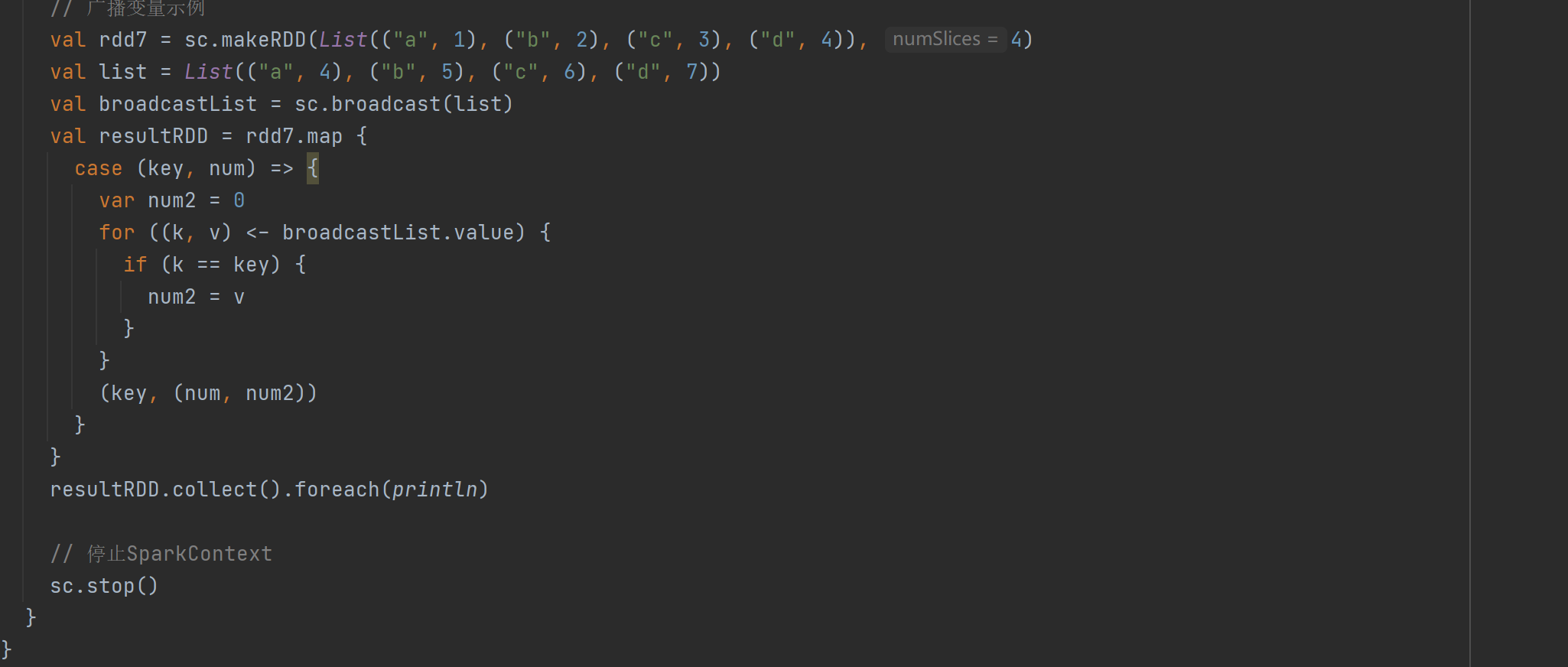
- 常用聚合与获取数据算子
-
reduce:聚集RDD所有元素,先分区内聚合,再分区间聚合 ,如 rdd.reduce(+) 可对 RDDInt 类型数据求和。
-
collect:在驱动程序中以数组形式返回数据集所有元素。
-
foreach:分布式遍历RDD元素并调用指定函数 。
-
count:返回RDD中元素个数。
-
first:返回RDD的第一个元素。
-
take:返回RDD前n个元素组成的数组。
-
takeOrdered:返回RDD排序后的前n个元素组成的数组。
代码
结果

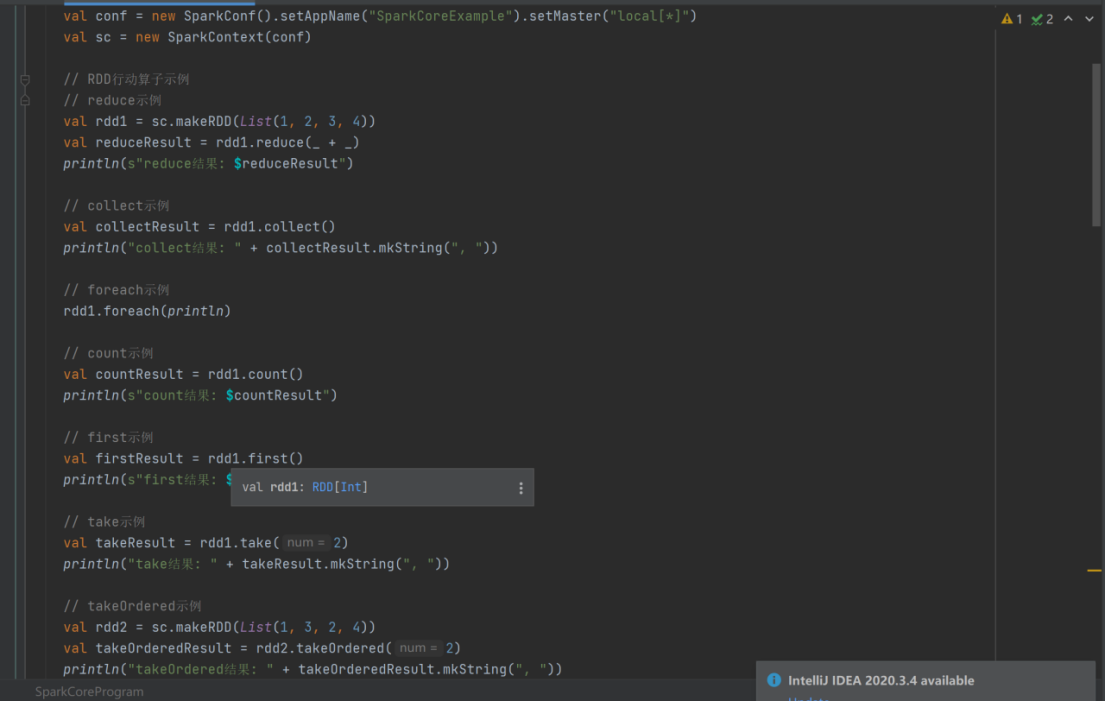
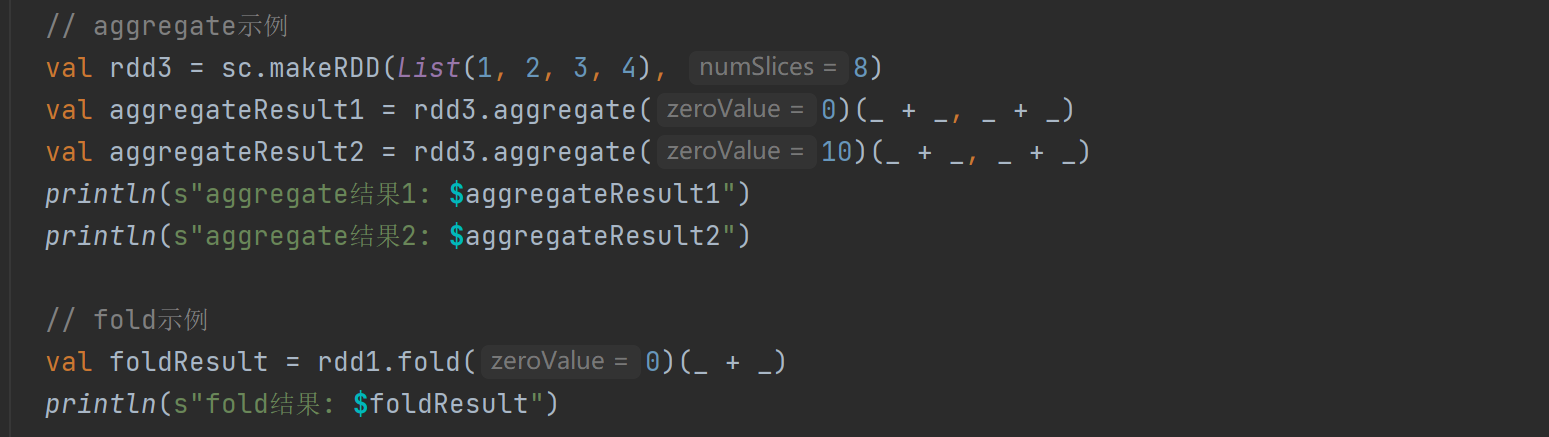
- 复杂聚合算子
-
aggregate:分区数据先与初始值聚合,再进行分区间聚合,可自定义聚合逻辑。
-
fold:是 aggregate 的简化版,按指定操作和初始值进行折叠操作。
代码
结果

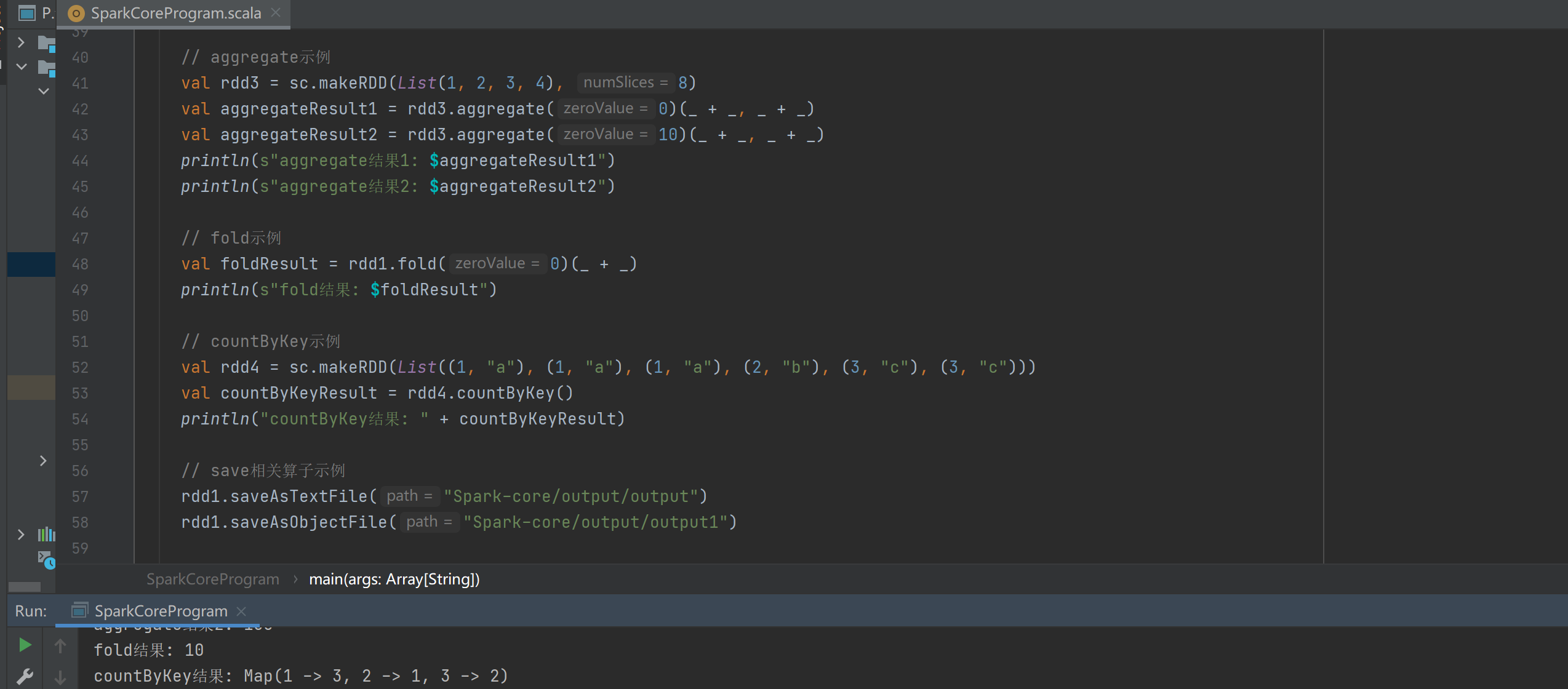
- 特定功能算子
-
countByKey:统计 RDD(K, V) 中每种key的个数。
-
save相关算子:包括 saveAsTextFile 保存为文本文件、 saveAsObjectFile 保存为对象文件 、 saveAsSequenceFile (了解即可),用于将RDD数据保存为不同格式。
- 累加器:主要用于将Executor端变量信息聚合到Driver端。Driver程序定义变量后,Executor端每个Task都会有该变量副本,Task更新副本值后传回Driver端进行合并。文档通过简单示例展示了累加器的基本用法,还给出了自定义累加器实现wordcount的详细步骤,包括创建自定义累加器类,重写相关方法,以及在Spark程序中注册和调用自定义累加器。
代码
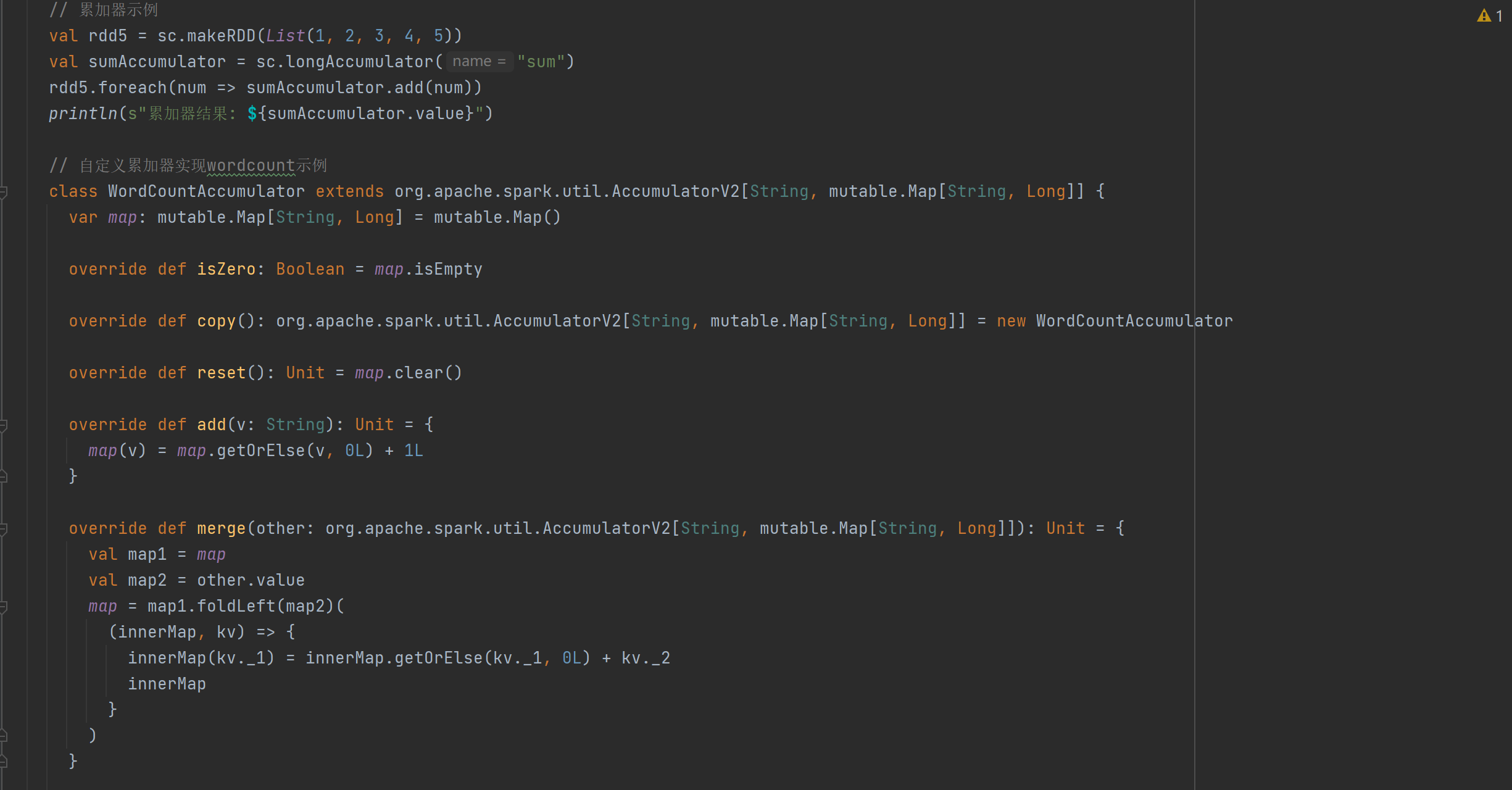
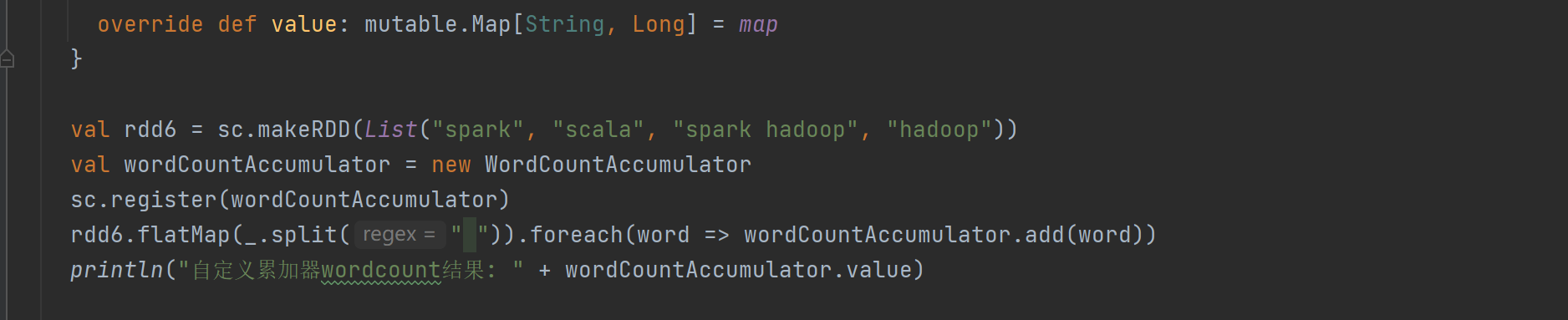
结果

- 广播变量:用于高效分发较大的只读对象到所有工作节点,供一个或多个Spark操作使用。以向所有节点发送较大只读查询表为例,说明了广播变量的应用场景。文档通过代码示例,展示了广播变量的使用过程,先创建广播变量,然后在RDD操作中使用广播变量的值,最终输出结果。