图像去噪是计算机视觉中的一个基础问题,在医学图像、遥感、夜间视觉等领域有广泛应用。本文将手把手带你用 PyTorch 构建一个 UNet 架构的图像去噪模型,包括数据预处理、网络搭建、PSNR 评估与模型保存的完整流程。
本项目已支持将数据增强版本保存为独立图像对,用于数据集扩充或训练可视化。
项目结构
1. 数据集加载与预处理
我们构建了一个 DenoisingDataset 类,用于加载 noisy-clean 图像对,并转换为 PyTorch Tensor:
python
# --- 数据集定义 ---
class DenoisingDataset(Dataset):
def __init__(self, noisy_dir, clean_dir, transform=None):
self.noisy_paths = sorted([os.path.join(noisy_dir, f) for f in os.listdir(noisy_dir)])
self.clean_paths = sorted([os.path.join(clean_dir, f) for f in os.listdir(clean_dir)])
self.transform = transform if transform else transforms.ToTensor()
def __len__(self):
return len(self.noisy_paths)
def __getitem__(self, idx):
noisy_img = Image.open(self.noisy_paths[idx]).convert("RGB")
clean_img = Image.open(self.clean_paths[idx]).convert("RGB")
return self.transform(noisy_img), self.transform(clean_img)可在此基础上扩展数据增强(如随机裁剪、翻转、旋转等),提升模型泛化能力。
2. UNet 去噪模型结构
相比简单 CNN,我们采用了经典的 UNet 网络,具有强大的上下文信息融合能力,特别适合图像恢复任务。
结构亮点:
-
编码器-解码器结构
-
三层下采样 + 三层上采样
-
每一层都使用跳跃连接融合细节信息
python
class UNetDenoiser(nn.Module):
def __init__(self):
super(UNetDenoiser, self).__init__()
# Encoder
self.enc1 = self.conv_block(3, 64)
self.enc2 = self.conv_block(64, 128)
self.enc3 = self.conv_block(128, 256)
self.pool = nn.MaxPool2d(2)
# Bottleneck
self.bottleneck = self.conv_block(256, 512)
# Decoder
self.up3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)
self.dec3 = self.conv_block(512, 256)
self.up2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.dec2 = self.conv_block(256, 128)
self.up1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.dec1 = self.conv_block(128, 64)
# Output
self.final = nn.Conv2d(64, 3, kernel_size=1)
def conv_block(self, in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True)
)
def forward(self, x):
# Encoder
e1 = self.enc1(x) # [B, 64, H, W]
e2 = self.enc2(self.pool(e1)) # [B, 128, H/2, W/2]
e3 = self.enc3(self.pool(e2)) # [B, 256, H/4, W/4]
# Bottleneck
b = self.bottleneck(self.pool(e3)) # [B, 512, H/8, W/8]
# Decoder
d3 = self.up3(b) # [B, 256, H/4, W/4]
d3 = self.dec3(torch.cat([d3, e3], dim=1))
d2 = self.up2(d3) # [B, 128, H/2, W/2]
d2 = self.dec2(torch.cat([d2, e2], dim=1))
d1 = self.up1(d2) # [B, 64, H, W]
d1 = self.dec1(torch.cat([d1, e1], dim=1))
return self.final(d1)输出为与输入同尺寸的 RGB 图像。
3. 评估指标:PSNR
我们使用图像恢复领域常用的 峰值信噪比(PSNR) 衡量输出图像质量:
python
# --- PSNR 计算函数 ---
def calculate_psnr(img1, img2):
mse = torch.mean((img1 - img2) ** 2)
if mse == 0:
return float("inf")
return 20 * torch.log10(1.0 / torch.sqrt(mse))PSNR 越高代表还原质量越好,一般能达到 30dB 以上的去噪模型就较为可用了。
4. 模型训练主流程
训练使用 MSELoss 作为重建损失,优化器为 Adam,默认训练 50 个 epoch:
python
# --- 主训练过程 ---
def train_denoiser():
noisy_dir = "dataset/noisy"
clean_dir = "dataset/clean"
batch_size = 1
num_epochs = 50
lr = 0.0005
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dataset = DenoisingDataset(noisy_dir, clean_dir, transform=transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# model = SimpleDenoiser().to(device)
# 替换为 UNet
model = UNetDenoiser().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
for epoch in range(num_epochs):
model.train()
total_loss = 0.0
total_psnr = 0.0
for noisy, clean in dataloader:
noisy, clean = noisy.to(device), clean.to(device)
denoised = model(noisy)
loss = criterion(denoised, clean)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
total_psnr += calculate_psnr(denoised, clean).item()
avg_loss = total_loss / len(dataloader)
avg_psnr = total_psnr / len(dataloader)
print(f"Epoch [{epoch+1}/{num_epochs}] - Loss: {avg_loss:.4f}, PSNR: {avg_psnr:.2f} dB")
# 保存模型
os.makedirs("weights", exist_ok=True)
torch.save(model.state_dict(), "weights/denoiser.pth")
print("模型已保存为 weights/denoiser.pth")训练完成后,模型将保存到 weights/denoiser.pth,后续可用于推理、部署、导出为 ONNX 等操作。
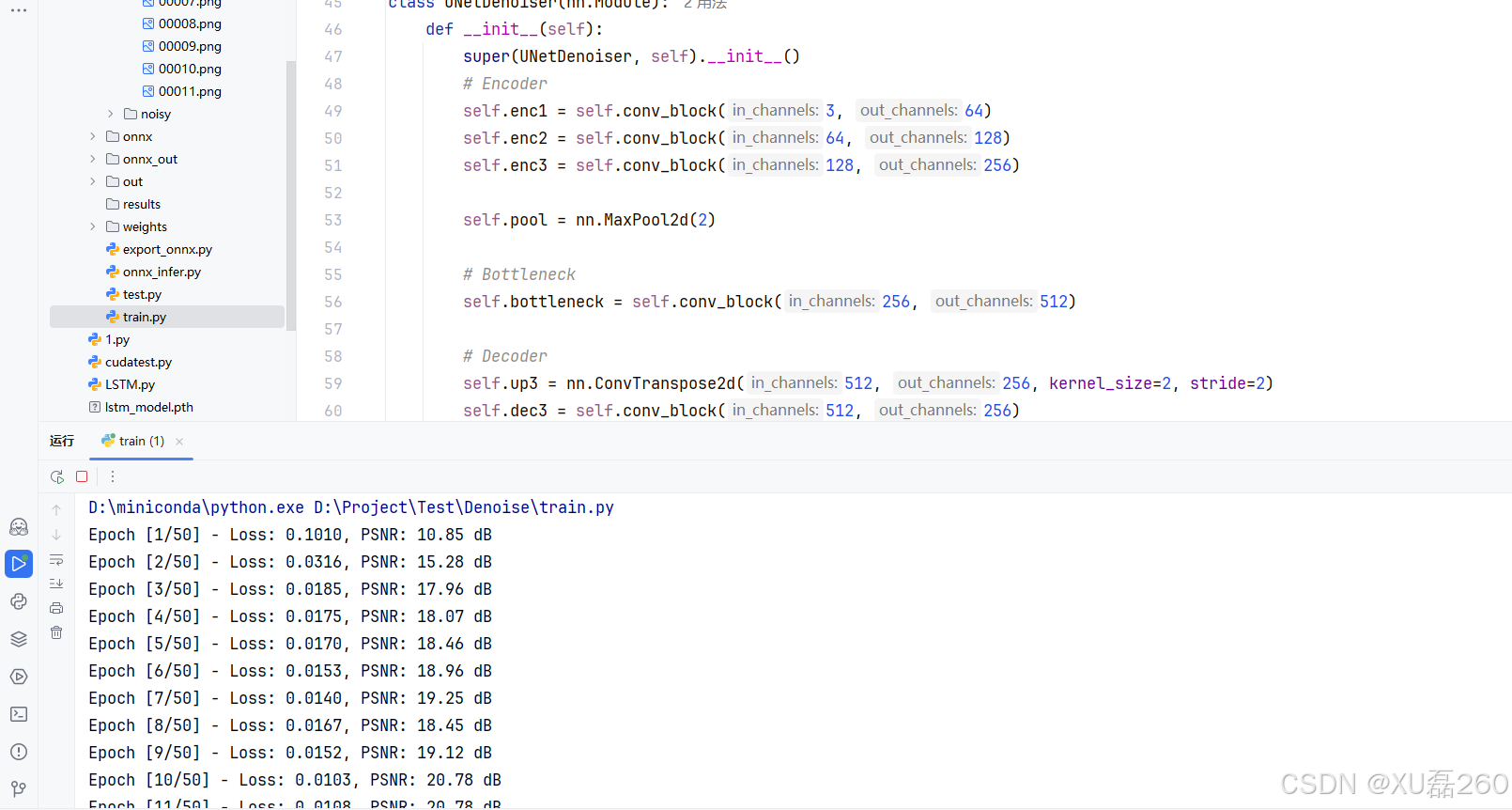
5. 训练效果
6. 未来可扩展方向
你可以基于这个项目进一步扩展:
-
加入
RandomCrop和ColorJitter等数据增强 -
替换为 SwinIR、Uformer 等更强的图像恢复模型
-
迁移至 TensorRT / ONNX for deployment
-
训练灰度图(单通道)或医学图像(DICOM)
结语
通过本文,我们从零实现了一个 完整的图像去噪深度学习系统,涵盖数据读取、模型搭建、训练与保存,适合作为图像恢复任务的起点项目。
如果你有更小的数据集,推荐加入数据增强;如果你追求精度,建议使用 Uformer 或 Transformer-based 模型。