目录
[1 HDFS核心架构回顾](#1 HDFS核心架构回顾)
[2 HDFS与YARN的集成](#2 HDFS与YARN的集成)
[3 HDFS与MapReduce的协同](#3 HDFS与MapReduce的协同)
[4 HDFS与Hive的集成](#4 HDFS与Hive的集成)
[4.1 Hive架构与HDFS交互](#4.1 Hive架构与HDFS交互)
[4.2 Hive数据组织](#4.2 Hive数据组织)
[4.3 Hive查询执行流程](#4.3 Hive查询执行流程)
[5 HDFS在生态系统中的核心作用](#5 HDFS在生态系统中的核心作用)
[6 性能优化实践](#6 性能优化实践)
[7 总结](#7 总结)
引言
在大数据领域,Hadoop生态系统已经成为处理海量数据的首选框架。作为这个生态系统的基石,HDFS(Hadoop Distributed File System)与其他关键组件如YARN、MapReduce和Hive的紧密集成,构成了一个强大而灵活的大数据处理平台。
1 HDFS核心架构回顾
HDFS是一个高度容错的分布式文件系统,专为运行在廉价硬件上的大规模数据集而设计。其核心架构遵循主从模式:
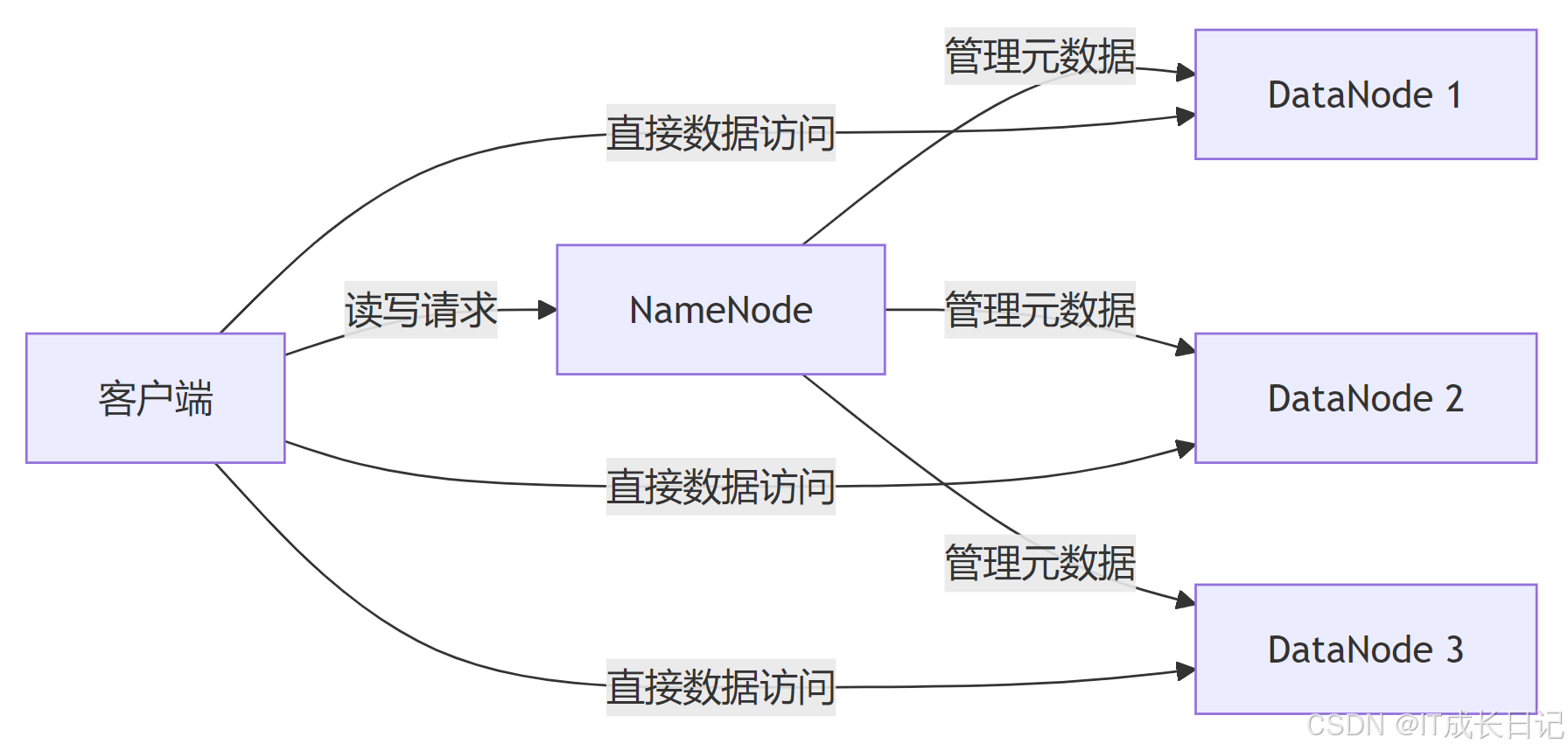
NameNode:管理文件系统的命名空间和客户端对文件的访问
DataNode:存储实际数据块并执行块的读写操作
Secondary NameNode:定期合并命名空间镜像和编辑日志(图中未显示)
2 HDFS与YARN的集成
YARN(Yet Another Resource Negotiator)是Hadoop的资源管理框架,负责集群资源的管理和调度。HDFS与YARN的集成主要体现在资源管理和数据本地化方面。
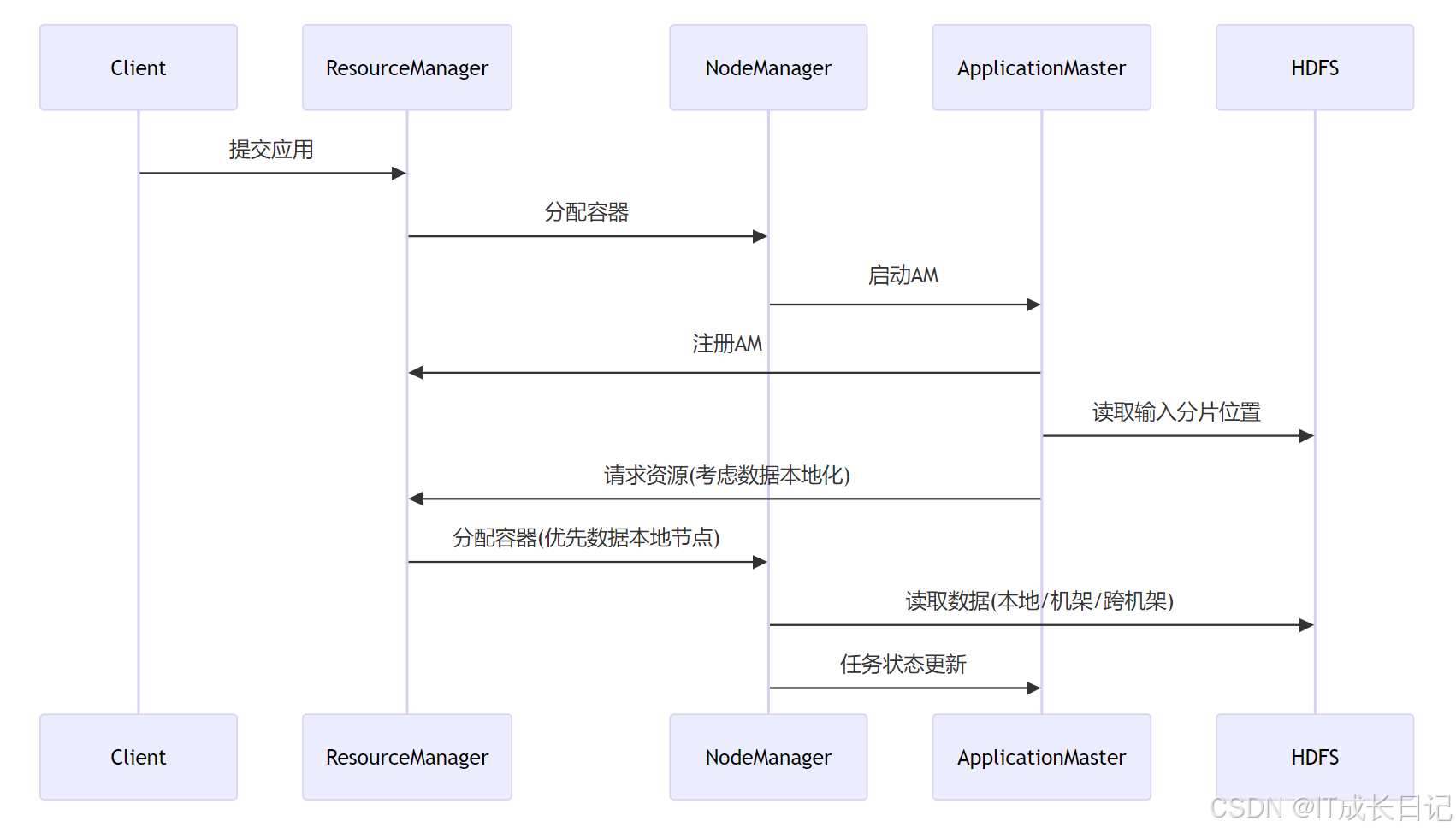
- 数据本地化:YARN调度器会尽量将任务分配到存储有所需数据块的节点上,减少网络传输
- 资源分配:YARN根据HDFS数据分布情况优化资源分配
- 容错机制:任务失败时,YARN会重新调度,HDFS确保数据可靠性
3 HDFS与MapReduce的协同
MapReduce是Hadoop的原始处理模型,它与HDFS的集成体现了"移动计算比移动数据更便宜"的理念。

- 详细工作阶段
输入阶段:
- InputFormat从HDFS读取数据并生成分片(Splits)
- 每个分片对应一个Map任务
Map阶段:- Map任务在存储有输入数据的节点上执行(数据本地化)
- 处理后的中间结果写入本地磁盘
Shuffle阶段:- 中间结果按照键分区并传输到Reducer节点
Reduce阶段:- 对中间结果进行聚合处理
- 最终输出写回HDFS
4 HDFS与Hive的集成
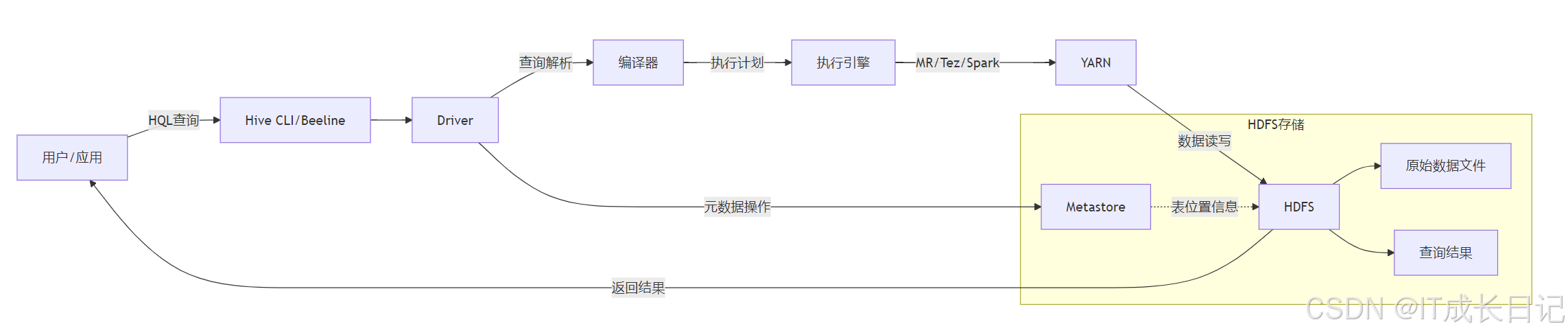
Hive是构建在Hadoop上的数据仓库基础设施,它提供了SQL-like查询语言(HQL)并将查询转换为MapReduce/Tez/Spark作业。
4.1 Hive架构与HDFS交互
4.2 Hive数据组织
/user/hive/warehouse/
├── db1.db
│ ├── table1
│ │ ├── file1.orc
│ │ ├── file2.orc
│ ├── table2
│ ├── part1
│ │ ├── file1.parquet
├── db2.db
├── ...4.3 Hive查询执行流程
解析与编译:
- HiveQL查询被解析为抽象语法树(AST)
- 类型检查和语义分析
- 生成逻辑执行计划
优化:- 应用谓词下推、分区裁剪等优化规则
- 生成物理执行计划
执行:- 转换为MapReduce/Tez/Spark作业
- 通过YARN调度执行
- 从HDFS读取输入数据
- 将结果写回HDFS
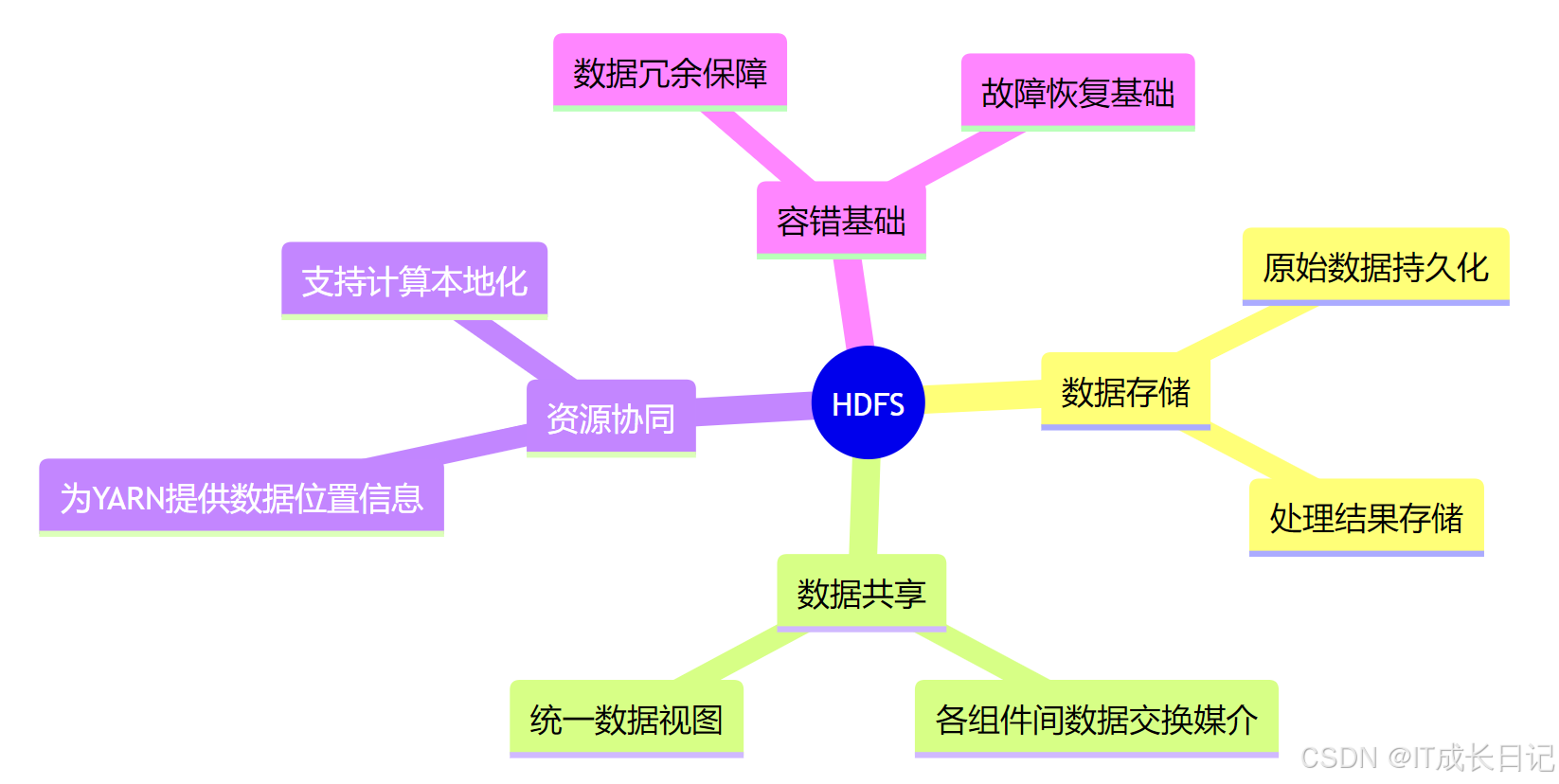
5 HDFS在生态系统中的核心作用
通过上述集成分析,我们可以看到HDFS在整个Hadoop生态系统中扮演着关键角色:
6 性能优化实践
基于HDFS集成的优化策略:
数据本地化优化:
- 合理设置HDFS块大小(通常128MB-256MB)
- 确保集群节点同时运行DataNode和NodeManager
存储格式选择:- 针对Hive表使用列式存储(ORC/Parquet)
- 压缩中间数据(Snappy/LZO)
资源调优:- 平衡HDFS和YARN资源分配
- 配置适当的Map/Reduce任务数
7 总结
HDFS作为Hadoop生态系统的存储基石,通过与YARN、MapReduce和Hive的深度集成,构建了一个完整的大数据处理平台。这种集成不仅实现了数据的高效存储和访问,还通过数据本地化等机制显著提高了处理效率。理解这些组件间的协同工作原理,对于设计和优化大数据应用至关重要。