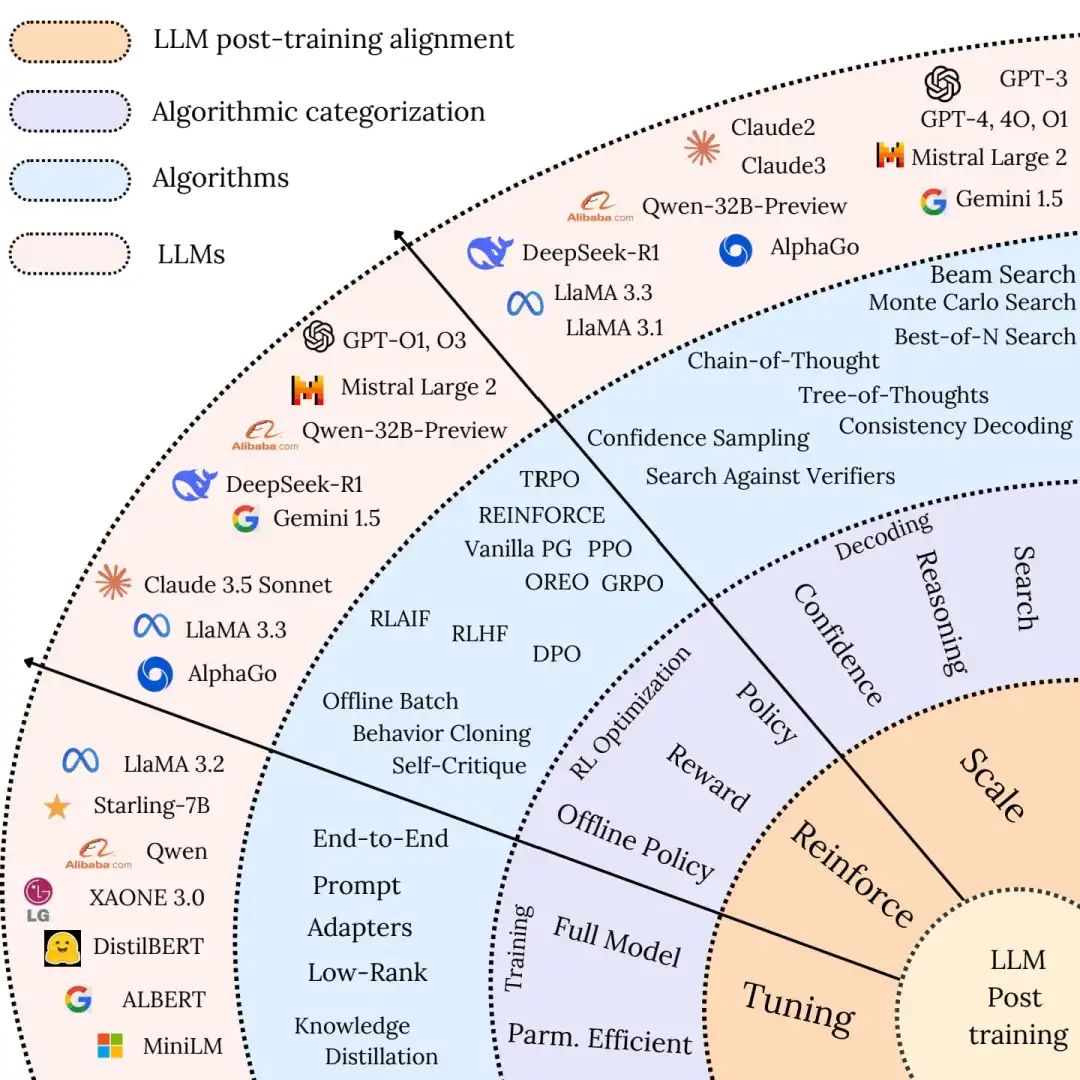
1. LLM的后训练分类
- Fine-tuning
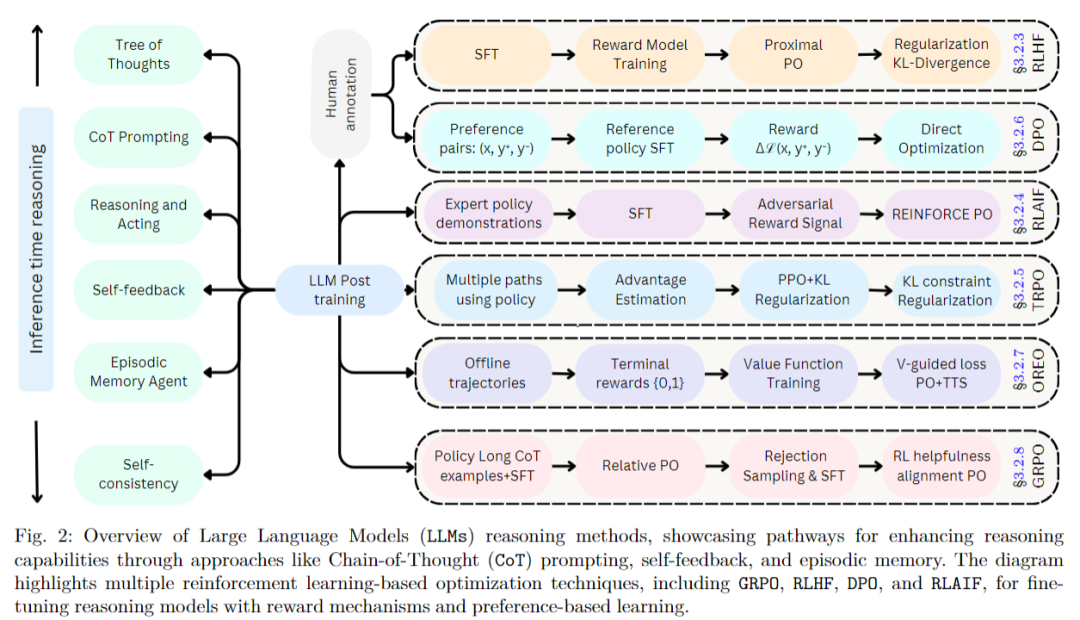
- Reinforcement Learning
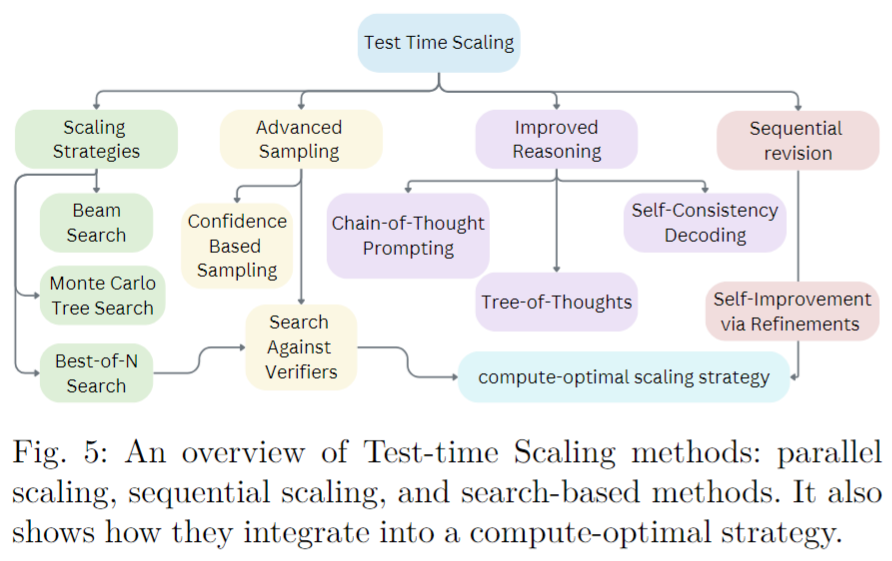
- Test-time Scaling
|------------------------|------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------|
| 方法 | 优点 | 缺点 |
| Fine-tuning | 任务适应性:能够针对特定任务或领域进行优化,提升模型在该任务上的性能。 数据驱动优化:利用标注数据直接调整模型参数,使模型更好地符合任务要求。 广泛适用性:适用于多种任务,包括文本生成、问答、分类等。 | 过拟合风险:可能导致模型在训练数据上表现良好,但在未见过的数据上性能下降。 计算成本高:需要对整个模型或大量参数进行更新,计算资源消耗大。 数据偏差敏感:如果训练数据有偏差,模型可能学习到错误的模式。 |
| Reinforcement Learning | 动态优化:能够根据环境反馈动态调整策略,优化长期目标。 适应性强:可以处理复杂的、动态变化的任务,如对话生成、多步推理等。 对齐用户意图:通过奖励信号优化模型输出,使其更符合人类偏好。 | 奖励函数设计复杂:需要精心设计奖励函数,以避免奖励误导或奖励黑客问题。 训练不稳定:由于奖励信号稀疏且主观,可能导致训练过程不稳定。 计算资源需求高:尤其是当模型规模较大时,训练成本显著增加。 |
| Test-time Scaling | 推理时优化:在推理阶段动态调整模型行为,无需重新训练模型。 资源灵活分配:可以根据任务复杂度灵活调整计算资源,提高推理效率。 性能提升:在某些任务上,通过优化推理过程可以显著提升模型性能。 | 推理延迟增加:在某些情况下,如使用复杂的搜索策略,可能导致推理时间延长。 适用性有限:某些方法可能仅适用于特定类型的任务或模型。 环境依赖:某些技术(如蒙特卡洛树搜索)可能对环境设置较为敏感。 |
2. 微调
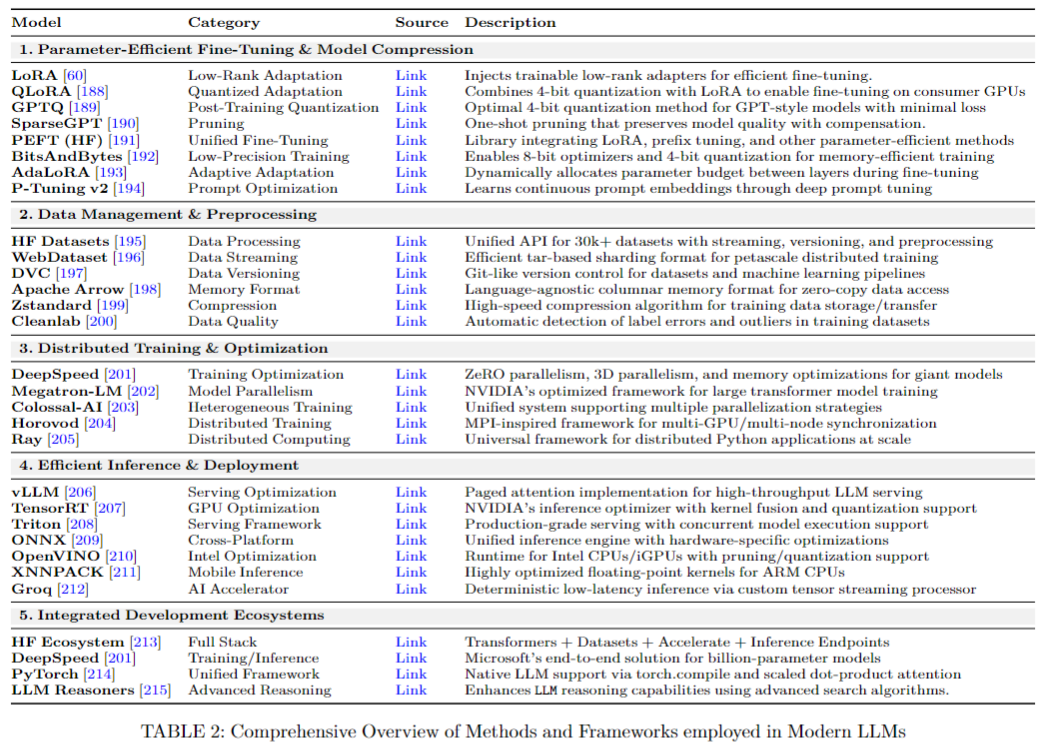
3. 强化学习
4. Test Time Scaling(测试时扩展)