一、下载原因:
我们的业务中通常使⽤的是中⽂分词,es的中⽂分词默认会将中⽂词每个字看成⼀个词⽐如:"我想吃⾁夹馍"会被分为"我","想","吃","⾁" ,"夹","馍" 这显然是不太符合⽤⼾的使⽤习惯,所以我们需要安装中⽂分词器ik,来讲中⽂内容分解成更加符合⽤⼾使⽤的关键字。如下图:
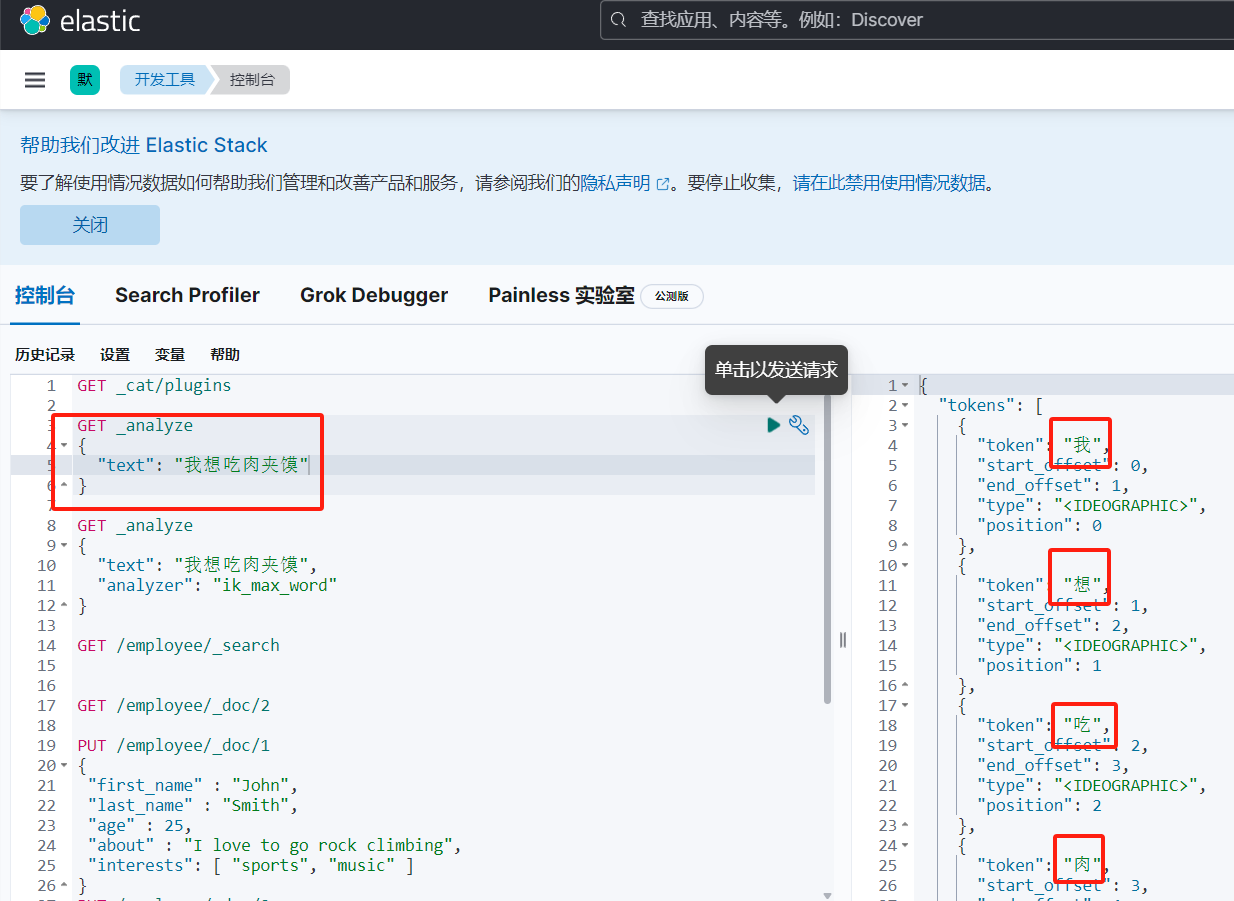
二、下载地址
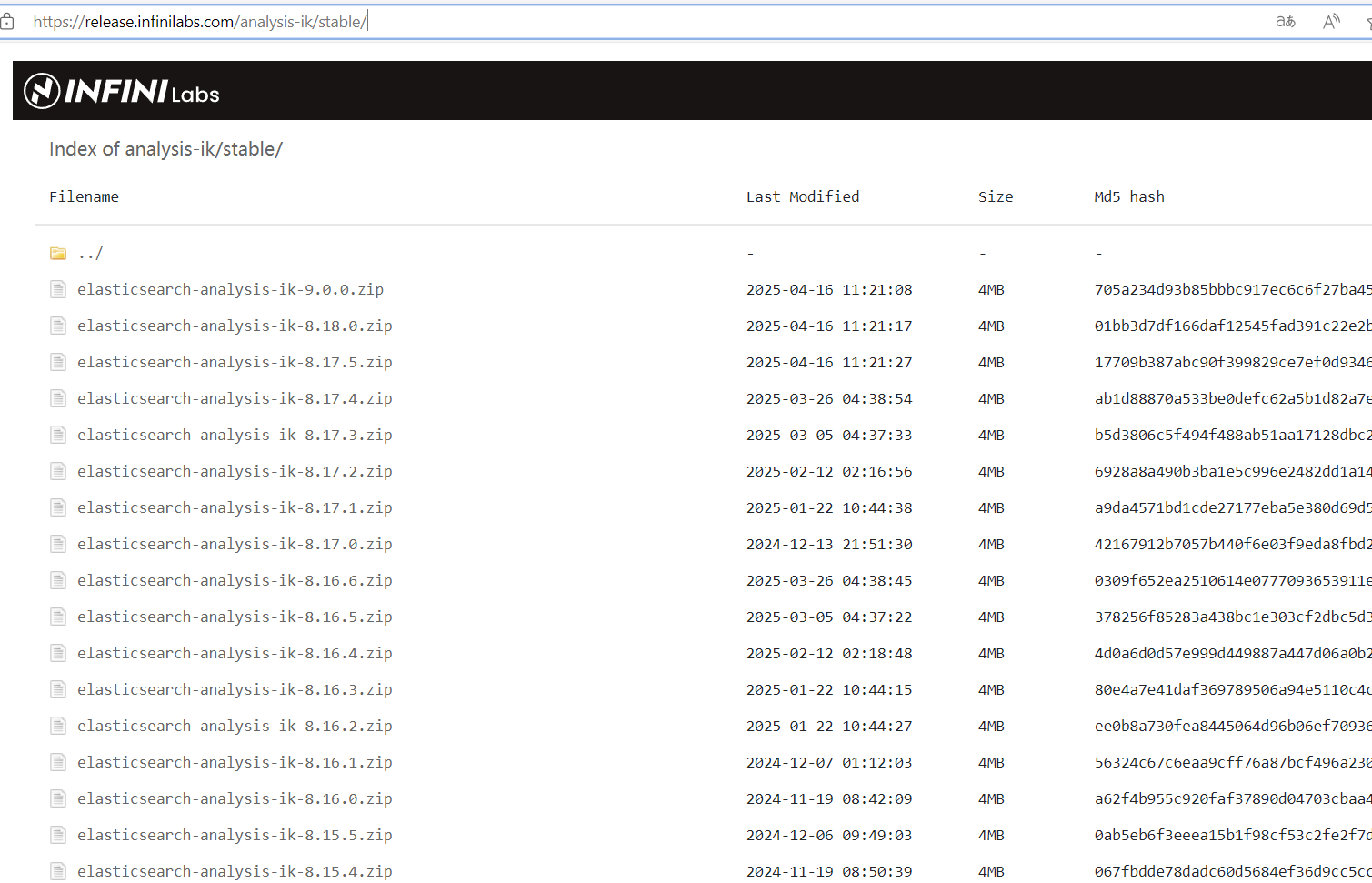
找到与自己的elasticsearch想对应的版本下载即可
三、配置插件
下载完成后将其压随后放置在:es容器内/usr/share/elasticsearch/plugins⽬录下,也可以通过配置
挂载⽬录的⽅式将插件放在挂载⽬录下。然后可以去kibana可视化页面中,进行校验,如图:
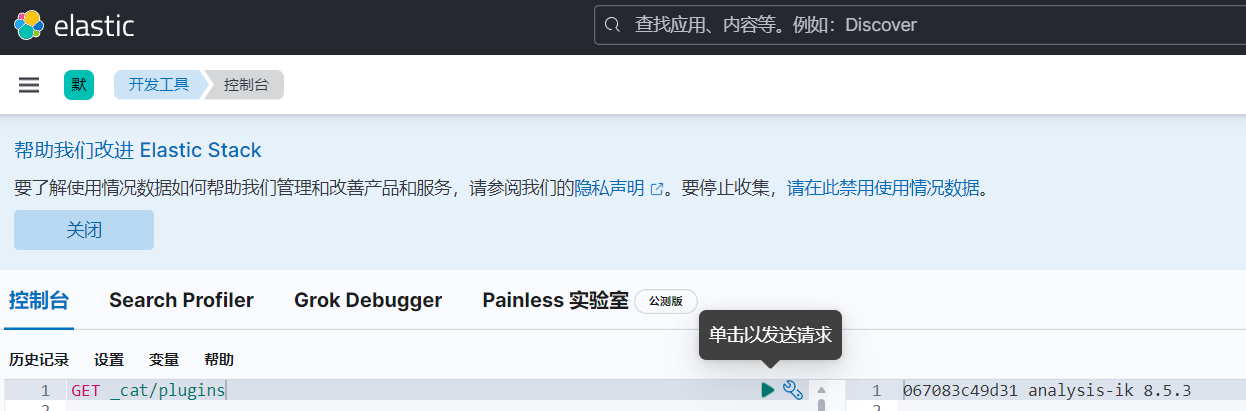
至此我们成功的下载了对应的中文分词器,我们来看看效果如何:
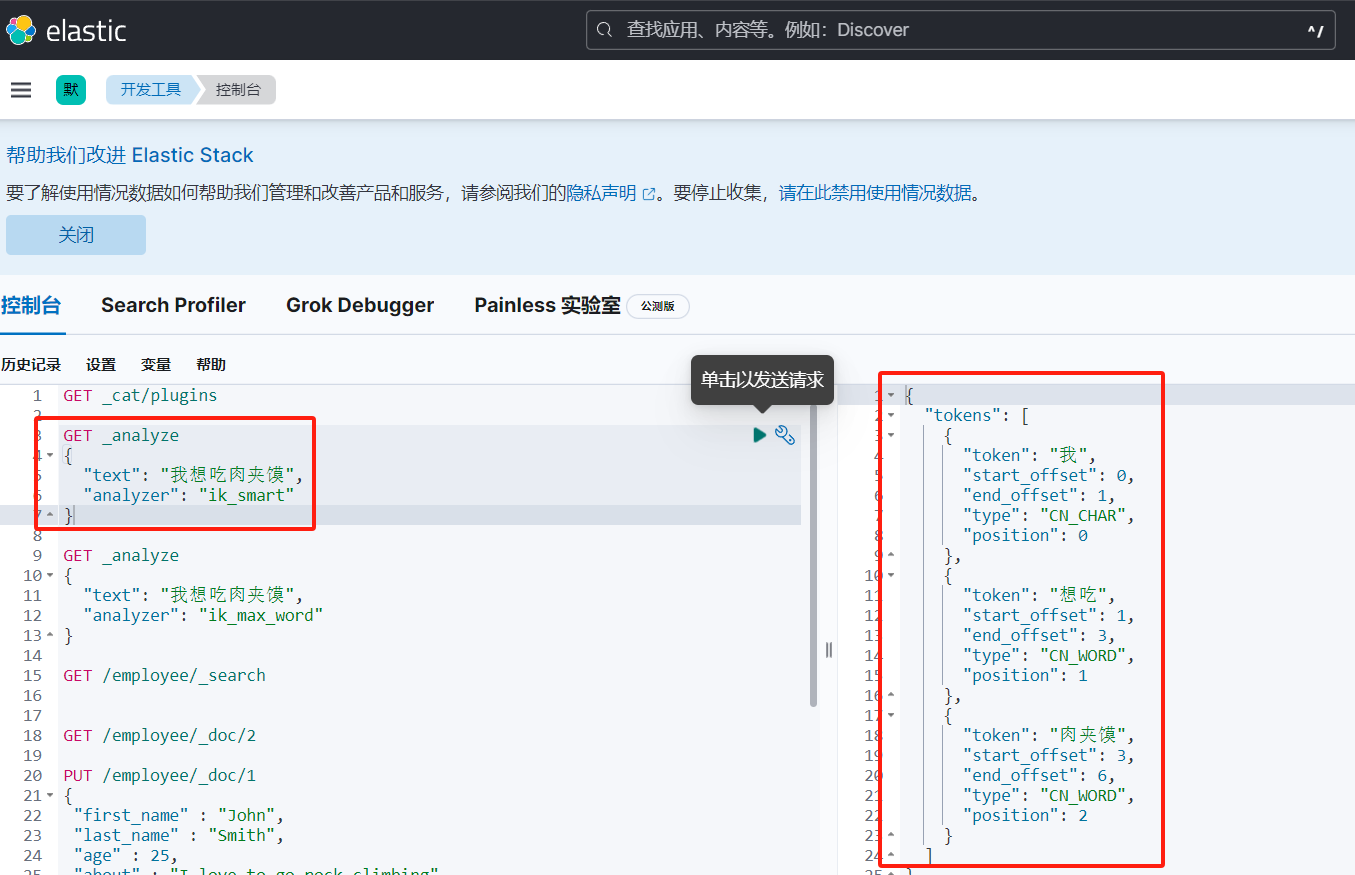
可以看到,对中文的分词达到了我们预期的效果。