目录
效果一览

基本介绍
经典麻雀搜索算法+深度学习+多目标优化+多属性决策!SSA-CNN+NSGAII+熵权TOPSIS,附相关气泡图!本文旨在通过优化卷积神经网络(CNN)以及采用NSGAII多目标优化与熵权TOPSIS评价提升工艺参数优化的性能与效率。研究将借助麻雀搜索算法对CNN进行优化,通过调整批次数、初始学习率、正则化系数等关键参数,改善网络的学习效率和稳定性。在工艺参数优化方面,首先运用NSGAII算法进行多目标优化,该算法通过模拟自然选择过程,进行选择、交叉和变异操作,生成Pareto解集,以获得多个目标之间的平衡解。而后引入熵权TOPSIS决策方法,利用信息熵计算权重,减小主观因素对权重赋值的影响,依据优化方案与理想方案的接近程度进行排序,从而选出最优的工艺参数组合。这种综合方法有望为工艺参数实际优化应用提供有力支持。
经典麻雀搜索算法+深度学习+多目标优化+多属性决策!
SSA-CNN+NSGAII+熵权TOPSIS,附相关气泡图!matlab2023b语言运行!
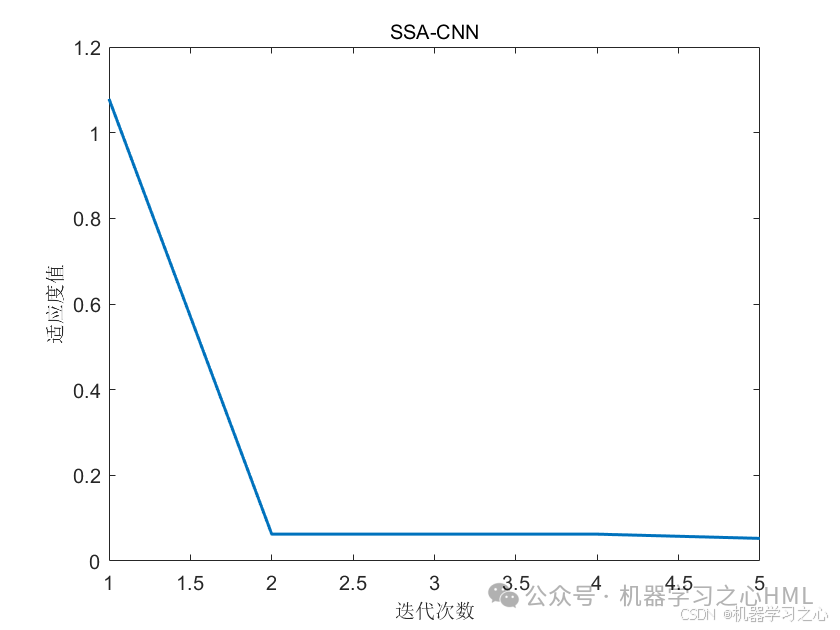
1.麻雀搜索算法(Sparrow Search Algorithm, SSA)是于2020年提出的。SSA 主要是受麻雀的觅食行为和反捕食行为的启发而提出的。该算法比较新颖,具有寻优能力强,收敛速度快的优点。
2.SSA-CNN+NSGAII+熵权TOPSIS,麻雀搜索算法优化卷积神经网络(优化批次数、初始学习率、正则化系数)+NSGAII+熵权TOPSIS工艺参数优化、工程设计优化!(Matlab完整源码和数据)
多目标优化是指在优化问题中同时考虑多个目标的优化过程。在多目标优化中,通常存在多个冲突的目标,即改善一个目标可能会导致另一个目标的恶化。因此,多目标优化的目标是找到一组解,这组解在多个目标下都是最优的,而不是仅仅优化单一目标。
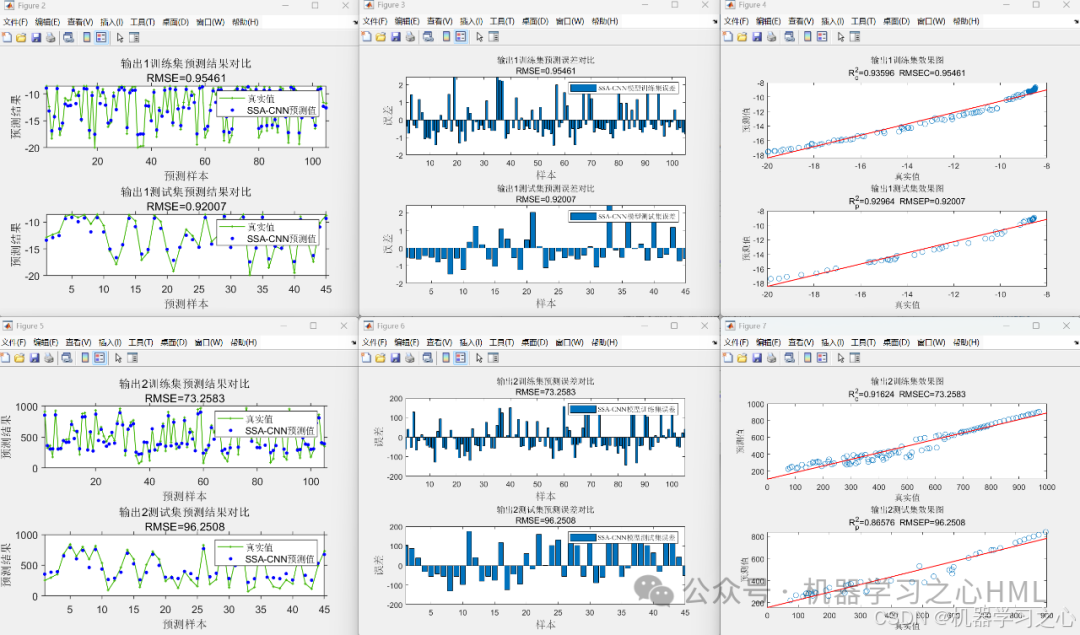
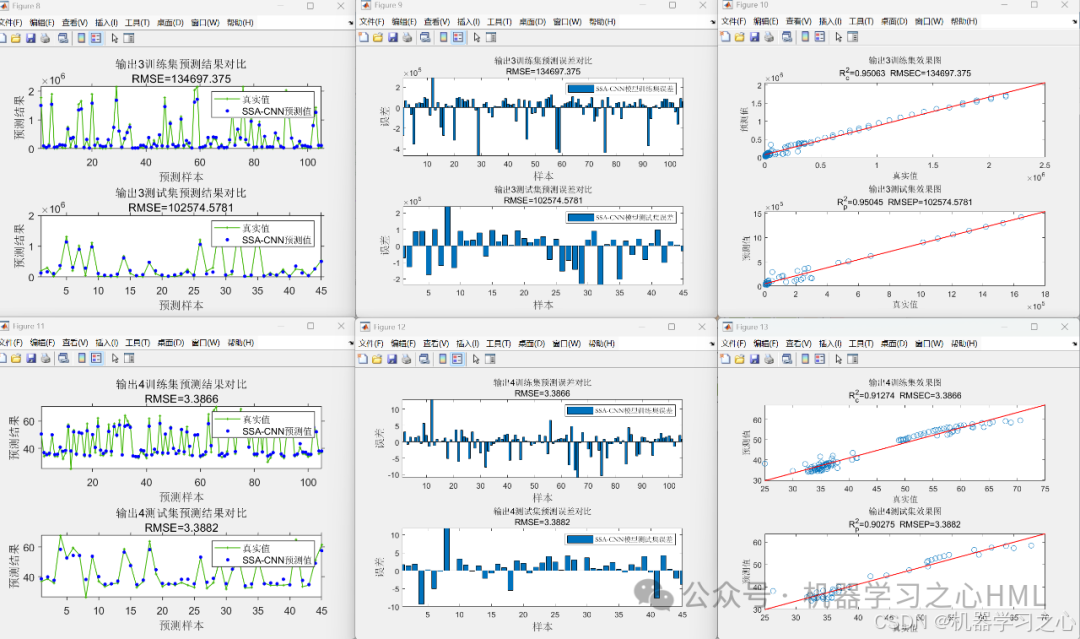
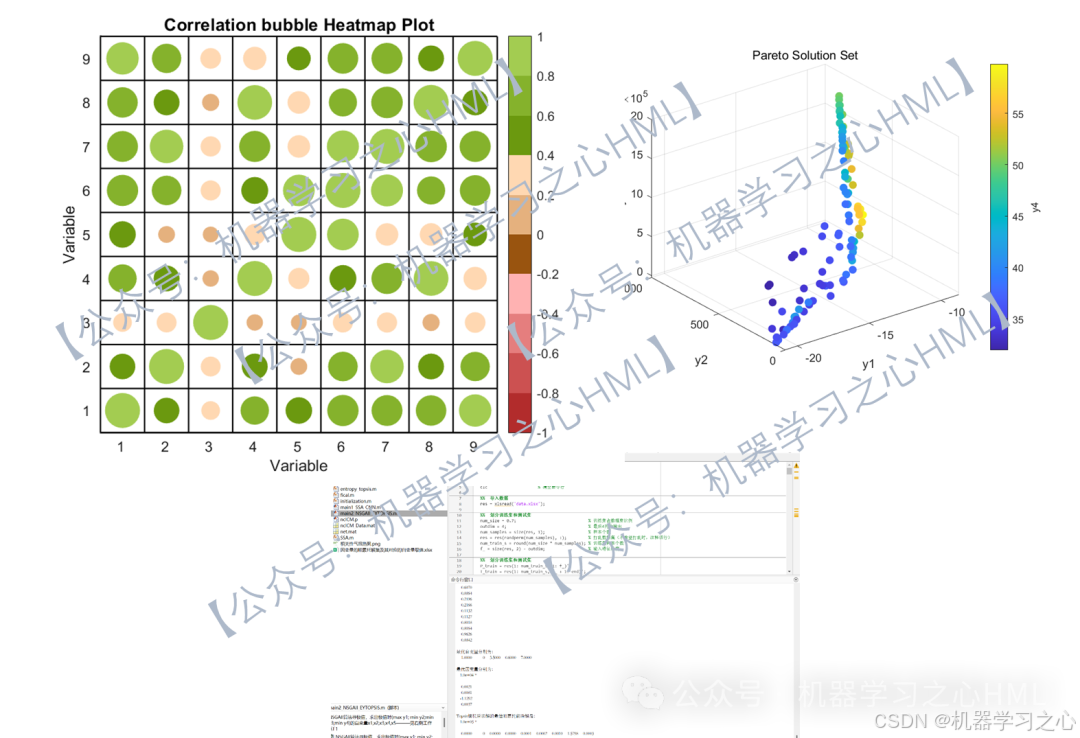
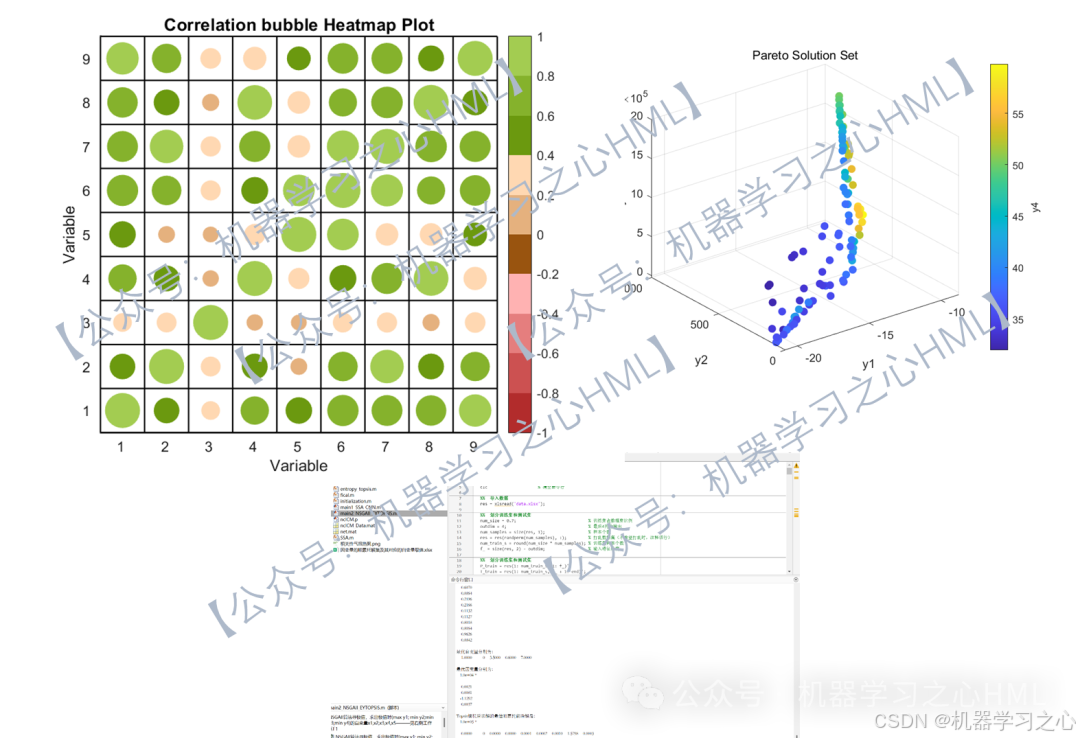
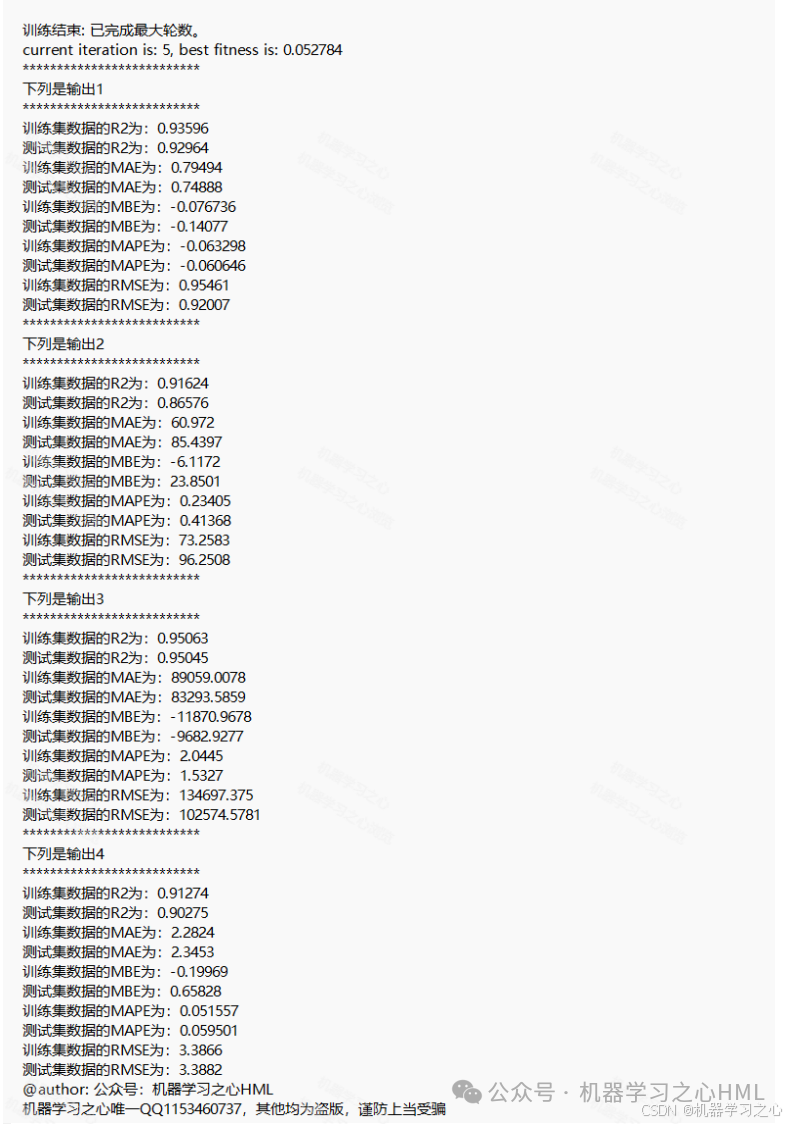
2.先通过SSA-CNN封装因变量(y1 y2 y3 y4)与自变量(x1 x2 x3 x4 x5)代理模型,再通过nsga2寻找y极值(y1极大;y2 y3 y4极小),并给出对应的x1 x2 x3 x4 x5Pareto解集,最后通过熵权TOPSIS求解的最佳帕累托前沿解(最优自变量,附加最优因变量)。
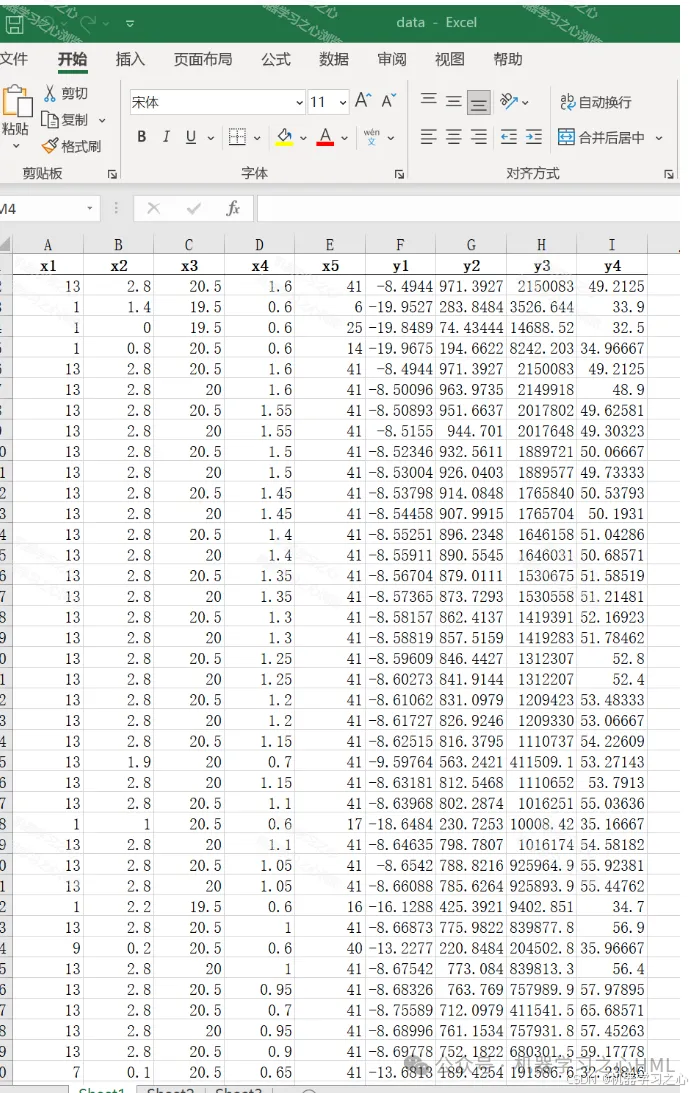
3.data为数据集,5个输入特征,4个输出变量,NSGAII算法寻极值,求出极值时(max y1; min y2;min y3;min y4)的自变量x1,x2,x3,x4,x5,最后通过熵权TOPSIS求解的最佳帕累托前沿解(最优自变量,附加最优因变量)。
4.main1.m为SSA-CNN主程序文件、main2.m为NSGAII+熵权TOPSIS主程序文件,依次运行即可,其余为函数文件,无需运行。
5.命令窗口输出R2、MAE、MBE、MAPE、RMSE等评价指标和最佳帕累托前沿解(最优自变量,附加最优因变量),输出相关性气泡图、预测对比图、误差分析图、决定系数图、多目标优化算法求解Pareto解集图,可在下载区获取数据和程序内容。
6.适合工艺参数优化、工程设计优化等最优特征组合领域。
NSGA-II算法的基本思想与技术路线
1) 随机产生规模为N的初始种群Pt,经过非支配排序、 选择、 交叉和变异, 产生子代种群Qt, 并将两个种群联合在一起形成大小为2N的种群Rt;
2)进行快速非支配排序, 同时对每个非支配层中的个体进行拥挤度计算, 根据非支配关系以及个体的拥挤度选取合适的个体组成新的父代种群Pt+1;
3) 通过遗传算法的基本操作产生新的子代种群Qt+1, 将Pt+1与Qt+1合并形成新的种群Rt, 重复以上操作, 直到满足程序结束的条件。

熵权TOPSIS法
Topsis优劣解距离法模型是一种常用的综合评价方法,能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。相对于层次分析法而言,Topsis法是解决决策层中数据已知的评价类模型。它可以解决多数据量的题目,数据计算简单易行。但对于各数据量之间的关系,我们需要使用熵权法或层次分析法来建立权重。熵权法的原理是指标的变异程度越小,所反映的信息量也越少,其对应的权值也应该越低。因此数据本身就告诉了我们权重。所以说熵权法是一种客观的方法。
数据集
程序设计
- 完整程序和数据获取方式:私信博主回复SSA-CNN+NSGAII+熵权TOPSIS,附相关气泡图,Matlab代码!(Matlab完整源码)。
matlab
%% 仿真测试
%% 数据反归一化
T_sim1 = mapminmax('reverse', t_sim1, ps_output);
T_sim2 = mapminmax('reverse', t_sim2, ps_output);
%% 定义结果存放模板
empty.position = []; %输入变量存放
empty.cost = []; %目标函数存放
empty.rank = []; % 非支配排序等级
empty.domination = []; %支配个体集合
empty.dominated = 0; %支配个体数目
empty.crowdingdistance = [];%个体聚集距离
pop = repmat(empty, npop, 1);
%% 1、初始化种群
for i = 1 : npop
pop(i).position = create_x(var); %产生输入变量(个体)
pop(i).cost = costfunction(pop(i).position);%计算目标函数
end
%% 2、构造非支配集
[pop,F] = nondominatedsort(pop);
%% 计算聚集距离
pop = calcrowdingdistance(pop,F);
%% 主程序(选择、交叉、变异)参考资料
深度学习工艺参数优化+酷炫相关性气泡图!CNN卷积神经网络+NSGAII多目标优化算法(Matlab完整源码)
工艺参数优化、工程设计优化!GRNN神经网络+NSGAII多目标优化算法(Matlab)
工艺参数优化、工程设计优化陪您跨年!RBF神经网络+NSGAII多目标优化算法(Matlab)
工艺参数优化、工程设计优化来袭!BP神经网络+NSGAII多目标优化算法(Matlab)
北大核心工艺参数优化!SAO-BP雪融算法优化BP神经网络+NSGAII多目标优化算法(Matlab)