导读在无人机技术快速发展的今天,如何确保无人机在复杂动态环境中的安全飞行成为一个关键挑战。传统的导航方法通常将决策过程分解为预测和规划两个独立模块,这种手工设计的系统虽然在特定环境中表现良好,但当环境条件发生变化时,往往需要仔细的参数调整才能维持性能。此外,这些方法通常基于不准确的数学模型假设和为提高计算效率而进行的简化,可能导致次优解。
©️【深蓝AI】编译
本文由paper一作------Zhefan Xu授权【深蓝AI】编译发布!
论文题目: NavRL: Learning Safe Flight in Dynamic Environments
论文作者: Zhefan Xu,Xinming Han,Haoyu Shen,Hanyu Jin,Kenji Shimada
论文地址: NavRL: Learning Safe Flight in Dynamic Environments | IEEE Journals & Magazine | IEEE Xplore
代码地址: https://github.com/Zhefan-Xu/NavRL

近年来,强化学习(RL)在无人机控制领域展现出巨大潜力,为解决上述问题提供了新思路。强化学习允许无人机通过经验学习决策能力,提供更好的适应性和性能。然而,将强化学习应用于实际无人机导航仍面临三大挑战:
-
模拟到现实的迁移问题:强化学习需要在模拟环境中训练无人机,但模拟与现实世界之间存在感知信息差距,特别是相机图像方面。
-
安全保障机制:即使经过训练的强化学习策略表现良好,由于神经网络的黑盒特性,仍难以保证在所有情况下的安全性。
-
训练效率问题:训练强化学习策略需要大量无人机经验,单无人机数据
收集往往导致收敛速度慢和有限的探索机会。
针对这些挑战,论文《NavRL: Learning Safe Flight in Dynamic Environments》提出了一种创新解决方案,从多维度带来创新突破。在感知环节,设计了针对静态和动态障碍物的独特表征方式,提升感知精度与效率;强化学习公式化中,创新的状态、动作表示及奖励函数设计,增强决策灵活性与适应性;引入速度障碍物概念构建安全护盾,有效降低神经网络风险;利用 NVIDIA Isaac Sim 进行并行训练,大幅加快训练收敛速度。这些创新点为无人机在动态环境安全飞行提供了更可靠的解决方案,具有重要的研究与应用价值。

NavRL框架是一种基于深度强化学习的导航方法,专为解决无人机在动态环境中的安全飞行问题而设计。NavRL框架基于近端策略优化(PPO)算法,通过感知系统处理RGB-D图像和无人机内部状态,生成静态和动态障碍物的表示。如图1所示,这些表示被输入到两个特征提取器中,产生与无人机内部状态连接的状态嵌入。本节将详细介绍NavRL的核心技术组件,包括状态表示、动作表示、奖励函数设计以及安全屏障机制。
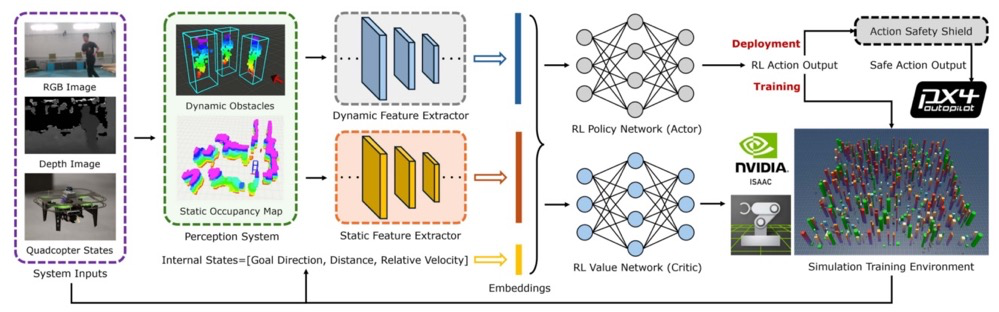
图1-NavRL整体框架。在训练阶段,采用演员-评论家网络结构在NVIDIA Isaac Sim环境中并行训练无人机。在部署阶段,策略网络生成的动作会通过安全屏障机制进一步优化,确保无人机控制的安全性。
状态表示
状态由无人机内部状态、动态障碍物和静态障碍物三部分构成。无人机内部状态提供了关于无人机方向、到导航目标的距离以及当前速度的详细信息,定义为
其中,和
分别表示无人机位置和目标位置,
是无人机当前速度,上标
表示向量在"目标坐标系"中表示。这种目标坐标系的定义非常巧妙,它以无人机起始位置为原点,x轴与从起始位置指向目标位置的向量对齐,y轴平行于地面。这种坐标变换减少了对全局坐标系的依赖,提高了强化学习训练的收敛速度,并将应用于障碍物状态表示。
动态障碍物(如移动物体)使用2D矩阵表示:
这里每个动态障碍物的状态向量表示为:
其中,和
分别表示动态障碍物的中心位置和速度,
表示障碍物的高度和宽度,
是预定义的动态障碍物数量,这种表示方法将相对位置向量分为单位向量和范数,能提高收敛速度。
与动态障碍物不同,静态障碍物(如墙壁、柱子等)表示为地图体素,无法直接输入神经网络。NavRL采用3D射线投射技术从无人机位置对地图进行采样。如图2所示,射线在水平面和垂直平面全方向投射,最大范围由用户定义的射线投射角度间隔决定。对于每个对角射线投射角度,记录水平面内所有射线的长度到向量
。超出最大范围的射线被赋予等于最大范围加小偏移的长度,允许障碍物不存在时的表示。这种设计使系统能以恒定时间复杂度 访问占用信息,在每个时间步递归更新占用概率并清除动态障碍物的占用数据。

图2-地图射线投射示意图
动作表示
在每个时间步,NavRL提供速度控制用于导航和避障。相比于低级控制,速度控制具有更好的跨平台迁移性和泛化能力,同时对人类更具可解释性并易于监督。控制策略首先推断归一化速度
,并通过下式得到最终速度:
其中是用户定义的最大速度。最终速度在目标坐标系中表示,需要应用坐标变换到无人机。这种方法比要求强化学习策略直接学习动作限制并适应训练动作范围提供了更大的灵活性。
奖励函数设计
NavRL的奖励函数是训练强化学习控制策略的核心,由多项奖励加权组成:
其中表示速度奖励且速度越高奖励越大,
表示静态安全奖励,
表示动态安全奖励,当无人机与障碍物保持更大距离时,奖励越大,
表示平滑度奖励,用于计算当前时间步和前一时间步速度之间的差异,差异越小奖励越大
表示高度奖励。

论文进行了一系列仿真和物理实验来验证NavRL框架的有效性。NavRL采用课程学习训练控制策略,如图3所示,随动态障碍物增多,无课程学习的导航成功率大幅下降,有课程学习的下降较缓,如环境动态障碍物为100个时,有课程学习的成功率达 80.96%,远高于无课程学习的 62.30%。
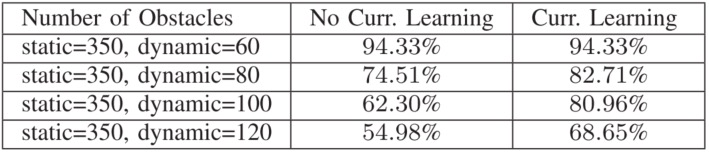
图3-不同静态/动态障碍物下,无课程学习与课程学习的比较结果
仿真实验
在 Gazebo 模拟的室内动态环境中,无人机成功避开障碍安全导航,如图4所示。
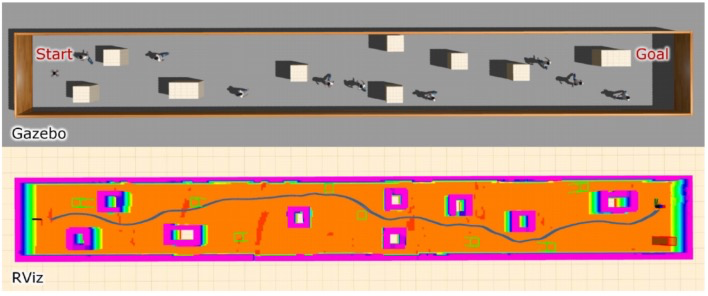
图4-在仿真走廊环境中无人机实现安全导航
与 EGO、ViGO 等规划器对比,NavRL 在动态和混合环境中碰撞次数最少,如图5所示。在静态环境与 EGO 碰撞率相当,EGO 在动态和混合环境因地图更新问题表现不佳,ViGO 在障碍物靠近时难避障。NavRL 的安全护盾能有效减少碰撞,在动态环境效果更明显。
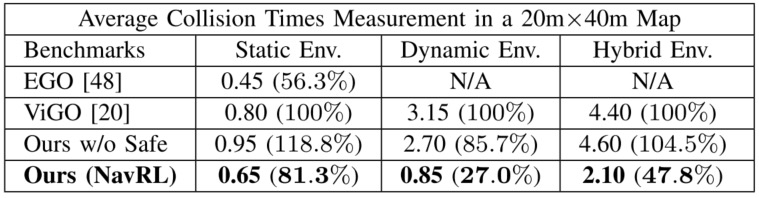
图5-NavRL与不同算法的性能比较
物理实验
论文中在包含静态障碍物和行人活动的真实场景里对 NavRL 框架展开测试,结果现实搭载NavRL算法的无人机成功避开各类障碍,顺利到达目的地,如视频1所示。此外,论文中对机载电脑的运算时间做了记录,其中静态感知模块为15ms、动态感知模块 27ms、RL 策略网络 7ms、安全护盾模块 16ms,满足实际复杂环境中的实时性要求。

NavRL 是一种基于深度强化学习的导航方法,专为解决无人机在动态环境中的安全飞行问题而设计。其主要贡献包括提出创新的基于强化学习的 UAV 导航系统,通过近端策略优化算法实现安全自主飞行且能零样本迁移;引入安全屏障机制解决神经网络黑盒特性带来的安全隐患;利用 NVIDIA Isaac Sim 并行训练提高效率并结合课程学习策略快速学习导航策略。技术创新点有采用目标坐标系表示减少对全局坐标系依赖、设计多组件奖励函数引导安全高效导航、应用速度障碍概念于安全屏障机制防止潜在碰撞。NavRL 在复杂环境导航、实时决策系统、跨平台部署等方面有广阔应用前景,但也存在对感知系统依赖、训练计算资源需求大、超参数调整困难等局限性。未来可在多智能体协作、端到端学习、自适应安全屏障、迁移学习增强等方向深入探索,总之,NavRL 通过创新的状态表示、安全屏障机制和高效训练方法,为无人机在动态环境中的安全飞行提供了有效解决方案,有望推动无人机技术进步和应用拓展 。
Ref:
NavRL: Learning Safe Flight in Dynamic Environments