前言:本文是上一篇文章【数据结构】二叉树基本概念及堆的C语言模拟实现的补充,主要介绍的是两种建队方式分别为向上调整建堆和向下从叶子结点的父结点开始向下调整建队的时间复杂度分析和堆的经典应用场景TOP-K问题
1.两种建堆方式
场景:给我们一个数组,数组里面有N个元素要求我们让通过向上调整算法或者向下调整算法把这个数组变成一个堆
这里先说结论是从叶子结点的父结点开始从下往上分别执行向下调整建堆的方式更好,如果像我们模拟堆插入元素那样向上调整建堆的话它的时间复杂度是O(N * log N)而向下调整建队的时间复杂度是O(N)的时间复杂度,那为什么要介绍向上调整建堆呢?是因为直接介绍向下调整建堆的话不好理解为什么要这样建,所以我这里就先介绍更容易理解的向上调整建堆来所为引子。
1.1向上调整建堆
开头那篇文章里模拟堆部分我们写过一个函数来模拟堆的插入:
cpp
void AdjustUp(HeapDataType* a, int n)
{
int child = n;
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent])
{
Sawp(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void HpPush(HP* php, HeapDataType x)
{
assert(php);
if (php->capacity == php->size)
{
int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;
HeapDataType* tem = (HeapDataType*)realloc(php->a, sizeof(HeapDataType) * newcapacity);
if (tem == NULL)
{
perror("malloc fail !");
return;
}
php->a = tem;
php->capacity = newcapacity;
}
php->a[php->size] = x;
php->size++;
AdjustUp(php->a, php->size - 1);
}向上调整建堆其实就是和堆插入一样的,遍历一遍数组一个个的插入新元素通过向上调整算法来建堆:
cpp
int a[] = { 2, 5, 1, 3, 7, 8, 10, 0 };
int n = sizeof(a) / sizeof(int);
for (int i = 1; i < n; i++)
{
AdjustUp(a, i);
}经过我们前面的学习我其实是非常符合我们的直觉和理解的,我这里就不多说了重点在后面那个方式
1.2向下调整建堆
回忆我们之前写的向下调整算法,我们是在堆中删除元素才用的为什么可以用来建堆呢?我们可以换一个角度来看,无论是向上调整算法还是向下调整算法我们都是以维护这堆为目的而使用这些算法的,既然它们都有维护堆的作用那也同样可以在创建堆时使用。
函数:
cpp
void AdjustDown(HeapDataType* a, int prent, int n)
{
int child = prent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child + 1] < a[child])//先判断是否越界
{
child++;
}
if (a[child] < a[prent])
{
Sawp(&a[child], &a[prent]);
prent = child;
child = prent * 2 + 1;
}
else
{
break;
}
}
}
void HpPop(HP* php)
{
assert(php);
assert(php->size > 0);
Sawp(&php->a[php->size - 1], &php->a[0]);
php->size--;
AdjustDown(php->a, 0, php->size);
}在堆中删除元素时我们是先交换首尾的元素才能使用使用向下调整算法,这是因为在元素交换后,原来结点的左子树和右子树本来就是合法的大根堆或者小根堆。可是我们在创建堆时我们是不能确定左右子树是否合法的,所以我们可以转换一下思路,既然需要左右子树合法那我们从树的下面开始使用向下调整算法呢?
因为叶子结点都没有左右子树,所以这些结点无论这棵树是大根堆还是小根堆都可以作为根节点,所以我们可以从这些叶子结点的父结点开始使用向下调整算法,当这层父结点合法了之后再依次向上执行向下调整算法就可以一直保持左右子树是合法的。这里我们以个数组创建一个小根堆为例子来模拟过程:
cpp
int a[] = { 2, 1, 3, 5, 7, 0, 23, 54, 12 };画图:
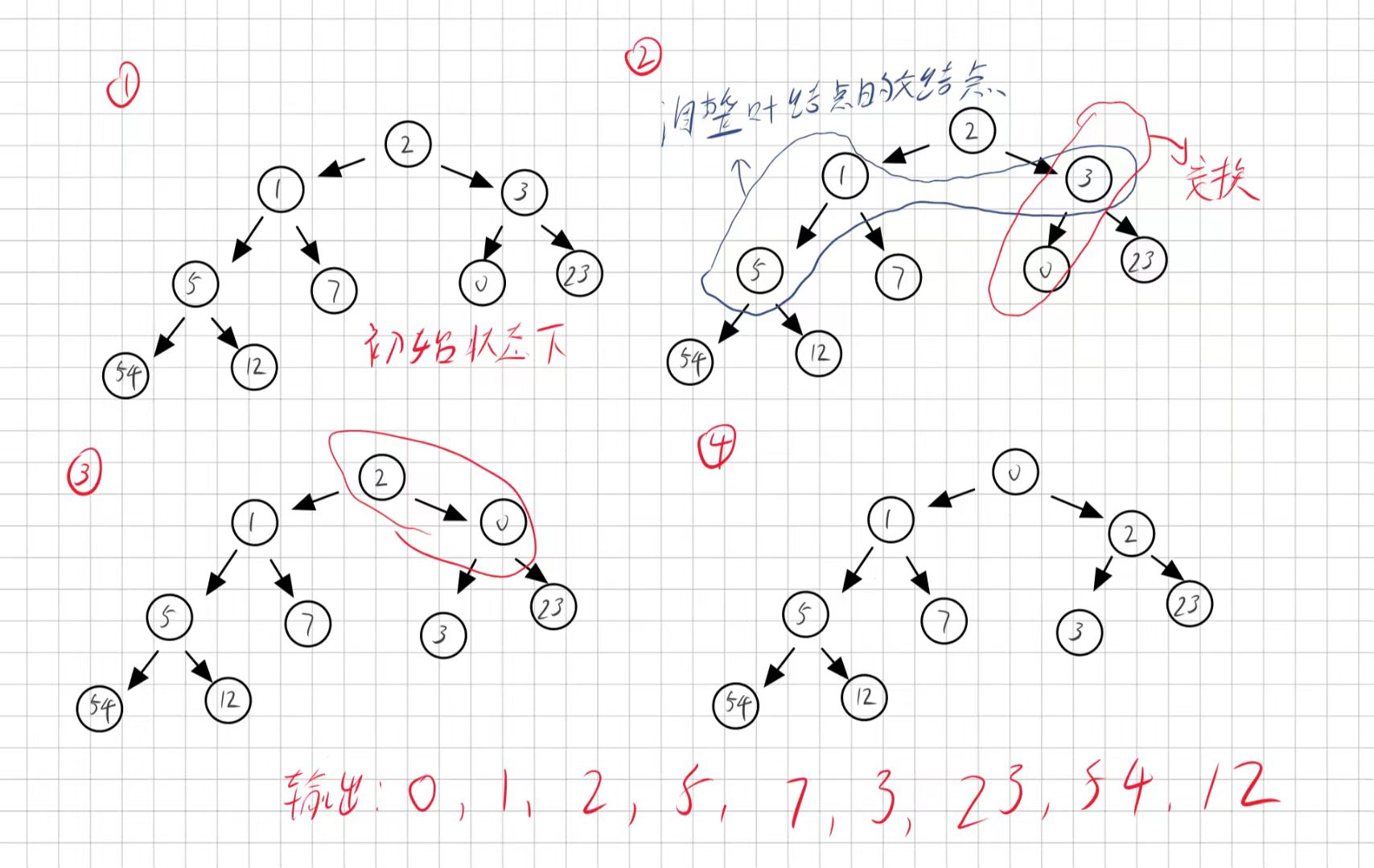
我们运行下面这个程序验证一下我们的推理结果:
cpp
HeapSort(int *a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, i, n);
}
//int end = n - 1;
//while (end > 0)
//{
// Sawp(&a[0], &a[end]);
// AdjustDown(a, 0, end);
// end--;
//}
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
}程序输出:
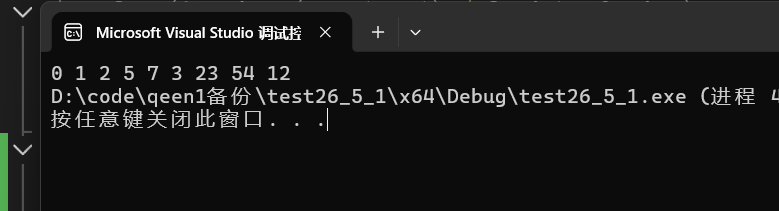
完全符合我们的预期证明这种建堆方法也是可行的
2.两种方法时间复杂度分析
场景:我们这里有一颗这样的二叉树:
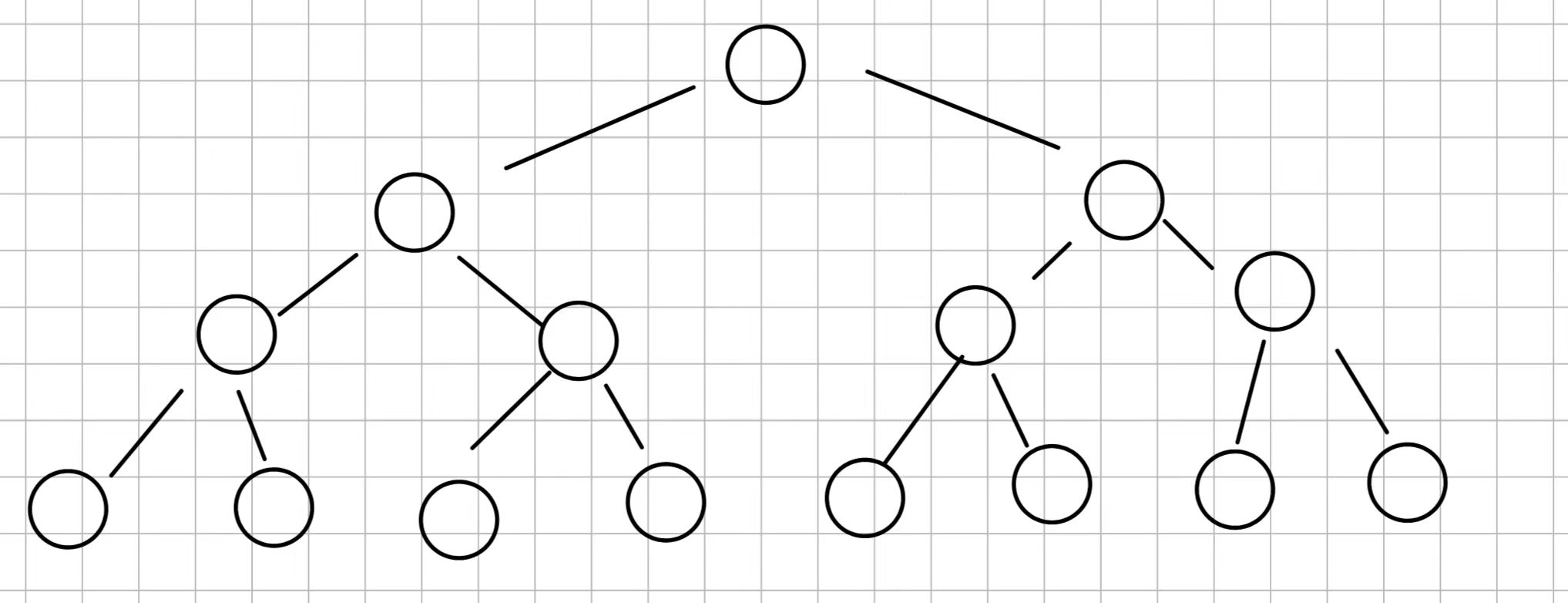
树的高度统一为 h 、结点的数量统一为N。
我们可以通过高中学过的数列公式来推到时间复杂度(高中的知识在攻击我。。。)
2.1向上调整建堆时间复杂度
根据向上调整算法我吗可以知道每层元素在进入堆时对应的需要调整次数:
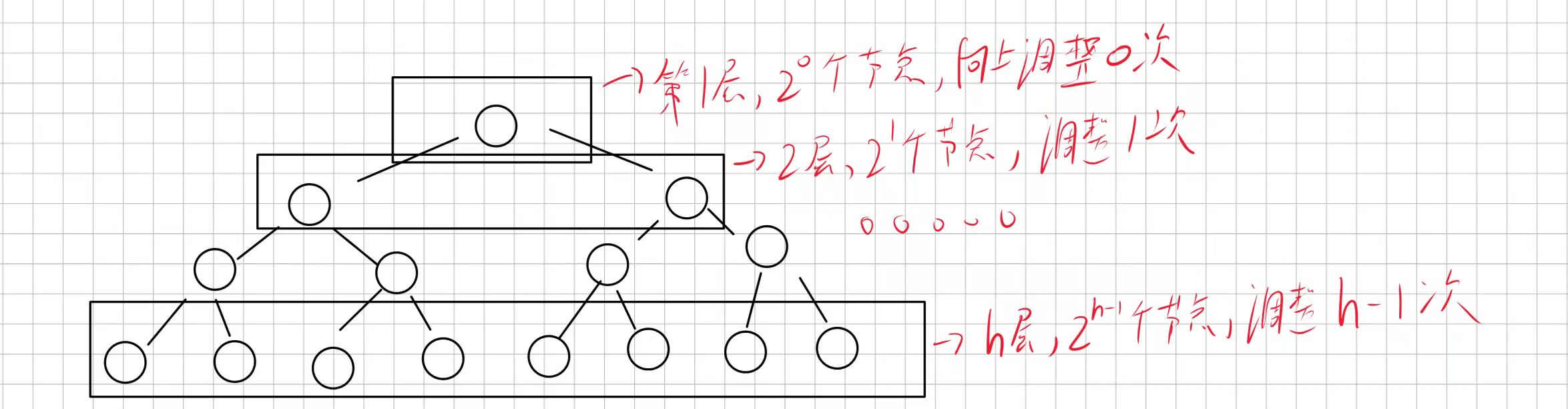
因此我们可以得出N个元素调整的总次数公式T(N):
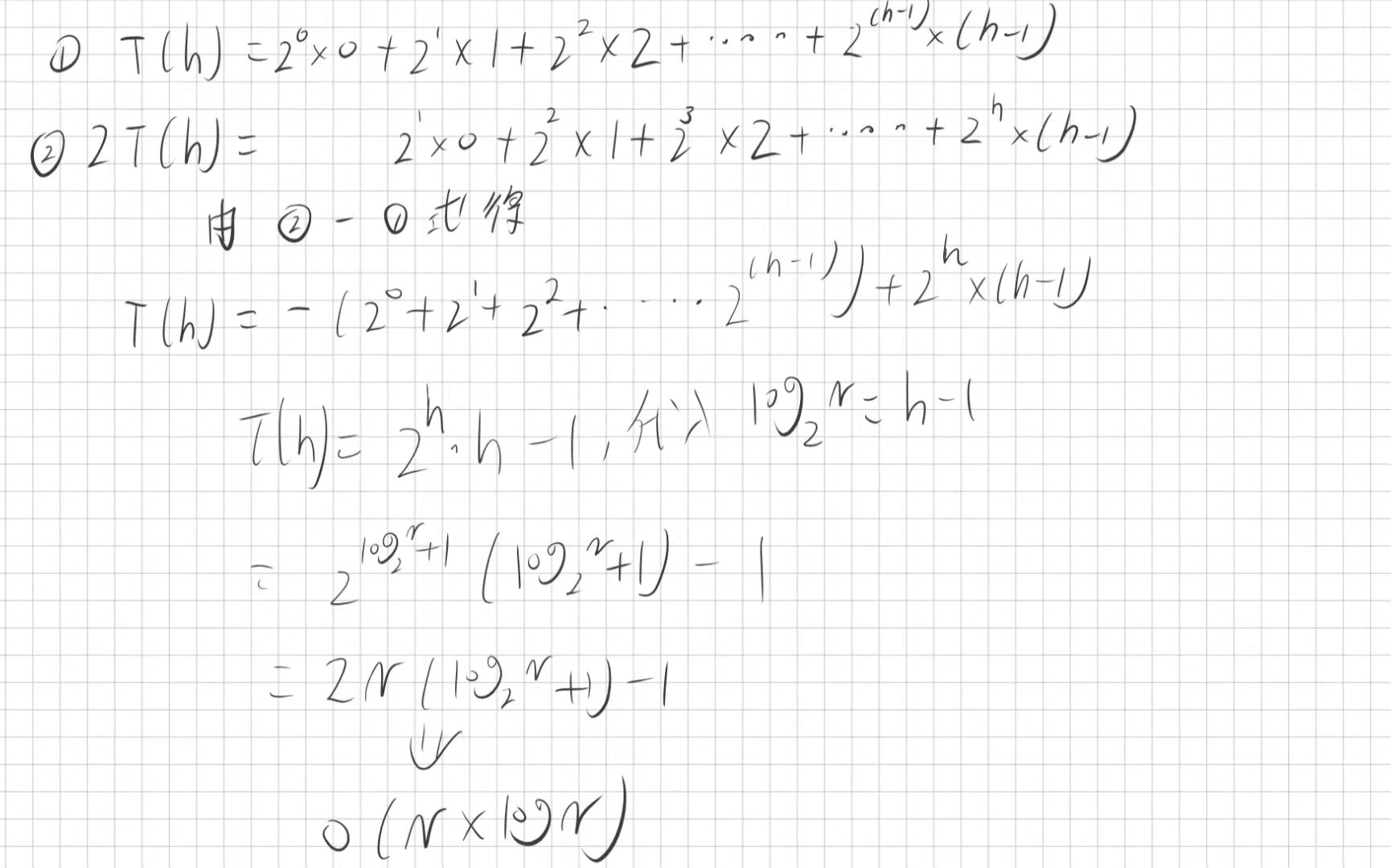
这个是利用以前学过的错位相减法来证明的,这样就证明了用向上调整法来建堆是O(N * longN)的时间复杂度,就是不是一颗满二叉树也是一样的方法同样是可以时间复杂度感兴趣可以自己来证明看看,只需要假设最后一层只有一个结点即可
2.2向下调整建堆时间复杂度
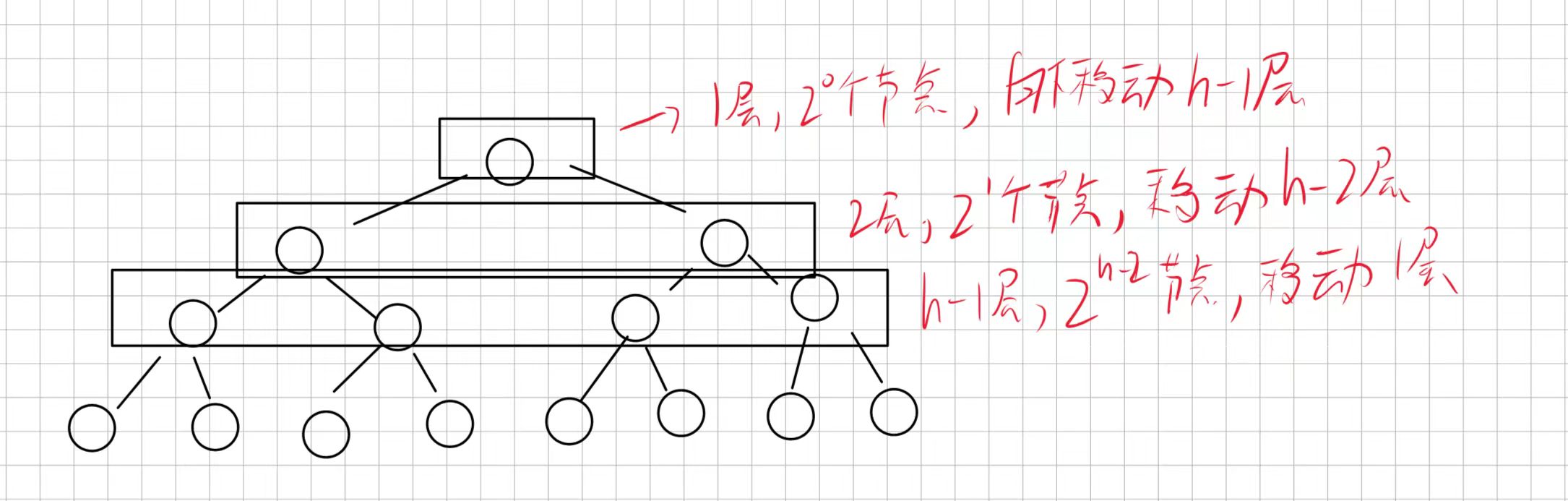
其实这里就可以看出来这个方法的优越性了,因为它执行总次数是多乘少的,而上面的向上调整建堆是多乘多。
还是相同的计算方法来算出总次数T(N):
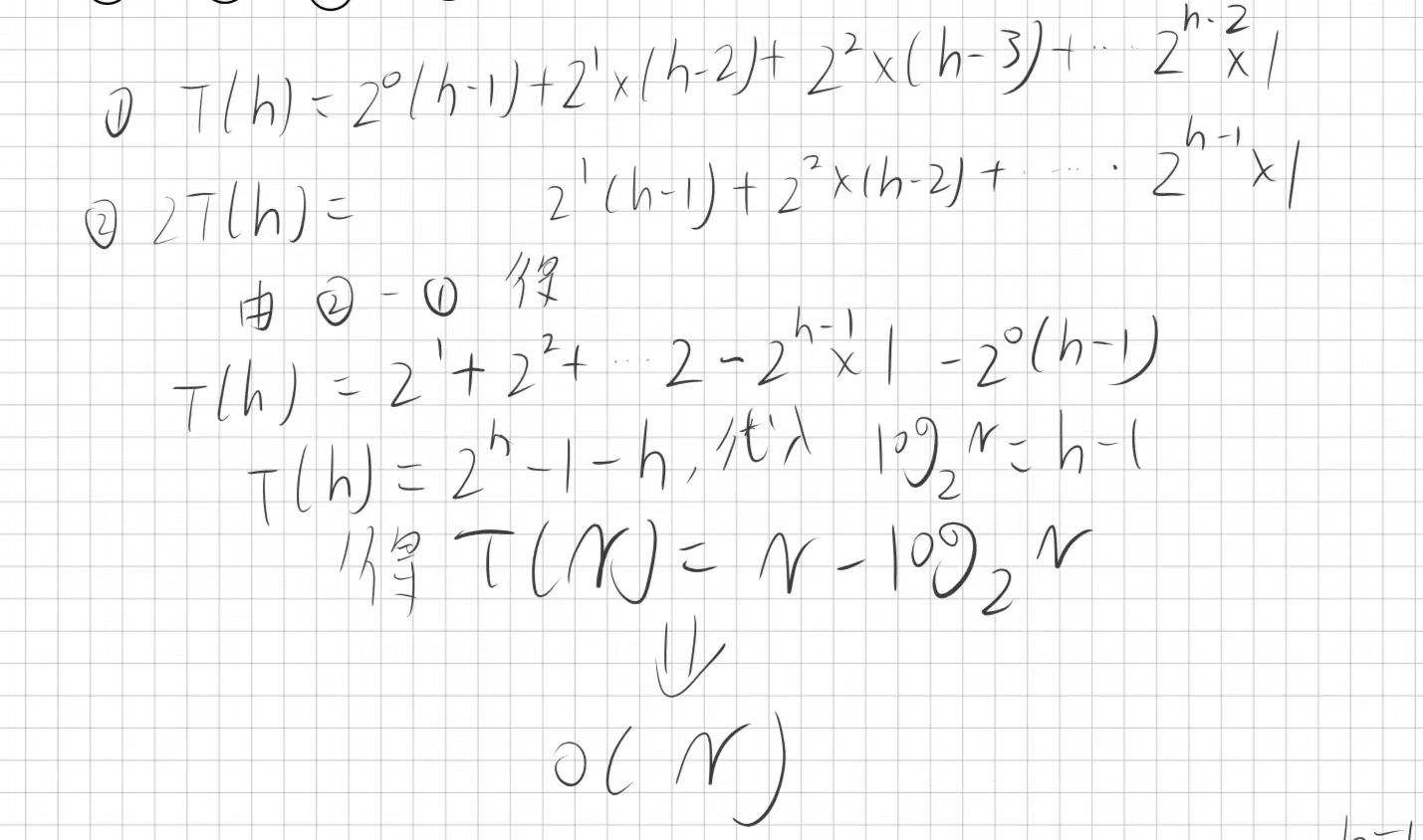
还是用的错位相减法证明出来的,因此向下调整建堆更加的优秀只有O(N)的时间复杂度。
3.TOP-K问题
我们打游戏时往往又会什么各种各样的排行榜,比如王者农药的英雄战力排行榜。而这个排行榜的数据是不断的随着玩家游玩不断刷新的,我们都真的像王者农药这种国民游戏是有千万甚至上亿的玩家的,那我们该如何在这么庞大的玩家群体中快速找出战力前白的玩家呢?
当然我都把这个问题放这里了当然是用堆了,原理就不多说了开头那篇文章就有原理的介绍。但是还有一个问题就是当玩家的数据量如此大我们不可能把这么大的堆加载入内存中,要不看一下排行榜手机就炸了也太难绷了,那我们该如何解决这个问题呢?
我们假设每个玩家会产生一个整形的数据大小(实际不可能这么小)假设这个游戏有12亿的玩家总数
cpp
// 1G == 1024MB == 1024 * 1024KB == 1024 * 1024 * 1024 BYTE那数据的大小大概为4.47个G这明显是不现实的,而且现在的内存这么贵。。。
但是这点数据量对于硬盘来说是不值一提的,假如我们要选出前k个大的数据,我们可以在内存中创建一个k大小的小根堆,然后再读取外存中的数据,当读取到的数据比这个小根堆的堆顶元素要大时我们就替换掉这个堆顶元素,更大的元素就会沉入下面,这样就成功的选出了前k个最大(或者最小)数而且对内存的占用几乎是可以忽略的。
比如这我创建了10000个大小小于1000000的随机数据:
cpp
void CreateNDate()
{
int n = 10000;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (size_t i = 0; i < n; ++i)
{
int x = rand() % 1000000;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}我想取出前5个大的数,我手动的修改data.txt文件的5个数让它大于1000000我们来看看这个堆能不能帮我们完成任务:
cpp
void PrintTopK()
{
int k = 0;
printf("请输入k->");
scanf("%d", &k);
int* kminheap = (int*)malloc(sizeof(int) * k);
if (kminheap == NULL)
{
perror("malloc fail !");
return;
}
const char* file = "data.txt";
FILE* fout = fopen(file, "r");
if (fout == NULL)
{
perror("fopen fail !");
return;
}
for (int i = 0; i < k; i++)
{
fscanf(fout, "%d", &kminheap[i]);
}
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(kminheap, i, k);
}
int x = 0;
while (fscanf(fout, "%d", &x) > 0)
{
if (x > kminheap[0])
{
kminheap[0] = x;
AdjustDown(kminheap, 0, k);
}
}
printf("最大的前k个数:\n");
for (int i = 0; i < k; i++)
{
printf("%d ", kminheap[i]);
}
}修改的数:
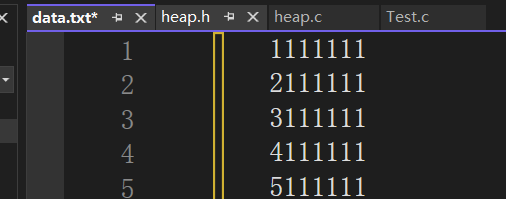
我们运行程序:
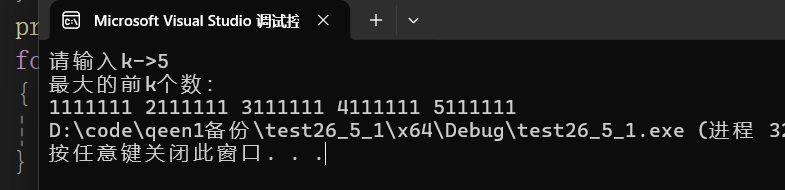
这个程序完全的帮我们完成了任务
完