1 Hadoop文件系统概述
Hadoop分布式文件系统(HDFS)是Hadoop生态的核心存储组件,专为大规模数据集设计,具有高容错性和高吞吐量特性。

HDFS核心特性:
- 分布式存储:文件被分割成块(默认128MB)分布存储
- 多副本机制:每个块默认3副本,保障数据安全
- 一次写入多次读取:适合批处理场景
2 HDFS文件操作基础
2.1 常用Shell命令
|------------------|------|---------------------------------|
| 命令 | 描述 | 示例 |
| hadoop fs -ls | 列出目录 | hadoop fs -ls /user |
| hadoop fs -mkdir | 创建目录 | hadoop fs -mkdir /data |
| hadoop fs -put | 上传文件 | hadoop fs -put local.txt /data |
| hadoop fs -get | 下载文件 | hadoop fs -get /data/remote.txt |
| hadoop fs -cat | 查看内容 | hadoop fs -cat /data/file.txt |
| hadoop fs -rm | 删除文件 | hadoop fs -rm /data/old.txt |
2.2 Java API操作简单示例
// 创建配置对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
// 创建目录
Path dirPath = new Path("/user/hadoop/mydir");
fs.mkdirs(dirPath);
// 上传文件
Path localPath = new Path("localfile.txt");
Path hdfsPath = new Path("/user/hadoop/mydir/remotefile.txt");
fs.copyFromLocalFile(localPath, hdfsPath);
// 列出文件
RemoteIterator<LocatedFileStatus> files = fs.listFiles(hdfsPath, true);
while(files.hasNext()) {
LocatedFileStatus file = files.next();
System.out.println(file.getPath());
}3 高级文件操作
3.1 文件合并与归档

# HAR创建命令
hadoop archive -archiveName data.har -p /input /output3.2 快照管理
# 启用快照功能
hdfs dfsadmin -allowSnapshot /user/important
# 创建快照
hdfs dfs -createSnapshot /user/important backup3.3 权限控制
# 设置目录权限(类似Linux)
hadoop fs -chmod -R 755 /user/data
hadoop fs -chown hadoop:hadoop /user/data4 HDFS文件操作原理
4.1 文件写入流程
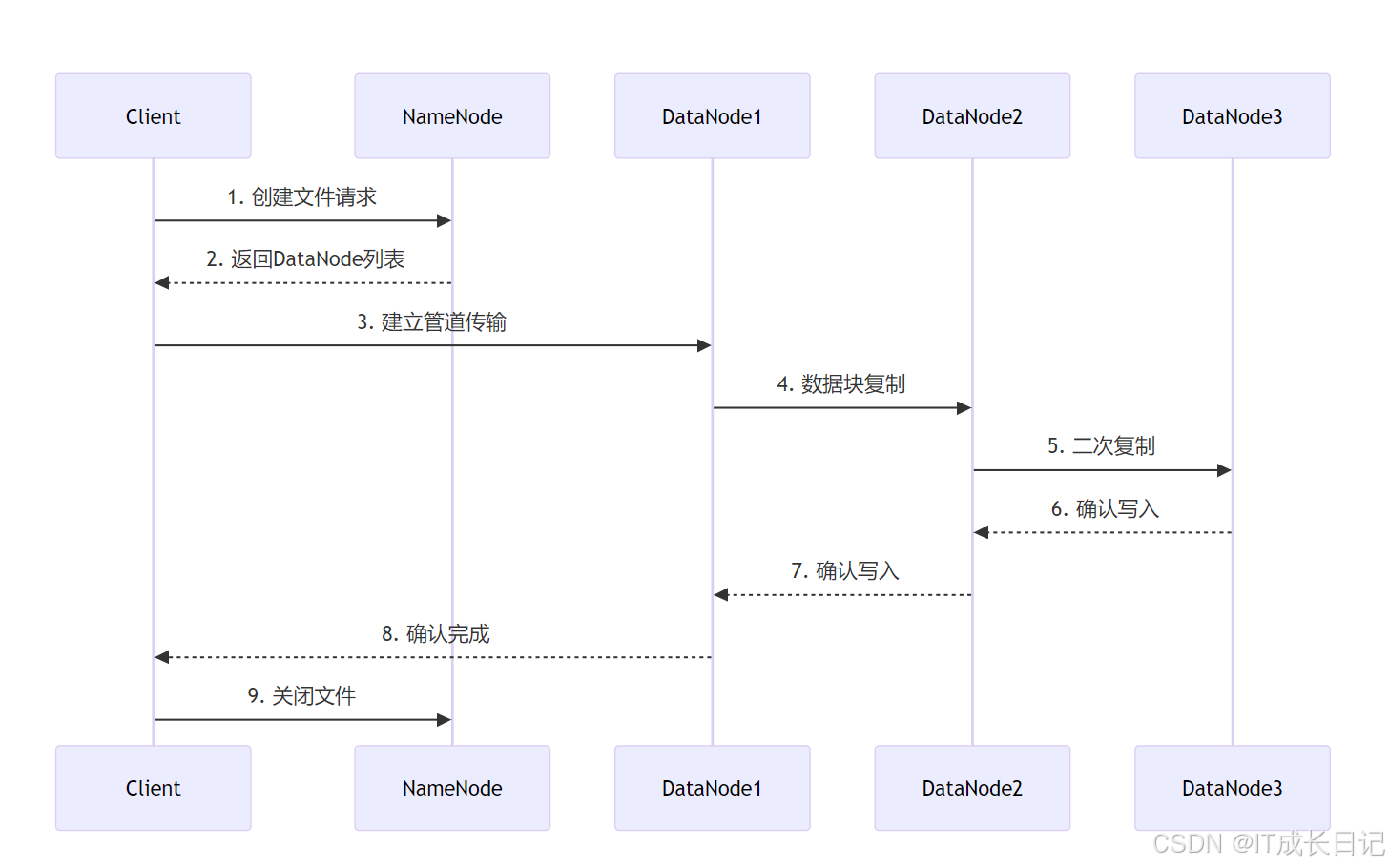
初始化阶段
- 客户端首先向NameNode发起创建文件请求
- NameNode响应并返回一组适合存储数据的DataNode列表
数据传输阶段- 客户端与第一个DataNode建立管道式数据传输连接
- 数据块按照流水线方式依次复制到多个DataNode
- 数据沿管道反向确认,确保所有副本写入成功
完成阶段- 最终由主DataNode向客户端返回写入确认
- 客户端通知NameNode完成文件关闭操作
4.2 文件读取流程

5 性能优化技巧
5.1 小文件处理方案
|------------------------|--------------|---------|
| 方案 | 优点 | 缺点 |
| HAR归档 | 减少NameNode负载 | 仍需解压访问 |
| SequenceFile | 支持键值对存储 | 需定制读取逻辑 |
| CombineFileInputFormat | MapReduce优化 | 仅限MR作业 |
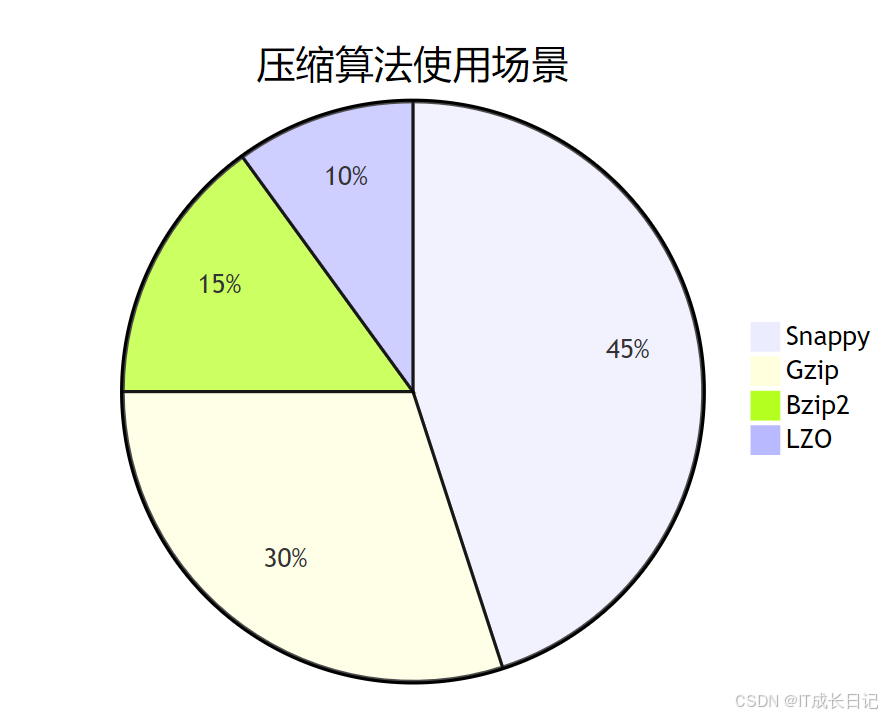
5.2 压缩算法选择
6 故障排查指南
6.1 常见问题及解决方案
-
文件无法删除
强制删除
hadoop fs -rm -f /data/file
检查权限
hadoop fs -ls -d /data/path
-
空间不足
检查配额
hdfs dfs -count -q /data
清理回收站
hadoop fs -expunge
-
块损坏恢复
检查损坏块
hdfs fsck / -list-corruptfileblocks
删除损坏块
hdfs fsck / -delete