数据加载与保存
通用方式:
SparkSQL 提供了通用的保存数据和数据加载的方式 。这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据,SparkSQL ++默认读取和保存的文件格式为parquet++
数据加载方法:
spark.read.load 是加载数据的通用方法。如果读取不同格式的数据,可以对不同的数据格式进行设定。
spark.read.format("...").option("...").load("...")
三种加载数据的方法:
使用 option 参数加载数据,在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable
(适用于需要传入数据库连接信息的情况。)
使用 load方法加载数据,在"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"格式下需要传入加载数据的路径。
(适用于指定数据路径和类型的情况。)
使用format 加载数据,指定加载的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和
"textFile"。
++前面都是使用 read API 先把文件加载到 DataFrame 然后再查询,其实,我们也可以直接在文件上进行查询: 文件格式.'文件路径'++
++spark.sql("select * from json.' Spark-SQL/input/user.json'").show++
数据保存方法:
主要介绍了两种保存数据的方法,一种是df write.save的通用方法,另一种是通过指定format、option和save(需要指定数据格式和保存路径的情况)路径来保存。
format("..."):指定保存的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"。
save ("..."):在"csv"、"orc"、"parquet"和"textFile"格式下需要传入保存数据的路径。
option("..."):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbta
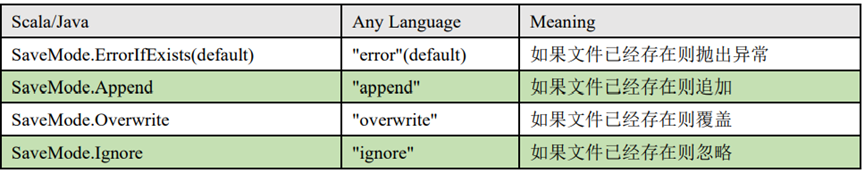
save mode的不同选项,如append、error、overwrite和ignore,以及它们在文件已存在时的处理方式。
Parquet
Spark SQL 的默认数据源为 Parquet 格式。Parquet 是一种能够有效存储嵌套数据的列式
存储格式。
加载数据:
val df = spark.read.load("examples/src/main/resources/users.parquet")
保存数据:
var df = spark.read.json("/opt/module/data/input/people.json")
df.write.mode("append").save("/opt/module/data/output")
数据格式与数据源
默认数据源介绍了 Spark 的默认数据源,能够存储嵌套数据,简化了数据操作。强调了默认数据源的便利性,通常不需要修改配置。
JSON
JSON数据处理:
spark SQL自动检测JSON数据集的结构,并将其加载为dataset。
可以通过 SparkSession.read.json()去加载 JSON 文件。
强调了spark中读取的JSON文件每一行应为一个json串。
加载json文件
val path = "/opt/module/spark-local/people.json"
val peopleDF = spark.read.json(path)
创建临时表
peopleDF.createOrReplaceTempView("people")
数据查询
val resDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
CSV 数据
CSV 文件的读取方法,通常用于简单的数据导入。
Spark SQL 可以配置 CSV 文件的列表信息,读取 CSV 文件,CSV 文件的第一行设置为
数据列。
spark.read.format("csv").option("sep",";").option("inferSchema","true")
.option("header", "true").load("data/user.csv")
MySQL 数据操作
连接与加载
通过 JDBC 连接 MySQL 数据库并加载数据的方法。
强调:驱动版本与 MySQL 版本匹配的重要性。
介绍了三种加载数据的方式:使用 option 参数逐个设置连接信息。使用 options 参数在 URL 中融合连接信息。使用 spark.read.jdbc 方法直接传入 JDBC 参数。
写入数据
通过 JDBC 将数据写入 MySQL 数据库的方法。
举例说明了如何创建 RDD 并将其转换为 DataFrame 进行写入操作。
强调了 save mode 在写入操作中的应用。
1) 导入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
MySQL8 <version>8.0.11</version>
2) 读取数据
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SQL")
val spark:SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
//通用的load方式读取
spark.read.format("jdbc")
.option("url","jdbc:mysql://localhost:3306/system")
.option("driver","com.mysql.jdbc.Driver")//com.mysql.cj.jdbc.Driver
.option("user","root")
.option("password","123456")
.option("dbtable","user")
.load().show()
spark.stop()
//通用的load方法的另一种形式
spark.read.format("jdbc")
.options(
Map("url"->"jdbc:mysql://localhost:3306/system?user=root&password=123456","dbtable"->"user","driver"->"com.mysql.jdbc.Driver"))
.load().show()
//通过JDBC
val pros :Properties = new Properties()
pros.setProperty("user","root")
pros.setProperty("password","123456")
val df :DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/system","user",pros)
df.show()
3) 写入数据
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SQL")
val spark:SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
val rdd: RDD[Stu] = spark.sparkContext.makeRDD(List(Stu("lisi", 20),
Stu("zs", 30)))
val ds:Dataset[Stu] = rdd.toDS()
ds.write.format("jdbc")
.option("url","jdbc:mysql://localhost:3306/system")
.option("driver","com.mysql.jdbc.Driver")
.option("user","root")
.option("password","123456")
.option("dbtable","user2")
.mode(SaveMode.Append)
.save()
spark.stop()Spark-SQL连接Hive
连接方式:内嵌Hive、外部Hive、Spark-SQL CLI、Spark beeline 以及代码操作。
内嵌HIVE:在生产环境中几乎不使用内嵌Hive模式。
外部HIVE:需要与虚拟机中的Hive相连,需下载并配置PS ML、CORE杠set SML、HDFS等文件,并修改配置文件以指向虚拟机的Have。
在虚拟机中下载以下配置文件

如果想在spark-shell中连接外部已经部署好的 Hive,需要通过以下几个步骤:
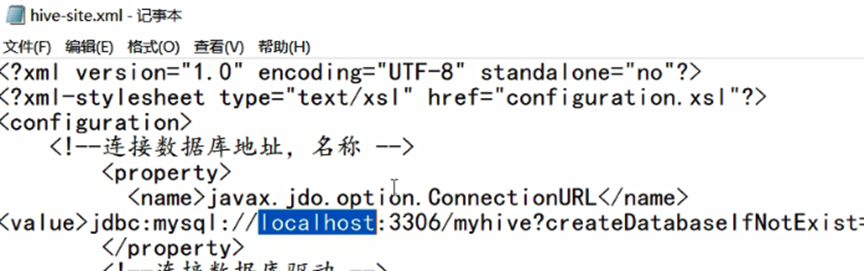
Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下,并将url中的localhost改为node01

驱动放置:MySQL驱动 copy 需要放到 jars/目录下

把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
重启 spark-shell
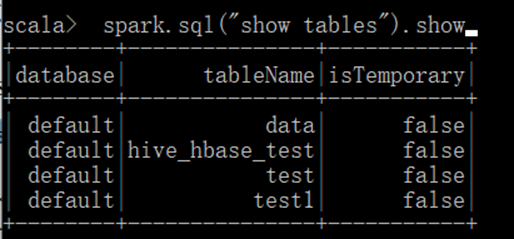
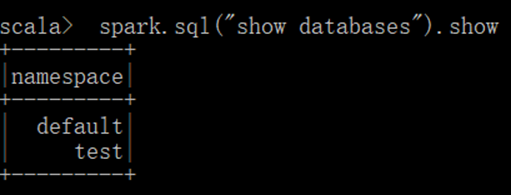
运行Spark-SQL CLI
Spark SQL CLI 可以很方便的在本地运行 Hive 元数据服务以及从命令行执行查询任务。在 Spark 目录下执行如下命令启动 Spark SQL CLI,直接执行 SQL 语句,类似于 Hive 窗口。
操作步骤:
- 将mysql的驱动放入jars/当中;
- 将hive-site.xml文件放入conf/当中;
- 运行bin/目录下的spark-sql.cmd 或者打开cmd,在
D:\spark\spark-3.0.0-bin-hadoop3.2\bin当中直接运行spark-sql

可以直接运行SQL语句,如下所示:
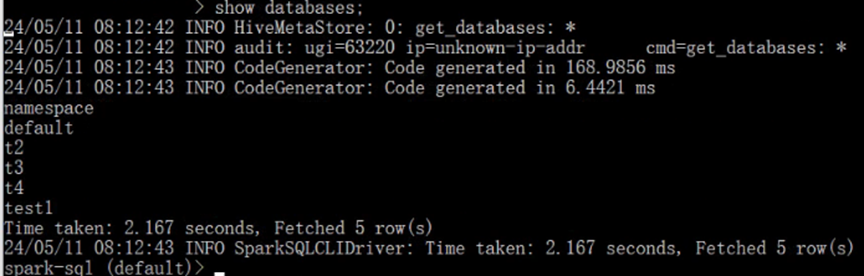
运行Spark-SQL CLI 的使用:
通过spark-sql. cmd运行,可以直接输入MySQL语句,不需要SQL括号和双引号。
驱动和配置文件的放置位置与外部Hive相同。
导入依赖:需要导入与Spark版本一致的依赖包(如3.0.0版本),并与Hive版本保持一致。
虚拟机运行:强调所有操作需要在虚拟机运行的情况下进行,除非使用IDEA。
代码实现:导入必要的包。创建配置对象和SQL对象,输入SQL语句以展示数据库和数据表。