MOEA/D-DE 算法在工程设计、生产调度、资源分配等领域有着广泛应用。在工程设计中,助力机械、电子电路实现多性能指标平衡;生产调度场景里,优化车间任务与物流配送规划;资源分配方面,实现能源与人力资源的合理调配 ,借此在各领域复杂的多目标优化场景下,寻找不同目标间的最佳平衡点。
算法简介
-
MOEA/D-DE 算法,即基于分解的多目标进化算法与差分进化相结合的算法。它将多目标优化问题分解为一系列子问题,通过优化这些子问题来逼近多目标问题的 Pareto 前沿。 核心思想:该算法利用权重向量将多目标优化问题转化为多个单目标优化子问题,每个权重向量对应一个子问题。通过差分进化(DE)算子,在种群中进行变异、交叉和选择操作,产生新的解。算法在更新解的过程中,不仅考虑当前子问题,还利用邻域子问题的信息,从而有效提高算法的搜索效率和收敛性。
-
算法优势
-
高效性:通过将多目标问题分解为多个子问题,MOEA/D-DE 算法能够在多个方向上同时进行搜索,大大提高了搜索效率,减少了计算时间。
-
解的多样性:算法在进化过程中,通过邻域操作和差分进化算子,能够保持种群的多样性,避免算法陷入局部最优,从而获得分布均匀的 Pareto 前沿近似解。
-
灵活性:该算法可以灵活地与不同的分解方法和进化算子相结合,适应不同类型的多目标优化问题,具有很强的通用性。
算法步骤与公式
以下是对MOEA/D - DE算法步骤更详细的介绍:
初始化
-
生成权重向量 :
- 对于维目标空间,通常使用均匀设计等方法生成个均匀分布的权重向量,。例如,在二维目标空间中,若要生成个权重向量,可以将区间等分为段,然后对于第个权重向量,令,。
-
初始化种群 :
- 针对每个权重向量,在问题的可行解空间内通过随机采样等方式生成一个初始解,从而得到初始种群。例如,对于一个变量取值范围在的问题,可通过来生成第个个体的第个变量值,其中是生成到之间随机数的函数。
-
计算目标函数值 :
- 对于每个初始解,将其代入多目标优化问题的目标函数中,计算出对应的目标函数值。假设多目标优化问题为,则分别计算每个目标函数,的值。
-
确定邻域结构 :
- 计算权重向量之间的距离,常用欧几里得距离。对于每个权重向量,找到与它距离最近的个权重向量,这些对应的子问题就是子问题的邻域。例如,将所有权重向量之间的距离计算出来后,对距离进行排序,选取前个距离最小的权重向量作为邻居。
-
初始化理想点 :
- 设理想点,初始时,。即遍历初始种群中所有个体的第个目标函数值,取最小值作为理想点的第个分量。
迭代优化
-
子问题优化:
-
变异操作 :
- 对于每个子问题,从当前种群中随机选择三个不同的个体、、(),通过公式生成变异个体,其中是变异因子,一般在到之间取值,例如取。
-
交叉操作 :
- 将变异个体与原个体进行基因交换生成新的候选解。采用二项式交叉时,对于每个基因座,以概率(交叉概率,通常取值在到之间,如)将设置为,否则设置为。即,其中是生成到之间随机数的函数。
-
计算目标函数值和分解后的适应度值 :
- 计算新候选解的目标函数值。若采用切比雪夫法计算分解后的适应度值,公式为。
-
更新邻域 :
- 对于子问题及其邻域中的子问题(即权重向量为,属于的邻域),如果,则用替换,即。同时,更新理想点,对于,。这意味着如果新解在某个目标上的值比当前理想点对应的值更好,就更新理想点。
-
归档 :
- 检查新生成的解以及种群中的其他解,将非支配解保存到归档集合中。非支配解是指对于解,如果不存在其他解使得对于所有成立,且至少存在一个使得$f_k(y)
终止条件
-
当达到预设的迭代次数时,算法终止,输出最终的Pareto前沿近似解集,即归档集合中的解。
-
或者满足其他收敛标准时终止,例如连续代种群的最优解的最大变化量小于某个阈值,即,其中是第代的解。这里的是一个很小的正数,根据具体问题设定,如。或者是目标函数值的变化小于某个阈值,例如,其中是第代的理想点的第个分量。
代码
matlab代码
clear
clc
close all
% 问题参数设置
% M 表示目标函数的个数,这里设置为 2 代表是一个双目标优化问题
M = 2;
% D 表示决策变量的个数,也就是优化问题中需要确定的变量数量
D = 10;
% N 表示种群的大小,即每一代中包含的个体数量
N = 100;
% T 表示邻域的大小,用于确定每个子问题的邻居数量
T = 20;
% MaxGen 表示最大迭代次数,算法达到该次数后将停止迭代
MaxGen = 500;
% F 是差分进化算法中的变异因子,控制变异操作的幅度
F = 0.5;
% CR 是差分进化算法中的交叉概率,决定了变异个体与原个体进行基因交换的可能性
CR = 0.9;
% 生成权重向量
% W 是一个 N 行 M 列的矩阵,用于存储生成的权重向量
W = zeros(N, M);
% 目前仅处理二维目标空间的权重向量生成
if M == 2
% 通过循环生成 N 个均匀分布在 [0, 1] 区间上的权重向量对
for i = 1:N
% 第一个目标函数的权重
W(i, 1) = (i - 1) / (N - 1);
% 第二个目标函数的权重,保证两个权重之和为 1
W(i, 2) = 1 - W(i, 1);
end
else
% 对于更高维度的目标空间,当前代码不支持,给出错误提示
error('目前仅支持二维目标空间的权重向量生成');
end
% 初始化种群
% P 是一个 N 行 D 列的矩阵,通过 rand 函数在 [0, 1] 区间内随机生成种群
P = rand(N, D);
% 计算目标函数值
% F_values 是一个 N 行 M 列的矩阵,用于存储每个个体对应的目标函数值
F_values = zeros(N, M);
% 遍历种群中的每个个体
for i = 1:N
% 调用目标函数计算目标值
[f1, f2] = zdt1_objective(P(i, :), D);
% 将计算得到的目标函数值存储到 F_values 矩阵中
F_values(i, 1) = f1;
F_values(i, 2) = f2;
end
% 确定邻域结构
% B 是一个 N 行 T 列的矩阵,用于存储每个子问题的邻域信息
B = zeros(N, T);
% 遍历每个子问题
for i = 1:N
% 计算当前权重向量与其他所有权重向量之间的欧几里得距离
dist = sqrt(sum((repmat(W(i, :), N, 1) - W).^2, 2));
% 对距离进行排序,并返回排序后的索引
[~, idx] = sort(dist);
% 选取距离最近的 T 个权重向量的索引(排除自身),作为当前子问题的邻域
B(i, :) = idx(2:T + 1);
end
% 初始化理想点
% z 是一个 1 行 M 列的向量,存储每个目标函数在初始种群中的最小值,作为理想点
z = min(F_values);
% 迭代优化
% 开始迭代,直到达到最大迭代次数
for gen = 1:MaxGen
% 遍历每个子问题
for i = 1:N
% 变异操作
% 从当前子问题的邻域中随机选择 3 个不同的个体的索引
r = randperm(T, 3);
% 得到这 3 个个体在种群中的实际索引
r1 = B(i, r(1));
r2 = B(i, r(2));
r3 = B(i, r(3));
% 根据差分进化算法的变异公式生成变异个体
V = P(r1, :) + F * (P(r2, :) - P(r3, :));
% 边界处理
% 确保变异个体的每个决策变量值不小于 0
V = max(V, 0);
% 确保变异个体的每个决策变量值不大于 1
V = min(V, 1);
% 交叉操作
% 初始化新的候选解为当前个体
U = P(i, :);
% 随机选择一个基因座
jrand = randi(D);
% 遍历每个基因座
for j = 1:D
% 如果随机数小于交叉概率或者当前基因座是随机选择的基因座
if rand <= CR || j == jrand
% 将新候选解的该基因座的值替换为变异个体的对应值
U(j) = V(j);
end
end
% 计算目标函数值
% 调用目标函数计算新候选解的目标值
[f1, f2] = zdt1_objective(U, D);
% 将新候选解的目标函数值存储到 U_F 向量中
U_F = [f1, f2];
% 计算切比雪夫适应度值
% 根据切比雪夫分解方法计算新候选解的适应度值
g_tch_U = max(abs(U_F - z).* W(i, :));
% 更新邻域
% 遍历当前子问题的邻域
for j = 1:T
% 得到邻域中个体在种群中的实际索引
k = B(i, j);
% 计算邻域中个体的切比雪夫适应度值
g_tch_P = max(abs(F_values(k, :) - z).* W(k, :));
% 如果新候选解的适应度值更优
if g_tch_U <= g_tch_P
% 用新候选解替换邻域中的个体
P(k, :) = U;
% 更新邻域中个体的目标函数值
F_values(k, :) = U_F;
end
end
% 更新理想点
% 如果新候选解的某个目标函数值比当前理想点更好,更新理想点
z = min([z; U_F]);
end
end
% 归档
% dominated 是一个长度为 N 的逻辑向量,用于标记每个个体是否被支配
dominated = false(N, 1);
% 遍历每个个体
for i = 1:N
% 与其他个体进行比较
for j = 1:N
if i ~= j
% 如果个体 i 在所有目标上都不优于个体 j,且至少在一个目标上劣于个体 j
if all(F_values(i, :) >= F_values(j, :)) && any(F_values(i, :) > F_values(j, :))
% 标记个体 i 为被支配
dominated(i) = true;
% 跳出内层循环
break;
end
end
end
end
% 筛选出非支配个体
F_values = F_values(~dominated, :);
P = P(~dominated, :);
[~,ia] = unique(F_values,'row','stable');
F_values = F_values(ia,:);
P = P(ia,:);
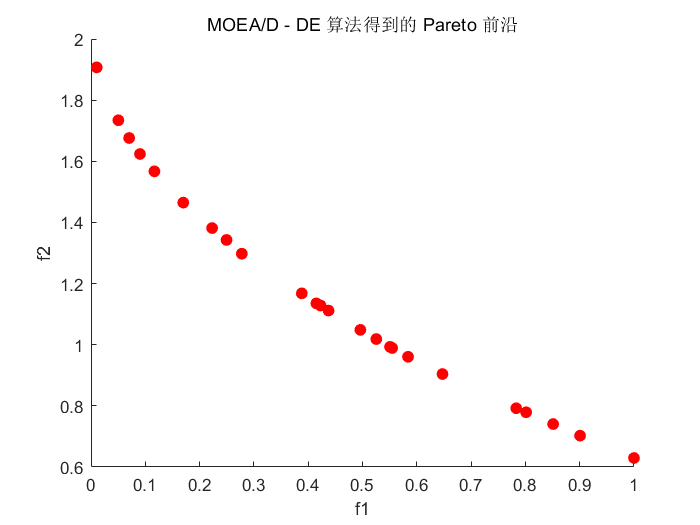
% 绘制 Pareto 前沿
% 创建一个新的图形窗口
figure;
% 绘制非支配个体的目标函数值,用圆点表示
scatter(F_values(:, 1),F_values(:, 2),50,'r','filled');
% 设置 x 轴的标签
xlabel('f1');
% 设置 y 轴的标签
ylabel('f2');
% 设置图形的标题
title('MOEA/D - DE 算法得到的 Pareto 前沿');
function [f1, f2] = zdt1_objective(x, D)
% 第一个目标函数的值,直接取个体的第一个决策变量
f1 = x(1);
% 计算 ZDT1 函数中的中间变量 g
g = 1 + 9 * sum(x(2:end)) / (D - 1);
% 第二个目标函数的值
f2 = g * (1 - sqrt(f1 / g));
end 结果图
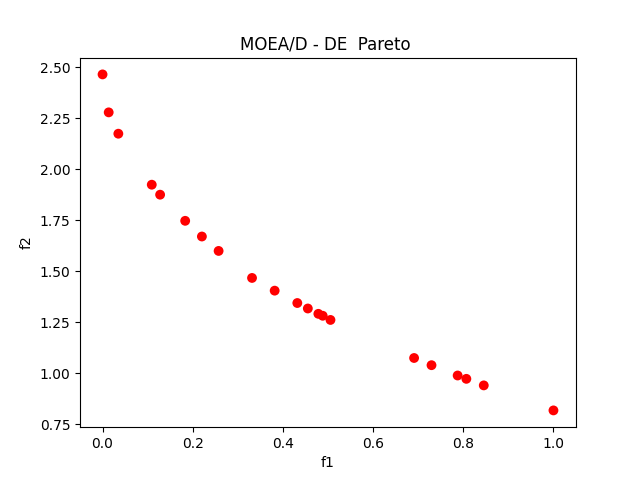
python代码
import numpy as np
import matplotlib.pyplot as plt
# 问题参数设置
M = 2 # 目标函数个数
D = 10 # 决策变量个数
N = 100 # 种群大小
T = 20 # 邻域大小
MaxGen = 500 # 最大迭代次数
F = 0.5 # 差分进化变异因子
CR = 0.9 # 差分进化交叉概率
# 定义目标函数
def zdt1_objective(x):
f1 = x[0]
g = 1 + 9 * np.sum(x[1:]) / (D - 1)
f2 = g * (1 - np.sqrt(f1 / g))
return f1, f2
# 生成权重向量
W = np.zeros((N, M))
if M == 2:
for i in range(N):
W[i, 0] = i / (N - 1)
W[i, 1] = 1 - W[i, 0]
else:
raise ValueError("目前仅支持二维目标空间的权重向量生成")
# 初始化种群
P = np.random.rand(N, D)
# 计算目标函数值
F_values = np.zeros((N, M))
for i in range(N):
f1, f2 = zdt1_objective(P[i])
F_values[i, 0] = f1
F_values[i, 1] = f2
# 确定邻域结构
B = np.zeros((N, T), dtype=int)
for i in range(N):
dist = np.sqrt(np.sum((W[i] - W) ** 2, axis=1))
idx = np.argsort(dist)
B[i] = idx[1:T + 1]
# 初始化理想点
z = np.min(F_values, axis=0)
# 迭代优化
for gen in range(MaxGen):
for i in range(N):
# 变异操作
r = np.random.permutation(T)[:3]
r1, r2, r3 = B[i, r]
V = P[r1] + F * (P[r2] - P[r3])
# 边界处理
V = np.clip(V, 0, 1)
# 交叉操作
U = P[i].copy()
jrand = np.random.randint(D)
for j in range(D):
if np.random.rand() <= CR or j == jrand:
U[j] = V[j]
# 计算目标函数值
f1, f2 = zdt1_objective(U)
U_F = np.array([f1, f2])
# 计算切比雪夫适应度值
g_tch_U = np.max(np.abs(U_F - z) * W[i])
# 更新邻域
for j in range(T):
k = B[i, j]
g_tch_P = np.max(np.abs(F_values[k] - z) * W[k])
if g_tch_U <= g_tch_P:
P[k] = U
F_values[k] = U_F
# 更新理想点
z = np.minimum(z, U_F)
# 归档
dominated = np.zeros(N, dtype=bool)
for i in range(N):
for j in range(N):
if i != j:
if np.all(F_values[i] >= F_values[j]) and np.any(F_values[i] > F_values[j]):
dominated[i] = True
break
F_values = F_values[~dominated]
P = P[~dominated]
unique_indices = np.unique(F_values, axis=0, return_index=True)[1]
F_values = F_values[unique_indices]
P = P[unique_indices]
# 绘制 Pareto 前沿
plt.figure()
plt.scatter(F_values[:, 0], F_values[:, 1], s=50, c='r', edgecolors='none')
plt.xlabel('f1')
plt.ylabel('f2')
plt.title('MOEA/D - DE Pareto ')
plt.show() 结果图