共现词矩阵
-
- [1. 概述](#1. 概述)
- [2. 构建步骤](#2. 构建步骤)
- [3. 代码实现(Python)](#3. 代码实现(Python))
- 结语
共现词矩阵 (Co-occurrence Matrix)是自然语言处理(NLP)中用于捕捉词语间语义关系的重要工具。共现矩阵通过统计词语在特定上下文窗口内的共现频率,揭示文本中词汇的关联性,并为关键词提取、词向量表示等任务提供支持。
1. 概述
(1)基本概念
共现词矩阵 (Co-Occurrence Matrix) 是具有固定上下文窗口的共现矩阵 (Co-Occurrence Matrix with a fixed context window)。
共现词矩阵通过统计语料库中词语对的共现次数 构建。其核心思想是:语义相近的词语往往在相似的上下文中出现。例如,在句子"苹果是水果"和"芒果是水果"中,"苹果"与"芒果"因共享上下文"水果"而具有语义关联。
应用于以下场景
- 关键词提取:通过共现网络识别高频关联词,辅助主题分析。
- 词向量表示:将矩阵行/列作为词向量,用于语义相似度计算。
- 文本分类:结合共现特征增强模型对上下文的理解能力。
(2)上下文窗口
对于给定的语料库,一对单词(如 w 1 w_1 w1和 w 2 w_2 w2)的共现是指它们在上下文窗口(Context Window)中同时出现的次数。
因此,共现频率的计算依赖于上下文窗口(Context Window),窗口大小决定统计范围。例如,窗口大小为1时,仅统计相邻词对的共现次数;窗口大小为2时,覆盖左右各两个词的位置。
(3)矩阵形式
共现矩阵的行和列为所有不重复词语,矩阵元素表示对应词语对的共现次数。例如,以下语料的共现矩阵(窗口大小=1):
-
语料:"I like NLP", "I enjoy flying"
-
矩阵片段:
I like NLP enjoy I 0 2 0 1 like 2 0 1 0
(4)优缺点
| 优点 | 缺点 |
|---|---|
| 保留词语语义关系(如近义词聚类) | 高内存消耗(需存储N×N矩阵) |
| 无需复杂训练,一次构建可重复使用 | 稀疏性导致计算效率低 |
2. 构建步骤
(1)数据预处理
- 分词与去重:将文本拆分为词语列表,并提取唯一关键词集合。
- 格式化语料:将每篇文章或句子转换为词语序列。
(2)矩阵初始化
构建一个大小为N×N的空矩阵(N为关键词数量),首行和首列填入关键词列表。
(3)共现频率计算
- 字典优化法:记录每个关键词在语料中的位置(如行号),通过集合交集快速计算共现次数。
- 窗口遍历法:对每个词语,遍历其窗口范围内的邻近词,逐对累加共现计数。
e.g.1
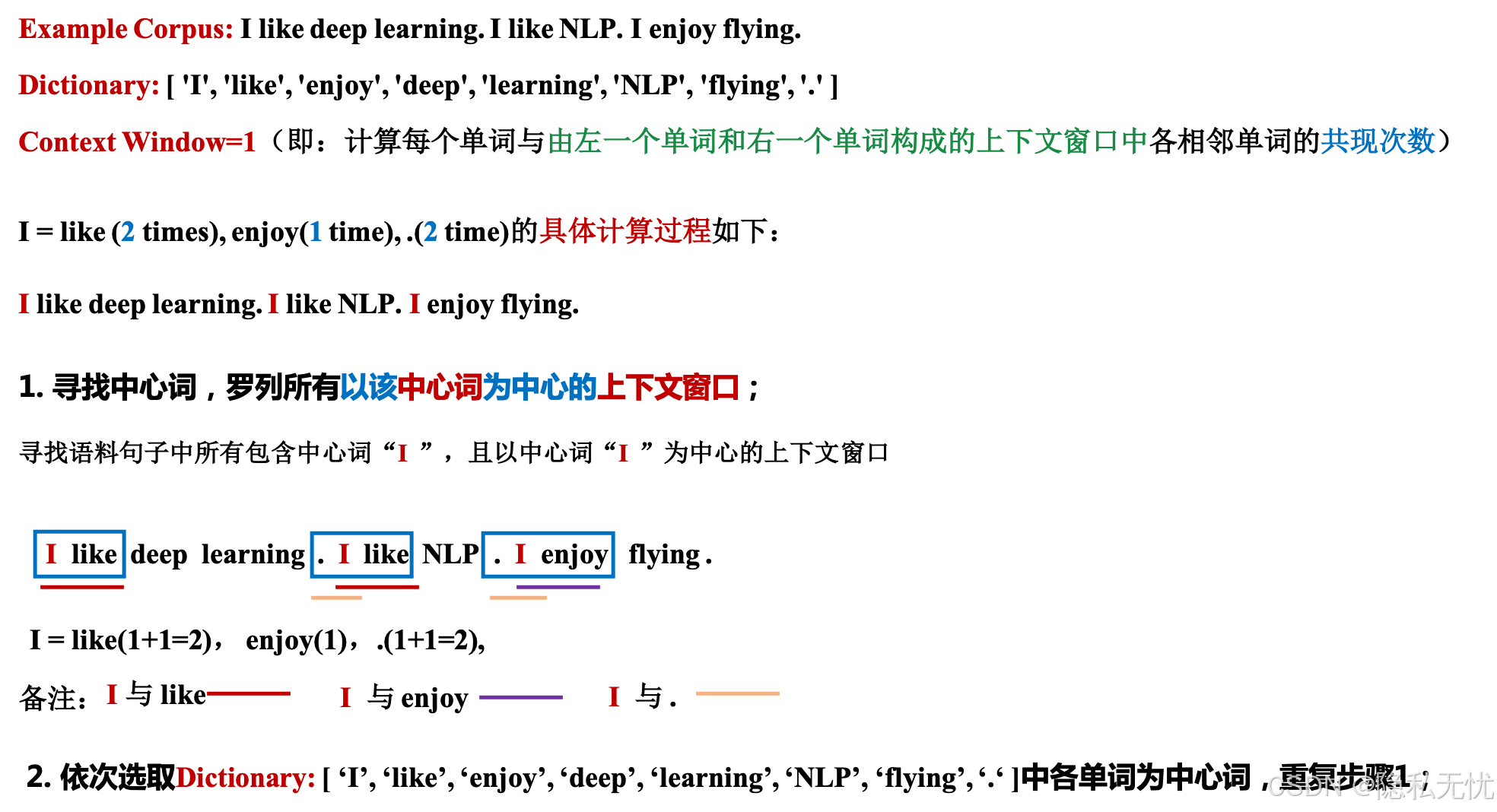
输出如下:
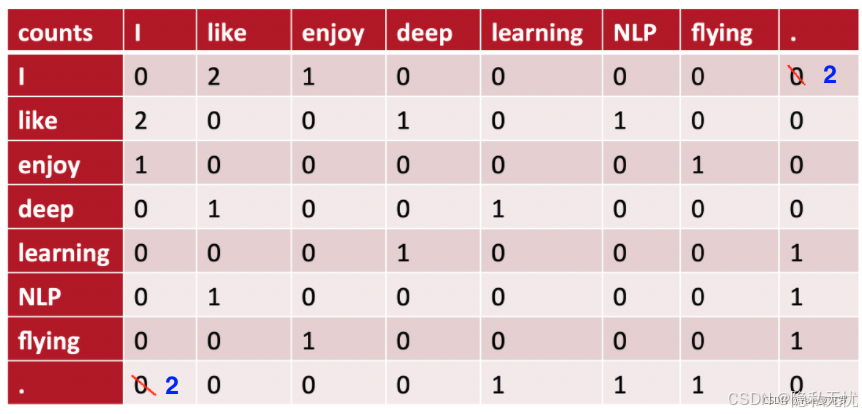
e.g.2
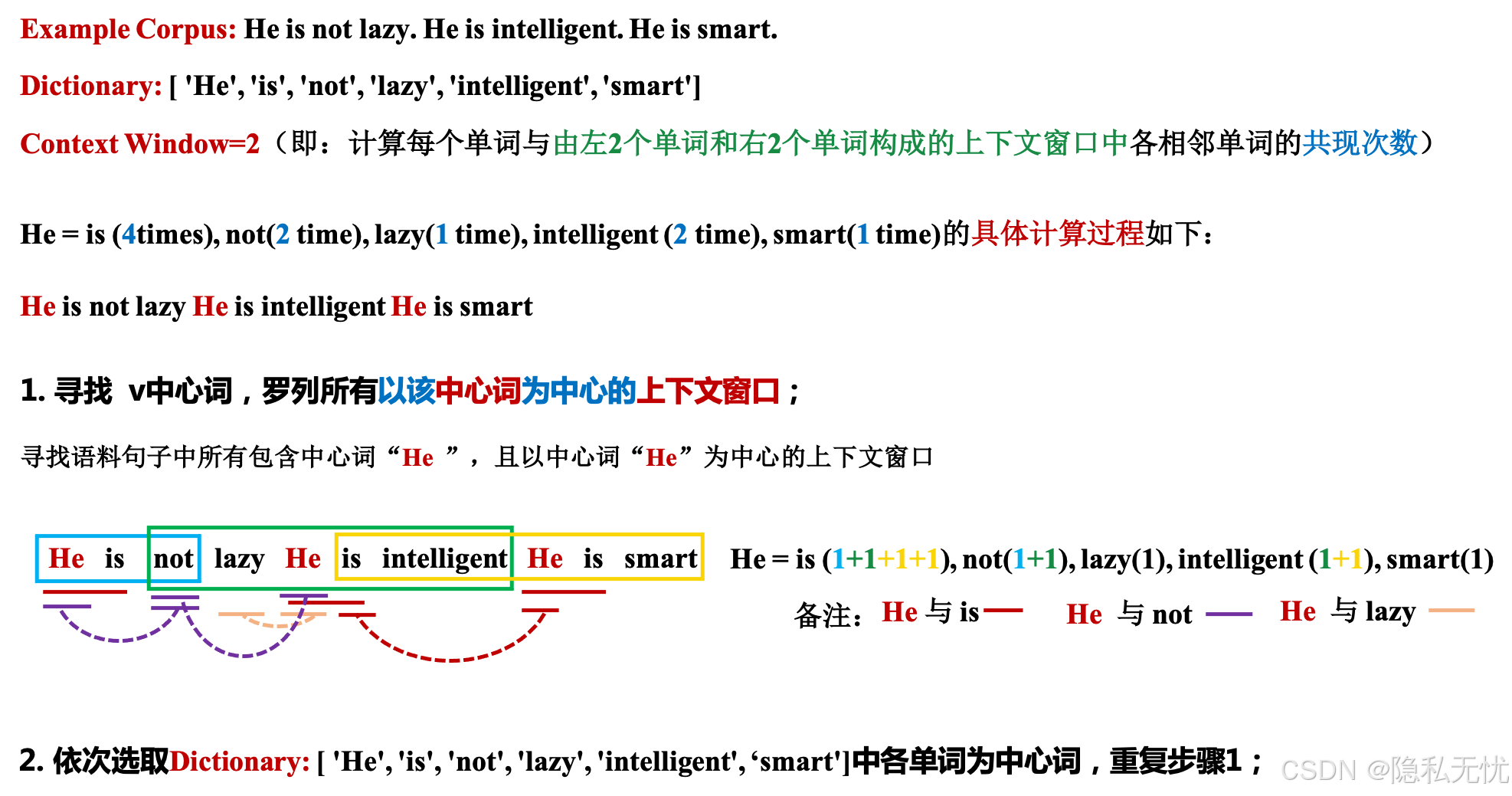
输出如下:
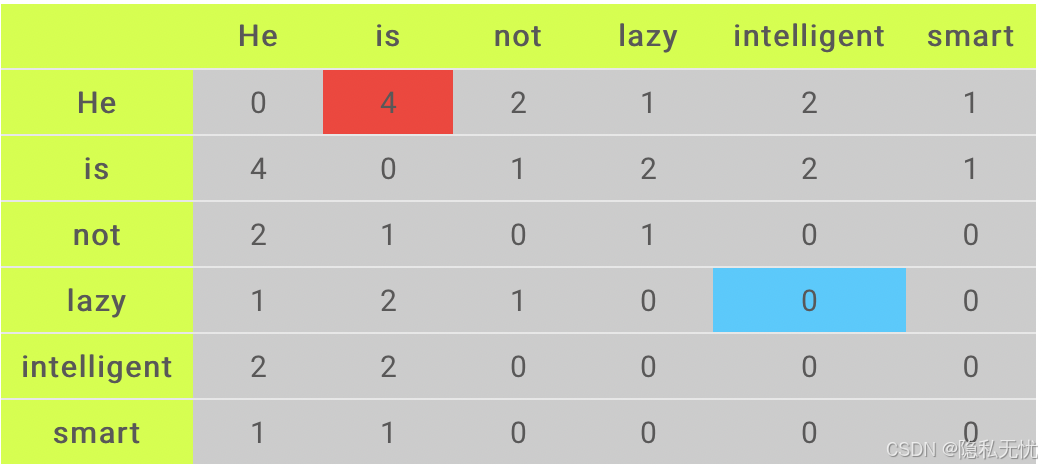
红框表示"He"和"is"在上下文窗口等于2时的共现次数是4。为了理解和可视化计数,具体共现情况如下图:

3. 代码实现(Python)
读取文件
python
######################## 读取文件 ########################
def readFile(filePath):
# #读取停止词 输入: 文件路径 输出:字符串
with open(filePath,encoding = 'utf-8') as file:
mytext = file.read() #返回一个字符串
return mytext文件处理
python
######################## 文件处理 ########################
def process_text(text_cn, stopWord_cn, defstop=None):
words = jieba.lcut(text_cn)
words = [w for w in words if ((w not in stopWord_cn)&('\u4e00' <= w <= '\u9fff'))]
return words构建共现矩阵字典
python
######################## 构建共现矩阵字典 ########################
def build_cooccurrence_matrix(words, window_size=2):
"""
:param text: 输入文本(字符串)
:param window_size: 上下文窗口半径
:return: 共现统计字典
"""
co_occur = defaultdict(int) # 共现统计字典
# 遍历每个中心词
for center_idx in range(len(words)):
center_word = words[center_idx]
# 确定上下文窗口边界
left = max(0, center_idx - window_size)
right = min(len(words), center_idx + window_size + 1)
# 遍历窗口内其他词
for other_idx in range(left, right):
if other_idx == center_idx:
continue # 跳过自身
other_word = words[other_idx]
# 创建有序词对(避免A-B和B-A重复计数)
sorted_pair = tuple(sorted([center_word, other_word]))
# 更新共现次数
co_occur[sorted_pair] += 1
# 返回共现统计字典
return co_occurTopN共现词
python
######################## TopN共现词 ########################
def get_top_vocab(co_dict, N=10):
sorted_pairs = sorted(co_dict.items(), key=lambda x: x[1], reverse=True)
top_pairs = [(pair, count) for pair, count in sorted_pairs if pair[0] != pair[1]][:N]
print("共现词对Top"+str(N))
for idx, (pair, count) in enumerate(top_pairs, 1):
print(f"{idx}. {pair[0]} - {pair[1]}: {count}次")
all_words = []
for pair, count in top_pairs:
all_words.extend(pair)
top_vocab = set(all_words)
return top_vocab,sorted_pairs保存结果
python
######################## 保存结果 ########################
def save_results(co_dict,sorted_pairs,top_vocab,output_prefix):
"""保存两个CSV文件:共现词对和矩阵"""
# 保存TopN共现词对
df_pairs = pd.DataFrame([(p[0], p[1], c) for (p, c) in sorted_pairs if p[0] in top_vocab and p[1] in top_vocab],
columns=["Word1", "Word2", "Count"])
df_pairs.to_csv(f"{output_prefix}_pairs.csv", index=False)
# 构建并保存共现矩阵
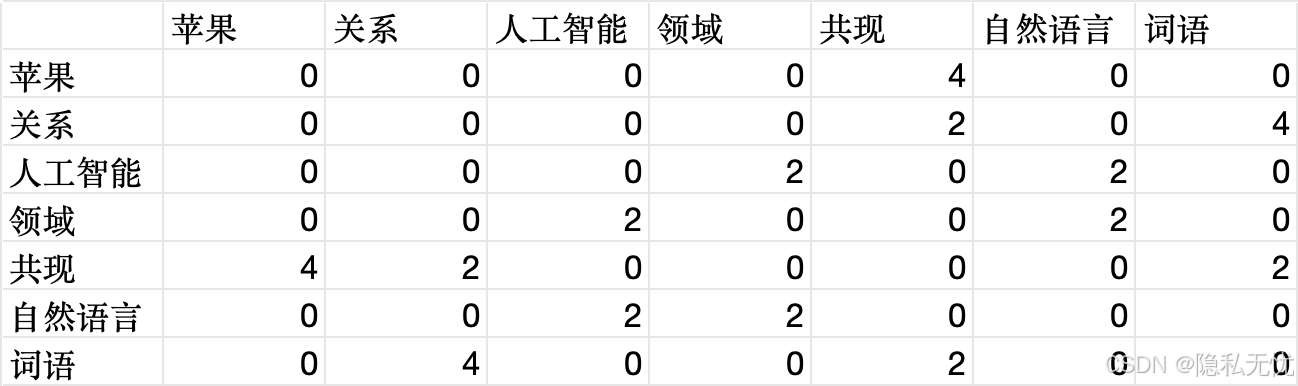
matrix = pd.DataFrame(0, index=top_vocab, columns=top_vocab)
for (w1, w2), count in co_dict.items():
if w1 in top_vocab and w2 in top_vocab:
matrix.at[w1, w2] += count
matrix.at[w2, w1] += count # 对称矩阵
matrix.to_csv(f"{output_prefix}_matrix.csv")
return df_pairs, matrix示例
python
sample_text = """
自然语言处理是人工智能领域的重要方向。通过分析文本中的词语共现关系,
我们可以发现词语之间的语义关联。例如"苹果"与"手机"的共现可能暗示科技主题,
而"苹果"与"水果"的共现则指向食品领域。深度学习模型常利用共现矩阵捕捉语义信息。
"""
# 参数配置
params = {
"window_size": 2,
"top_N": 5,
"output_prefix": "demo_co_occurrence"}
stopWordfile_cn = r'Data/stopword_cn.txt'
# 0. 读取文件
stopWord_cn = readFile(stopWordfile_cn) ##读取中文停止词
# 1. 文本预处理
words = process_text(sample_text, stopWord_cn)
# 2. 构建共现词典
co_occur = build_cooccurrence_matrix(words, params["window_size"])
# 3. TopN共现词
top_vocab,sorted_pairs = get_top_vocab(co_occur, params["top_N"])
# 4. 保存结果
df_pairs, df_matrix = save_results(co_occur,sorted_pairs,top_vocab, params["output_prefix"])
print("共现词对已保存至 demo_co_occurrence_pairs.csv")
print("共现矩阵已保存至 demo_co_occurrence_matrix.csv")
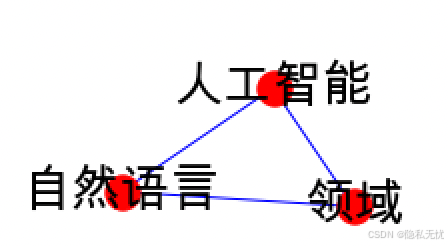
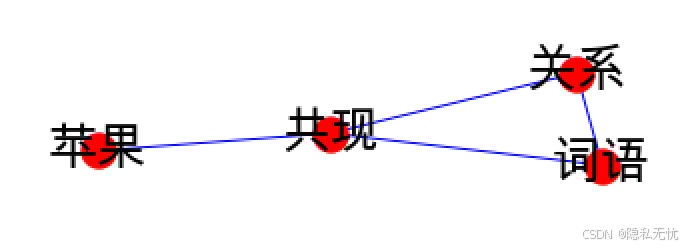
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.figure(figsize=(10, 10))
graph1 = nx.from_pandas_adjacency(df_matrix)
nx.draw(graph1, with_labels=True, node_color='red', font_size=25, edge_color='blue')
plt.savefig('demo_共现网络图.jpg')输出:
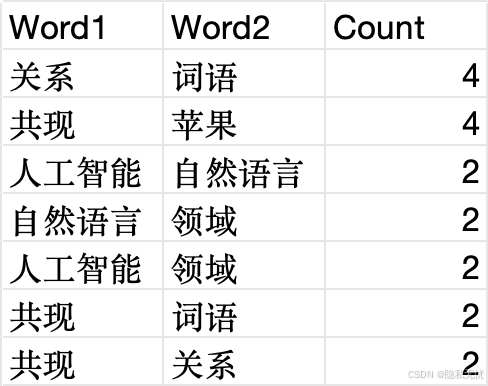
共现词对Top5
- 关系 - 词语: 4次
- 共现 - 苹果: 4次
- 人工智能 - 自然语言: 2次
- 自然语言 - 领域: 2次
- 人工智能 - 领域: 2次
demo_co_occurrence_pairs.csv
demo_co_occurrence_matrix
demo_共现网络图.jpg
结语
共现词矩阵是NLP领域的基础工具,尽管矩阵维度随词汇量增长面临稀疏性 和高维度的挑战,但通过优化算法(如SVD)和工程策略(分布式计算),其仍是语义分析和文本挖掘的重要支柱。实际应用中可结合具体任务选择窗口大小和降维方法,以平衡性能与效果。