🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 ------ 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
- [1. 背景介绍](#1. 背景介绍)
- [2. 相关工作](#2. 相关工作)
-
- [2.1. 二维车道检测](#2.1. 二维车道检测)
- [2.2. 三维车道检测](#2.2. 三维车道检测)
- [3. 方法](#3. 方法)
-
- [3.1 模型概述](#3.1 模型概述)
- [3.2 特殊几何下的 PV 到 BEV 投影](#3.2 特殊几何下的 PV 到 BEV 投影)
- [3.3 多关键点估计](#3.3 多关键点估计)
- [3.4 关键点连接预测](#3.4 关键点连接预测)
- [3.5 匹配与损失函数](#3.5 匹配与损失函数)
- [3.6 从图中提取车道线](#3.6 从图中提取车道线)
- [4. 实验](#4. 实验)
-
- [4.1 数据集](#4.1 数据集)
- [4.2 评估指标](#4.2 评估指标)
- [4.3 实现细节](#4.3 实现细节)
- [4.4 消融实验](#4.4 消融实验)
- [4.5 OpenLane 结果](#4.5 OpenLane 结果)
- [4.6 Apollo 结果](#4.6 Apollo 结果)
- [4.7 跨数据集评估](#4.7 跨数据集评估)
- [5. 结论](#5. 结论)
1. 背景介绍
Öztürk H İ, Kalfaoğlu M E, Kilinc O. GLane3D: Detecting Lanes with Graph of 3D KeypointsJ. arXiv preprint arXiv:2503.23882, 2025.
🚀以上学术论文翻译由ChatGPT辅助。
在三维空间中实现准确且高效的车道线检测,对于自动驾驶系统至关重要,其中鲁棒的泛化能力是 3D 车道检测算法的首要要求。
考虑到全球车道结构的巨大差异,要实现高度的泛化能力尤其具有挑战性,因为算法必须能够准确识别各种不同的车道线模式。
传统的自顶向下方法严重依赖于从训练数据集中学习车道特征,往往难以应对具有未见属性的车道结构。
为了解决这一泛化能力的局限,我们提出了一种方法,首先检测车道的关键点,然后预测它们之间的顺序连接,以构建完整的三维车道线。
每个关键点对于维持车道连续性都是关键的,我们通过允许相邻网格使用偏移机制预测同一个关键点,从而对每个关键点生成多个候选提议。
我们引入 PointNMS 来去除重复的候选关键点,减少 BEV(鸟瞰图)图中的冗余,从而降低连接预测带来的计算开销。
我们的模型在 Apollo 和 OpenLane 数据集上均超越了之前的最新方法,展现了更高的 F1 分数。
尤其是当使用 OpenLane 数据集训练的模型在 Apollo 数据集上评估时,展示出相比以往方法更强的泛化能力。
稳健的 3D 车道线检测对于自动驾驶中的多种关键功能至关重要,例如车道保持、车道偏离预警和轨迹规划。
然而,车道检测方法在复杂场景下常常表现不佳。尽管部分系统采用了 LiDAR 或多传感器配置,但由于成本效益,纯视觉方案(仅使用摄像头)在车道线检测中越来越受到青睐。
目前的一大挑战在于如何准确检测 3D 车道边界,这对于安全导航至关重要,并为路径规划和车辆控制提供了关键信息。
从历史上看,车道线检测主要依赖于二维方法,包括基于分割的 4, 6, 13, 25, 26, 29, 44, 49, 52,基于锚点的 10, 15, 34, 36, 43, 50,以及基于关键点的方法 9, 12, 32, 41, 45。
为了将这些 2D 检测扩展到 3D 空间,研究者尝试了逆投影的方法;但这种方式由于缺乏深度信息,难以准确表示车道线的真实三维结构。
另一种变通方法 46 是在投影前进行深度估计,但这需要极其精确的深度数据和完美的二维分割结果。
最近,一些端到端的 3D 车道检测方法 2, 5, 22, 28 出现,使用前视摄像头图像作为输入,成为一种有前景的解决方案。
这些方法通常通过逆透视映射(IPM)或 Lift-Splat-Shoot(LSS)方法将透视视角的特征投影到鸟瞰图(BEV)。
另一类方法则将 3D 车道锚点投影到透视图中,预测必要的偏移后再进行重投影。
无论是二维还是三维空间中的车道检测,主要有两种思路:
- 自顶向下的基于实例的方法 2, 16, 22, 28, 37, 50,直接预测完整的车道实例;
- 自底向上的方法,检测每个车道组件(如关键点),随后通过后处理将其组合成完整车道线 32, 41, 42。
将像素分割为车道和背景通常比直接预测复杂参数的整条车道线更容易。
这种差异增强了自底向上方法的泛化能力,使其在面对未见过的场景时依然能检测出车道片段,而自顶向下方法在面对新型车道类型时则可能表现不佳。
但另一方面,自底向上方法在如何将检测到的关键点聚合为连贯车道方面存在挑战。
例如,42 采用基于关键点特征的聚类进行后处理;41 则基于关键点指向公共车道起点的方向来进行分组;而 32 使用迭代的关键点关联逐步构建车道。
为简化关键点在后处理阶段的聚合问题,我们与其他自底向上方法不同地将车道检测形式化为:
- 在预测的有向图中定位关键点,并
- 预测它们之间的顺序连接,
从而可通过最短路径算法在起点和终点关键点之间提取完整车道。
准确检测每个车道关键点至关重要,漏检关键点将导致车道线断裂。为应对这一问题,我们为每个车道上的目标关键点在 d x dx dx 范围内生成多个候选关键点,并施加微小偏移来精确其位置。
引入冗余关键点虽降低了漏检概率,但同时也带来了计算成本的增加。为控制这一权衡,我们引入了 PointNMS 操作,仅保留最强的关键点,消除冗余。
我们的主要贡献如下:
-
我们提出了 GLane3D,一种基于关键点的 3D 车道检测方法。
它通过关键点之间的有向连接预测来实现高效的车道提取。
通过生成多个关键点候选,我们提高了检测召回率。
PointNMS 算法选择最强候选点,减少了歧义和计算开销。
-
使用逆透视映射(IPM)结合自定义的 BEV 位置,在前视图中计算采样点,
替代使用均匀分布的 BEV 位置,减少了自车附近区域的稀疏性,
缓解了远处区域的饱和问题。
-
得益于其创新的设计,GLane3D 展现出极强的泛化能力。
我们在跨数据集测试中验证了这一点:在 OpenLane2 上训练的模型在 Apollo5 上表现良好,
展示了 GLane3D 相比以往方法更强的泛化能力。
-
仅使用摄像头的 GLane3D 方法在 OpenLane2 和 Apollo5 两个数据集上都超过了当前最先进方法,
在 OpenLane 所有测试类别中均表现出色。
GLane3D 在摄像头+激光雷达融合设置下也取得了最高的 F1 得分。
此外,它在帧率(FPS)上也优于其他模型。
2. 相关工作
2.1. 二维车道检测
尽管二维车道检测已经取得了显著进展,但二维检测结果与现实应用中所需的精确三维位置之间,仍存在明显的差距。
二维车道检测方法大致可分为以下四类:
-
基于分割的方法 4, 6, 13, 25, 26, 29, 44, 49, 52:
通过在透视图中分割出车道线区域,然后经过后处理来获得完整车道实例。
-
基于锚点的方法 10, 15, 34, 36, 43, 50:
使用预定义的锚点(如线段锚点)来回归与目标之间的相对偏移量。
另一类锚点方法是基于行的锚点(row-based anchors) 17, 30, 31, 48,按行将像素分类为不同的车道。
-
基于曲线的方法 3, 18, 20, 38--40:
预测多项式参数来拟合车道曲线,利用车道的先验知识来提升预测精度。
-
基于关键点的方法 9, 12, 32, 41, 45:
先估计车道关键点的位置,再将这些点聚合成完整车道线,建模更加灵活。
聚合方式有多种:如使用全局点预测 41,或结合全局和局部预测 45,也有方法根据几何关系预测邻近点 32。
这些方法通常还包含一个额外步骤,如热图提取,以便更有效地匹配关键点。
2.2. 三维车道检测
为了获取精确的三维车道位置信息,三维车道检测方法通常从前视图(Front View, FV)图像中进行估计。
将前视图特征投影到鸟瞰图(Bird's Eye View, BEV)空间,使得三维车道检测成为可能,如 2, 5, 14, 27, 28 所示。
三维车道检测中的投影方式主要分为两类:
-
基于 Lift-Splat-Shoot(LSS)方法 21, 28:
从前视图中直接学习深度估计,部分工作中使用监督深度估计 21, 28。
-
基于逆透视映射(IPM)方法 2, 5, 14:
将前视图投影到 BEV 空间后进行处理。
另外,也有方法无需特征投影,直接从前视图中预测 3D 车道点位置 22, 23,其思想类似于 PETR 19 中的车道和点查询机制。
此外,还有方法将锚点车道线投影到三维空间中,然后回归偏移量,无需进行特征投影 8。
一些方法尝试隐式学习 3D 投影过程,而不是显式的 FV 到 BEV 的转换,但在摄像头位置变化时往往表现不佳。
三维车道信息也可通过结合二维车道预测与密集深度估计获取 46,或通过直接将二维预测投影到三维空间实现 5。
将前视图特征投影到 BEV 空间,使得可以利用已有的二维方法来进行三维车道检测:
-
基于锚点的方法 2, 14, 21:
从锚点车道线回归横向偏移量,以获得目标车道线。
-
基于曲线的方法 1, 11, 27, 28:
直接预测曲线的参数进行拟合,LaneCPP 28 更是引入物理先验来调控学习到的参数。
-
基于关键点的方法 :
BEVLaneDet 42 使用以 BEV 网格中心为锚点的关键点,通过回归目标车道,再结合学习到的嵌入进行关键点分组。
将车道检测视为多点目标检测会限制模型的泛化能力,因为模型可能在遇到未见过的车道布局时表现不佳。
相比之下,关键点方法将车道检测视为局部结构的检测与组装,能有效提升泛化能力。
无论是 2D 还是 3D 空间中的关键点方法,通常都通过以下方式实现聚合:
- 基于聚类的后处理,
- 基于局部几何偏移的预测,
- 或两者结合。
GLane3D 方法在此基础上更进一步:
- 通过估计关键点之间的顺序连接关系,
- 并应用 PointNMS 来去除冗余关键点,
- 以实现高效且结构清晰的车道线组装。
3. 方法
GLane3D 检测三维关键点 k i ∈ K k_i \in K ki∈K,其中 k i = ( x i , y i , z i ) k_i = (x_i, y_i, z_i) ki=(xi,yi,zi), i = 1 , 2 , ... , S i = 1, 2, \dots, S i=1,2,...,S,并预测一个邻接矩阵 A ∈ R S × S A \in \mathbb{R}^{S \times S} A∈RS×S,其中 A i j Aij Aij 表示关键点 k i k_i ki 和 k j k_j kj 之间存在连接的概率。
我们根据由公式 (1) 提取出的有向连接集合 C C C 构建有向图 G G G,其中预测关键点集合 K K K 来自模型输出。
通过这个有向图 G G G,车道实例可以被简单地提取出来。
C = { ( k i , k j ) ∣ A i j > t a } . (1) C = \{(k_i, k_j) \mid Aij > t_a\}. \tag{1} C={(ki,kj)∣Aij>ta}.(1)
预测过程基于将前视图(Frontal View, FV)特征 F F V F_{FV} FFV 投影到鸟瞰图(BEV)空间后的特征图 F B E V ∈ R c × H b × W b F_{BEV} \in \mathbb{R}^{c \times H_b \times W_b} FBEV∈Rc×Hb×Wb,该特征图通过逆透视映射(IPM)从输入图像 I ∈ R 3 × H × W I \in \mathbb{R}^{3 \times H \times W} I∈R3×H×W 提取。
3.1 模型概述
该模型使用锚点 a i , j ∈ R H b × W b × 2 a_{i,j} \in \mathbb{R}^{H_b \times W_b \times 2} ai,j∈RHb×Wb×2,其中 a i , j = ( x i , j , y i , j ) a_{i,j} = (x_{i,j}, y_{i,j}) ai,j=(xi,j,yi,j),每个锚点 a i , j a_{i,j} ai,j 对应特征 f i , j = F B E V i , j f_{i,j} = F_{BEV}i, j fi,j=FBEVi,j,如图 1 所示。
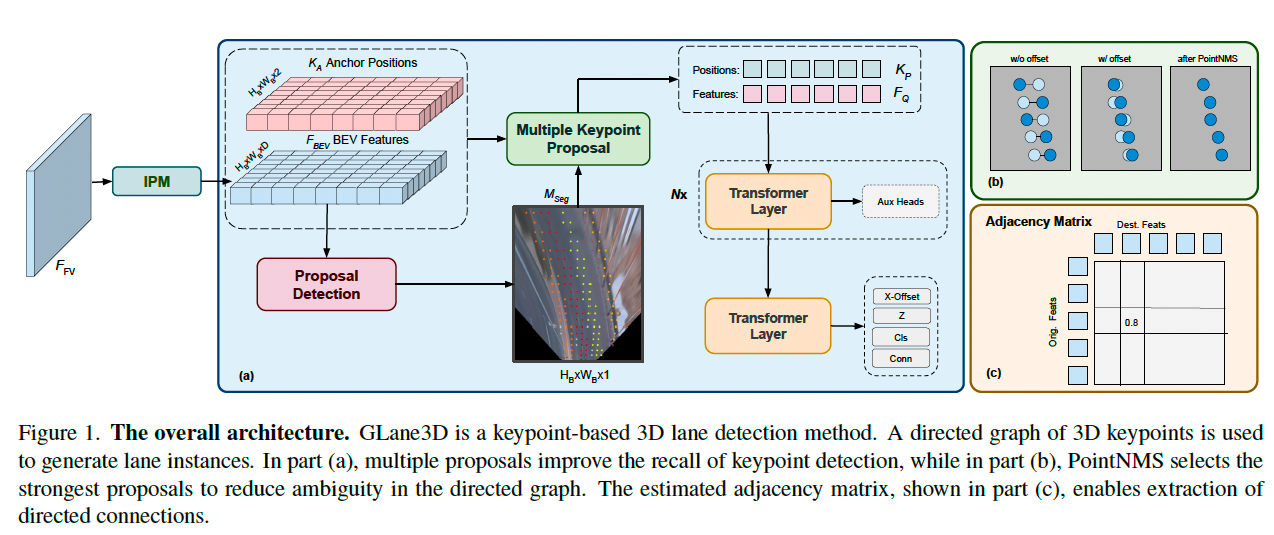
模型初始步骤中预测前景/背景分割图 M s e g ∈ R H b × W b × 1 M_{seg} \in \mathbb{R}^{H_b \times W_b \times 1} Mseg∈RHb×Wb×1。提议检测模块从中选出前 N N N 个得分最高的锚点作为候选关键点集合 K P K_P KP。
在自底向上的方法中,关键点对车道预测至关重要,若缺失某个关键点,可能导致车道线被断裂。
为避免此问题,GLane3D 中的提议检测模块会从锚点中选择多个候选关键点,如图 2a 所示,候选点在目标车道线的左右 d x d_x dx 范围内。
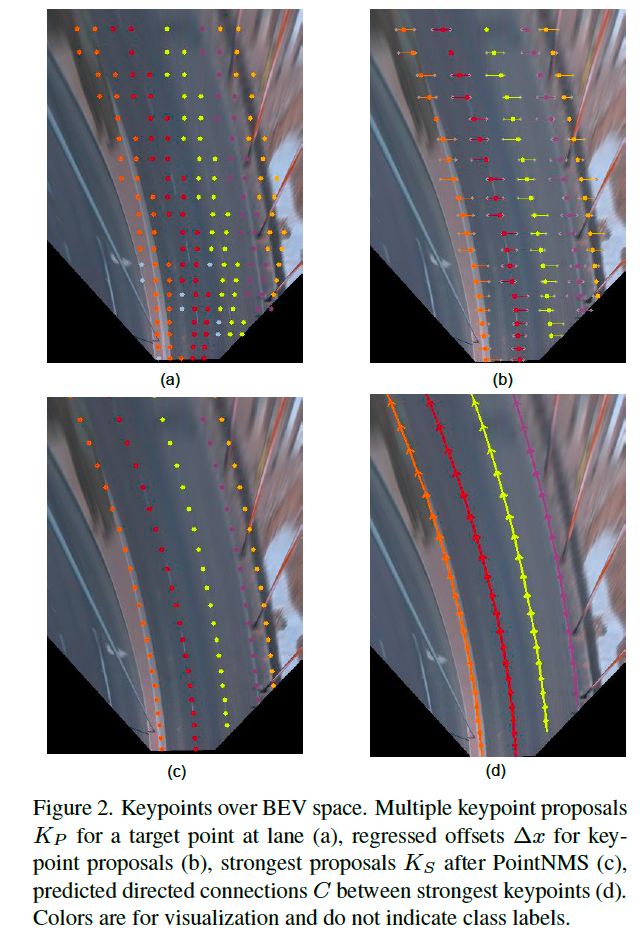
通过预测多个候选点,可显著减少漏检关键点的可能性。这些候选关键点随后会通过预测的横向偏移 Δ x \Delta x Δx 对齐到目标车道线,如图 2b 所示。
由于每个关键点是独立预测的,因此还需额外预测关键点之间的有向连接来形成车道线。在后处理阶段,通过追踪这些连接来提取完整车道。
为减少连接预测的计算开销,使用 PointNMS 操作,从 N N N 个候选点中保留 S S S 个置信度最高的关键点,其他低置信度的被丢弃。
连接头(relation head)在这 S S S 个关键点上运行,并输出邻接矩阵 A A A。
3.2 特殊几何下的 PV 到 BEV 投影
逆透视映射(IPM)将前视图特征 F P V F_{PV} FPV 投影到 BEV 空间,即将 BEV 空间的位置投影回 FV 空间,通过投影矩阵确定对应采样位置。
GLane3D 使用在 BEV 空间中的锚点位置 K A H b × W b × 2 K^{H_b \times W_b \times 2}_A KAHb×Wb×2 来计算其在前视图中的对应位置。
若 BEV 中锚点是等距均匀分布的,则在投影至 FV 时,近距离区域的投影点稀疏,而远处则密集,如图 3a 所示。
为使近距离区域在前视图中具有更密集的点,我们自定义锚点分布方式,使得越靠近 ego 车的区域,其锚点间距越小,且每一行锚点数量固定,得到如图 3c 的效果。
更多几何设计细节详见补充材料。

3.3 多关键点估计
GLane3D 会为车道线上的每个目标关键点预测多个候选点,如图 2a。
将被选中的锚点对应的特征向量组成 F Q F_Q FQ,如下式所示:
F Q = F B E V x i , y i , k i ∈ K P N × 2 . (2) F_Q = F_{BEV}x_i, y_i, \quad k_i \in K^{N \times 2}_P. \tag{2} FQ=FBEVxi,yi,ki∈KPN×2.(2)
这些查询特征 F Q F_Q FQ 被送入 Transformer 块,包含自注意力和交叉注意力层。交叉注意力中的 memory 输入为 F B E V F_{BEV} FBEV。
为提升效率,在交叉注意力中使用 deformable attention 机制。
我们使用 4 个 MLPs 来分别预测:
- 分类得分 S C L S S_{CLS} SCLS
- 横向偏移 Δ x \Delta x Δx
- 高度 z z z
- 连接特征向量 f c f_c fc
每个候选点 k i ∈ K P k_i \in K_P ki∈KP 都会产生以上预测结果。
训练过程中还加入辅助头,对 Transformer 中间层的特征进行额外监督,以增强稳定性。
应用横向偏移 Δ x \Delta x Δx 后,候选点会被对齐至目标关键点,如图 2b。
为了去除冗余且保持高召回率,我们使用 PointNMS 操作:在相距 d x d_x dx 范围内的候选点中,仅保留分类得分最大的点:
max ( s i ) , s i ∈ S C L S \max(s_i), \quad s_i \in S_{CLS} max(si),si∈SCLS
最终得到去重后的关键点集合 K S K_S KS,如图 2c 所示。
3.4 关键点连接预测
我们从邻接矩阵 A A A 中提取关键点之间的有向连接集合 C C C,如公式 (1),用于车道提取。
关键点的位置信息对连接预测至关重要,因此将位置编码 P E PE PE 和特征向量拼接,如下:
p e i = P E ( x i + Δ x , y i ) (3) pe_i = PE(x_i + \Delta x, y_i) \tag{3} pei=PE(xi+Δx,yi)(3)
f c ′ = concat ( p e i , f c ) (4) f'_c = \text{concat}(pe_i, f_c) \tag{4} fc′=concat(pei,fc)(4)
然后对所有特征 F C = ( f c ′ 0 , . . . , f c ′ S ) FC = (f'_c0, ..., f'_cS) FC=(fc′0,...,fc′S) 输入两个 MLP,分别生成:
- 起始点特征 F o r i g ∈ R S × d F_{orig} \in \mathbb{R}^{S \times d} Forig∈RS×d
- 终止点特征 F d e s t ∈ R S × d F_{dest} \in \mathbb{R}^{S \times d} Fdest∈RS×d
我们将 F o r i g F_{orig} Forig reshape 成 F o r i g ′ ∈ R S × 1 × d F'{orig} \in \mathbb{R}^{S \times 1 \times d} Forig′∈RS×1×d, F d e s t F{dest} Fdest reshape 成 F d e s t ′ ∈ R 1 × S × d F'_{dest} \in \mathbb{R}^{1 \times S \times d} Fdest′∈R1×S×d。
两者逐元素乘法后得到形状为 R S × S × d \mathbb{R}^{S \times S \times d} RS×S×d 的张量,随后通过一个线性层和 sigmoid 激活函数得到邻接矩阵 A A A:
C = σ ( F C ( F s r c ′ ⊙ F t g t ′ ) ) (5) C = \sigma(F_C(F'{src} \odot F'{tgt})) \tag{5} C=σ(FC(Fsrc′⊙Ftgt′))(5)
3.5 匹配与损失函数
我们使用 Hungarian 算法将预测关键点与真实关键点进行匹配。
由于不是所有 K P K_P KP 中的点都会参与连接预测,因此需两次应用该算法:
- 第一次用于所有候选关键点 K P K_P KP
- 第二次用于 PointNMS 后的强关键点 K S K_S KS
匹配过程考虑了关键点之间的距离和分类概率的相似度。
我们还设置限制,禁止匹配纵向 y y y 坐标差距过大的点对。
对于 K P K_P KP,我们复制真实关键点 n n n 次以确保匹配充足;而对于去重后的 K S K_S KS,无需复制。
整体损失函数如下:
L t o t a l = w k p L k p + w r L r + w c n L c n + w c L c (6) L_{total} = w_{kp} L_{kp} + w_r L_r + w_{cn} L_{cn} + w_c L_c \tag{6} Ltotal=wkpLkp+wrLr+wcnLcn+wcLc(6)
其中:
- L c n L_{cn} Lcn 是连接头的 Focal Loss
- L r L_r Lr 是偏移 Δ x \Delta x Δx 和高度 z z z 的 L1 损失
- L k p L_{kp} Lkp 是关键点提议的二元交叉熵
- L c L_c Lc 是分类损失
损失权重 w ∗ w_* w∗ 由模型学习,如 7 所提出。
3.6 从图中提取车道线
我们从预测关键点 K S = ( k 0 , ... , k S ) K_S = (k_0, \dots, k_S) KS=(k0,...,kS) 中提取车道,每个关键点 k i = ( x i , Δ x , y i , z ) k_i = (x_i, \Delta x, y_i, z) ki=(xi,Δx,yi,z)。
首先识别起始点和终止点:
- 起始点:无入边,有出边
- 终止点:有入边,无出边
判断条件如下:
∑ j = 1 S C j i = 0 且 ∑ j = 1 S C i j > 0 (7) \sum_{j=1}^{S} C_{ji} = 0 \quad \text{且} \quad \sum_{j=1}^{S} C_{ij} > 0 \tag{7} j=1∑SCji=0且j=1∑SCij>0(7)
∑ j = 1 S C j i > 0 且 ∑ j = 1 S C i j = 0 (8) \sum_{j=1}^{S} C_{ji} > 0 \quad \text{且} \quad \sum_{j=1}^{S} C_{ij} = 0 \tag{8} j=1∑SCji>0且j=1∑SCij=0(8)
车道提取过程就是在起点和终点之间寻找路径。
我们采用 Dijkstra 最短路径算法,以 1 − A 1 - A 1−A 作为边权引导路径选择。由于已应用 PointNMS 去除重复关键点,提取复杂度大幅降低。
最后,车道类别和置信度通过关键点的分类得分确定。
4. 实验
我们在两个不同的数据集上评估模型:现实世界数据集 OpenLane 和合成数据集 Apollo。这两个数据集都提供了三维空间中的车道线真值标注和相机参数。
4.1 数据集
OpenLane 2 是一个从 Waymo Open Dataset 35 构建的大规模数据集,共包含 20 万帧图像,其中 15 万帧用于训练集,5 万帧用于测试集,采样自 1000 个场景。该数据集包含 88 万条车道标注,全部位于三维空间中。测试集的场景被划分为八个不同类别:上下坡、弯道、极端天气、夜间、交叉口、合并与分裂等。一个包含 300 个场景的子集,称为 Lane300,专用于消融实验。
Apollo 5 是一个较小的合成数据集,包含 10,500 帧图像,来自高速公路、城市和乡村环境。数据集分为三个子集:标准场景、稀有场景和视觉变化场景。
4.2 评估指标
我们采用 Gen-LaneNet 5 提出的评估指标,适用于两个三维数据集。这些指标计算纵向 y y y 轴方向上 0--100 米范围内等间距点的欧几里得距离。
一条预测车道与真值车道之间的匹配成功定义为:在纵向 y y y 方向上至少有 75% 的点落在指定距离阈值范围内。默认距离阈值为 1.5 米;由于该阈值相对较大,我们还使用了 0.5 米阈值作为补充评估。
4.3 实现细节
对于 Lite 和 Base 模型,我们使用 384 × 720 384 \times 720 384×720 的输入尺寸;Large 模型使用 512 × 960 512 \times 960 512×960 的输入尺寸。
BEV 投影的尺寸分别为 56 × 32 56 \times 32 56×32、 56 × 64 56 \times 64 56×64 和 72 × 128 72 \times 128 72×128。
最大提议关键点数 S S S 为 Lite 和 Base 模型设为 256,重复次数 n = 2 n=2 n=2;Large 模型设为 384,重复次数 n = 4 n=4 n=4。
我们使用 Adam 优化器,学习率为 3 × 1 0 − 4 3 \times 10^{-4} 3×10−4,采用 warm-up 和 cosine annealing 策略。
训练在 OpenLane v1.2 上进行 24 个 epoch,在 Apollo 上训练 300 个 epoch,batch size 为 16。
4.4 消融实验
如表 2 所示,单独使用 PointNMS 可提升性能;但仅使用多关键点提议反而会降低 F1 分数。
然而,当 PointNMS 与多关键点提议方法联合使用时,检测性能得到了提升。
仅使用多关键点提议造成性能下降的原因是连接图中的歧义性:因为 GLane3D 要求每个关键点仅有一个前驱和一个后继,在相同位置存在多个关键点会引入歧义。
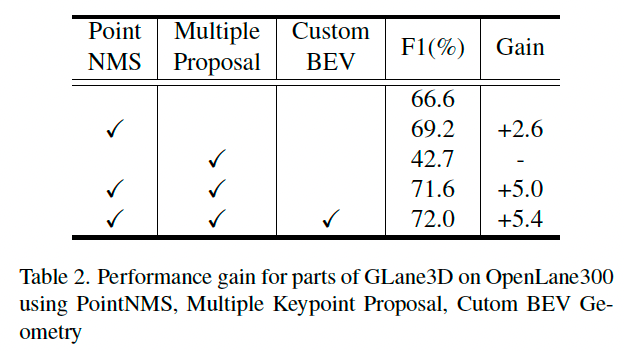
PointNMS 能解决这一问题,并减少计算开销。使用 IPM 中的自定义 BEV 几何也提升了性能,特别是在靠近 ego 车的位置提升了点密度。
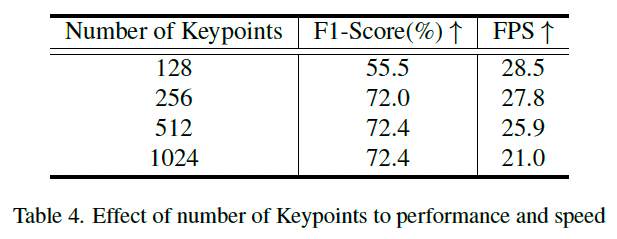
表 4 显示,增加关键点数量 S S S 的性能提升在超过 256 个节点后趋于饱和。超过这个最优点后,性能增益变小,但额外的关键点会增加计算量并降低 FPS。
这表明关键点提议头中前景/背景分离模块对模型速度有显著影响。
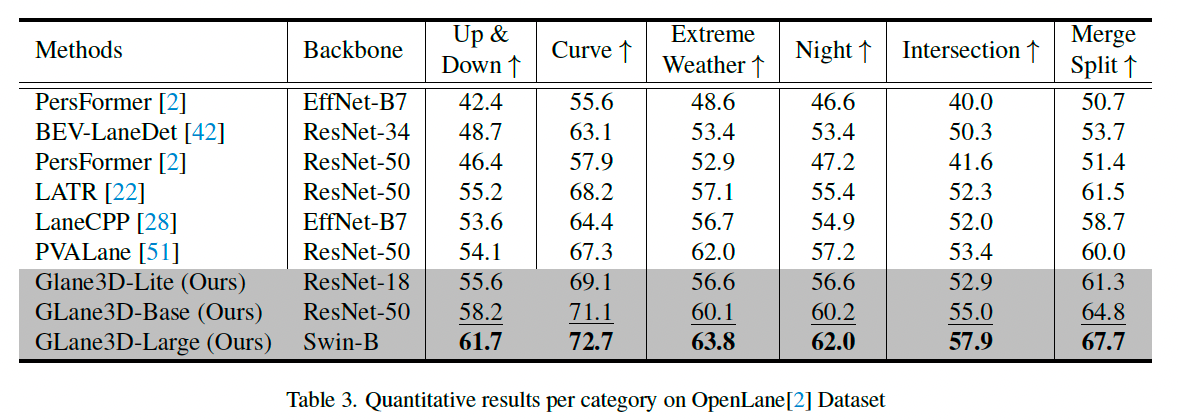
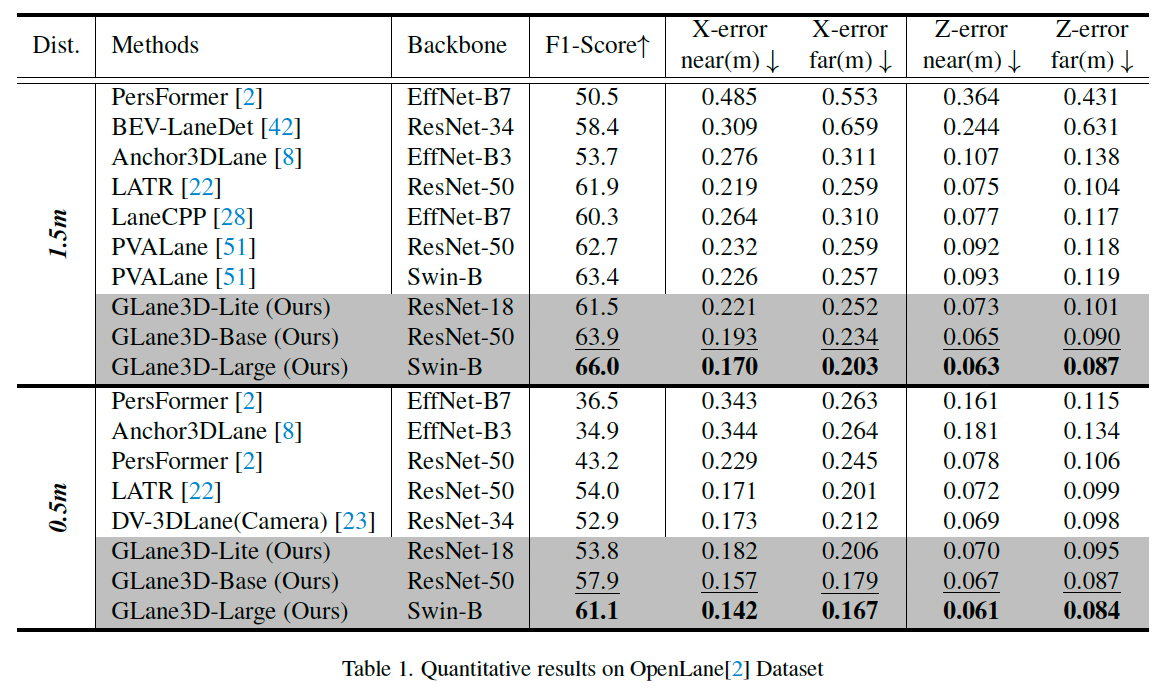
4.5 OpenLane 结果
如表 1 所示,GLane3D 模型在 F1 分数方面持续优于此前的最先进方法(SoTA)。
使用 ResNet-50 主干时,相比于基线提升了 1.2%;使用 Swin-B 主干时,GLane3D 相比 PVALane 提升了 2.6%。
在定位精度方面,GLane3D 在 x x x 和 z z z 维度上都具有更高精度。
即使在严格的 0.5 米匹配阈值下,GLane3D 仍表现出色,展现出强鲁棒性。
从表 3 的类别分析中可以看出,GLane3D 在所有场景类别上均优于 SoTA 方法。
例如,在上下坡场景中,IPM 投影有助于模型学习非平坦路面,提高了对不同地形的适应性。
关键点表示方法的灵活性也使 GLane3D 在预测弯道方面提升了 3.8%,在合并分裂和交叉口场景分别提升了 4.8% 和 1.6%。
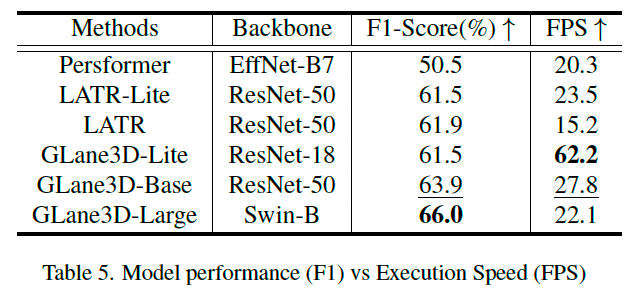
此外,GLane3D 在精度和效率之间也实现了良好平衡。
GLane3D-Lite 模型达到 62.2 FPS,F1 分数超过大多数模型,非常适合实时应用(见表 5)。
同时,GLane3D-Base 相比 LATR-Lite 提高了 2.4% 的 F1 分数,帧率相近。
该效率降低了车载部署的计算成本,提高了汽车应用的普适性和可达性。
尽管近年来激光雷达成本下降,但仍远高于摄像头。因此,GLane3D 更侧重于基于摄像头的处理,而非复杂的融合方式。
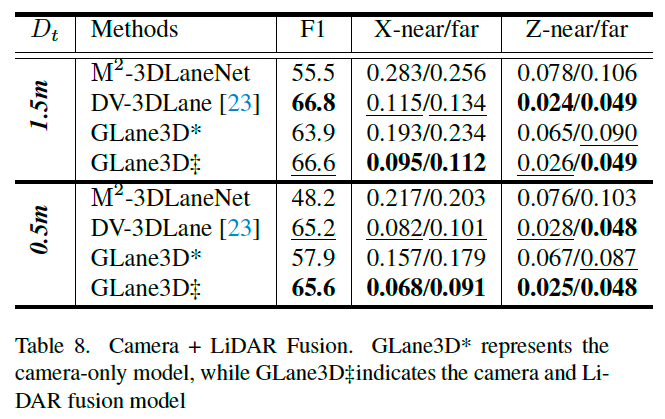
我们也训练和评估了融合摄像头+雷达输入的 GLane3D 版本,以展示其适应性。
在雷达处理方面,使用了 SECOND 47 作为雷达特征提取器,并将其与 IPM 特征结合。
尽管未采用先进融合技术,GLane3D 仍在 F1 分数上略优于先前模型(表 8),说明其在不同输入配置下的强鲁棒性和通用性。
4.6 Apollo 结果
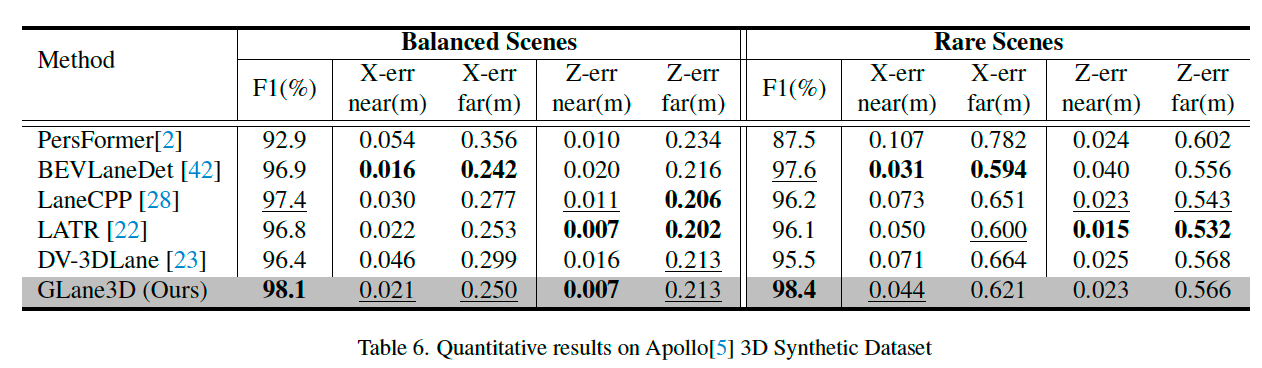
表 6 展示了在 Apollo 数据集上的量化结果。
GLane3D 在标准场景和稀有场景中 F1 分数均优于其他方法。
尽管定位误差趋于饱和,但 GLane3D 在大多数场景中定位误差仍更低。
更多详细结果见补充材料。
4.7 跨数据集评估
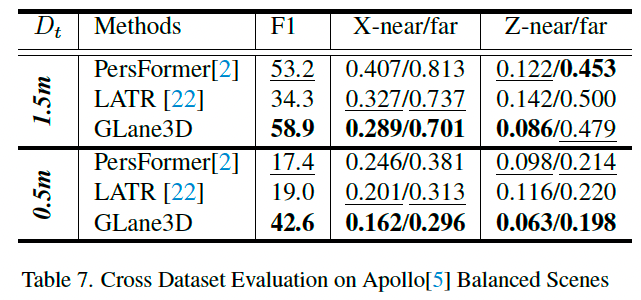
为评估模型的泛化能力,我们在 OpenLane 上训练模型,并在 Apollo 上测试。
这种方法可以验证模型在不同相机位置(俯仰、横滚、偏航及 x , y , z x,y,z x,y,z 位置)和未知环境中的推理能力,尤其是在未见过的车道结构下。
如表 7 所示,GLane3D 的泛化性能(包括 F1 分数和定位误差)明显优于其他方法。
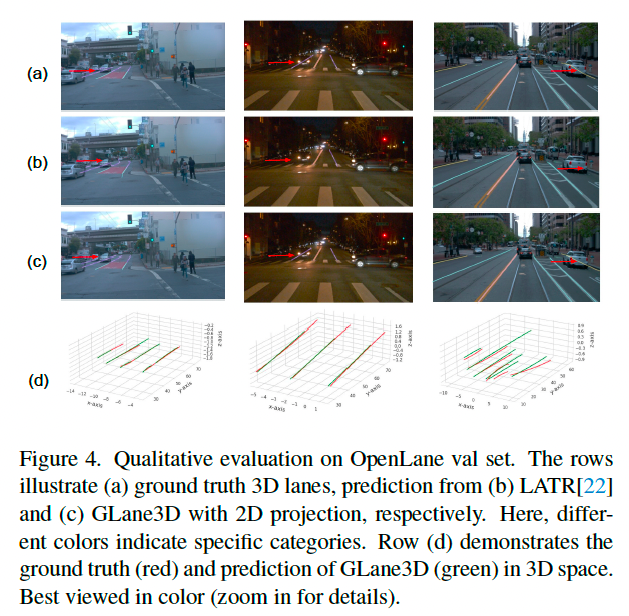
与 LATR 相比,GLane3D 的车道预测更加平滑,表明自上而下方法在泛化能力上不如本方法(见图 5)。
另一个原因是 LATR 缺乏显式的 FV 到 BEV 投影模块。
PersFormer 在跨数据集推理中缺乏定位精度,尤其是在近距离区域。
由于 F1 分数计算使用的是 1.5 米阈值,因此表 7 中的性能并未受到严重影响。

5. 结论
本文提出了 GLane3D,一种基于关键点的三维车道检测方法,采用有向连接估计进行高效车道提取。
通过多提议关键点和 PointNMS 增强检测,减少了计算开销。
我们采用自定义的 BEV 锚点结合逆透视映射(IPM),提升了靠近 ego 车位置的采样密度,缓解远距离区域的稀疏问题。
跨数据集评估验证了 GLane3D 的强泛化能力。
GLane3D 在 OpenLane 和 Apollo 数据集上均超越当前最先进方法,在摄像头+雷达融合设置下也取得了最高 F1 分数。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 "Stay Hungry, Stay Foolish" ------ 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!
