事情是这样的,因为昨天发现我用的ubuntu16.04官方不维护了,以及之前就觉得不是很好用,于是升级到了18.04。如图:
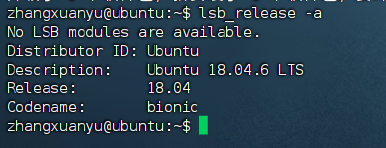
但是!由于为备份升级前忘记关闭服务,上面装好的东西所剩无几。
于是我重装了。。。
如何启动
1. Java 环境(JDK)
你的系统已安装 jdk1.8.0_371,确保环境变量已配置:
bash
export JAVA_HOME=/home/zhangxuanyu/jdk1.8.0_371
export PATH=$JAVA_HOME/bin:$PATH验证:
bash
java -version
结果:
zhangxuanyu@ubuntu:~$ java -version
java version "1.8.0_371"2. Apache Tomcat
(1)解压并启动
bash
cd ~
tar -xzf apache-tomcat-8.5.100-linux.tar.gz # 如果未解压
cd apache-tomcat-8.5.100/bin
./startup.sh # 启动(2)验证
bash
curl http://localhost:8080 # 或浏览器访问(3)停止
bash
./shutdown.sh3. ZooKeeper
(1)解压并配置
bash
cd ~
tar -xzf zookeeper-3.4.14.tar.gz
cd zookeeper-3.4.14/conf
cp zoo_sample.cfg zoo.cfg # 创建默认配置(2)启动
bash
cd ../bin
./zkServer.sh start # 启动
结果:
ZooKeeper JMX enabled by default
Using config: /home/zhangxuanyu/zookeeper-3.4.14/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED(3)验证
bash
./zkCli.sh # 连接本地 ZooKeeper(4)停止
bash
./zkServer.sh stop
结果:
ZooKeeper JMX enabled by default
Using config: /home/zhangxuanyu/zookeeper-3.4.14/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED4. Kafka
(1)解压并启动
bash
cd ~
tar -xzf kafka_2.12-3.3.2.tgz
#先启动zookeeper
cd kafka_2.12-3.3.2
bin/kafka-server-start.sh config/server.properties(2)验证
bash
ps aux | grep kafka #检查进程(3)停止
bash
bin/kafka-server-stop.sh
bin/zookeeper-server-stop.sh5. Hadoop
以下是 Ubuntu 18.04 上安装 Hadoop 3.3.5 的详细步骤(基于已有的 hadoop-3.3.5.tar.gz 安装包):
1. 环境准备
安装 Java
Hadoop 依赖 Java 8/11(推荐 OpenJDK 8):
bash
sudo apt update
sudo apt install openjdk-8-jdk -y
# 验证安装
java -version # 应显示 "openjdk version 1.8.0_xxx"配置 SSH 免密登录
Hadoop 本地模式需要 SSH 无密码访问:
bash
sudo apt install openssh-server -y
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa # 生成密钥
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
# 测试免密登录
ssh localhost # 首次需输入yes,之后应直接进入
exit # 退出SSH会话终极测试是否ok:
bash
zhangxuanyu@ubuntu:~$ ssh localhost "echo 'SSH免密登录成功!'"结果:
bash
ssh localhost "echo 'SSH免密登录成功'"
SSH免密登录成功2. 安装 Hadoop
解压安装包
bash
cd ~
tar -xzvf hadoop-3.3.5.tar.gz # 解压到当前目录
mv hadoop-3.3.5 hadoop # 重命名(可选)配置环境变量
编辑 ~/.bashrc:
bash
nano ~/.bashrc在文件末尾添加:
bash
# Java Environment
export JAVA_HOME=/usr/lib/jnm/jdk1.8.0_371
export PATH=$JAVA_HOME/bin:$PATH
# Hadoop Environment
export HADOOP_HOME=/home/zhangxuanyu/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin激活配置:
bash
source ~/.bashrc检查是否生效:
bash
zhangxuanyu@ubuntu:~$ echo $HADOOP_HOME
结果:
/home/zhangxuanyu/hadoop
bash
zhangxuanyu@ubuntu:~$ hadoop version
结果:
Hadoop 3.3.53. 配置 Hadoop
修改核心配置文件
进入配置目录:
bash
cd ~/hadoop/etc/hadoop1. hadoop-env.sh
设置 Java 路径:
bash
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64" >> hadoop-env.sh2. core-site.xml
配置 HDFS 地址和临时目录:
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-tmp</value>
</property>
</configuration>检查:
bash
zhangxuanyu@ubuntu:~/hadoop/etc/hadoop$ cat ~/hadoop/etc/hadoop/core-site.xml | grep -A 1 "hadoop.tmp.dir"
结果:
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-tmp</value>3. hdfs-site.xml
配置副本数(单机模式设为1):
xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/tmp/hadoop/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/tmp/hadoop/datanode</value>
</property>
</configuration>检查:
bash
zhangxuanyu@ubuntu:~/hadoop/etc/hadoop$ hdfs getconf -confKey dfs.replication
1
zhangxuanyu@ubuntu:~/hadoop/etc/hadoop$ hdfs getconf -confKey dfs.namenode.name.dir
/tmp/hadoop/namenode
zhangxuanyu@ubuntu:~/hadoop/etc/hadoop$ hdfs getconf -confKey dfs.datanode.data.dir
/tmp/hadoop/datanode4. mapred-site.xml
配置使用 YARN:
xml
<configuration>
<!-- 核心配置:声明使用YARN框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 临时目录设置(避免使用默认/tmp) -->
<property>
<name>mapreduce.cluster.temp.dir</name>
<value>/opt/hadoop/tmp/mapred</value>
</property>
<!-- 内存资源限制(根据机器配置调整) -->
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value> <!-- 每个Map任务的内存 -->
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value> <!-- 每个Reduce任务的内存 -->
</property>
<!-- JVM堆内存限制(需小于上述memory.mb) -->
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx768m</value> <!-- Map任务的JVM堆内存 -->
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx1536m</value> <!-- Reduce任务的JVM堆内存 -->
</property>
<!-- 任务重试策略 -->
<property>
<name>mapreduce.map.maxattempts</name>
<value>4</value> <!-- Map任务最大重试次数 -->
</property>
<property>
<name>mapreduce.reduce.maxattempts</name>
<value>4</value> <!-- Reduce任务最大重试次数 -->
</property>
<!-- 数据本地化优化 -->
<property>
<name>mapreduce.tasktracker.prefetch.local</name>
<value>true</value> <!-- 优先在数据所在节点执行任务 -->
</property>
</configuration>5. yarn-site.xml
xml
<configuration>
<!-- 你已存在的配置 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 新增关键配置 ▼▼▼ -->
<!-- 1. 指定Shuffle处理类 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 2. 定义ResourceManager主机 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ubuntu</value> <!-- 替换为你的主节点主机名 -->
</property>
<!-- 3. 内存资源池配置 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value> <!-- 建议=物理内存*0.8 -->
</property>
<!-- 4. 关闭虚拟内存检查(避免任务被误杀) -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 5. 启用日志聚合 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>4. 初始化并启动 Hadoop
格式化 HDFS
bash
hdfs namenode -format # 仅首次运行需要成功的标准:
2025-04-13 13:40:23,513 INFO common.Storage: Storage directory /tmp/hadoop/namenode has been successfully formatted.
启动 HDFS 和 YARN
bash
start-dfs.sh # 启动HDFS
start-yarn.sh # 启动YARN验证服务
-
检查进程:
bashjps
hadoop 启动成功的标志:
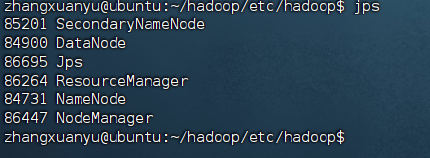
85201 SecondaryNameNode
84900 DataNode
86695 Jps
86264 ResourceManager
84731 NameNode
86447 NodeManager
-
访问 Web UI:
- HDFS: http://localhost:9870
- YARN: http://localhost:8088
5. 运行测试任务
创建 HDFS 目录
bash
hdfs dfs -mkdir /input
hdfs dfs -put $HADOOP_HOME/etc/hadoop/*.xml /input # 上传测试文件运行 MapReduce 示例
bash
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar grep /input /output 'dfs[a-z.]+'查看结果
bash
hdfs dfs -cat /output/*6. 停止 Hadoop
bash
stop-yarn.sh
stop-dfs.sh常见问题解决
-
端口冲突:
-
检查
9000、9870、8088端口是否被占用:bashsudo netstat -tulnp | grep -E '9000|9870|8088'
-
-
权限问题:
-
如果遇到权限错误,尝试:
bashsudo chown -R $USER:$USER /tmp/hadoop*
-
-
日志排查:
-
查看日志文件:
bashtail -n 100 ~/hadoop/logs/*.log
-
6.安装MySQL
在 Ubuntu 18.04 上安装 MySQL 的完整步骤如下(适用于 MySQL 5.7,Ubuntu 18.04 默认版本):
方法 1:使用 APT 安装(推荐)
1. 更新软件包列表
bash
sudo apt update2. 安装 MySQL Server
sudo apt install mysql-server -y- 这会安装 MySQL 5.7(Ubuntu 18.04 默认版本)。
3. 运行安全配置向导
sudo mysql_secure_installation- 按提示操作
- 设置 root 密码(我设置的My@Secure123)
- 移除匿名用户
- 禁止远程 root 登录
- 删除测试数据库
- 立即刷新权限
4. 检查 MySQL 状态
bash
sudo systemctl status mysql- 如果显示
active (running),说明安装成功。
进入:
bash
sudo mysql -u root -p输入密码后:
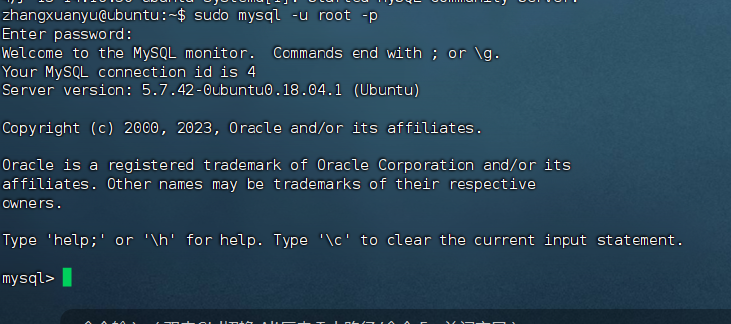
为了后面的Maxwell,需要修改mysql配置
bash
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf在mysqld区块末尾下面加:
bash
server_id = 12345
log_bin = /var/log/mysql/mysql-bin.log
binlog_format = ROW
binlog_row_image = FULL
expire_logs_days = 10
max_binlog_size = 100M再重启Mysql服务:
bash
sudo systemctl restart mysql7. Maxwell(MySQL Binlog 监听)
(1)解压并配置
bash
cd ~
tar -xzf maxwell-1.29.2.tar.gz
cd maxwell-1.29.2需修改 config.properties:
bash
nano config.properties修改为:
properties
producer=kafka
kafka.bootstrap.servers=localhost:9092
# mysql login info
host=localhost
user=root #mysql用户
password=My@Secure123 #mysql密码(2)启动
bash
bin/maxwell --config config.properties &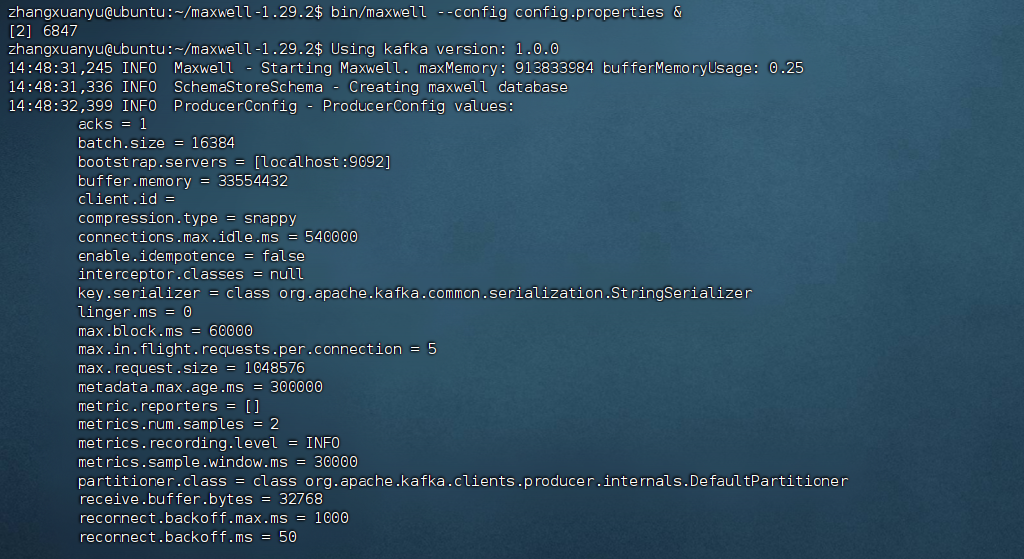
(3)验证
bash
tail -f logs/maxwell.log # 查看日志总结
| 软件 | 启动命令 | 停止命令 |
|---|---|---|
| Tomcat | ./startup.sh |
./shutdown.sh |
| Nginx | ~/nginx/sbin/nginx |
~/nginx/sbin/nginx -s stop |
| ZooKeeper | ./zkServer.sh start |
./zkServer.sh stop |
| Kafka | ./kafka-server-start.sh ... |
./kafka-server-stop.sh |
| Hadoop | sbin/start-dfs.sh + start-yarn.sh |
sbin/stop-dfs.sh + stop-yarn.sh |
| Maxwell | bin/maxwell --config ... |
kill 对应进程 |