TL;DR
- 场景:静态资源与文件业务从单机/独服走向高并发与海量存储,需要清晰的演进路径与落地清单。
- 结论:按"单机 → 独立文件服务器 → 分布式文件系统(FastDFS 等)"分层取舍,先解耦再扩展,聚焦可运维性与成本。
- 产出:一份 2025 年可执行的版本基线矩阵 + 常见故障速查卡,辅助上线与排障。

为什么要有分布式系统
单机时代
优点
-
文件访问便利性
- 项目可以直接通过相对路径或绝对路径引用文件,如
<img src="images/logo.png"> - 无需网络请求或额外的文件服务器配置
- 开发调试时可以直接在IDE中打开和编辑文件
- 项目可以直接通过相对路径或绝对路径引用文件,如
-
实现简单性
- 不需要复杂的架构设计,适合小型网站或个人项目
- 示例:个人博客可以直接将所有HTML、CSS和图片放在同一个目录下
- 不需要考虑CDN、缓存策略等技术问题
-
文件管理直接
- 修改后立即生效,无需部署流程
- 可以通过操作系统自带的文件管理器直接操作
- 适合快速原型开发
缺点
-
代码耦合问题
- 随着项目规模扩大,文件数量可能达到数百个
- 缺乏有效的组织方式,容易出现
images/2020/01/01/photo.jpg这样的深层嵌套 - 不同模块的资源文件混杂存放,难以管理
-
性能瓶颈
- 当访问量增加时,服务器需要同时处理动态请求和静态文件请求
- 示例:一个100KB的图片被1000个用户访问,就会产生100MB的流量
- 静态文件请求会占用宝贵的服务器带宽和I/O资源
-
扩展性限制
- 无法实现分布式部署,所有流量都集中到单一服务器
- 不支持CDN加速,异地用户访问速度较慢
- 缺乏缓存机制,每次访问都需要从磁盘读取
-
开发维护困难
- 团队协作时容易出现文件冲突
- 没有版本控制功能,误删文件难以恢复
- 无法实现按需加载,即使只访问一个页面也要加载所有资源
这些局限性促使了后续静态资源托管方案的发展,如CDN、对象存储等技术的出现。
独立文件服务器
优势
-
业务专注性
Web和APP服务器无需承担静态资源处理任务,可以专注于动态内容的处理和业务逻辑执行,提高整体系统响应速度。例如电商系统中,商品图片、详情页视频等静态资源完全交由文件服务器处理。
-
独立架构优势
- 扩展灵活:可根据存储需求单独扩容硬盘或增加服务器节点
- 容灾能力强:可采用RAID、分布式存储等技术实现数据冗余
- 迁移便捷:静态资源与业务系统解耦,可独立进行服务器迁移
-
性能优化空间大
- 支持完善的缓存策略:可配置Cache-Control、ETag等HTTP头,配合Nginx等实现代理缓存
- 负载均衡:可通过LVS、Nginx实现多台文件服务器的负载均衡
- CDN友好:静态资源URL规范统一,可无缝对接各类CDN服务
-
运维便利性
统一管理所有静态资源,包括图片、视频、文档等,便于实施统一的备份策略、访问控制和安全策略。
劣势
-
单机性能瓶颈
- I/O吞吐量受限于单台服务器的硬件配置
- 当访问量剧增时,容易出现磁盘I/O瓶颈
- 示例:突发性热点文件访问可能导致服务器响应延迟
-
扩展局限
- 垂直扩展成本高:需要不断提升单机配置(CPU、内存、磁盘阵列)
- 相比分布式存储系统,扩展性存在天花板
-
容灾挑战
- 单点故障风险:虽然可通过RAID等技术缓解,但仍存在整个服务器宕机的风险
- 备份恢复耗时:大容量存储的全量备份和恢复需要较长时间
-
管理复杂度
需要额外维护一套文件存储系统,增加了运维成本和系统复杂度。
适用场景
特别适合中小型Web应用、企业文档管理系统、图片/视频分享平台等以静态资源为主的业务场景。当业务规模扩大到一定程度时,建议考虑迁移至分布式文件存储系统(如FastDFS、HDFS等)。
分布式文件系统
优势
-
强大的扩展能力
- 这是分布式系统最突出的特点
- 通过横向扩展可以轻松应对数据量增长
- 支持PB级甚至EB级数据存储
典型应用场景:云存储服务(如阿里云OSS)可根据用户需求动态扩容
-
高可用性
- 系统可用性:采用多节点冗余设计,单点故障不影响整体运行
- 数据一致性:通过副本机制(如HDFS默认3副本)确保数据安全
案例:Google文件系统(GFS)通过数据分片和副本实现99.9%可用性
-
弹性存储
- 支持在线扩容/缩容,无需停机维护
- 可动态调整存储资源池配置
- 自动化负载均衡机制
实现方式:Ceph通过CRUSH算法实现存储资源的动态调配
劣势
-
系统复杂度高
- 需要部署多台服务器组成集群
- 涉及网络通信、数据同步等复杂机制
- 维护成本较高,需专业运维团队
例如:一个最小可用的Hadoop集群需要至少5个节点
-
硬件要求较高
- 需要配置专用网络设备(如万兆网卡)
- 存储节点建议使用企业级SSD
- 需考虑机房环境(电力、散热等)
典型配置:每个数据节点建议32GB内存+12块硬盘
分布式存储解决方案对比
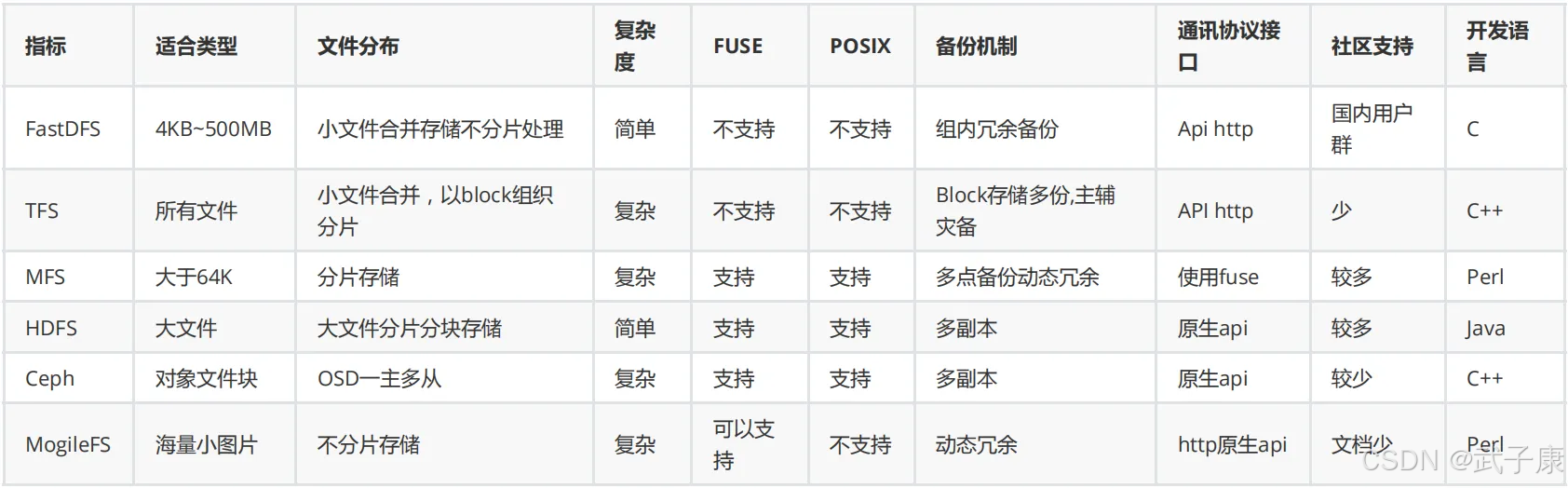
FastDFS
基本介绍
FastDFS(Fast Distributed File System)是一款开源的分布式文件存储系统,采用C语言开发,具有轻量级、高性能的特点。该系统主要提供文件存储、文件同步和文件访问(上传/下载)等核心功能,专门针对大容量存储和负载均衡场景进行了优化设计。
主要特点
-
分布式架构:
- 采用Tracker Server和Storage Server的双层架构
- 支持水平扩展,可轻松扩容存储节点
- 内置负载均衡机制,自动分配存储节点
-
高性能设计:
- 单节点支持高达1000 QPS
- 文件定位速度极快,通过两级目录实现快速访问
- 采用内存索引,提高文件检索效率
-
高可用性:
- 支持多副本存储(默认3副本)
- 自动同步机制保证数据一致性
- 节点故障自动检测和恢复
-
应用场景:
- 相册类网站:支持海量图片存储和管理
- 视频网站:适合短视频、教学视频等内容的存储
- 电商平台:商品图片、详情页资源存储
- 云存储服务:提供稳定可靠的文件存储基础
系统架构
FastDFS由两个主要组件构成:
- Tracker Server:负责调度和负载均衡,管理Storage Server的状态信息
- Storage Server:负责文件存储,包含文件上传、下载和同步功能
优势对比
相比传统文件存储方案,FastDFS具有:
- 更高的存储效率(文件按分组存储)
- 更可靠的数据保护(多副本机制)
- 更简单的扩容方式(支持在线扩容)
- 更低的管理成本(自动化程度高)
系统采用模块化设计,用户可根据实际需求灵活配置存储策略,特别适合日均访问量百万级以上的文件存储场景。
项目特性
分布式存储架构
● 采用分组存储模式,将存储节点划分为多个组,每个组内的存储服务器是对等的关系,没有单点故障风险。这种设计既保持了存储系统的灵活性,又保证了高可用性。例如可以设置3个存储组,每个组包含5台服务器,实现负载均衡和数据冗余。
文件存储机制
● 采用直接文件存储方式,上传的文件与OSS文件系统保持1:1对应关系,不进行分块处理。这种方式简化了文件管理流程,提高了存取效率。例如上传一个10MB的图片文件,在存储系统中就是以完整文件形式保存。
● 文件标识系统采用FastDFS自动生成的文件ID作为唯一访问凭证,不需要额外的name server服务。生成的ID格式通常为:group1/M00/00/01/wKgBZFn5X1iAdtR5AAABg5bdaE1234.jpg,包含分组和路径信息。
系统集成能力
● 提供与主流Web服务器的深度集成方案:
- Apache模块:mod_fastdfs_module
- Nginx模块:ngx_http_fastdfs_module
这些模块可以实现文件的高效代理和缓存,支持动静分离部署方案。
文件存储优化
● 针对不同规模文件的优化处理:
- 小文件(<1MB)采用合并存储策略,减少磁盘IO
- 中等文件(1MB-100MB)采用直接存储
- 提供海量小文件存储方案,实测可支持千万级小文件存储
● 磁盘管理特性:
- 支持多磁盘配置,可设置数据盘和日志盘分离
- 单磁盘损坏时可通过其他磁盘数据恢复
- 采用智能空间回收机制,自动清理过期文件
高级功能
● 重复文件检测:
- 通过SHA-1校验机制识别重复文件
- 系统内相同内容文件只保存一份
- 可节省30%-50%存储空间(视重复率而定)
● 弹性扩展能力:
- 支持在线添加存储组和存储节点
- 扩容过程不影响现有服务
- 支持主从文件同步,确保数据可靠性
性能优化
● 网络通信层采用libevent事件驱动框架(2.0版本):
- 支持10K+并发连接
- 吞吐量提升40%以上
- 响应时间降低30%
● 下载功能增强:
- 支持多线程并行下载(默认4线程)
- 断点续传功能支持:
- 记录已下载字节位置
- 支持HTTP Range请求
- 自动校验文件完整性
项目架构
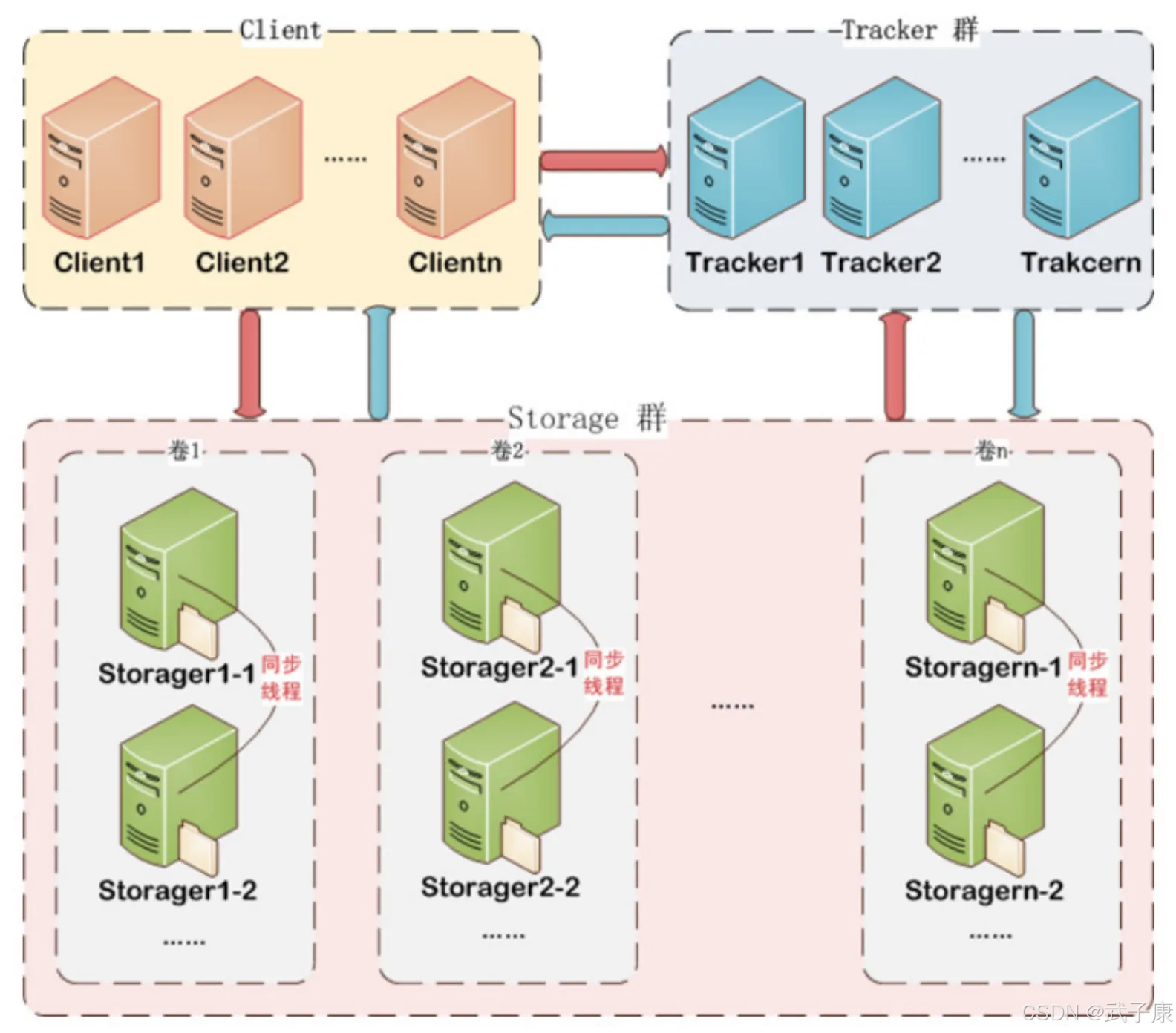
FastDFS 由客户端(Client)、跟踪服务器(Tracker Server)和存储服务器(Storage Server)构成。
客户端
Client 是 FastDFS 架构中的请求发起方,主要负责与追踪服务器(Tracker)和存储节点(Storage)进行交互。客户端通过专有 API 接口(如 fdfs_upload_file)发起文件上传、下载或删除请求,底层基于 TCP/IP 协议与服务器通信。具体流程如下:
- 文件上传:客户端首先连接 Tracker Server 获取可用的 Storage 节点地址
- 文件下载:通过文件 ID 向 Tracker 查询文件所在的 Storage 位置
- 典型应用场景 :
- Web 应用通过客户端 SDK 实现用户头像上传
- 移动 APP 使用断点续传功能下载大文件
追踪器
Tracker Server 是 FastDFS 的核心调度组件,主要承担以下职责:
- 负载均衡 :
- 基于存储节点的磁盘剩余空间(默认策略)或轮询算法选择目标 Storage
- 示例:当上传 100MB 文件时,Tracker 会自动选择剩余空间大于 500MB 的节点
- 服务发现 :
- 维护 Storage 节点的心跳检测,实时更新在线状态表
- 支持多 Tracker 部署(推荐奇数台)避免单点故障
- 协议支持 :
- 使用自定义二进制协议与客户端/存储节点通信
- 默认监听端口为 22122
存储节点
Storage Server 是实际存储文件的节点,具有以下关键特性:
- 文件存储机制 :
-
直接使用操作系统文件系统(如 ext4)管理文件,目录结构示例:
/data/fastdfs/storage/data/00/00/CgABcWB9dR-AAbQyAAAGZ7ZQq7M739.txt
-
- 文件被拆分为两部分存储:
- 元数据(Meta Data)
- 实际文件内容
- 动态扩展能力 :
- 支持横向扩展,新增节点只需在 Tracker 注册即可加入集群
- 在线移除节点时,Tracker 会自动将请求路由到其他可用节点
- 高可用设计 :
- 通过组(Group)实现冗余存储,每组包含多台 Storage
- 默认采用异步复制机制保证数据一致性
- 服务端口 :
- 默认监听 23000 端口接收客户端请求
运维提示:Storage 节点建议配置 RAID 或 SSD 存储以提高 IOPS,单节点支持存储文件数上限约 2.5 亿个(与 inode 数量相关)。
错误速查
| 症状 | 根因 | 定位方法 | 修复措施 |
|---|---|---|---|
| 下载 404 / file not exist | group/路径不一致或跨组访问 | fdfs_file_info <fileId>、Tracker/Storage 日志检查原始 groupX/... fileId |
使用完整 fileId;检查 Nginx rewrite 与跨组访问配置 |
| 上传/下载偶发超时 | 防火墙/端口未放行或网络抖动 | telnet <tracker>:22122、`ss -antp |
grep 22122/23000` |
| Storage 同步落后 | 带宽/IO 吞吐不足或故障节点 | fdfs_monitor /etc/fdfs/client.conf,Storage 日志 SYNC 状态 |
增加副本或扩容;限速大流量写入;修复慢盘/网卡,必要时重建副本 |
| 大量 CLOSE_WAIT | 客户端未正确关闭连接/KeepAlive 配置不当 | ss -s、`ss -antp |
grep CLOSE_WAIT` |
| 小文件写入失败 | Inode 用尽 | df -i |
重建分区提高 inode 数量;合并小文件策略;冷热分层/归档 |
| 断点续传失效 | Range 未透传或模块未启用 | curl -I -H "Range: bytes=0-1" <url> |
启用模块 Range 支持;确认 Accept-Ranges 返回头与缓存链路兼容 |
| 上传大文件 (>4GB) 失败 | client_max_body_size/ulimit/磁盘限额 | Nginx/服务日志、ulimit -n |
提高 client_max_body_size、FD 限制与磁盘配额;采用分片/分段上传 |
| QPS 波动/签名错乱 | 时钟漂移 | chronyc sources、ntpstat |
全集群统一时钟;设置告警阈值≤100ms |
| 读写热点导致压力飙升 | 选址策略单一/分组不均 | Tracker 日志/各组 QPS 监控 | 调整写入分配策略(空间/轮询/自定义);热点数据前置 CDN/缓存 |
| CPU 飙高伴随高磁盘 IO | 未开启零拷贝/缓存配置不当 | iostat、pidstat、Nginx 配置检查 |
启用 sendfile/aio/open_file_cache;合理设置限速与并发窗口 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接