Connectionist Temporal Classification|CTC
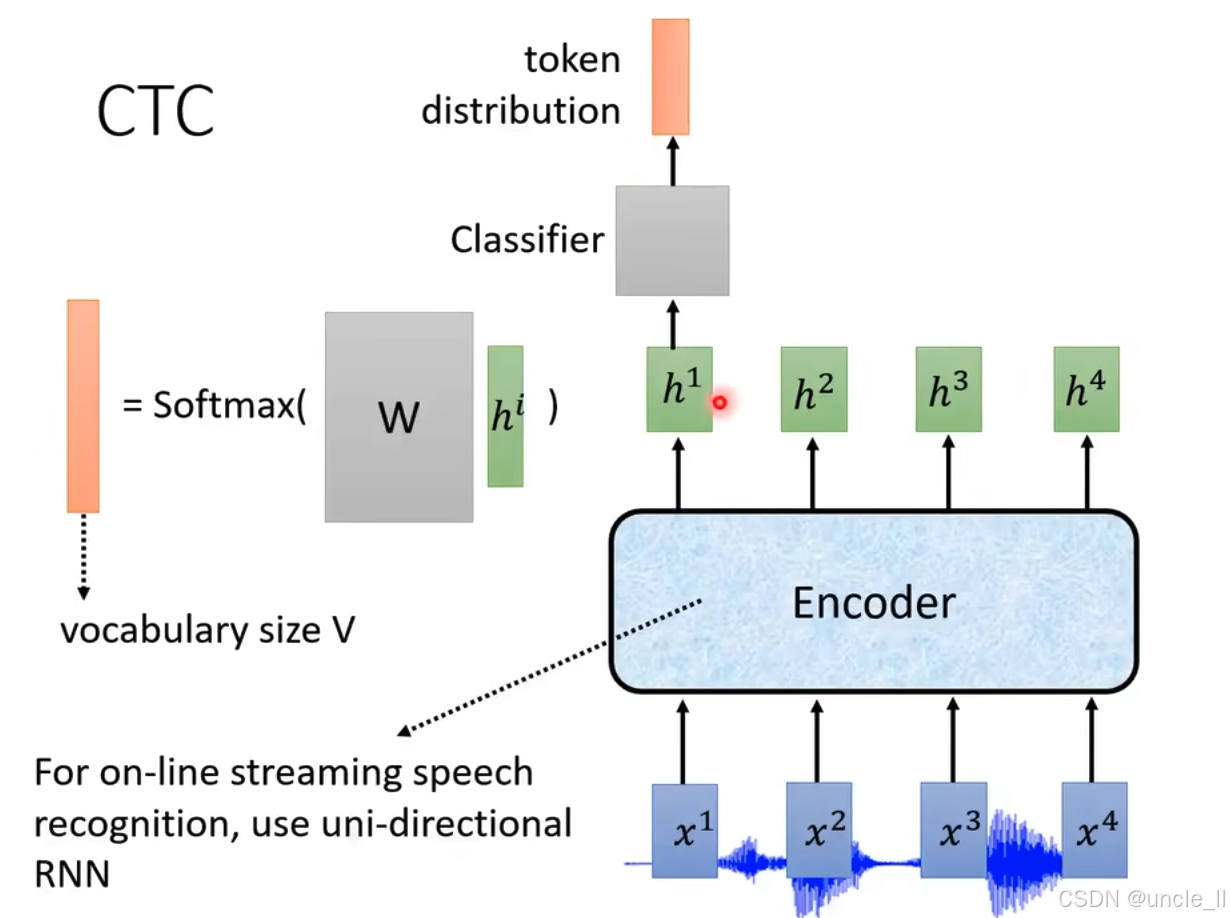
基于连接主义时间分类(CTC)的语音识别架构,具体描述如下:
- 输入层 :底部的 x 1 , x 2 , x 3 , x 4 x^1, x^2, x^3, x^4 x1,x2,x3,x4代表输入的语音信号分帧数据,是语音识别的原始输入。
- 编码器(Encoder) :浅蓝色模块表示编码器(如循环神经网络 RNN),负责对输入的语音帧 x i x^i xi 进行特征提取和时序建模,输出隐藏状态 h 1 , h 2 , h 3 , h 4 h^1, h^2, h^3, h^4 h1,h2,h3,h4。
- 分类器(Classifier) :每个隐藏状态 h i h^i hi输入到分类器(灰色模块),通过矩阵 W W W 线性变换后,再经过 Softmax 函数,生成词汇表 V V V 大小的概率分布( token distribution \text{token distribution} token distribution),表示每个时刻对应词汇表中各 token 的预测概率。
- 在线流式处理说明:图下方文字 "For on - line streaming speech recognition, use uni - directional RNN" 指出,对于在线流式语音识别,采用单向 RNN,确保实时处理,不依赖未来帧的数据。
该架构通过 CTC 解决语音帧与文本标签的对齐问题,适用于端到端的语音识别任务,特别是需要实时处理的流式场景。
 介绍连接主义时间分类(CTC)的核心特性及处理规则:
介绍连接主义时间分类(CTC)的核心特性及处理规则:
- 输入输出特性 :
- 输入 T T T 个声学特征,输出 T T T 个 tokens(忽略下采样),即输入与输出时间步一一对应。
- 输出处理规则 :
- 输出 tokens 包含空白符 ϕ \phi ϕ,最终需通过"合并重复 tokens,去除 ( \phi )"得到最终结果。
- 示例说明 :
- 英文示例:
- ϕ ϕ d d ϕ e ϕ e ϕ p p \phi \ \phi \ d \ d \ \phi \ e \ \phi \ e \ \phi \ p \ p ϕ ϕ d d ϕ e ϕ e ϕ p p:合并重复的 d d d、 e e e、 p p p,去除 ϕ \phi ϕ,得到 d e e p d \ e \ e \ p d e e p。
- ϕ ϕ d d ϕ e e e e ϕ p p \phi \ \phi \ d \ d \ \phi \ e \ e \ e \ e \ \phi \ p \ p ϕ ϕ d d ϕ e e e e ϕ p p:合并重复的 d d d、 e e e、 p p p,去除 ϕ \phi ϕ,得到 d e p d \ e \ p d e p。
- 中文示例:
- "好 好 棒 棒 棒 棒 棒":合并重复的"好""棒",得到"好 棒"。
- "好 ϕ \phi ϕ 棒 ϕ \phi ϕ 棒 ϕ ϕ \phi \ \phi ϕ ϕ":合并重复的"棒",去除 ϕ \phi ϕ,得到"好 棒 棒"。
- 英文示例:
通过这些规则,CTC 解决了语音帧与文本标签对齐的难题,适用于语音识别等序列建模任务。
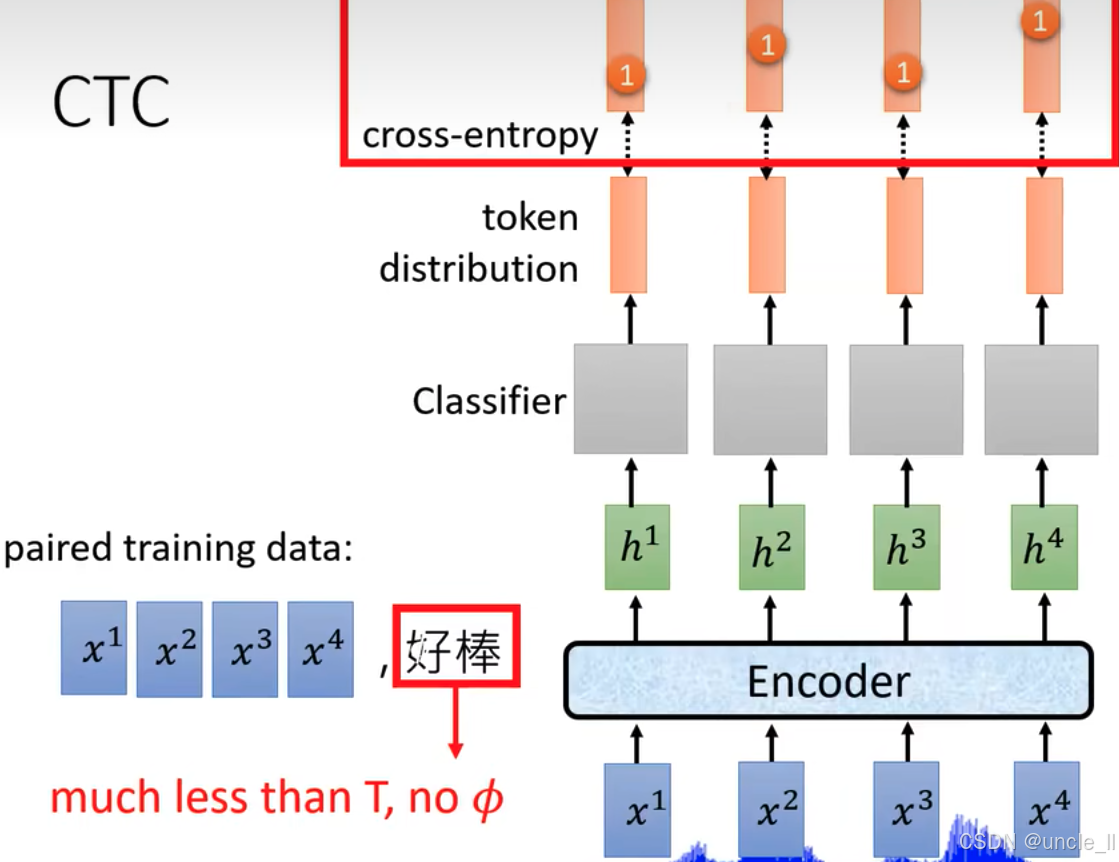
展示连接主义时间分类(CTC)在训练中的应用,具体内容如下:
- 左侧训练数据 :标注为 "paired training data",输入为 x 1 x^1 x1到 x 4 x^4 x4的声学特征,对应标签为 "好棒"。红色文字 "much less than T T T, no ϕ \phi ϕ" 表明标签长度远小于输入时间步 T T T,且不含空白符 ϕ \phi ϕ,体现了 CTC 处理输入输出长度不对齐的特性。
- 右侧模型架构 :
- Encoder(编码器) :处理输入 x\^1到 x 4 x^4 x4,输出隐藏状态 h 1 h^1 h1到 h 4 h^4 h4。
- Classifier(分类器) :将每个 h i h^i hi转换为 token distribution \text{token distribution} token distribution(令牌分布),表示每个时间步对词汇单元的预测概率。
- 交叉熵损失(cross - entropy) :图中红色框标注,每个时间步的输出通过交叉熵与目标标签比较,指导模型训练。尽管标签长度短于输入时间步,CTC 仍能通过引入空白符 ϕ \phi ϕ、合并重复令牌等机制,解决输入与输出的对齐问题,实现端到端的训练。
该图直观呈现了 CTC 在语音识别等序列任务中,处理输入输出不对齐数据的训练过程与架构。

穷举所有的alignment作为训练数据
训练原理:CTC 在训练时考虑所有可能的对齐路径(即不同的 ϕ 插入方式),对这些路径的概率进行求和,通过最大化目标标签的总概率来更新模型参数。这种方式解决了语音识别等任务中输入(如声学特征)与输出(如文本标签)长度不一致的难题,无需精确对齐每一个时间步,只需利用插入 ϕ 的多种对齐方式进行训练,使模型学习到更鲁棒的序列映射关系。
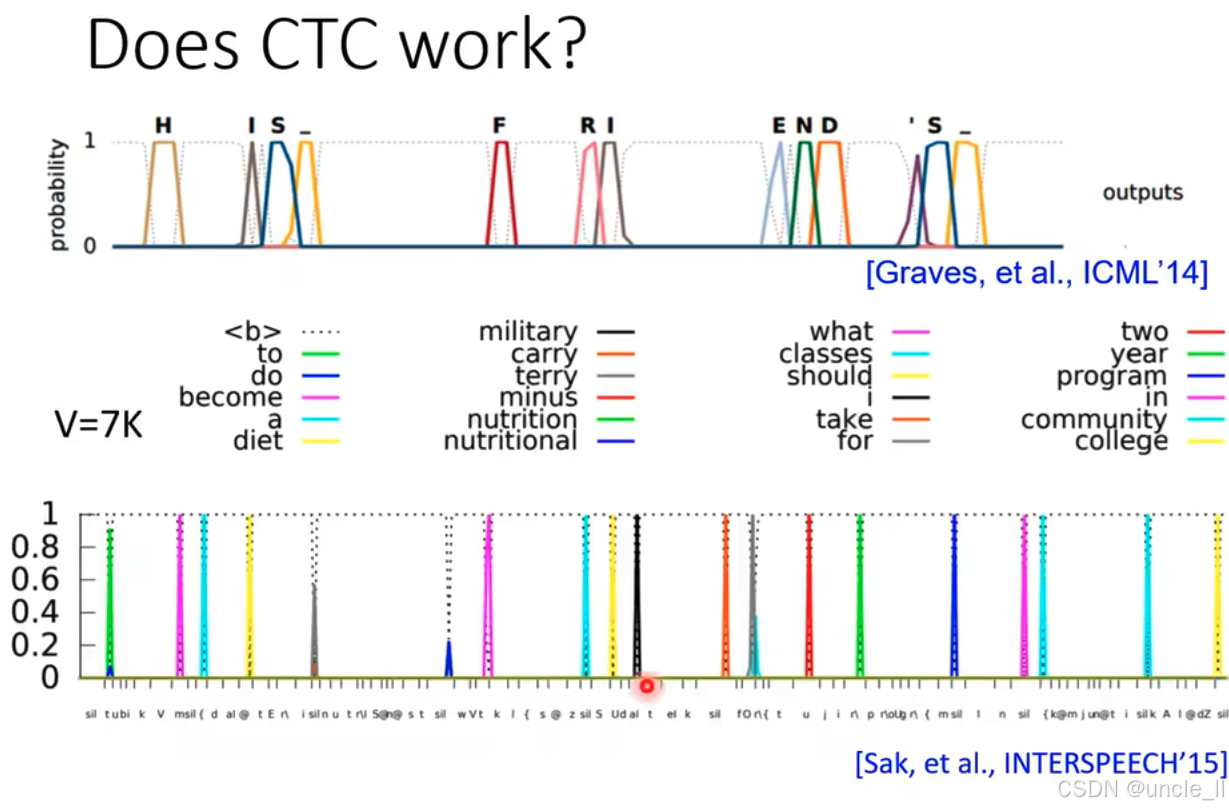
整体通过展示 CTC 模型在语音识别任务中对目标 token / 单词的高概率预测,直观证明了 CTC 在序列建模中有效,能够准确捕捉并输出目标序列。

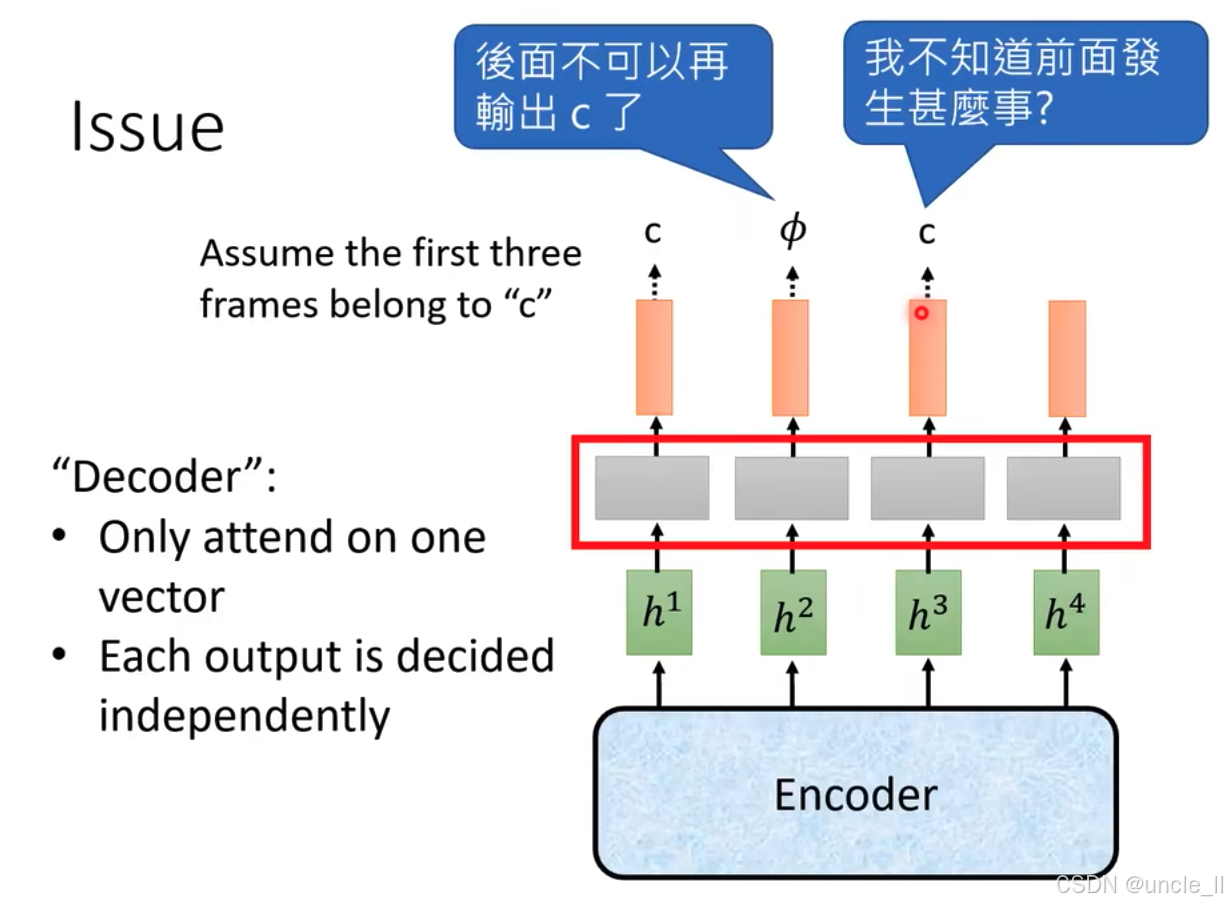
CTC 模型中解码器(Decoder)存在的问题具体如下:
-
假设与模型结构:
- 假设前三个帧对应字符 "c"。图中下方的 "Encoder" 生成隐藏状态 h 1 , h 2 , h 3 , h 4 h^1, h^2, h^3, h^4 h1,h2,h3,h4,传递给上方的解码器(灰色模块)。
- 解码器特性标注为 "Only attend on one vector"(仅关注一个向量)和 "Each output is decided independently"(每个输出独立决定),即每次仅基于单个输入向量独立生成输出,不考虑前后文依赖。
-
输出问题示例:
- 输出序列中出现 "c - ϕ \phi ϕ - c"。第一个对话框 "後面不可以再輸出 c 了" 表明,由于前三个帧已对应 "c",后续不应再输出 "c",但解码器独立决策未考虑此约束。
- 第二个对话框 "我不知道前面發生甚麼事?" 体现解码器独立生成输出,缺乏对前文信息的记忆与关联,导致重复或不合理输出(如再次输出 "c")。
综上, CTC 解码器因独立输出、不考虑前后文依赖而产生的问题,即无法利用序列的历史信息进行全局优化决策。