一.配置主机名
1.查看自己服务器ip输入命令:ifconfig
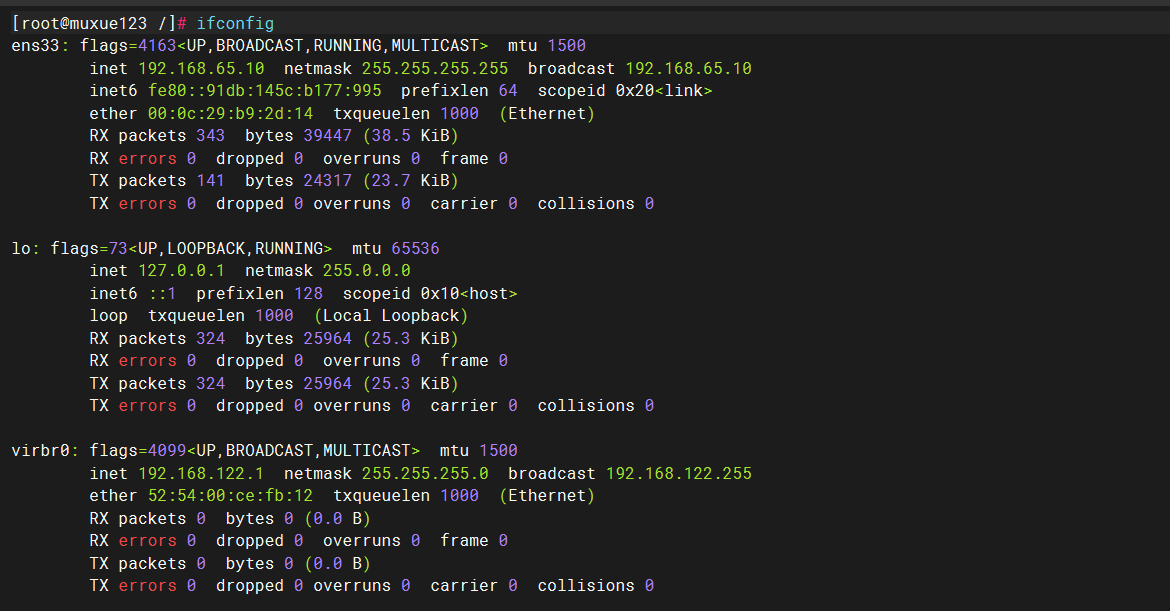
给服务配置一个主机名,这样后面在访问的时候只需要通过主机名而不是 IP 了
|----|--------|-----------|
| 序号 | 主机名称 | IP |
| 1 | master | 设置自己的主机ip |
2.修改主机名在,服务器上执行命令如下:
bash
hostnamectl set-hostname master #将主机名改为master3.配置 IP 和主机名称之间的映射,要想通过主机名识别服务器还需要配置IP和主机名之间的映射关系,执行如下指令对 IP 映射文件 hosts进行编辑。
bash
vim /etc/host添加以下内容:
bash
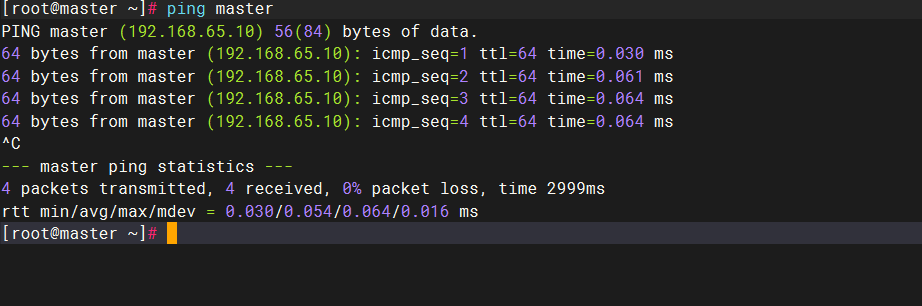
192.168.65.10 master4.reboot重启虚拟机通过ping命令ping master显示通即成功:
二. 配置免密登录
在集群开发中,节点之间通常会对集群中其他节点频繁地访问,就需要不断输入目标服务器的用户名和密码,这种操作方式非常麻烦并且还会影响集群服务的连续运行。为了解决上述问题,可以通过配置SSH 实现服务之间的免密登录功能。
这里,我们只需要配置master到master自己,在master中生成公钥私钥对,将master上的公钥拷贝到master自己。
1.在master服务器上生成公钥私钥对,执行如下命令:
bash
ssh-keygen -t rsa #4个回车生成公钥、私钥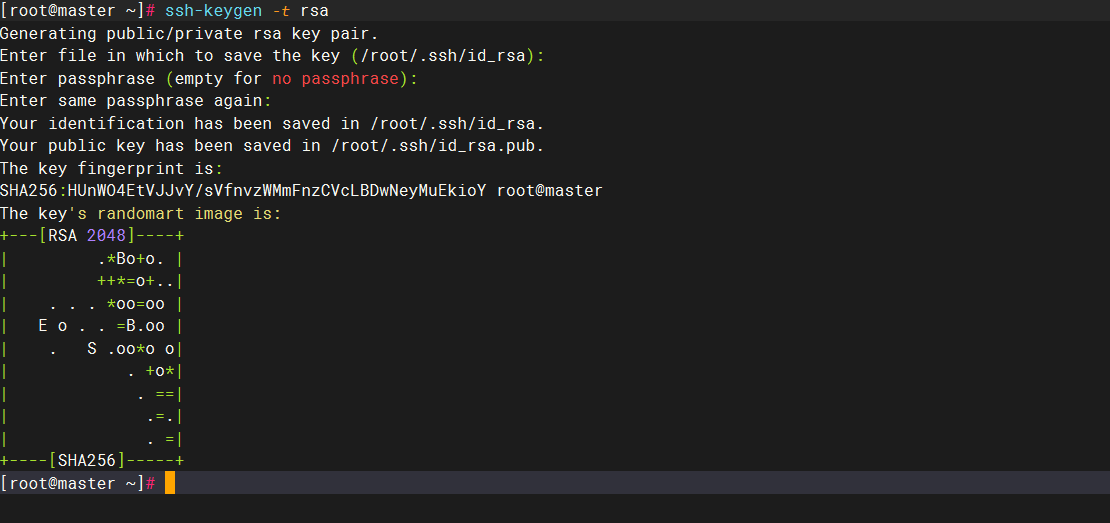
2.在master上将公钥拷贝到自己master,执行如下命令
bash
ssh-copy-id master
3.完成上述配置后,我们可以选择启动master服务器进行免密测试:
bash
ssh master #通过ssh访问master看看是否需要输入密码?
直接登录不需要输入密码即代表配置成功。
三. 关闭防火墙
1.为了方便内部服务之间相互访问,建议将master服务器的防火墙关闭。在master服务器上执行命令如下:
bash
systemctl stop firewalld #关闭防火墙
systemctl disable firewalld #防止防火墙自启
2.配置java环境
1.配置 JDK
由于 Hadoop 是由 Java 语言开发的,Hadoop 集群的使用依赖于 Java 环境,因此在安装 Hadoop 集群前,需要先安装并配置好 JDK。接下来,就在前面规划的 Hadoop 集群主节点master机器上分步骤演示如何安装和配置 JDK。
查看系统已有的JDK执行:
bash
rpm -qa | grep java #查询系统中存在的JDK相关的包有的话建议删除执行:
bash
rpm -e --nodeps rpm包名出现空白即代表删除彻底:

2.准备JDK文件
为了规范后续 Hadoop 集群相关软件和数据的安装配置,这里在虚拟机的根目录下创建一些文件夹作为约定提示:
bash
mkdir -p /opt/data #数据存储路径
mkdir -p /opt/module #软件安装路径3.解压 JDK
接着,将安装包解压到/opt/module/目录,具体指令如下:
bash
cd /opt/software #切换工作目录
tar zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/ #将jdk源文件解压到/opt/module完成后,到/opt/module目录下会看到解压后的文件

4.配置环境变量安装完 JDK 后,还需要配置 JDK 环境变量,在/etc/profile.d目录下创建一个新的文件my_env.sh
bash
vim /etc/profile.d/my_env.sh #编辑文件在该文件中添加如下内容:
bash
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin修改完成后执行以下命令生效环境变量:
bash
source /etc/profile5.在完成 JDK 的安装和配置后,为了检测安装效果,可以输入如下指令进行验证:
bash
java -version
到这里,我们已经完成了master服务器上的 JDK 配置。