一. 利用IDEA开发Spark-SQL
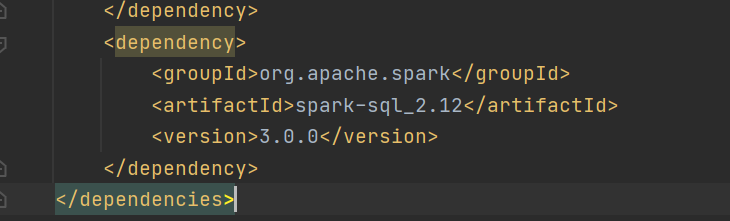
1 在pop.xml中添加spark-sql依赖
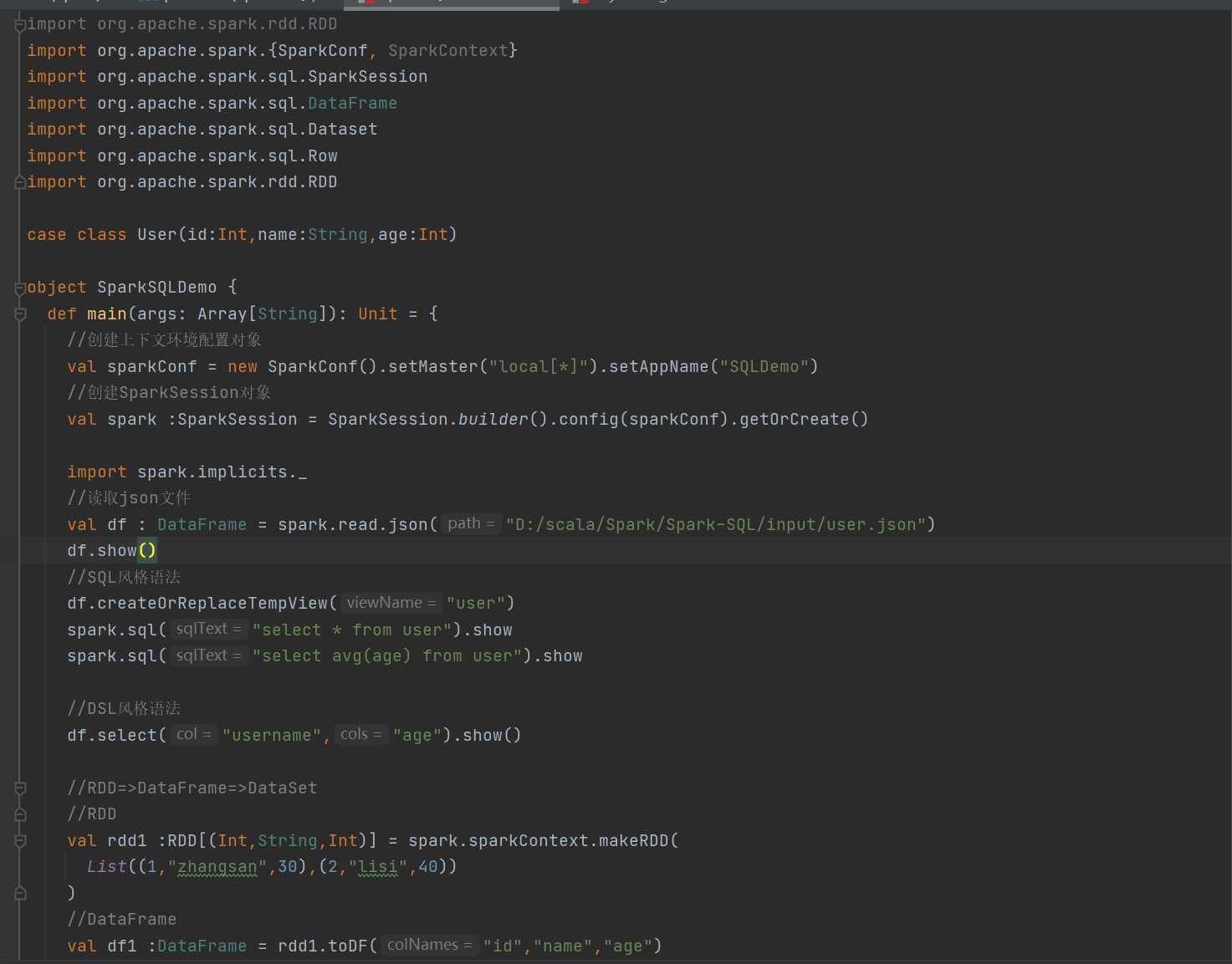
2 spark-sql测试代码
1)在idea中读取json文件创建DataFrame
2)SQL风格语法
3 )DSL风格语法
4) RDD转换成DataFrame,DataFrame转换成DataSet
5)DataSet转换成DataFrame ,DataFrame转换成 RDD
实例演示
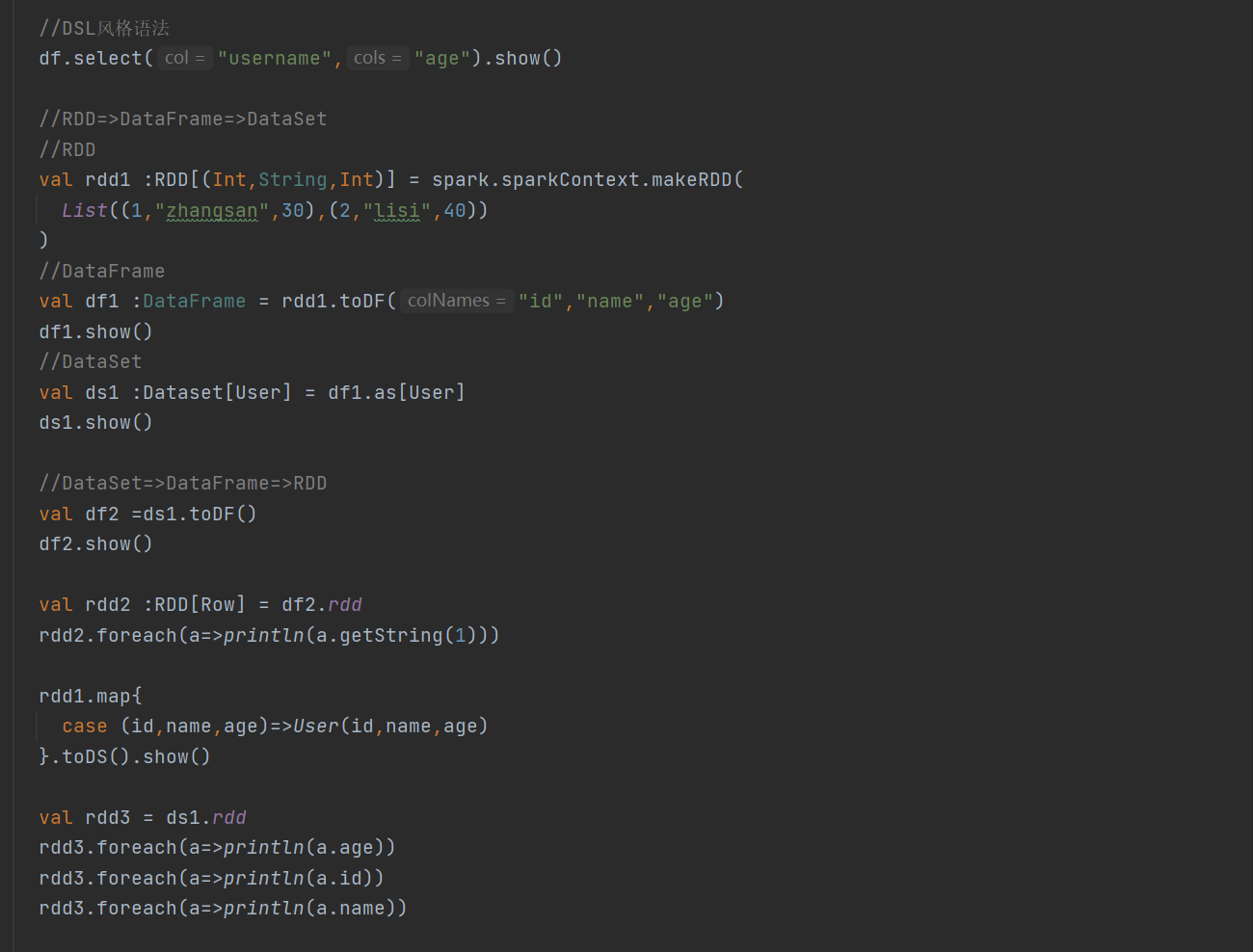
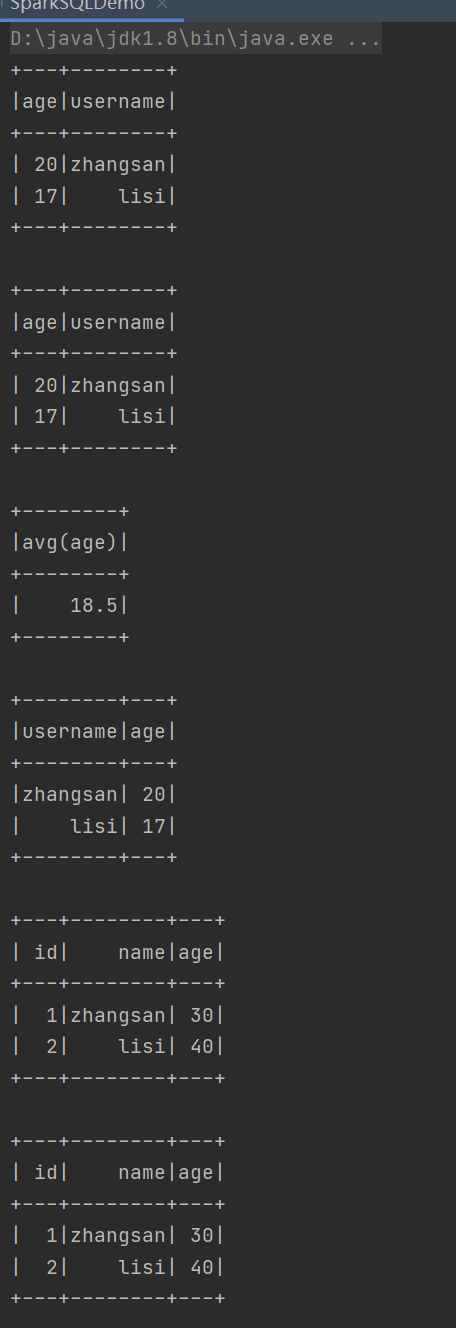
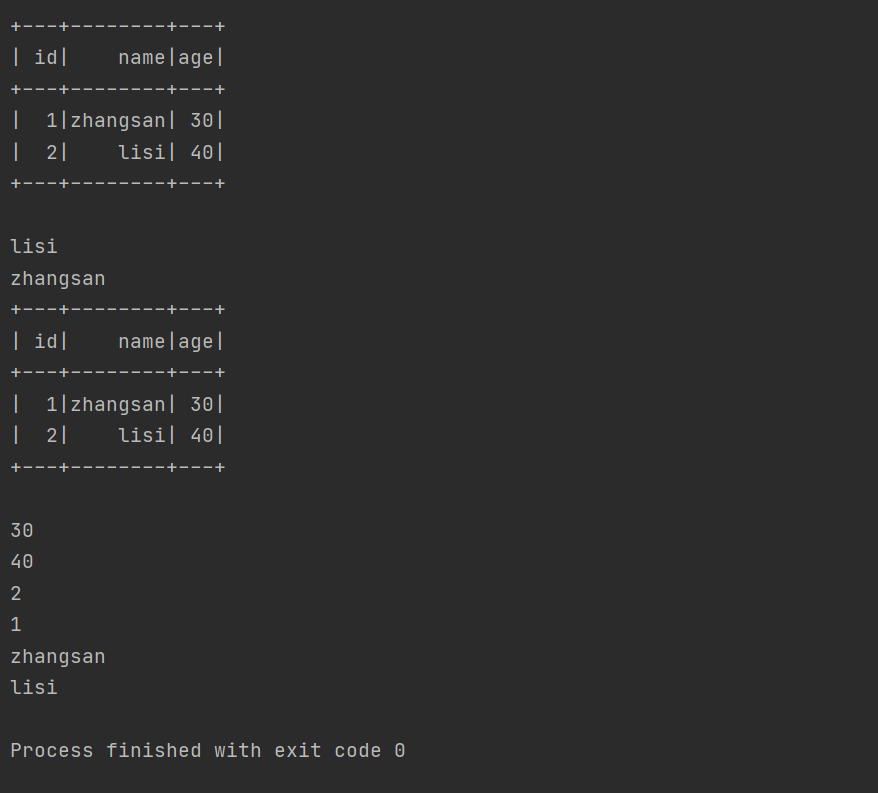
运行结果
二 自定义函数
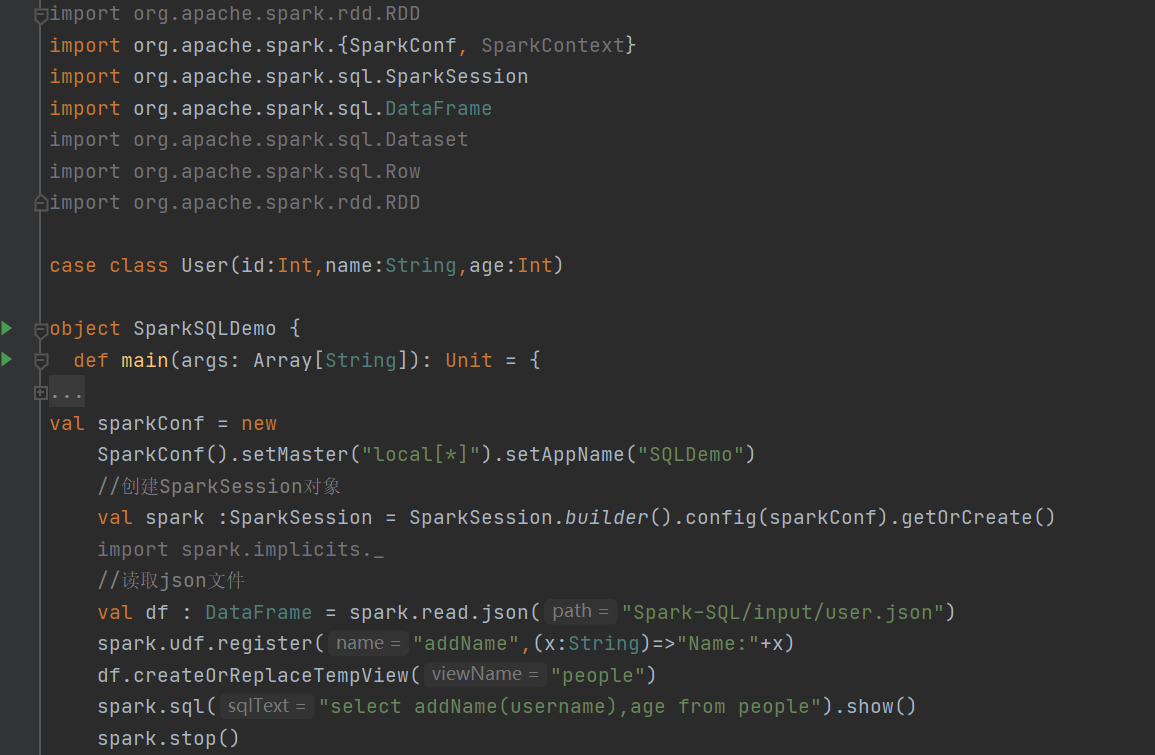
UDF
创建SparkSession ,读取json文件
实例演示
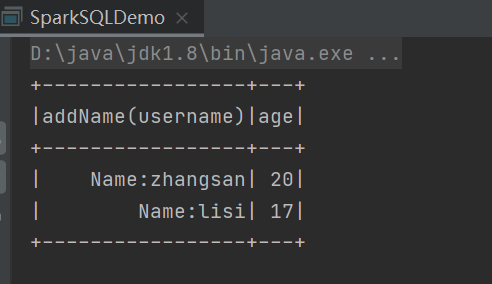
运行结果
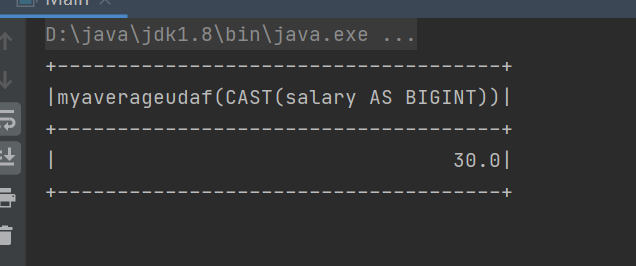
三 UDAF
任务需求:计算平均工资
方式一 :RDD
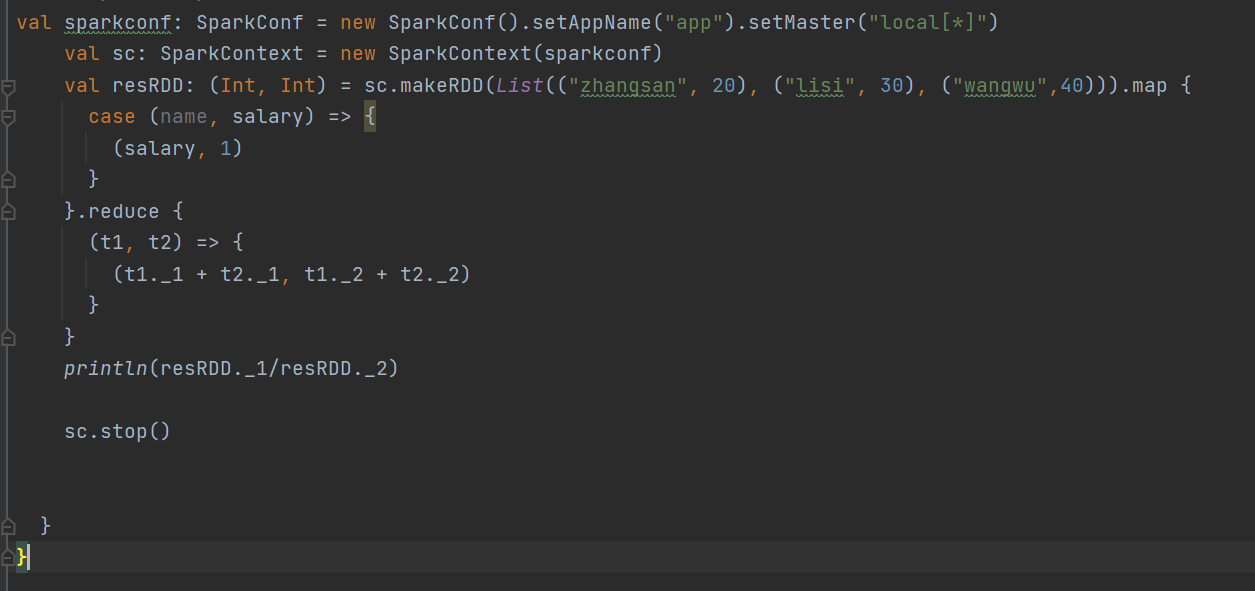
运行结果
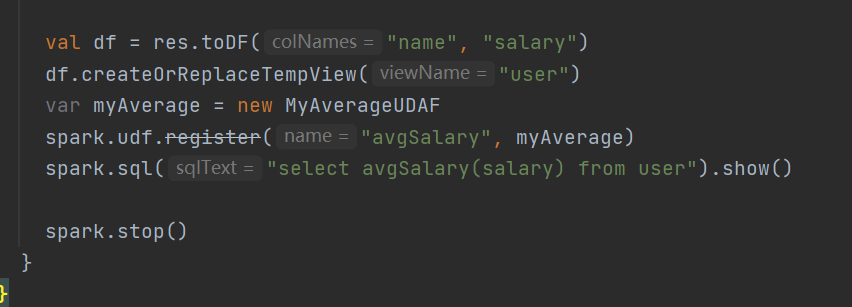
方式二:弱类型UDAF

运行结果
方式三:强类型UDAF
实例演示
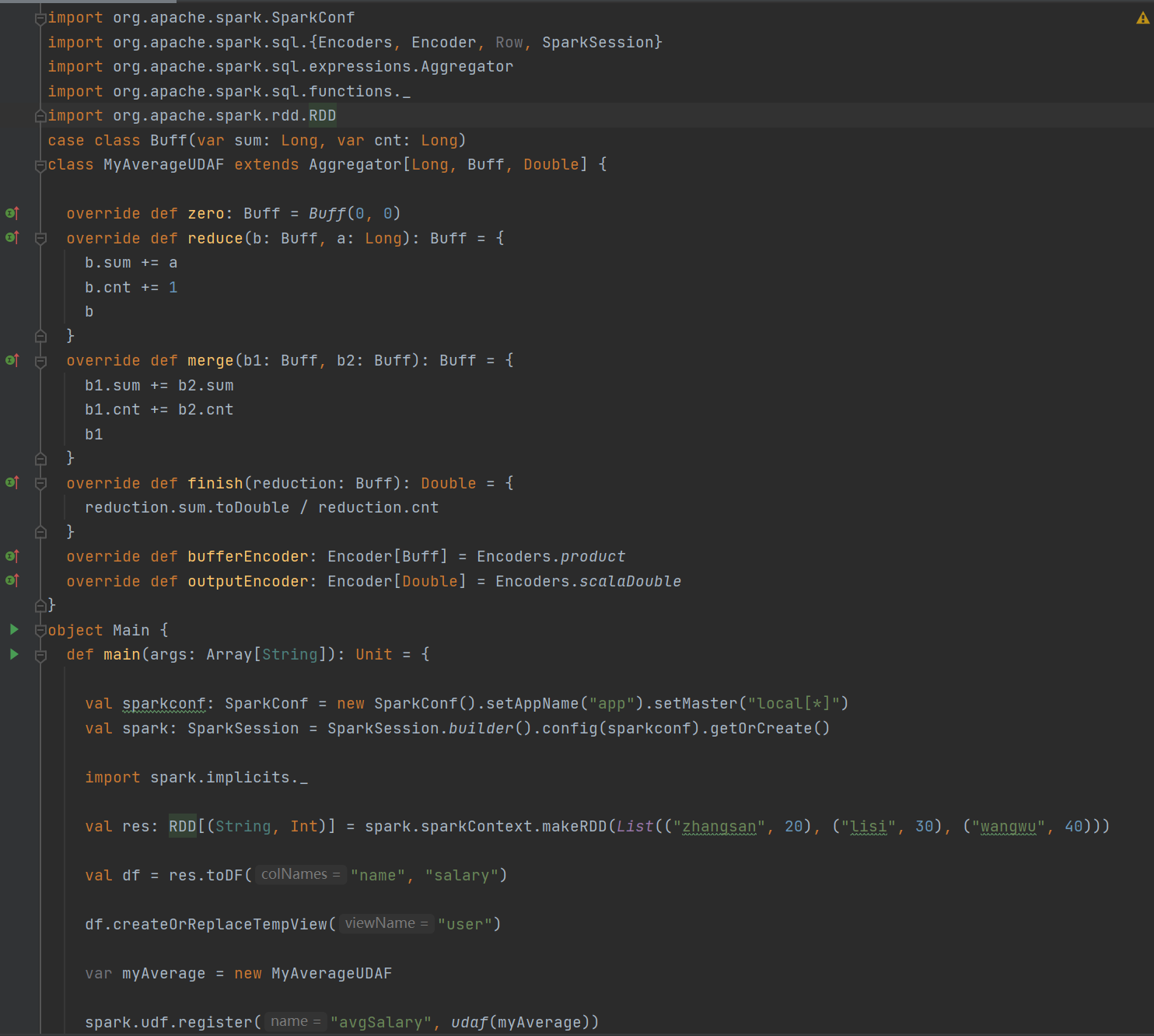
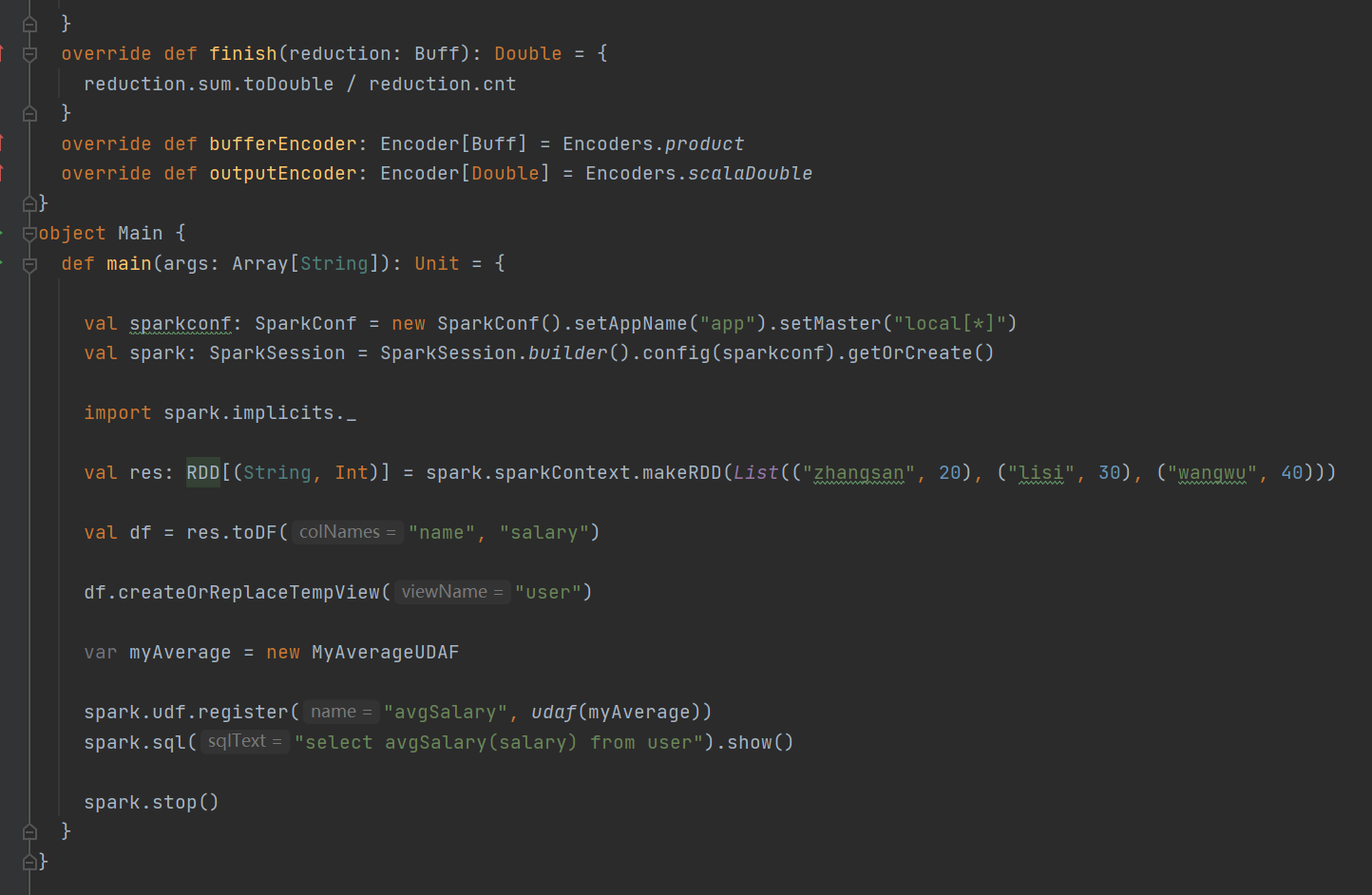
运行结果