🔍 开始你的图像分类之旅:一步一步学习 CIFAR-10 分类
图像分类是计算机视觉中最基础的任务之一,如果你是初学者,那么以 CIFAR-10 为训练场是一个不错的选择。本文一步一步带你从零开始,学习如何用深度学习模型实现图像分类。
一、CIFAR-10 数据集是什么?
CIFAR-10 是一个小型图像分类数据集,共包括 10 个类别:✈ 飞机(airplane)🚗 汽车(automobile)🐦 鸟(bird)🐱 猫(cat)🦌 鹿(deer)🐶 狗(dog)🐸 青蛙(frog)🐴 马(horse)🚢 船(ship)🚚 卡车(truck)
每张图片都是 32x32 的小图,有 RGB 三个颜色通道。
总共有 60000 张图,其中:
- 训练集: 50000 张
- 测试集: 10000 张
这些图片内容丰富,分辨率低,适合初学者练手。
二、模型训练的整体流程
我们用以下流程完成图像分类:
- 数据加载和预处理
- 构建模型(CNN)
- 设置损失函数和优化器
- 训练模型(前向 + 反向传播 + 更新参数)
- 测试模型效果
🧠 类比理解: 把整个过程比作"学会识别水果":
- 数据加载:收集不同水果的照片
- 模型:像是大脑处理这些图像的神经元网络
- 损失函数:告诉我们判断错误的严重程度
- 优化器:帮助我们不断修正错误,直到准确
三、数据加载和预处理
我们使用 PyTorch 中的 transforms 来将图片:
- 转换成 Tensor(张量)
- 正则化颜色值到 -1~1 之间,加快模型收敛
python
import torch
import torchvision
import torchvision.transforms as transforms
# 定义图像转换操作:将图片转换为 Tensor,并进行标准化
transform = transforms.Compose([
transforms.ToTensor(), # 将图片转为 Tensor 类型,方便计算
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 将图片标准化,均值和标准差都设为0.5
])
# 加载 CIFAR-10 训练数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
# 使用 DataLoader 进行批量加载数据,batch_size 是每次加载的图片数量
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True) # shuffle=True 表示打乱数据
# 加载 CIFAR-10 测试数据集
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64,
shuffle=False) # 测试集不需要打乱数据🎓 例子解释:
- 如果 batch_size=64,就意味着每次训练取 64 张图片
- shuffle=True 可以打乱图片顺序,防止模型记住顺序而不是学习特征
🍎 通俗类比:
- ToTensor 就像是把一张照片转成表格(数字表示颜色)
- Normalize 就像是统一标准,把所有颜色亮度调成统一区间,好比较
四、构建 CNN 模型
CNN(卷积神经网络)特别适合处理图像。我们构建一个简单 CNN 模型,包含:
- 两个卷积层 + ReLU 激活
- 两个最大池化层(缩小图片尺寸)
- 一个全连接隐藏层 + 一个输出层(10类)
python
import torch.nn as nn
import torch.nn.functional as F
# 定义简单的卷积神经网络
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
# 第一层卷积层,输入通道为3(RGB图像),输出通道为32,卷积核大小为3x3,padding=1 保证输出尺寸不变
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
# 最大池化层:2x2池化,用来减少图像尺寸
self.pool = nn.MaxPool2d(2, 2)
# 第二层卷积层,输入通道为32,输出通道为64
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
# 全连接层:将卷积层输出展平为一维向量,连接到一个128维的隐藏层
self.fc1 = nn.Linear(64 * 8 * 8, 128) # CIFAR-10图像尺寸32x32,经过两次池化后尺寸为8x8
# 输出层:10类,CIFAR-10数据集包含10个类别
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 第一层卷积 + ReLU 激活 + 池化
x = self.pool(F.relu(self.conv1(x)))
# 第二层卷积 + ReLU 激活 + 池化
x = self.pool(F.relu(self.conv2(x)))
# 展平特征图为一维向量,便于输入全连接层
x = x.view(-1, 64 * 8 * 8)
# 全连接层 + ReLU 激活
x = F.relu(self.fc1(x))
# 输出层,返回每个类别的预测概率
x = self.fc2(x)
return x📷 类比:
- 卷积操作就像"扫描照片"的滤镜,用来提取边缘、颜色块等图像特征
- 最大池化像是"缩略图",保留最显著的特征,减少计算量
五、设置损失函数和优化器
python
import torch.optim as optim
# 初始化模型并将其放到 GPU 或 CPU 上
model = SimpleCNN()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 损失函数:交叉熵损失函数,用于多分类问题
criterion = nn.CrossEntropyLoss()
# 优化器:Adam 优化器,适用于大部分情况,学习率设置为0.001
optimizer = optim.Adam(model.parameters(), lr=0.001)🧠 例子类比:
- 损失函数就像考试成绩:越高说明你错越多
- 优化器就像"老师指出你的错误"并教你怎么改正
📘 数值示例:
- 如果模型预测飞机的概率是 0.1, 0.05, ..., 0.7(第10类)
- 但真实标签是第1类(飞机),交叉熵损失会很大
- 优化器就会调整参数,使下一次飞机的概率尽量靠近第1类
六、训练模型:前向、反向、更新
python
# 训练过程:迭代多个 epoch,每个 epoch 会遍历所有训练数据
for epoch in range(10): # 总共训练 10 个 epoch
running_loss = 0.0 # 每个 epoch 初始化损失值为 0
for inputs, labels in trainloader: # 遍历每个 batch
inputs, labels = inputs.to(device), labels.to(device) # 将数据移到 GPU 或 CPU
optimizer.zero_grad() # 清除上一次的梯度
outputs = model(inputs) # 前向传播,得到每张图片的预测结果
loss = criterion(outputs, labels) # 计算损失值
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
running_loss += loss.item() # 累加损失值
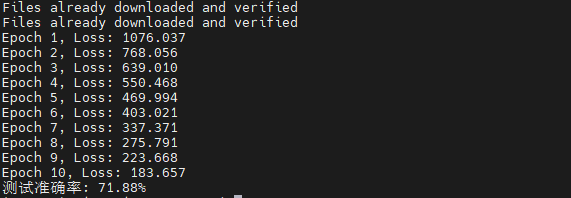
print(f"Epoch {epoch + 1}, Loss: {running_loss:.3f}") # 打印当前 epoch 的损失📐 具体数值例子:
- 模型初始权重是 0.3,预测错误 → loss = 2.5
- 反向传播算出权重梯度是 -0.8
- 学习率为 0.01,更新后权重 = 0.3 - 0.01 × (-0.8) = 0.308
七、测试模型效果
python
correct = 0 # 初始化正确预测的个数
total = 0 # 初始化总预测的个数
model.eval() # 设置模型为评估模式,关闭 Dropout 等训练时的特殊操作
with torch.no_grad(): # 在测试时,不需要计算梯度,减少计算量
for data in testloader: # 遍历测试集中的数据
images, labels = data
images, labels = images.to(device), labels.to(device) # 将数据移到 GPU 或 CPU
outputs = model(images) # 获取模型的输出
_, predicted = torch.max(outputs, 1) # 获取预测结果,torch.max 返回最大值和其索引,这里我们只取索引
total += labels.size(0) # 累加总的测试样本数量
correct += (predicted == labels).sum().item() # 统计预测正确的样本数量
print(f"测试准确率: {100 * correct / total:.2f}%") # 打印测试集上的准确率
📊 例子:
- 如果 total=10000,correct=7000,准确率就是 70%
🏁 完整代码快速运行包
python
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt # 添加matplotlib用于可视化
from matplotlib import rcParams # 用于设置字体
# 1. 数据加载与预处理
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为Tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化到[-1, 1]之间
])
# 加载训练集与测试集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False)
# 2. 定义模型:简单的CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
# 第一个卷积层:3个输入通道,32个输出通道,卷积核大小3x3,padding为1
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
# 最大池化层:2x2池化
self.pool = nn.MaxPool2d(2, 2)
# 第二个卷积层:32个输入通道,64个输出通道,卷积核大小3x3,padding为1
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
# 全连接层,输入大小64x8x8,输出128
self.fc1 = nn.Linear(64 * 8 * 8, 128)
# 最后一层全连接层,输出10个类别
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # 卷积+ReLU+池化
x = self.pool(F.relu(self.conv2(x))) # 卷积+ReLU+池化
x = x.view(-1, 64 * 8 * 8) # 展平数据,准备全连接
x = F.relu(self.fc1(x)) # 全连接+ReLU
x = self.fc2(x) # 最后一层输出
return x
# 3. 初始化模型、损失函数与优化器
model = SimpleCNN()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 判断是否使用GPU
model.to(device) # 将模型转移到GPU或CPU上
criterion = nn.CrossEntropyLoss() # 使用交叉熵作为损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器,学习率为0.001
# 4. 训练模型
for epoch in range(10): # 训练10个epoch
running_loss = 0.0
for inputs, labels in trainloader:
inputs, labels = inputs.to(device), labels.to(device) # 数据转移到GPU或CPU
optimizer.zero_grad() # 清除上一次的梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化器更新参数
running_loss += loss.item() # 累加损失
print(f"Epoch {epoch + 1}, Loss: {running_loss:.3f}") # 打印每个epoch的损失
# 5. 测试模型效果
correct = 0
total = 0
model.eval() # 将模型设置为评估模式
with torch.no_grad(): # 禁止计算梯度,提高效率
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device) # 数据转移到GPU或CPU
outputs = model(images)
_, predicted = torch.max(outputs, 1) # 获取最大概率的类别
total += labels.size(0) # 累加总样本数
correct += (predicted == labels).sum().item() # 统计正确的样本数
# 可视化一个批次的预测结果
plt.figure(figsize=(10, 10))
for i in range(8): # 显示前8张图片
plt.subplot(2, 4, i + 1)
plt.imshow(images[i].cpu().permute(1, 2, 0) * 0.5 + 0.5) # 反归一化并显示图片
plt.title(f"Label: {labels[i].item()}\nPrediction: {predicted[i].item()}")
plt.axis('off')
plt.show()
break # 仅显示一个批次
# 输出测试准确率
print(f"测试准确率: {100 * correct / total:.2f}%")你可以将以下内容保存为 train_cifar10.py 并运行:
python train_cifar10.py💡 不需要修改任何内容就能开始训练和测试!有 CUDA 就用 GPU,否则自动使用 CPU。