1. 工具介绍
该工具软件是基于 OpenAI Whisper 的模型编写的,使用 Python 语言开发,然后通过 pyinstaller 打包成 exe 可执行程序,方便用户使用,之间双击就可以启动。点击这里,跳转到工具产品页面
该工具有以下功能:
- 支持对指定的目录下的全部音视频文件进行转写操作,无需手动一个个文件处理。适用于需要对大量音视频进行转写的场景。
- 该工具可以把任意支持的语种转写为英文输出。
- 该工具解决了OpenAI Whisper 对普通话转写偶尔产生繁体中文的问题。
- 该工具可以控制输出文件中每行最多显示多少个字符。
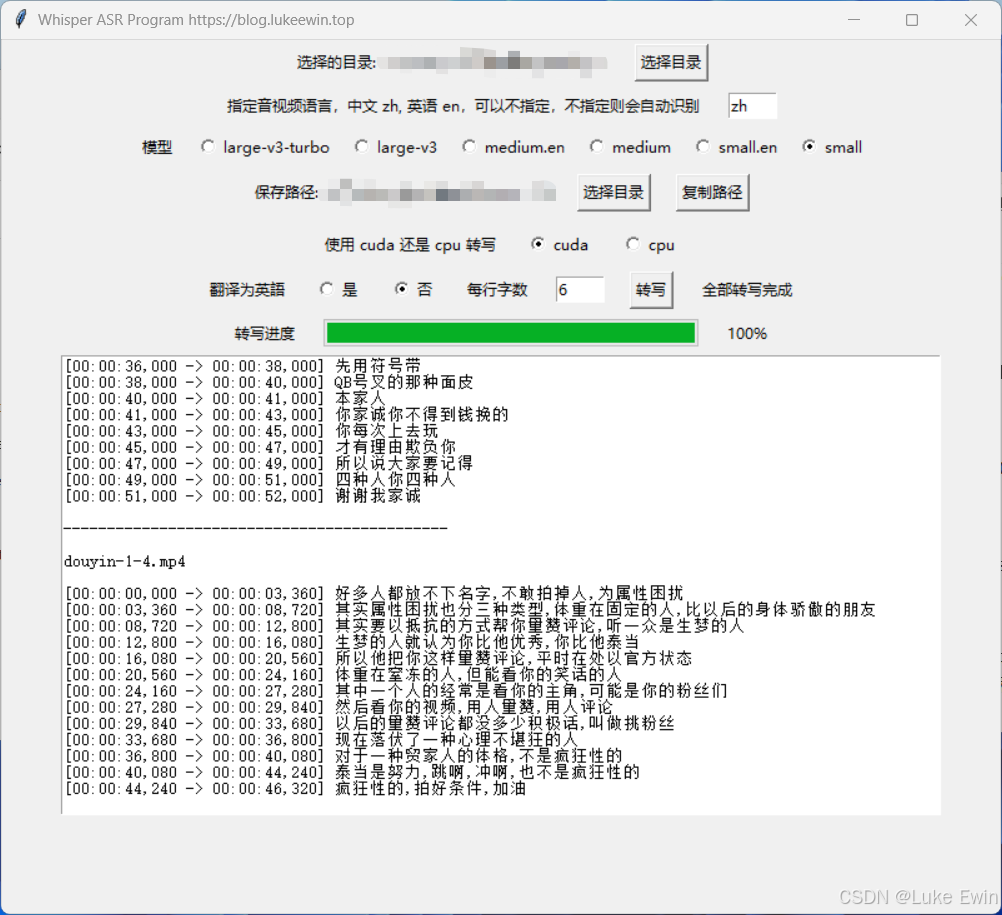
2. 模型文件下载
模型下载地址:
large-v3-turbo模型:https://openaipublic.azureedge.net/main/whisper/models/aff26ae408abcba5fbf8813c21e62b0941638c5f6eebfb145be0c9839262a19a/large-v3-turbo.pt
3. 使用说明
-
双击 app.exe 运行程序,有点电脑中没有开启显示文件后缀,显示的是 app
-
选择需要转写的音视频所在的目录
-
可以指定要转写的音视频的语言,如果目录中同时包含多种语言,那么不要指定语言,如果是中文指定为Chinese或者zh,如果是英语,则指定为English或者en,其它语言可以看下面的支持语种信息
-
选择模型,small,small.en,medium,medium.en,large-v3-turbo,large-v3 占用的显存或者内存依次增加,转写的速度依次变慢,准确率依次增加,通常使用small模型需要4GB的显存显卡,并且只支持英伟达显卡,如果是AMD或者英特尔显卡,那么会使用CPU运行,CPU运行速度会比CUDA慢很多。注意:其中以en结尾的模型是英语专用模型,其它模型是多语种模型,也就是如果你输入的音视频是讲英语的,那么你可以选择en结尾的模型或非en结尾的模型都可以,但是如果你输入的音视频是非英语,而你模型选择的却是en结尾的模型,那么会导致转写出来的内容不正确,如果你输入的音视频是部分讲英语,不是整个音视频都是讲英语,那么你也不要选择en结尾的模型
-
选择转写生成纯文本txt和字幕文件srt的目录
-
选择使用cuda还是cpu来运行,如果有英伟达显卡,默认使用cuda
-
是否翻译为英语,支持所有支持的语种翻译为英文输出
-
控制保存到txt和srt文件每行最大的字数
-
开始转写
-
转写进度,注意:如果你输入的音视频很长,比如几个小时的音视频,那么需要等待的时间比较长,需要耐心等待,可以看cmd窗口是否卡住,如果你鼠标不小心点击了cmd窗口,那么会暂停,你需要在cmd窗口中按下回车键,就会继续转写
4. 支持的语种
shell
Afrikaans,Albanian,Amharic,Arabic,Armenian,Assamese,Azerbaijani,Bashkir,Basque,Belarusian,Bengali,Bosnian,Breton,Bulgarian,Burmese,Cantonese,Castilian,Catalan,Chinese,Croatian,Czech,Danish,Dutch,English,Estonian,Faroese,Finnish,Flemish,French,Galician,Georgian,German,Greek,Gujarati,Haitian,Haitian Creole,Hausa,Hawaiian,Hebrew,Hindi,Hungarian,Icelandic,Indonesian,Italian,Japanese,Javanese,Kannada,Kazakh,Khmer,Korean,Lao,Latin,Latvian,Letzeburgesch,Lingala,Lithuanian,Luxembourgish,Macedonian,Malagasy,Malay,Malayalam,Maltese,Mandarin,Maori,Marathi,Moldavian,Moldovan,Mongolian,Myanmar,Nepali,Norwegian,Nynorsk,Occitan,Panjabi,Pashto,Persian,Polish,Portuguese,Punjabi,Pushto,Romanian,Russian,Sanskrit,Serbian,Shona,Sindhi,Sinhala,Sinhalese,Slovak,Slovenian,Somali,Spanish,Sundanese,Swahili,Swedish,Tagalog,Tajik,Tamil,Tatar,Telugu,Thai,Tibetan,Turkish,Turkmen,Ukrainian,Urdu,Uzbek,Valencian,Vietnamese,Welsh,Yiddish,Yoruba