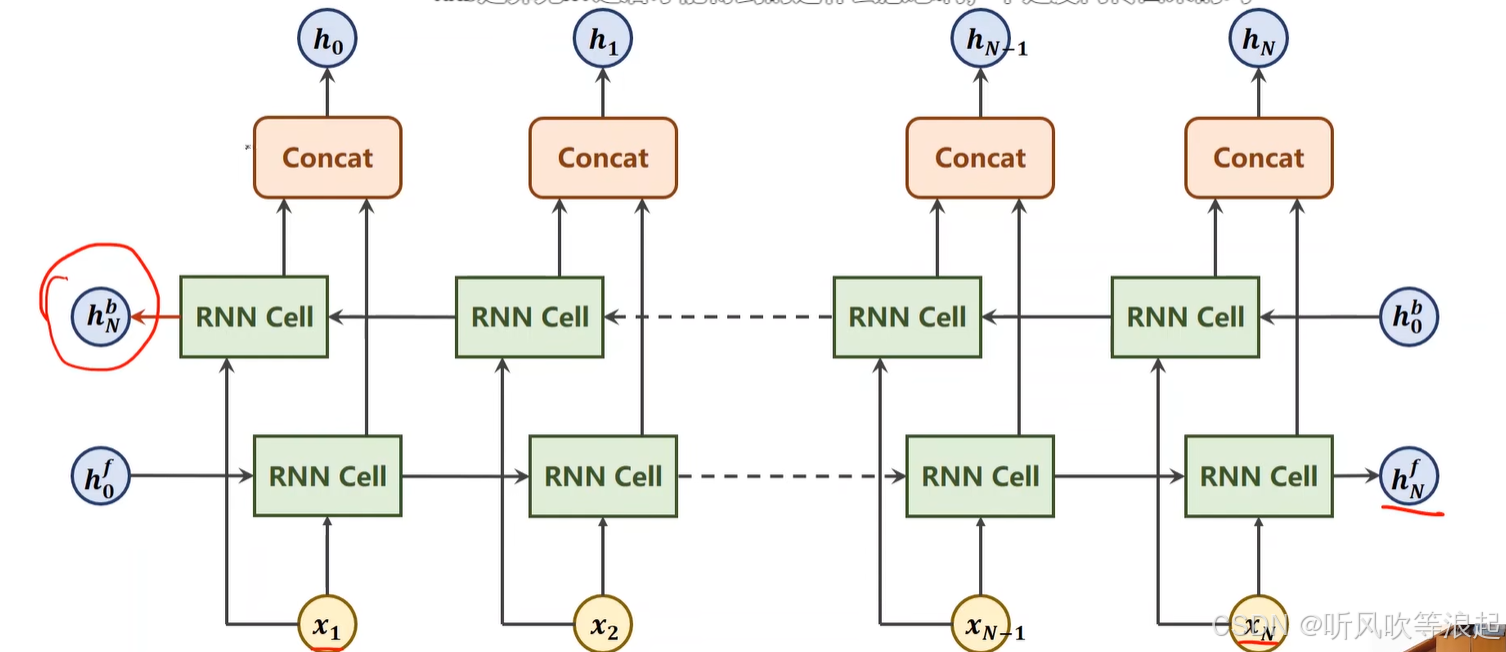
双向的循环神经网络就是反向来一次传播,把h的结果进行concat拼接
3. 代码解析
本文实现了一个基于双向GRU的RNN模型,用于对名字进行国家分类。
以下是详细的模块解析和功能说明:
1. 环境配置与设备检测
-
环境变量 :
KMP_DUPLICATE_LIB_OK用于避免OpenMP库重复加载的冲突。 -
设备选择:自动检测GPU(CUDA)是否可用,优先使用GPU加速计算。
2. 模型定义(RNNClassifier)
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(input_size, hidden_size)
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers,
bidirectional=bidirectional)
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)
def _init_hidden(self, batch_size):
return torch.zeros(self.n_layers * self.n_directions,
batch_size,
self.hidden_size).to(device)
def forward(self, input, seq_lengths):
# 确保lengths在CPU上
seq_lengths = seq_lengths.cpu() # 关键修复
input = input.t()
batch_size = input.size(1)
hidden = self._init_hidden(batch_size)
embedding = self.embedding(input)
# 打包序列(lengths必须在CPU)
packed = pack_padded_sequence(embedding, seq_lengths)
output, hidden = self.gru(packed, hidden)
# 处理双向输出
if self.n_directions == 2:
hidden = torch.cat([hidden[-1], hidden[-2]], dim=1)
else:
hidden = hidden[-1]
return self.fc(hidden)-
结构:
-
Embedding层 :将输入的ASCII字符编码映射到隐藏空间(
input_size=128对应ASCII字符数)。 -
GRU层 :支持双向设置(
bidirectional=True),通过n_layers指定层数。 -
全连接层:将GRU的最终隐藏状态映射到国家分类的输出维度。
-
-
核心逻辑:
-
前向传播 :输入序列通过Embedding层后,使用
pack_padded_sequence处理变长序列,提升计算效率。GRU的输出经过双向拼接(如果是双向),最终通过全连接层生成分类结果。 -
隐藏状态初始化 :初始隐藏状态为全零张量,形状为
(n_layers * n_directions, batch_size, hidden_size)。
-
3. 数据加载与处理(NameDataset)
class NameDataset(Dataset):
def __init__(self, is_train_set=True):
filename = './data/names_train.csv' if is_train_set else './data/names_test.csv'
with open(filename, 'r') as f:
lines = f.read().splitlines()
self.names = [line.split(',')[0] for line in lines]
self.countries = [line.split(',')[1] for line in lines]
self.country_list = sorted(set(self.countries))
self.country_dict = {c: i for i, c in enumerate(self.country_list)}
self.n_countries = len(self.country_list)
def __getitem__(self, index):
return self.names[index], self.country_dict[self.countries[index]]
def __len__(self):
return len(self.names)
def getCountriesNum(self):
return self.n_countries
def idx2country(self, index):
return self.country_list[index]-
数据格式 :从CSV文件加载数据,格式为
名字,国家(如"John,USA")。 -
功能:
-
国家编码 :将国家名称转换为唯一的整数索引(通过
country_dict)。 -
数据集接口 :继承
Dataset类,实现__getitem__和__len__方法,支持PyTorch的DataLoader。 -
辅助方法 :
getCountriesNum获取国家数量,idx2country通过索引反向查询国家名称。
-
4. 数据预处理(name2list与make_tensors)
-
字符编码 :
name2list将名字转换为ASCII码列表(如"John"→[74, 111, 104, 110])并记录长度。 -
张量生成 :
make_tensors将数据填充为等长张量,并按序列长度降序排列(优化pack_padded_sequence性能):-
填充:短序列补零,长序列截断。
-
设备分配 :数据张量(
seq_tensor和countries)移动到指定设备(GPU/CPU),lengths保留在CPU(因pack_padded_sequence要求)。
-
5. 训练与测试流程
def train():
total_loss = 0
for i, (names, countries) in enumerate(train_loader, 1):
inputs, lengths, labels = make_tensors(names, countries)
outputs = model(inputs, lengths)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if i % 10 == 0:
print(f'[{time_since(start)}] Epoch {epoch} '
f'[{i * len(inputs)}/{len(train_set)}] '
f'loss={total_loss / (i * len(inputs)):.4f}')
return total_loss / len(train_set)-
训练函数(train):
-
前向计算:输入数据通过模型,计算交叉熵损失。
-
反向传播:优化器(Adam)更新参数,每10个batch输出平均损失。
-
损失计算:累积损失除以总样本数,确保不同batch大小的可比性。
-
-
测试函数(test):
-
推理模式:禁用梯度计算,计算测试集准确率。
-
结果输出:打印正确样本数和总准确率。
def test():
correct = 0
with torch.no_grad():
for names, countries in test_loader:
inputs, lengths, labels = make_tensors(names, countries)
outputs = model(inputs, lengths)
pred = outputs.argmax(dim=1)
correct += (pred == labels).sum().item()
acc = correct / len(test_set)
print(f'Test Accuracy: {correct}/{len(test_set)} ({acc:.2%})\n')
return acc
-
6. 主程序与超参数
-
超参数:
-
HIDDEN_SIZE=128:GRU隐藏层维度。 -
BATCH_SIZE=256:批量大小。 -
N_LAYERS=2:GRU层数。 -
N_EPOCHS=50:训练轮次。 -
N_CHARS=128:输入字符的ASCII码范围(0-127)。
-
-
训练循环:
-
初始化模型、损失函数(交叉熵)和优化器(学习率0.001)。
-
每个epoch结束后在测试集上评估准确率,记录到
acc_history。
-
-
结果可视化 :使用
matplotlib绘制准确率随epoch变化的曲线。
7. 关键实现细节
-
变长序列处理 :通过
pack_padded_sequence压缩填充后的序列,避免无效计算。 -
双向GRU输出拼接 :双向GRU的最终隐藏状态是前向和后向的拼接(
hidden[-1]和hidden[-2])。 -
设备管理 :数据张量(输入、标签)和模型参数需在同一设备(GPU/CPU),但
lengths必须保留在CPU。
8. 潜在优化点
-
学习率调整 :可引入学习率调度器(如
ReduceLROnPlateau)提升收敛性。 -
早停机制:根据验证集准确率提前终止训练,防止过拟合。
-
字符嵌入维度 :调整Embedding层的输出维度(
hidden_size)可能影响模型表达能力。 -
数据增强:对名字进行扰动(如增删字符)提升泛化性。
9. 代码执行流程
-
加载训练集和测试集。
-
初始化模型并移至GPU(若可用)。
-
训练50个epoch,每个epoch结束后测试准确率。
-
绘制准确率变化曲线,观察模型性能。
该代码完整实现了从数据加载、模型定义到训练测试的全流程,适用于基于字符级别的短文本分类任务(如名字国籍分类)。通过调整超参数和模型结构,可适配其他类似场景。
4. 完整代码
完整代码:
python
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE' # 允许重复加载OpenMP库
import torch
import time
import matplotlib.pyplot as plt
import math
from torch.utils.data import DataLoader, Dataset
from torch.nn.utils.rnn import pack_padded_sequence
# 设备检测
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(input_size, hidden_size)
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers,
bidirectional=bidirectional)
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)
def _init_hidden(self, batch_size):
return torch.zeros(self.n_layers * self.n_directions,
batch_size,
self.hidden_size).to(device)
def forward(self, input, seq_lengths):
# 确保lengths在CPU上
seq_lengths = seq_lengths.cpu() # 关键修复
input = input.t()
batch_size = input.size(1)
hidden = self._init_hidden(batch_size)
embedding = self.embedding(input)
# 打包序列(lengths必须在CPU)
packed = pack_padded_sequence(embedding, seq_lengths)
output, hidden = self.gru(packed, hidden)
# 处理双向输出
if self.n_directions == 2:
hidden = torch.cat([hidden[-1], hidden[-2]], dim=1)
else:
hidden = hidden[-1]
return self.fc(hidden)
class NameDataset(Dataset):
def __init__(self, is_train_set=True):
filename = './data/names_train.csv' if is_train_set else './data/names_test.csv'
with open(filename, 'r') as f:
lines = f.read().splitlines()
self.names = [line.split(',')[0] for line in lines]
self.countries = [line.split(',')[1] for line in lines]
self.country_list = sorted(set(self.countries))
self.country_dict = {c: i for i, c in enumerate(self.country_list)}
self.n_countries = len(self.country_list)
def __getitem__(self, index):
return self.names[index], self.country_dict[self.countries[index]]
def __len__(self):
return len(self.names)
def getCountriesNum(self):
return self.n_countries
def idx2country(self, index):
return self.country_list[index]
def name2list(name):
return [ord(c) for c in name], len(name)
def make_tensors(names, countries):
# 生成序列和长度
sequences_and_lengths = [name2list(name) for name in names]
sequences = [s[0] for s in sequences_and_lengths]
lengths = torch.LongTensor([s[1] for s in sequences_and_lengths])
countries = torch.LongTensor(countries)
# 创建填充张量
seq_tensor = torch.zeros(len(sequences), lengths.max()).long()
for idx, (seq, length) in enumerate(zip(sequences, lengths)):
seq_tensor[idx, :length] = torch.LongTensor(seq)
# 按长度排序(保持lengths在CPU)
lengths, perm_idx = lengths.sort(dim=0, descending=True)
seq_tensor = seq_tensor[perm_idx].to(device) # 数据到GPU
countries = countries[perm_idx].to(device) # 数据到GPU
return seq_tensor, lengths, countries # lengths保留在CPU
def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m * 60
return f'{m}m {s:.0f}s'
def train():
total_loss = 0
for i, (names, countries) in enumerate(train_loader, 1):
inputs, lengths, labels = make_tensors(names, countries)
outputs = model(inputs, lengths)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if i % 10 == 0:
print(f'[{time_since(start)}] Epoch {epoch} '
f'[{i * len(inputs)}/{len(train_set)}] '
f'loss={total_loss / (i * len(inputs)):.4f}')
return total_loss / len(train_set)
def test():
correct = 0
with torch.no_grad():
for names, countries in test_loader:
inputs, lengths, labels = make_tensors(names, countries)
outputs = model(inputs, lengths)
pred = outputs.argmax(dim=1)
correct += (pred == labels).sum().item()
acc = correct / len(test_set)
print(f'Test Accuracy: {correct}/{len(test_set)} ({acc:.2%})\n')
return acc
if __name__ == '__main__':
# 超参数
HIDDEN_SIZE = 128
BATCH_SIZE = 256
N_LAYERS = 2
N_EPOCHS = 50
N_CHARS = 128 # ASCII字符数
# 数据加载
train_set = NameDataset(is_train_set=True)
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
test_set = NameDataset(is_train_set=False)
test_loader = DataLoader(test_set, batch_size=BATCH_SIZE)
N_COUNTRIES = train_set.getCountriesNum()
# 模型初始化
model = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRIES, N_LAYERS).to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练循环
start = time.time()
acc_history = []
for epoch in range(1, N_EPOCHS + 1):
print(f"=== Epoch {epoch}/{N_EPOCHS} ===")
train_loss = train()
val_acc = test()
acc_history.append(val_acc)
# 结果可视化
plt.plot(acc_history)
plt.title('Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.show()5. 结果
下载:基于RNN循环神经网络实现的时间序列英文name国家分类资源-CSDN文库
如下:
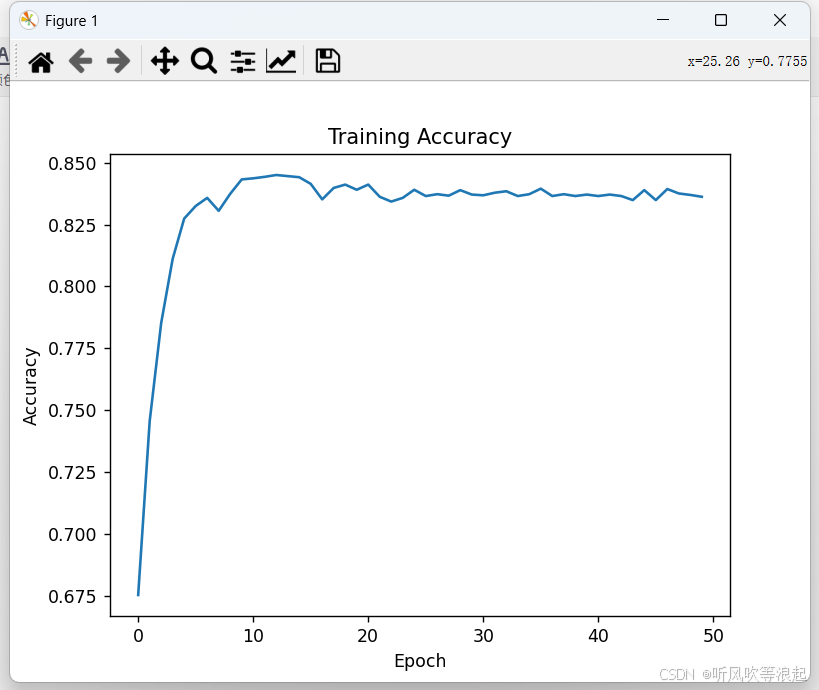
日志:
Using device: cuda
=== Epoch 1/50 ===
0m 0s Epoch 1 2560/13374 loss=0.0082
0m 0s Epoch 1 5120/13374 loss=0.0073
0m 1s Epoch 1 7680/13374 loss=0.0067
0m 1s Epoch 1 10240/13374 loss=0.0063
0m 1s Epoch 1 12800/13374 loss=0.0059
Test Accuracy: 4524/6700 (67.52%)
=== Epoch 2/50 ===
0m 1s Epoch 2 2560/13374 loss=0.0043
0m 1s Epoch 2 5120/13374 loss=0.0040
0m 2s Epoch 2 7680/13374 loss=0.0039
0m 2s Epoch 2 10240/13374 loss=0.0038
0m 2s Epoch 2 12800/13374 loss=0.0037
Test Accuracy: 4995/6700 (74.55%)
=== Epoch 3/50 ===
0m 2s Epoch 3 2560/13374 loss=0.0030
0m 2s Epoch 3 5120/13374 loss=0.0029
0m 2s Epoch 3 7680/13374 loss=0.0029
0m 3s Epoch 3 10240/13374 loss=0.0029
0m 3s Epoch 3 12800/13374 loss=0.0028
Test Accuracy: 5261/6700 (78.52%)
=== Epoch 4/50 ===
0m 3s Epoch 4 2560/13374 loss=0.0025
0m 3s Epoch 4 5120/13374 loss=0.0025
0m 3s Epoch 4 7680/13374 loss=0.0025
0m 4s Epoch 4 10240/13374 loss=0.0024
0m 4s Epoch 4 12800/13374 loss=0.0024
Test Accuracy: 5435/6700 (81.12%)
=== Epoch 5/50 ===
0m 4s Epoch 5 2560/13374 loss=0.0020
0m 4s Epoch 5 5120/13374 loss=0.0021
0m 4s Epoch 5 7680/13374 loss=0.0021
0m 4s Epoch 5 10240/13374 loss=0.0021
0m 5s Epoch 5 12800/13374 loss=0.0020
Test Accuracy: 5544/6700 (82.75%)
=== Epoch 6/50 ===
0m 5s Epoch 6 2560/13374 loss=0.0018
0m 5s Epoch 6 5120/13374 loss=0.0019
0m 5s Epoch 6 7680/13374 loss=0.0018
0m 5s Epoch 6 10240/13374 loss=0.0018
0m 6s Epoch 6 12800/13374 loss=0.0018
Test Accuracy: 5578/6700 (83.25%)
=== Epoch 7/50 ===
0m 6s Epoch 7 2560/13374 loss=0.0015
0m 6s Epoch 7 5120/13374 loss=0.0016
0m 6s Epoch 7 7680/13374 loss=0.0016
0m 6s Epoch 7 10240/13374 loss=0.0016
0m 7s Epoch 7 12800/13374 loss=0.0016
Test Accuracy: 5600/6700 (83.58%)
=== Epoch 8/50 ===
0m 7s Epoch 8 2560/13374 loss=0.0013
0m 7s Epoch 8 5120/13374 loss=0.0014
0m 7s Epoch 8 7680/13374 loss=0.0014
0m 8s Epoch 8 10240/13374 loss=0.0014
0m 8s Epoch 8 12800/13374 loss=0.0014
Test Accuracy: 5565/6700 (83.06%)
=== Epoch 9/50 ===
0m 8s Epoch 9 2560/13374 loss=0.0012
0m 8s Epoch 9 5120/13374 loss=0.0012
0m 8s Epoch 9 7680/13374 loss=0.0012
0m 9s Epoch 9 10240/13374 loss=0.0013
0m 9s Epoch 9 12800/13374 loss=0.0013
Test Accuracy: 5611/6700 (83.75%)
=== Epoch 10/50 ===
0m 9s Epoch 10 2560/13374 loss=0.0011
0m 9s Epoch 10 5120/13374 loss=0.0011
0m 9s Epoch 10 7680/13374 loss=0.0011
0m 10s Epoch 10 10240/13374 loss=0.0011
0m 10s Epoch 10 12800/13374 loss=0.0011
Test Accuracy: 5650/6700 (84.33%)
=== Epoch 11/50 ===
0m 10s Epoch 11 2560/13374 loss=0.0010
0m 10s Epoch 11 5120/13374 loss=0.0010
0m 11s Epoch 11 7680/13374 loss=0.0010
0m 11s Epoch 11 10240/13374 loss=0.0010
0m 11s Epoch 11 12800/13374 loss=0.0010
Test Accuracy: 5653/6700 (84.37%)
=== Epoch 12/50 ===
0m 11s Epoch 12 2560/13374 loss=0.0008
0m 12s Epoch 12 5120/13374 loss=0.0008
0m 12s Epoch 12 7680/13374 loss=0.0008
0m 12s Epoch 12 10240/13374 loss=0.0008
0m 12s Epoch 12 12800/13374 loss=0.0008
Test Accuracy: 5657/6700 (84.43%)
=== Epoch 13/50 ===
0m 12s Epoch 13 2560/13374 loss=0.0008
0m 13s Epoch 13 5120/13374 loss=0.0007
0m 13s Epoch 13 7680/13374 loss=0.0007
0m 13s Epoch 13 10240/13374 loss=0.0007
0m 13s Epoch 13 12800/13374 loss=0.0007
Test Accuracy: 5662/6700 (84.51%)
=== Epoch 14/50 ===
0m 13s Epoch 14 2560/13374 loss=0.0006
0m 14s Epoch 14 5120/13374 loss=0.0006
0m 14s Epoch 14 7680/13374 loss=0.0006
0m 14s Epoch 14 10240/13374 loss=0.0006
0m 14s Epoch 14 12800/13374 loss=0.0006
Test Accuracy: 5659/6700 (84.46%)
=== Epoch 15/50 ===
0m 14s Epoch 15 2560/13374 loss=0.0005
0m 14s Epoch 15 5120/13374 loss=0.0005
0m 15s Epoch 15 7680/13374 loss=0.0005
0m 15s Epoch 15 10240/13374 loss=0.0005
0m 15s Epoch 15 12800/13374 loss=0.0005
Test Accuracy: 5656/6700 (84.42%)
=== Epoch 16/50 ===
0m 15s Epoch 16 2560/13374 loss=0.0004
0m 15s Epoch 16 5120/13374 loss=0.0004
0m 16s Epoch 16 7680/13374 loss=0.0004
0m 16s Epoch 16 10240/13374 loss=0.0005
0m 16s Epoch 16 12800/13374 loss=0.0005
Test Accuracy: 5638/6700 (84.15%)
=== Epoch 17/50 ===
0m 16s Epoch 17 2560/13374 loss=0.0004
0m 16s Epoch 17 5120/13374 loss=0.0004
0m 16s Epoch 17 7680/13374 loss=0.0004
0m 17s Epoch 17 10240/13374 loss=0.0004
0m 17s Epoch 17 12800/13374 loss=0.0004
Test Accuracy: 5596/6700 (83.52%)
=== Epoch 18/50 ===
0m 17s Epoch 18 2560/13374 loss=0.0004
0m 17s Epoch 18 5120/13374 loss=0.0004
0m 17s Epoch 18 7680/13374 loss=0.0004
0m 18s Epoch 18 10240/13374 loss=0.0004
0m 18s Epoch 18 12800/13374 loss=0.0004
Test Accuracy: 5627/6700 (83.99%)
=== Epoch 19/50 ===
0m 18s Epoch 19 2560/13374 loss=0.0003
0m 18s Epoch 19 5120/13374 loss=0.0003
0m 18s Epoch 19 7680/13374 loss=0.0003
0m 18s Epoch 19 10240/13374 loss=0.0003
0m 19s Epoch 19 12800/13374 loss=0.0003
Test Accuracy: 5636/6700 (84.12%)
=== Epoch 20/50 ===
0m 19s Epoch 20 2560/13374 loss=0.0003
0m 19s Epoch 20 5120/13374 loss=0.0003
0m 19s Epoch 20 7680/13374 loss=0.0003
0m 19s Epoch 20 10240/13374 loss=0.0003
0m 20s Epoch 20 12800/13374 loss=0.0003
Test Accuracy: 5622/6700 (83.91%)
=== Epoch 21/50 ===
0m 20s Epoch 21 2560/13374 loss=0.0003
0m 20s Epoch 21 5120/13374 loss=0.0003
0m 20s Epoch 21 7680/13374 loss=0.0003
0m 20s Epoch 21 10240/13374 loss=0.0003
0m 21s Epoch 21 12800/13374 loss=0.0003
Test Accuracy: 5636/6700 (84.12%)
=== Epoch 22/50 ===
0m 21s Epoch 22 2560/13374 loss=0.0003
0m 21s Epoch 22 5120/13374 loss=0.0003
0m 21s Epoch 22 7680/13374 loss=0.0003
0m 21s Epoch 22 10240/13374 loss=0.0003
0m 21s Epoch 22 12800/13374 loss=0.0003
Test Accuracy: 5603/6700 (83.63%)
=== Epoch 23/50 ===
0m 22s Epoch 23 2560/13374 loss=0.0002
0m 22s Epoch 23 5120/13374 loss=0.0002
0m 22s Epoch 23 7680/13374 loss=0.0002
0m 22s Epoch 23 10240/13374 loss=0.0003
0m 22s Epoch 23 12800/13374 loss=0.0003
Test Accuracy: 5590/6700 (83.43%)
=== Epoch 24/50 ===
0m 23s Epoch 24 2560/13374 loss=0.0002
0m 23s Epoch 24 5120/13374 loss=0.0002
0m 23s Epoch 24 7680/13374 loss=0.0002
0m 23s Epoch 24 10240/13374 loss=0.0002
0m 23s Epoch 24 12800/13374 loss=0.0003
Test Accuracy: 5600/6700 (83.58%)
=== Epoch 25/50 ===
0m 24s Epoch 25 2560/13374 loss=0.0002
0m 24s Epoch 25 5120/13374 loss=0.0002
0m 24s Epoch 25 7680/13374 loss=0.0002
0m 24s Epoch 25 10240/13374 loss=0.0002
0m 24s Epoch 25 12800/13374 loss=0.0003
Test Accuracy: 5622/6700 (83.91%)
=== Epoch 26/50 ===
0m 25s Epoch 26 2560/13374 loss=0.0002
0m 25s Epoch 26 5120/13374 loss=0.0002
0m 25s Epoch 26 7680/13374 loss=0.0002
0m 25s Epoch 26 10240/13374 loss=0.0002
0m 25s Epoch 26 12800/13374 loss=0.0002
Test Accuracy: 5605/6700 (83.66%)
=== Epoch 27/50 ===
0m 26s Epoch 27 2560/13374 loss=0.0002
0m 26s Epoch 27 5120/13374 loss=0.0002
0m 26s Epoch 27 7680/13374 loss=0.0002
0m 26s Epoch 27 10240/13374 loss=0.0002
0m 26s Epoch 27 12800/13374 loss=0.0002
Test Accuracy: 5610/6700 (83.73%)
=== Epoch 28/50 ===
0m 26s Epoch 28 2560/13374 loss=0.0002
0m 27s Epoch 28 5120/13374 loss=0.0002
0m 27s Epoch 28 7680/13374 loss=0.0002
0m 27s Epoch 28 10240/13374 loss=0.0002
0m 27s Epoch 28 12800/13374 loss=0.0002
Test Accuracy: 5606/6700 (83.67%)
=== Epoch 29/50 ===
0m 27s Epoch 29 2560/13374 loss=0.0002
0m 28s Epoch 29 5120/13374 loss=0.0002
0m 28s Epoch 29 7680/13374 loss=0.0002
0m 28s Epoch 29 10240/13374 loss=0.0002
0m 28s Epoch 29 12800/13374 loss=0.0002
Test Accuracy: 5621/6700 (83.90%)
=== Epoch 30/50 ===
0m 28s Epoch 30 2560/13374 loss=0.0002
0m 28s Epoch 30 5120/13374 loss=0.0002
0m 29s Epoch 30 7680/13374 loss=0.0002
0m 29s Epoch 30 10240/13374 loss=0.0002
0m 29s Epoch 30 12800/13374 loss=0.0002
Test Accuracy: 5609/6700 (83.72%)
=== Epoch 31/50 ===
0m 29s Epoch 31 2560/13374 loss=0.0002
0m 29s Epoch 31 5120/13374 loss=0.0002
0m 30s Epoch 31 7680/13374 loss=0.0002
0m 30s Epoch 31 10240/13374 loss=0.0002
0m 30s Epoch 31 12800/13374 loss=0.0002
Test Accuracy: 5607/6700 (83.69%)
=== Epoch 32/50 ===
0m 30s Epoch 32 2560/13374 loss=0.0001
0m 30s Epoch 32 5120/13374 loss=0.0002
0m 30s Epoch 32 7680/13374 loss=0.0002
0m 31s Epoch 32 10240/13374 loss=0.0002
0m 31s Epoch 32 12800/13374 loss=0.0002
Test Accuracy: 5614/6700 (83.79%)
=== Epoch 33/50 ===
0m 31s Epoch 33 2560/13374 loss=0.0001
0m 31s Epoch 33 5120/13374 loss=0.0002
0m 31s Epoch 33 7680/13374 loss=0.0002
0m 32s Epoch 33 10240/13374 loss=0.0002
0m 32s Epoch 33 12800/13374 loss=0.0002
Test Accuracy: 5618/6700 (83.85%)
=== Epoch 34/50 ===
0m 32s Epoch 34 2560/13374 loss=0.0002
0m 32s Epoch 34 5120/13374 loss=0.0002
0m 32s Epoch 34 7680/13374 loss=0.0002
0m 33s Epoch 34 10240/13374 loss=0.0002
0m 33s Epoch 34 12800/13374 loss=0.0002
Test Accuracy: 5605/6700 (83.66%)
=== Epoch 35/50 ===
0m 33s Epoch 35 2560/13374 loss=0.0002
0m 33s Epoch 35 5120/13374 loss=0.0002
0m 33s Epoch 35 7680/13374 loss=0.0002
0m 33s Epoch 35 10240/13374 loss=0.0002
0m 34s Epoch 35 12800/13374 loss=0.0002
Test Accuracy: 5610/6700 (83.73%)
=== Epoch 36/50 ===
0m 34s Epoch 36 2560/13374 loss=0.0002
0m 34s Epoch 36 5120/13374 loss=0.0002
0m 34s Epoch 36 7680/13374 loss=0.0002
0m 34s Epoch 36 10240/13374 loss=0.0002
0m 35s Epoch 36 12800/13374 loss=0.0002
Test Accuracy: 5625/6700 (83.96%)
=== Epoch 37/50 ===
0m 35s Epoch 37 2560/13374 loss=0.0001
0m 35s Epoch 37 5120/13374 loss=0.0002
0m 35s Epoch 37 7680/13374 loss=0.0002
0m 35s Epoch 37 10240/13374 loss=0.0002
0m 35s Epoch 37 12800/13374 loss=0.0002
Test Accuracy: 5605/6700 (83.66%)
=== Epoch 38/50 ===
0m 36s Epoch 38 2560/13374 loss=0.0001
0m 36s Epoch 38 5120/13374 loss=0.0001
0m 36s Epoch 38 7680/13374 loss=0.0002
0m 36s Epoch 38 10240/13374 loss=0.0002
0m 36s Epoch 38 12800/13374 loss=0.0002
Test Accuracy: 5610/6700 (83.73%)
=== Epoch 39/50 ===
0m 37s Epoch 39 2560/13374 loss=0.0002
0m 37s Epoch 39 5120/13374 loss=0.0002
0m 37s Epoch 39 7680/13374 loss=0.0002
0m 37s Epoch 39 10240/13374 loss=0.0002
0m 37s Epoch 39 12800/13374 loss=0.0002
Test Accuracy: 5605/6700 (83.66%)
=== Epoch 40/50 ===
0m 38s Epoch 40 2560/13374 loss=0.0002
0m 38s Epoch 40 5120/13374 loss=0.0002
0m 38s Epoch 40 7680/13374 loss=0.0002
0m 38s Epoch 40 10240/13374 loss=0.0002
0m 38s Epoch 40 12800/13374 loss=0.0002
Test Accuracy: 5609/6700 (83.72%)
=== Epoch 41/50 ===
0m 39s Epoch 41 2560/13374 loss=0.0001
0m 39s Epoch 41 5120/13374 loss=0.0002
0m 39s Epoch 41 7680/13374 loss=0.0002
0m 39s Epoch 41 10240/13374 loss=0.0002
0m 39s Epoch 41 12800/13374 loss=0.0002
Test Accuracy: 5605/6700 (83.66%)
=== Epoch 42/50 ===
0m 40s Epoch 42 2560/13374 loss=0.0001
0m 40s Epoch 42 5120/13374 loss=0.0002
0m 40s Epoch 42 7680/13374 loss=0.0002
0m 40s Epoch 42 10240/13374 loss=0.0002
0m 40s Epoch 42 12800/13374 loss=0.0002
Test Accuracy: 5609/6700 (83.72%)
=== Epoch 43/50 ===
0m 41s Epoch 43 2560/13374 loss=0.0001
0m 41s Epoch 43 5120/13374 loss=0.0002
0m 41s Epoch 43 7680/13374 loss=0.0002
0m 41s Epoch 43 10240/13374 loss=0.0002
0m 41s Epoch 43 12800/13374 loss=0.0002
Test Accuracy: 5605/6700 (83.66%)
=== Epoch 44/50 ===
0m 41s Epoch 44 2560/13374 loss=0.0002
0m 42s Epoch 44 5120/13374 loss=0.0002
0m 42s Epoch 44 7680/13374 loss=0.0002
0m 42s Epoch 44 10240/13374 loss=0.0002
0m 42s Epoch 44 12800/13374 loss=0.0002
Test Accuracy: 5594/6700 (83.49%)
=== Epoch 45/50 ===
0m 42s Epoch 45 2560/13374 loss=0.0001
0m 43s Epoch 45 5120/13374 loss=0.0002
0m 43s Epoch 45 7680/13374 loss=0.0002
0m 43s Epoch 45 10240/13374 loss=0.0002
0m 43s Epoch 45 12800/13374 loss=0.0002
Test Accuracy: 5621/6700 (83.90%)
=== Epoch 46/50 ===
0m 43s Epoch 46 2560/13374 loss=0.0002
0m 44s Epoch 46 5120/13374 loss=0.0001
0m 44s Epoch 46 7680/13374 loss=0.0002
0m 44s Epoch 46 10240/13374 loss=0.0002
0m 44s Epoch 46 12800/13374 loss=0.0002
Test Accuracy: 5594/6700 (83.49%)
=== Epoch 47/50 ===
0m 44s Epoch 47 2560/13374 loss=0.0001
0m 45s Epoch 47 5120/13374 loss=0.0002
0m 45s Epoch 47 7680/13374 loss=0.0002
0m 45s Epoch 47 10240/13374 loss=0.0002
0m 45s Epoch 47 12800/13374 loss=0.0002
Test Accuracy: 5624/6700 (83.94%)
=== Epoch 48/50 ===
0m 45s Epoch 48 2560/13374 loss=0.0002
0m 46s Epoch 48 5120/13374 loss=0.0002
0m 46s Epoch 48 7680/13374 loss=0.0002
0m 46s Epoch 48 10240/13374 loss=0.0002
0m 46s Epoch 48 12800/13374 loss=0.0002
Test Accuracy: 5612/6700 (83.76%)
=== Epoch 49/50 ===
0m 47s Epoch 49 2560/13374 loss=0.0001
0m 47s Epoch 49 5120/13374 loss=0.0001
0m 47s Epoch 49 7680/13374 loss=0.0001
0m 47s Epoch 49 10240/13374 loss=0.0002
0m 47s Epoch 49 12800/13374 loss=0.0002
Test Accuracy: 5608/6700 (83.70%)
=== Epoch 50/50 ===
0m 48s Epoch 50 2560/13374 loss=0.0001
0m 48s Epoch 50 5120/13374 loss=0.0001
0m 48s Epoch 50 7680/13374 loss=0.0002
0m 48s Epoch 50 10240/13374 loss=0.0002
0m 48s Epoch 50 12800/13374 loss=0.0002
Test Accuracy: 5603/6700 (83.63%)