一、环境搭建与基础配置
1、安装指南
(1)Java环境校验
------JMeter是使用java编写的,必须安装java环境,推荐安装jdk11;
参考:blog.csdn.net/weixin_6153...
(2)JMeter下载与启动
---Part1:下载---
链接:jmeter.apache.org/download_jm...

---Part2:启动---
解压压缩包后进入bin文件夹,打开对应路径终端,输入jemter启动;

2、必装插件
通过jmeter官网下载的jmeter 并没有jmeter plugins manager,也没有常用的stepping thread group、RT和TPS UI视图界面需要自己下载安装;
1.从官网下载jmeter plugins manager的jar包
下载地址:jmeter-plugins.org/install/Ins...
2.按照提示文案,将下载的jar包放在jmeter的lib/ext目录下
3.启动jmeter
就可以在菜单栏 选项下找到plugins Manager,点击plugins Manager就会弹出一下界面
常用插件:RT和TPS UI视图界面
二、测试计划示例
Jmeter-http接口脚本
一般分五个步骤:(1)添加线程组 (2)添加http请求 (3)在http请求中写入接入url、路径、请求方式和参数 (4)添加查看结果树 (5)调用接口、查看返回值;
1、并发线程组:Concurrency Thread Group
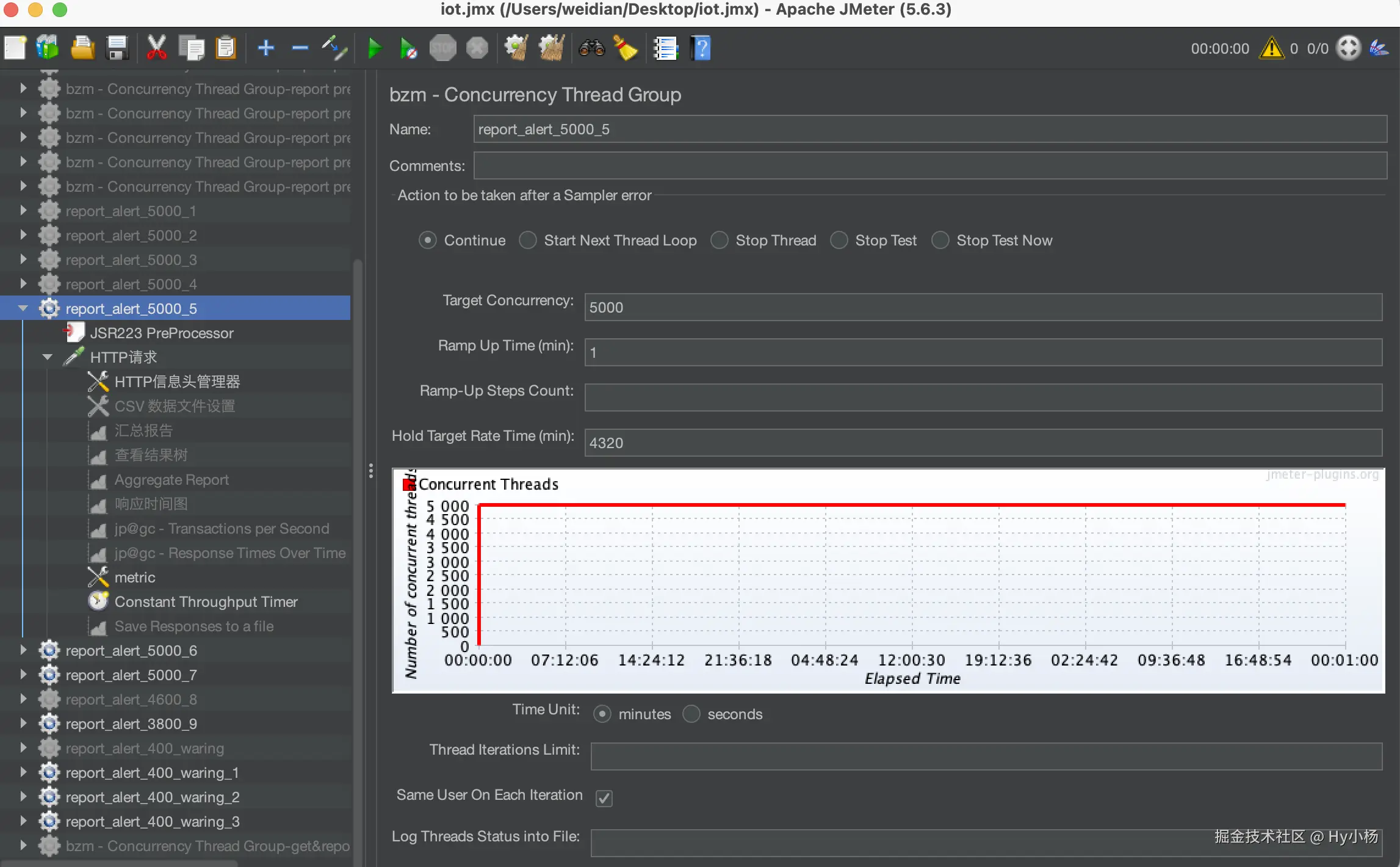
- Target Concurrency:目标并发(线程数),例如设置为5000表示最终会有5000个线程同时运行;
- Ramp Up Time:启动时间;若设置 1 min,则目标线程在1 imn内全部启动;
- Ramp-Up Steps Count :阶梯次数;若设置 10 ,则目标线程在 1min 内分六次阶梯加压(启动线程);每次启动的线程数 = 目标线程数 / 阶梯次数 = 5000 / 10 = 500;
- Hold Target Rate Time:持续负载运行时间;若设置 4320(min) ,则启动完所有线程后,持续负载运行 72小时,然后再结束;
- Time Unit:时间单位(分钟或者秒);
- Thread Iterations Limit: 线程迭代次数限制(循环次数);默认为空,理解成永远,如果运行时间到达 Ramp Up Time + Hold Target Rate Time,则停止运行线程 【不建议设置该值】;
- Log Threads Status into File: 将线程状态记录到文件中(将线程启动和线程停止事件保存为日志文件);
2、HTTP请求
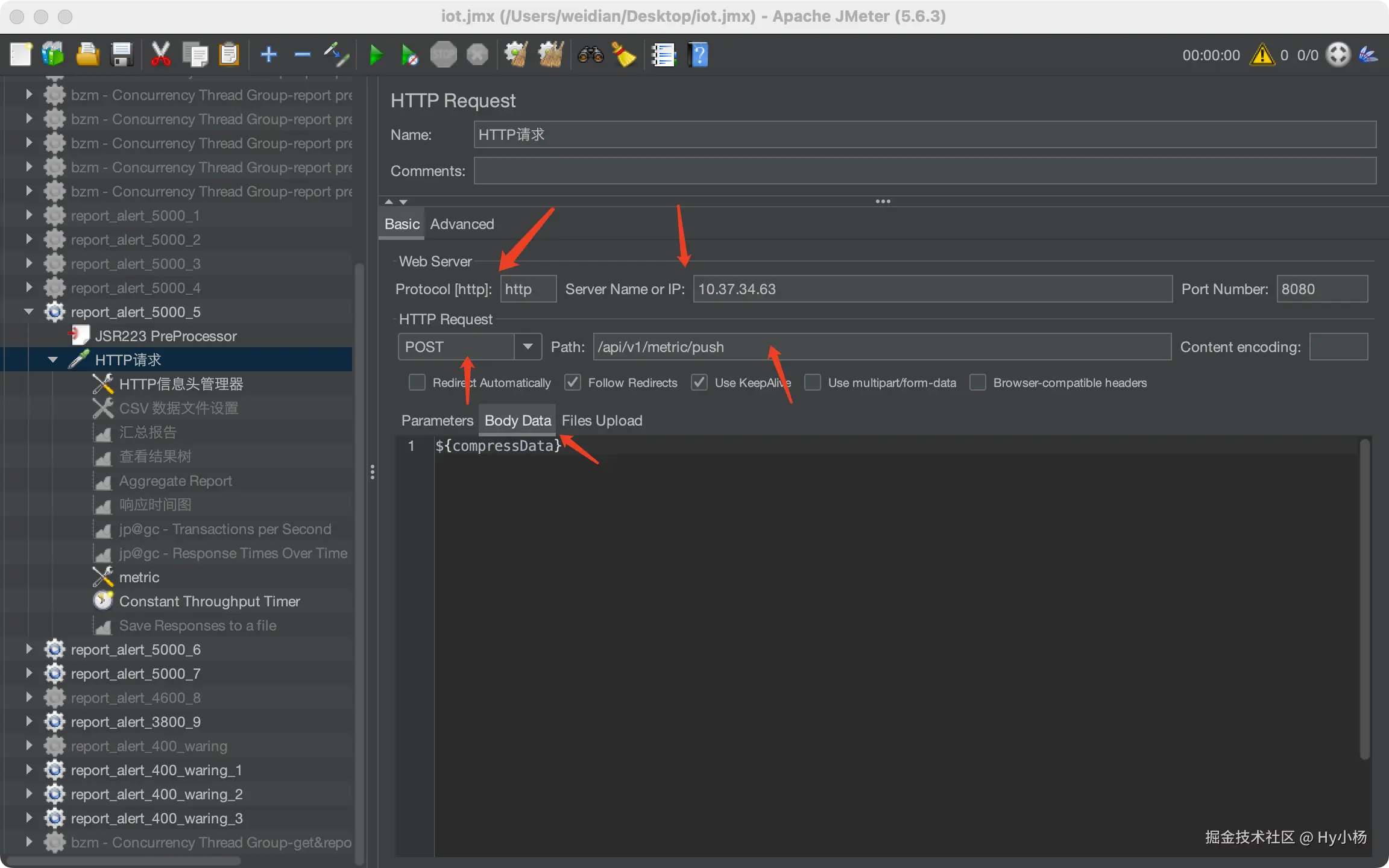
- 协议:http && https
- 服务器名称或ip:如172.16.195.143
- 方法:一般Post && Get
- 路径:你向服务器发送请求的路径(api)
- Parameters:请求的参数/ Body Data:post数据
3、HTTP信息头管理器
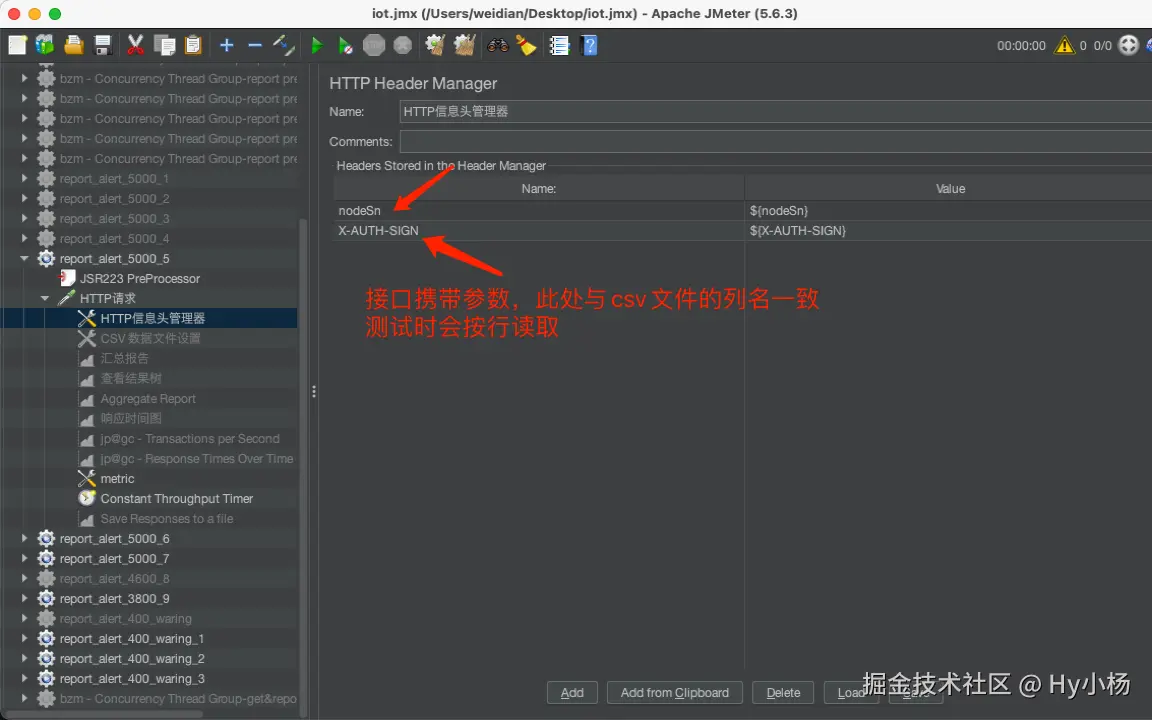
- 设置通用头部信息:为所有的 HTTP 请求设置相同的头部信息,减少重复配置;
- 覆盖默认头部:如果某些请求需要不同的头部信息,可以在具体的 HTTP 请求中覆盖这些默认设置;
4、CSV文件设置
------从外部 csv 文件读取数据出来作为变量
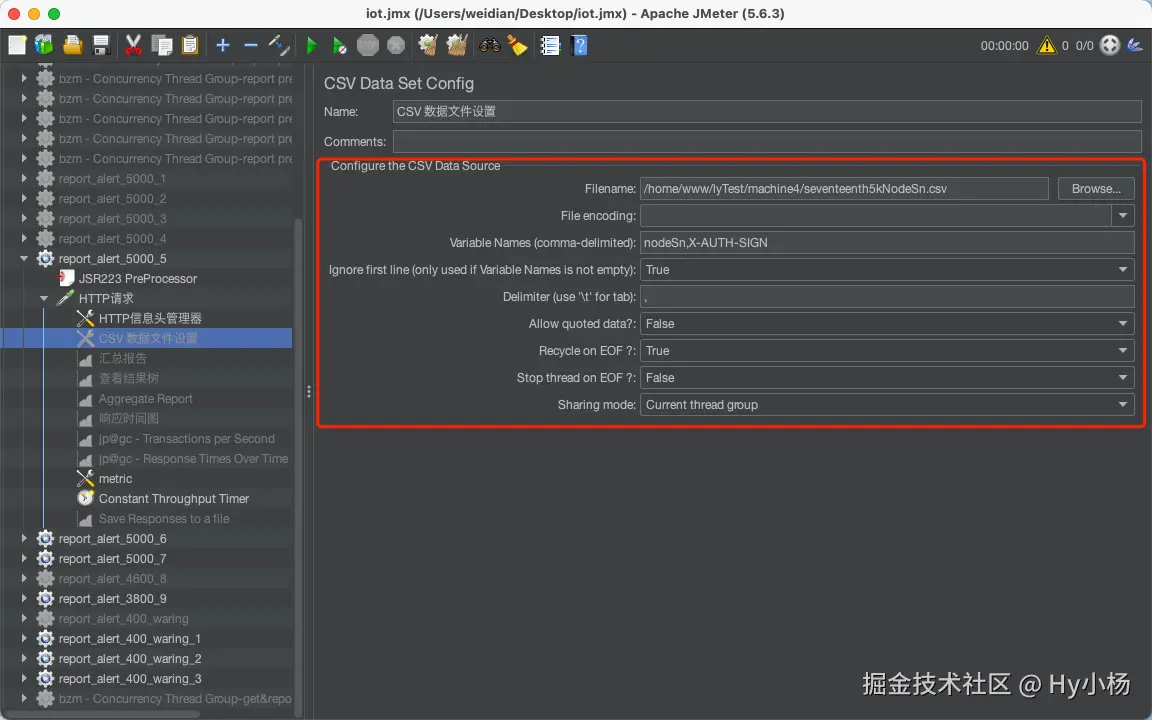
-
文件名:csv 文件路径,可以是绝对路径或者相对路径(建议设置成相对路径,填写相对于脚本的路径,后续远程压测或迁移时,可以更好的找到文件)
-
文件编码:编码格式,与所选文件编码格式保持一致
-
变量名称:如果文件中只有一个变量(csv文件列名),直接写变量名,如果有多个变量,用英文的逗号隔开(例:var1,var2)
-
忽略首行:设置为 True 时,从文件第二行开始读取,此时文件第一行为变量名,例:var1,var2;设置为 True
-
分隔符(用 '\t' 代替制表符) :根据文件中的分隔符进行填写,默认:,
-
是否允许带引号:
- True:参数文件包含引号时,实际的数据为引号中的数据。比如参数文件中的数据为"1,2",当使用该参数时,实际取得值为1,2
- False:参数文件包含引号时,实际取得值为全部的值。比如参数文件中的数据为"1,2",当使用该参数时,实际取得值为"1,2"会取成两个参数
- 遇到文件结束符再次循环:
-
- True:参数文件中的数据循环使用,测试按照线程组中的设置执行。比如csv 文件共有 10 条记录,但线程数有 15 个,循环 10 次后,重头开始循环取值
- False:参数文件不再循环遍历取值
-
遇到文件结束符停止线程:True:当执行完参数文件中所有参数后,直接停止线程,同理,false即不停止
-
线程共享模式:
- 所有线程(All threads):参数文件对所有线程共享,这包括同一测试计划中的不同线程组(测试计划下的所有线程组下的所有线程共享参数文件,所有线程之前参数取值互相影响,线程在同一次迭代下取值相同)
- 当前线程组(Current thread group): 只对当前线程组中的线程共享(当前线程组下的所有线程公用一个参数文件,同一个线程组下的线程之前取值相互影响,线程在同一次迭代下取值相同)
- 当前线程(Current thread): 仅当前线程获取(即每个线程获取一个参数文件,各个线程之间参数取值互不影响,线程在同一次迭代下取值相同)
5、聚合报告/汇总报告
(1)聚合报告
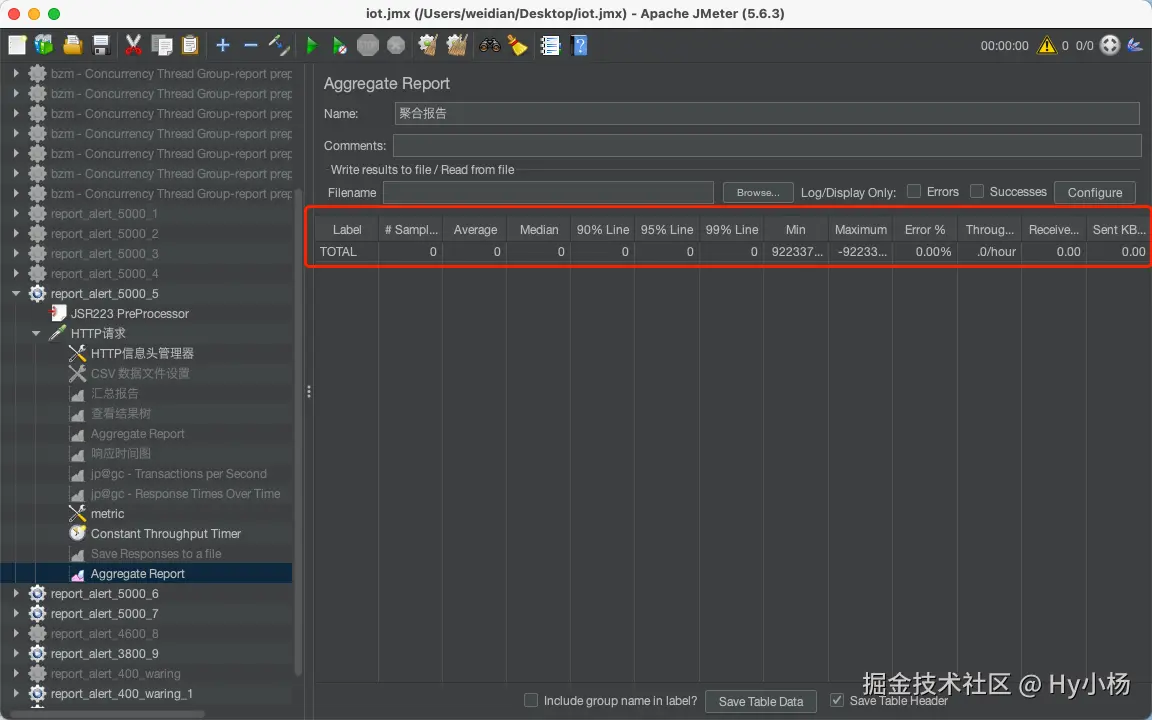
- Label:就是请求名称
- #Samples:总线程数,值 = 线程数 * 循环次数
- Average :单个请求的平均响应时间,值 = 总运行时间 / 发送到服务器的总请求数
- Median、90%line、95%line、99%line分别代表50%的用户响应时间、90%的用户响应时间、95%的用户响应时间、99%的用户响应时间,也就是有百分之多少的请求小于这个值。其中,90%line是性能测试中比较重要的一个衡量指标。
- Min:最小响应时间
- Max:最大响应时间
- Error% :错误率,发生错误的请求 / 总请求数
- Throughput:吞吐量,表示每秒完成的请求数
- KB/sec:以每秒接收/发送的千字节为单位测量的吞吐量
(2)汇总报告
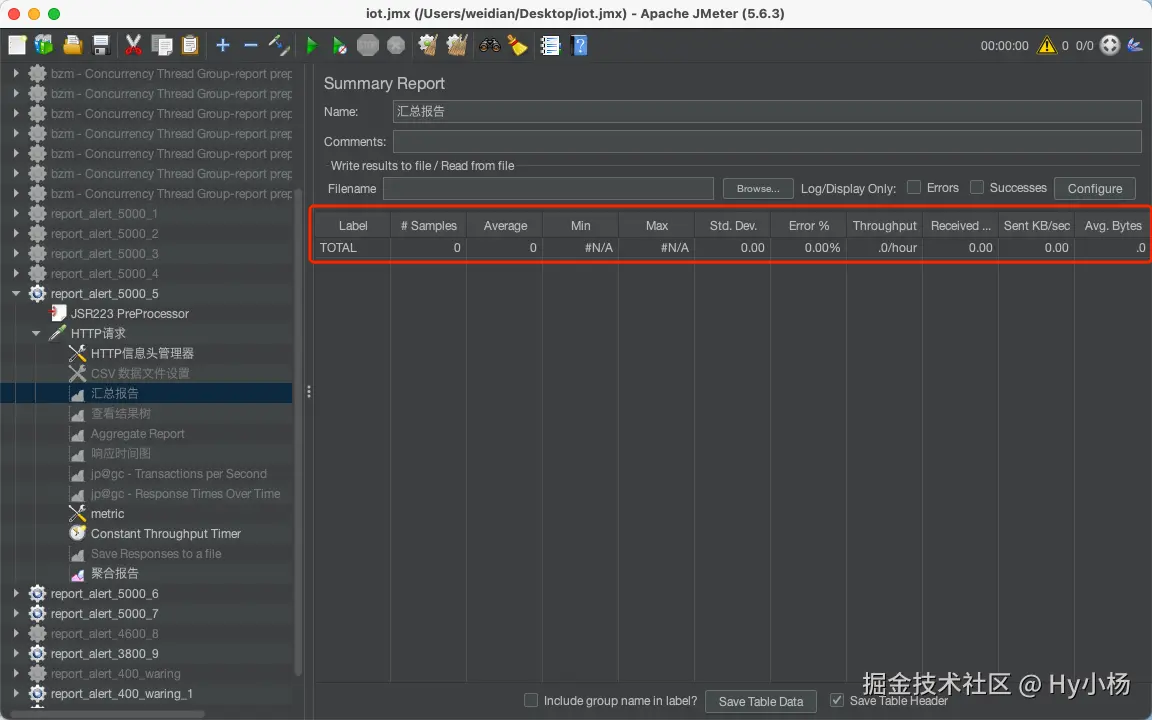
- 平均值:一组样本的平均响应时间
- 最小值:一组样本中最短的响应时间
- 最大值:一组样本中最长的响应时间
- 平均字节数:样本响应数据的平均大小,以字节为单位
6、查看结果树
显示所有样本响应数据、花费时间、响应代码等信息;
 查看响应的方法有以下15种,详细信息参考:www.cnblogs.com/dabeen/p/18...
查看响应的方法有以下15种,详细信息参考:www.cnblogs.com/dabeen/p/18...
- Text:显示响应中包含的所有文本
- Regexp Tester(正则表达式测试) :可用于正则表达式测试
- Boundary Extractor Tester(边界提取器测试) :可用于左右边界测试
- CSS/JQuery Tester(CSS选择器测试) :可用于属性测试
- JSON Path Tester(JSON路径测试) :可用于JSON路径测试
- XPath2 Tester(XPath2测试)
- JSON JMESPath Tester
- XPath Tester(XPath测试)
- HTML:将响应呈现为HTML
- HTML Source Formatted(HTML源格式) :呈现HTML源代码
- HTML (download resources)(HTML下载资源) :呈现HTML代码引用的图像、样式表等
- Document:文档视图将显示从各种类型的文档中提取文本、以及一些"多媒体"文件的数据
- JSON:以树样式展示json响应数据
- XML:以树样式显示响应
- Browser **
**
7、Response Times Over Time
即TRT:事务响应时间,性能测试中,最重要的2个指标之一。该插件的主要作用是在测试脚本执行过程中,监控查看响应时间的实时平均值、整体响应时间走向等。
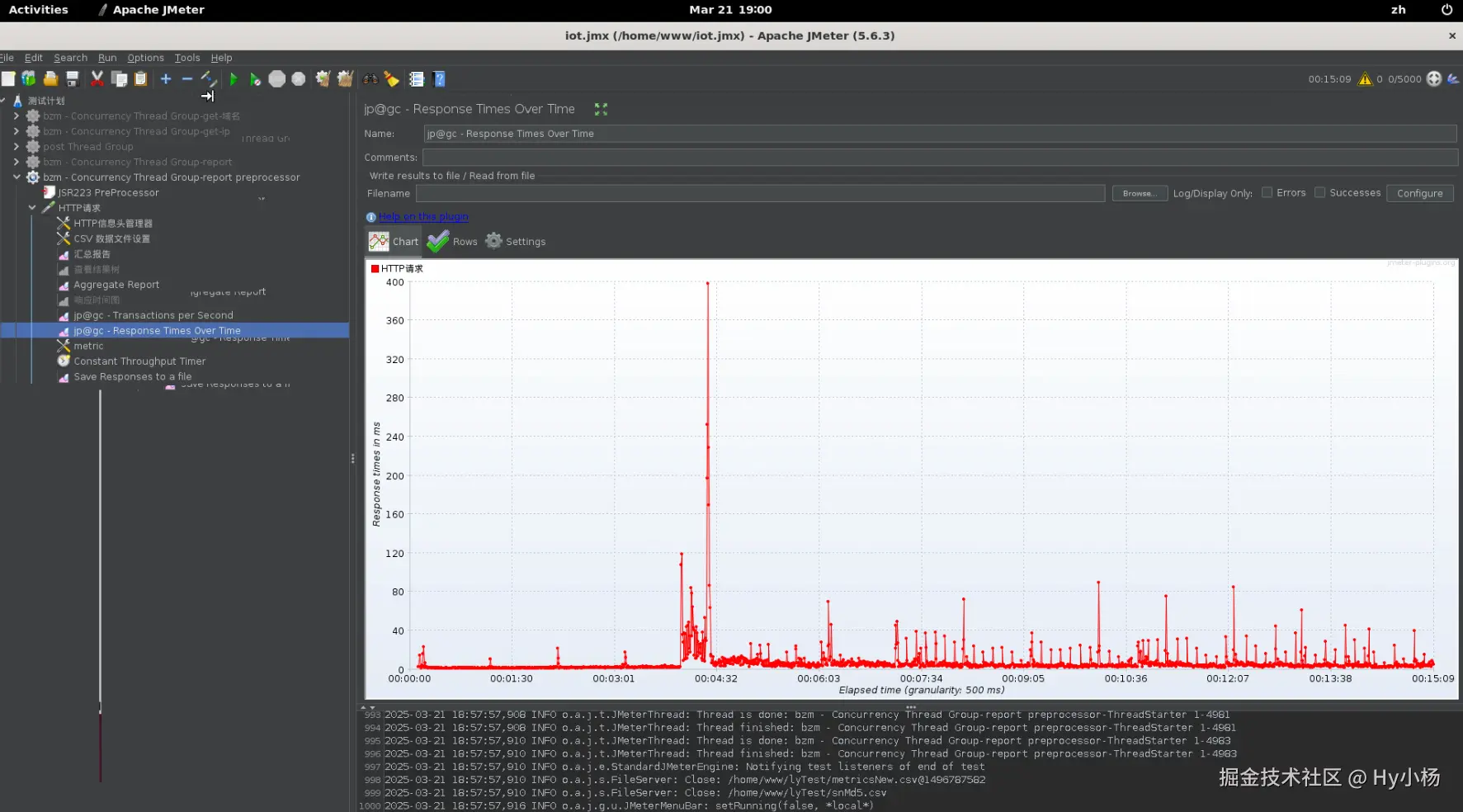
8、Transactions per Second
即TPS:每秒事务数,性能测试中,最重要的两个指标的另外一个。该插件的作用是在测试脚本执行过程中,监控查看服务器的TPS表现------------比如整体趋势、实时平均值走向、稳定性等。

9、Constant Throughput Timer(定时器)
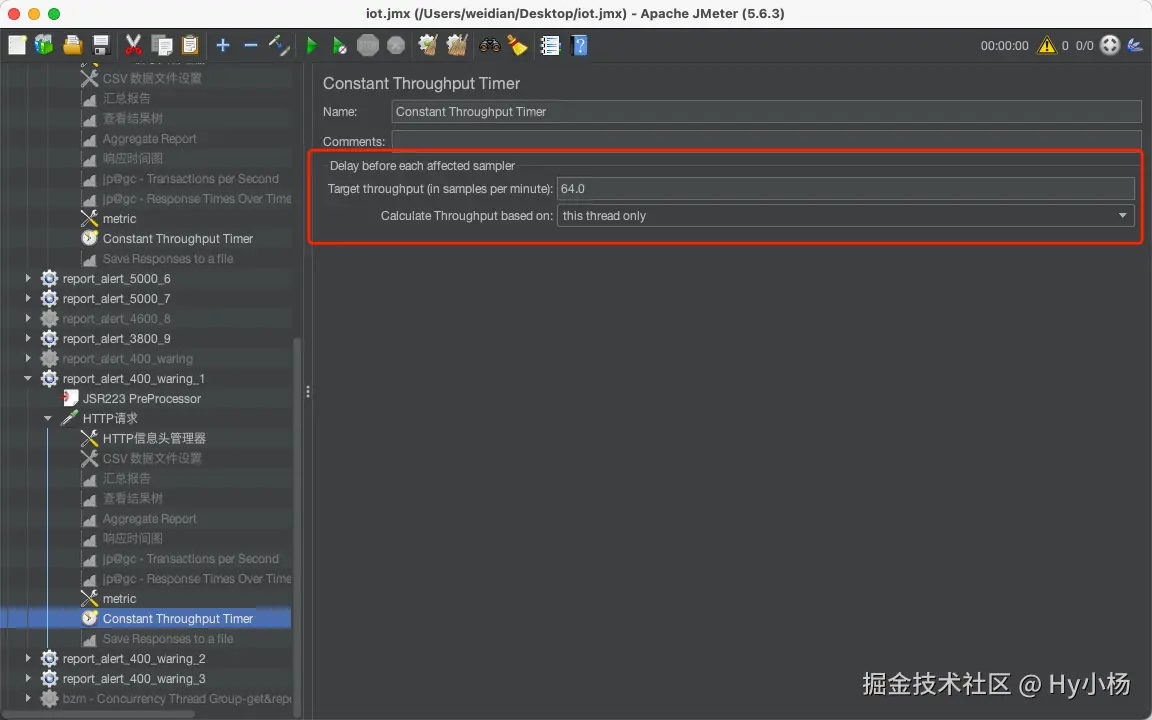
-
Target Throughput(minute) :每分钟吞吐量
-
Calculate Ghtrouhput based on:吞吐量基于下面几种方式计算
(1)this thread only:基于当前线程。如Number of Thread=5.则TPS=5*2=10
(2)all active threads:所有活跃的线程
(3)all active threads in current thread group:当前线程组所有活跃的线程
(4)all active thread(shared):所有活跃的线程(共享)
(5)all active threads in current thread group(shared):当前线程组中的所有活跃的线程(共享)
10、Save Responses to a file
使用场景:当结果太大,使用结果树监听器影响图形模式时,我们可以采用响应保存监听器来处理
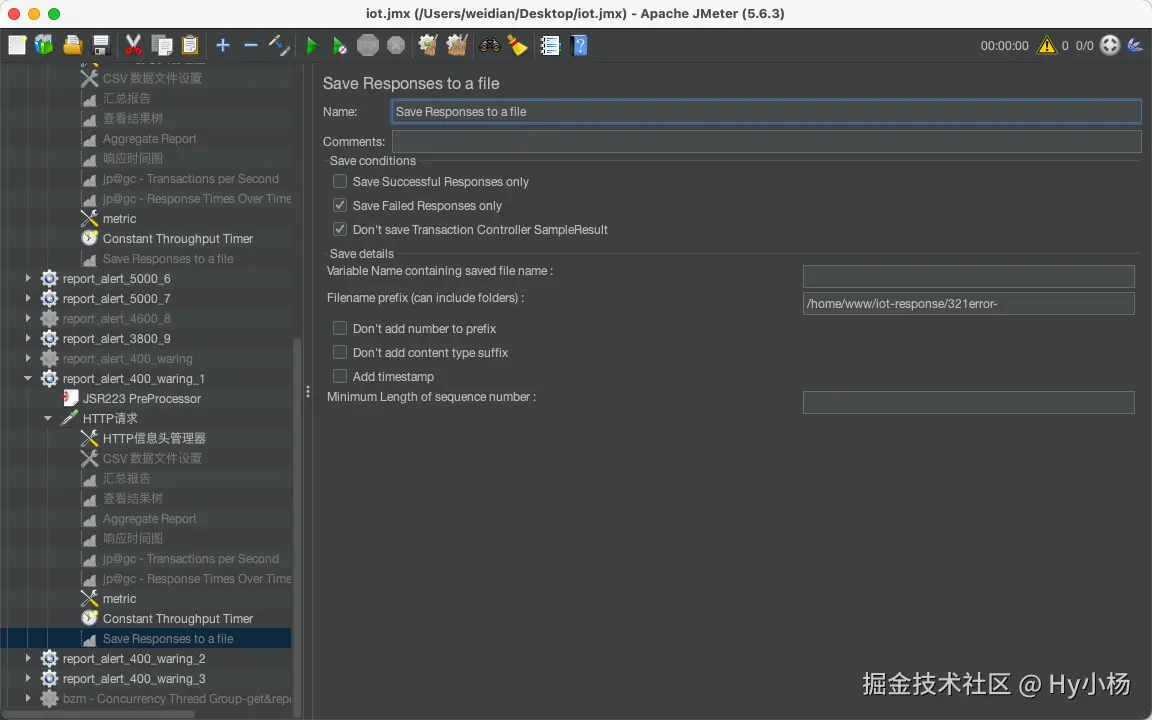
-
Save conditions
- Save Successful Responses only:仅保存成功响应
- Save Failed Responses only:仅保存失败响应
- Don't save Transaction Controller SampleResult:不保存事务控制器样本结果
-
Save details
- 文件名称前缀(Filename prefix (can include folders)):文件路径 + 文件前缀
- Don't add number to prefix:不添加数字到文件前缀
- Don't add content type suffix:不添加文件的后缀类型
- Add timestamp:添加时间戳到文件前缀
- Minimum Length of sequence number:设置文件名称最小的序列号
三、日志文件分析脚本
分析日志文件中"写入vm成功"相关的性能数据,主要计算响应时间(RT)的统计指标和写入样本总量;
js
#!/bin/bash
# 检查是否提供了足够的参数
if [ $# -lt 1 ]; then
echo "错误: 请指定日志文件路径"
echo "用法: $0 <日志文件路径> [开始时间] [结束时间]"
echo "时间格式: YYYY-MM-DD HH:MM:SS[.mmm]"
exit 1
fi
log_file="$1"
start_time="$2"
end_time="$3"
# 检查日志文件是否存在
if [ ! -f "$log_file" ]; then
echo "错误: 日志文件 $log_file 不存在"
exit 1
fi
grep "写入vm成功" "$log_file" | awk -v start_time="$start_time" -v end_time="$end_time" '
BEGIN {
# 初始化时间范围变量
if (start_time != "") {
gsub(/[-:.]/, " ", start_time)
split(start_time, st, " ")
start_ts = mktime(st[1] " " st[2] " " st[3] " " st[4] " " st[5] " " st[6]) * 1000 + (st[7] == "" ? 0 : st[7])
} else {
start_ts = 0
}
if (end_time != "") {
gsub(/[-:.]/, " ", end_time)
split(end_time, et, " ")
end_ts = mktime(et[1] " " et[2] " " et[3] " " et[4] " " et[5] " " et[6]) * 1000 + (et[7] == "" ? 0 : et[7])
} else {
end_ts = 9999999999999 # 未来很久的时间
}
}
{
# 提取日志时间
log_time = $1 " " $2
# 转换日志时间为时间戳
gsub(/[-:.]/, " ", log_time)
split(log_time, dt, " ")
current_ts = mktime(dt[1] " " dt[2] " " dt[3] " " dt[4] " " dt[5] " " dt[6]) * 1000 + (dt[7] == "" ? 0 : dt[7])
# 检查时间范围
if (current_ts < start_ts || current_ts > end_ts) {
next # 跳过不在时间范围内的记录
}
if (match($0, /[0-9]{13}/, ts_arr)) {
start_ms = ts_arr[0]
end_ms = current_ts
rt = end_ms - start_ms
# 提取批次数并累加
if (match($0, /批次: ([0-9]+)/, batch_arr)) {
total_samples += batch_arr[1]
}
# 只统计合理的 RT 值
if (rt >= 0 && rt <= 10000) {
rts[++n] = rt
sum += rt
if (rt > max || max == "") max = rt
if (rt < min || min == "") min = rt
}
}
}
END {
if (n > 0) {
# 计算平均值
avg = sum / n
# 计算 P90
asort(rts)
p90_pos = int(n * 0.9)
if (p90_pos < 1) p90_pos = 1
p90 = rts[p90_pos]
# 显示实际统计的时间范围
printf "统计时间范围: "
if (start_ts == 0) {
printf "开始"
} else {
printf "%s", strftime("%Y-%m-%d %H:%M:%S", start_ts/1000)
if (start_ts % 1000 > 0) {
printf ".%03d", start_ts % 1000
}
}
printf " 至 "
if (end_ts == 9999999999999) {
printf "结束"
} else {
printf "%s", strftime("%Y-%m-%d %H:%M:%S", end_ts/1000)
if (end_ts % 1000 > 0) {
printf ".%03d", end_ts % 1000
}
}
printf "\n"
printf "写入样本总量: %d\n", total_samples
printf "RT (ms):\nMax: %.2f\nMin: %.2f\nAvg: %.2f\nP90: %.2f\nCount: %d\n",
max, min, avg, p90, n
} else {
print "未找到有效日志"
}
}'(1)基础使用方法
./calculate_rt_stats.sh 日志文件路径
(2)带时间范围的用法
./calculate_rt_stats.sh 日志文件路径 "开始时间" "结束时间"
例如:./calculate_rt_stats.sh app.log "2025-01-01 10:00:00" "2025-01-01 11:00:00"
(3)输出说明
- 实际统计的时间范围
- 写入样本总量
- RT统计信息:最大值、最小值、平均值、P90值和有效记录数
(4)注意
- 如果没有提供时间参数,会处理整个日志文件
- 如果找不到匹配的日志,会显示"未找到有效日志"
四、压测踩坑经验分享
1、重新开始RUN之前,要清除当前计划中国中的所有监听器的执行结果;
2、导出.jmx文件之前,要先Save保存整个测试计划;
3、jmeter内存不足
JMeter 默认内存较小,大并发测试时修改bin\jmeter.bat(Windows)或jmeter.sh(Linux/Mac)中的HEAP参数(如set HEAP=-Xms2g -Xmx4g)。
4、正式压测执行时,GUI模式会占用大量系统资源(CPU/内存),影响压测结果的准确性
脚本开发与调试阶段、 实时监控测试结果时, 可开启图形化界面(GUI), 执行高并发测试(如1000+线程)或长时间稳定性测试时,通过命令行启动
运行命令格式:
./jmeter -n -t jmx脚本路径 -l 测试输出文件路径