1.综述
1.1.Zookeeper介绍
Zookeeper 是一个分布式协调服务,由 Apache 开发,主要用于管理分布式应用中的配置信息、命名服务、分布式同步和组服务。它通过简单的接口提供高性能、高可用性和严格的顺序访问控制,广泛应用于分布式系统的协调与管理,帮助开发者处理分布式环境中的复杂问题
ZooKeeper集群原理:Zookeeper是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务,它提供一项基本服务:分布式锁服务。
分布式应用可以基于它实现更高级的服务,实现诸如同步服务、配置维护和集群管理或者命名的服务。Zookeeper服务自身组成一个集群,2n+1个(奇数)服务允许n个失效,集群内一半以上机器可用,Zookeeper就可用。
1.2.架构图
下图是 Zookeeper 的架构图,ZooKeeper 集群中包含 Leader、Follower 以及 Observer 三个角色:
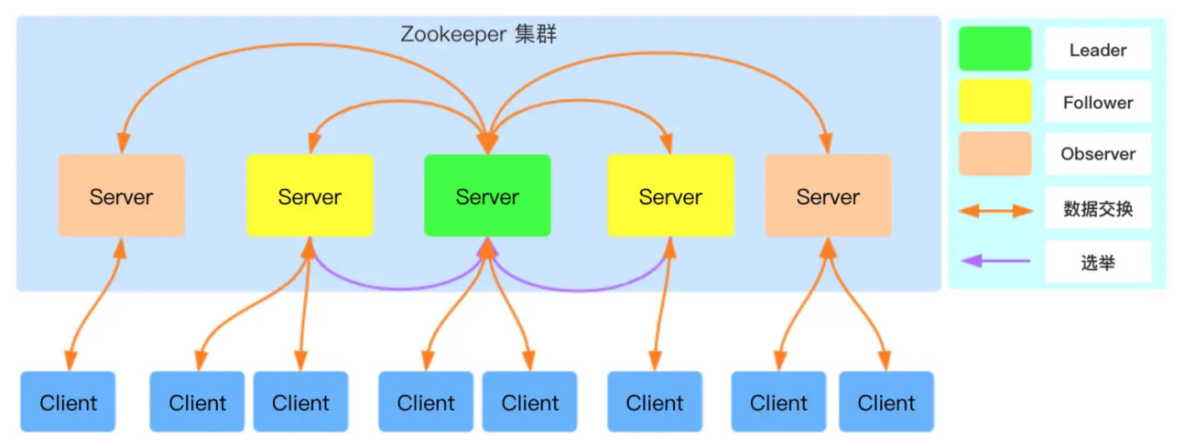
Leader:负责进行投票的发起和决议,更新系统状态,Leader 是由选举产生;
Follower: 用于接受客户端请求并向客户端返回结果,在选主过程中参与投票;
Observer:可以接受客户端连接,接受读写请求,写请求转发给 Leader,但 Observer 不参加投票过程,只同步 Leader 的状态,Observer 的目的是为了扩展系统,提高读取速度。
Client 是 Zookeeper 的客户端,请求发起方
1.3.集群架构原理
Leader主要有三个功能:
1.恢复数据;
2.维持与follower的心跳,接收follower请求并判断follower的请求消息类型;
3.follower的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
Follower主要有四个功能:
1.向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
2.接收Leader消息并进行处理;
3.接收Client的请求,如果为写请求,发送给Leader进行投票;
4.返回Client结果。
读操作分析:
ZooKeeper集群中所有的server节点都拥有相同的数据,所以读的时候可以在任意一台server节点上,客户端连接到集群中某一节点,读请求,然后直接返回。当然因为ZooKeeper协议的原因(一半以上的server节点都成功写入了数据,这次写请求便算是成功),读数据的时候可能会读到数据不是最新的server节点,所以比较推荐使用watch机制,在数据改变时,及时感应到。
写操作分析:
当一个客户端进行写数据请求时,会指定ZooKeeper集群中的一个server节点,如果该节点为Follower,则该节点会把写请求转发给Leader,Leader通过内部的协议进行原子广播,直到一半以上的server节点都成功写入了数据,这次写请求便算是成功,然后Leader便会通知相应Follower节点写请求成功,该节点向client返回写入成功响应
zookeeper 的三个端口作用:
2181 : 对 client 端提供服务
2888 : 集群内机器通信使用
3888:选举 leader 使用
2. 安装Zookeeper
2.1.适用版本
版本号:3.8.0(最新stale版本)
JDK版本:jdk1.8.0_341
Zookeeper 需要 Java 运行环境JDK 1.8 或以上
关于新版本的新特性请查阅如下官方:https://zookeeper.apache.org/
2.2.环境准备
操作系统 :Linux
Java 环境 :Zookeeper 需要 Java 运行环境(JDK 1.8 或以上)。
检查 Java 是否安装:java -version

2.3. 下载Zookeeper
zookeeper官网下载地址:Apache ZooKeeper
Jdk 官网源码包下载地址:Java Archive Downloads - Java SE 8u211 and later (oracle.com)
2.4 安装Zookeeper
2.4.1 解压安装包
下载安装包后上传至服务器。
解压安装包:tar -xf apache-zookeeper-3.9.3-bin.tar.gz

2.4.2 创建数据目录和日志目录
mkdir -p /app/zookeeper/data
mkdir -p /app/zookeeper/logs
2.4.3 配置Zookeeper
cp conf/zoo_sample.cfg conf/zoo.cfg
vi conf/zoo.cfg 文件,修改以下内容:
dataDir=/app/zookeeper/data
dataLogDir=/app/zookeeper/logs
clientPort=2181
集群配置
如果是集群模式,添加以下配置(以 3 节点为例):
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| server.1=192.168.1.101:2888:3888 server.2=192.168.1.102:2888:3888 server.3=192.168.1.103:2888:3888 其中 server.x:x 是节点的唯一 ID。 IP:2888:用于节点间通信。 IP:3888:用于 Leader 选举。 |
配置节点 ID:
在每个节点的 dataDir 目录下创建 myid 文件,并写入对应的节点 ID。
|----------------------------------------------------------------------------------------------------------------------------------|
| echo 1 > /data/zookeeper/data/myid # 节点 1 echo 2 > /data/zookeeper/data/myid # 节点 2 echo 3 > /data/zookeeper/data/myid # 节点 3 |
2.4.4 启动 Zookeeper
启动zookeeper:/app/zookeeper/bin/zkServer.sh start
/app/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
/app/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /app/zookeeper/bin/../conf/zoo.cfg
Client port found: 9090. Client address: localhost. Client SSL: false.
Mode: standalone(单机模式)
集群模式:
在每个节点上启动 Zookeeper:
bin/zkServer.sh start
查看集群状态:
bin/zkServer.sh status
3 . Zookeeper集群部署
过程、目录与单机部署一致,集群数量以奇数为准如(3、5、7...)偶数会导致脑裂。
以三台zookeeper服务器为例,均需配置
3.1 配置hosts
#cat >>/etc/hosts << EOF
IP1 zookeeper01
IP2 zookeeper02
IP3 zookeeper03
EOF
3.2 配置myid
|--------------------------------------------------|
| Zookeeper01 #echo 0 >>/app/zookeeper/data/myid |
| Zookeeper02 #echo 1 >>/app/zookeeper/data/myid |
| Zookeeper03 #echo 2 >>/app/zookeeper/data/myid |
3.3 修改配置文件
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| #cat >>/app/zookeeper/conf/zoo.cfg <<EOF tickTime=6000 initLimit=15 syncLimit=15 dataDir=/app/zk-data/data dataLogDir=/app/zk-data/logs clientPort=2181 clientPortAddress=0.0.0.0 maxClientCnxns=3000 maxSessionTimeout=120000 minSessionTimeout=4000 autopurge.snapRetainCount=3 autopurge.purgeInterval=1 server.1=0.0.0.1:2888:3888 server.2=0.0.0.2:2888:3888 server.3=0.0.0.3:2888:3888 4lw.commands.whitelist=mntr.conf.ruok EOF |
| tickTime=6000 #ZK中的一个时间单元。ZK中所有时间都是以这个时间单元为基础,进行整数倍配置的。例如,session的最小超时时间是2*tickTime。 initLimit=15 #Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader允许F在 initLimit时间内完成这个工作。通常情况下,我们不用太在意这个参数的设置。如果ZK集群的数据量确实很大了,F在启动的时候,从Leader上同步数据的时间也会相应变长,因此在这种情况下,有必要适当调大这个参数了。(No Java system property) syncLimit=15 #在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。如果L发出心跳包在syncLimit之后,还没有从F那里收到响应,那么就认为这个F已经不在线了。注意:不要把这个参数设置得过大,否则可能会掩盖一些问题。 dataDir=/app/zk-data/data #存储快照文件 snapshot 的目录。默认情况下,事务日志也会存储在这里。建议同时配置参数dataLogDir, 事务日志的写性能直接影响zk性能。 dataLogDir=/app/zk-data/logs #事务日志输出目录。尽量给事务日志的输出配置单独的磁盘或是挂载点,这将极大的提升ZK性能。(No Java system property) clientPort=2181 #客户端连接server的端口,即对外服务端口,一般设置为 2181 clientPortAddress=0.0.0.0 #对于多网卡的机器,可以为每个IP指定不同的监听端口。默认情况是所有IP都监听 clientPort指定的端口。 New in 3.3.0 maxClientCnxns=3000 #单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制。请注意这个限制的使用范围,仅仅是单台客户端机器与单台ZK服务器之间的连接数限制,不是针对指定客户端IP,也不是ZK集群的连接数限制,也不是单台ZK对所有客户端的连接数限制。 maxSessionTimeout=120000 #Session超时时间限制,如果客户端设置的超时时间不在这个范围,那么会被强制设置为最大或最小时间。默认的Session超时时间是在2 * tickTime ~ 20 * tickTime 这个范围 New in 3.3.0 minSessionTimeout=4000 #Session超时时间限制,如果客户端设置的超时时间不在这个范围,那么会被强制设置为最大或最小时间。默认的Session超时时间是在2 * tickTime ~ 20 * tickTime 这个范围 New in 3.3.0 autopurge.snapRetainCount=3 #这个参数指定了需要保留的文件数目。默认是保留3个 autopurge.purgeInterval=1 #ZK提供了自动清理事务日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是0,表示不开启自动清理功 server.1=0.0.0.1:2888:388 #zookeeper 集群监听地址 server.2=0.0.0.2:2888:3888 #zookeeper 集群监听地址 server.3=0.0.0.3:2888:3888 #zookeeper 集群监听地址 4lw.commands.whitelist=mntr.conf.ruok #是为了对 ZooKeeper 可以执行的命令集提供细粒度的控制 |
3.4 启动 Z ookeeper
#/app/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
三台ZK,两台是follower,一台是leader。集群启动成功
/app/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /app/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
/app/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /app/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
3.5 Z ookeeper添加系统启动
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| #cat >>/etc/systemd/system/zookeeper.service <<EOF Unit Description=Zookeeper Service unit Configuration After=network.target Service Type=forking Environment=JAVA_HOME=/usr/java/jdk1.8.0_331 CLASSPATH=JAVA_HOME/lib/tools.jar:JAVA_HOME/lib/dt.jar:$CLASSPATH ExecStartPost=/bin/sleep 2 ExecStart=/app/zookeeper/bin/zkServer.sh start /app/zookeeper/conf/zoo.cfg ExecStop=/app/zookeeper/bin/zkServer.sh stop PIDFile=/app/zk-data/data/zookeeper_server.pid KillMode=none User=zookeeper Group= zookeeper Restart=on-failure Install WantedBy=multi-user.target EOF |
| 添加开启自启 #systemctl enable zookeeper.service |
| 停止ZK #systemctl stop zookeeper.service 启动zk #systemctl start zookeeper.service |
3.6 ZK 配置
- 配置snapshot文件清理策略
autopurge.purgeInterval=1
autopurge.purgeInterval:开启清理事务日志和快照文件的功能,单位是小时。默认是0,表示不开启自动清理功能。
autopurge.snapRetainCount=10
autopurge.snapRetainCount:指定了需要保留的文件数目。默认是保留3个。
- 限制snapshot数量
snapCount=3000000
每snapCount次事务日志输出后,触发一次快照(snapshot)。 ZooKeeper会生成一个snapshot文件和事务日志文件。 默认是100000。
- log和data数据分磁盘存储
dataDir:存储快照文件snapshot的目录。默认情况下,事务日志也会存储在这里。
dataLogDir:事务日志输出目录。尽量给事务日志的输出配置单独的磁盘或是挂载点,这将极大的提升ZK性能。
- 调整JVM大小
ZooKeeper的JVM内存默认是根据操作系统本身内存大小的一个百分比预先分配的,所以这不是我们所需要的。
在./bin/zkEnv.sh文件中,有如下配置项:
if -f "$ZOOCFGDIR/java.env"
then
. "$ZOOCFGDIR/java.env"
fi
我们在./conf/java.env文件中配置JVM的内存,增加如下配置:
export JAVA_HOME=/app/jdk
export JVMFLAGS="-Xms10240m -Xmx20480m $JVMFLAGS"
修改完成使用jmap -heap $pid来验证内存修改情况。
- ZNode中可以存储数据星的最大值,默认值是1M。
jute.maxbuffer
修改jvm内存参数jute.maxbuffer大小调整到10M=10240KB=10485760Bytes
修改bin/zkServer.sh或者zkEnv.sh
JVMFLAGS="$JVMFLAGS -Djute.maxbuffer=10485760"
4. zookeeper开启ssl
4.1 使用keytool生成客户端和服务端证书
生成含有一个私钥的keystore文件
keytool -genkeypair -alias certificatekey -keyalg RSA -validity 3650 -keystore keystore.jks
查看生成的keystore文件
keytool -list -v -keystore keystore.jks
导出证书
keytool -export -alias certificatekey -keystore keystore.jks -rfc -file selfsignedcert.cer
导入证书到truststore文件中
keytool -import -alias certificatekey -file selfsignedcert.cer -keystore truststore.jks
查看生成的truststore文件
keytool -list -v -keystore truststore.jks
4.2 Zookeeper服务端添加ssl
方案一:添加到配置文件
在zoo.cfg里面添加
serverCnxnFactory=org.apache.zookeeper.server.NettyServerCnxnFactory
ssl.keyStore.location=/app/zookeeper/cert/keystore.jks
ssl.keyStore.password=123456
ssl.trustStore.location=/app/zookeeper/cert/truststore.jks
ssl.trustStore.password=123456
方案二:以变量的形式添加
在zkServer.sh开头添加
export SERVER_JVMFLAGS="
-Dzookeeper.serverCnxnFactory=org.apache.zookeeper.server.NettyServerCnxnFactory
-Dzookeeper.ssl.keyStore.location=/app/zookeeper/cert/keystore.jks
-Dzookeeper.ssl.keyStore.password=123456
-Dzookeeper.ssl.trustStore.location=/app/zookeeper/cert/truststore.jks
-Dzookeeper.ssl.trustStore.password=123456"
配置文件添加安全端口
zoo.cfg需要额外添加安全端口
secureClientPort=2183
为了防止全网监听
secureClientPortAddress=192.168.10.133 注:修改为本机ip地址
启动服务
./zkServer.sh start或systemctl start zookeeper.service
5. 配置Zookeeper ACL权限
ZooKeeper的ACL权限控制, 可以控制节点的读写操作, 保证数据的安全性,ZookeeperACL权限设置分为3部分组成, 分别是:权限模式(Scheme ) 、授权对象I(ID) 、权限信息(Permission ) 。最终组成一条例如"scheme:id:permission"格式的ACL请求信息
ZookeeperACL权限设置分为3部分组成, 分别是:权限模式(Scheme ) 、授权对象I(ID) 、权限信息(Permission ) 。最终组成一条例如"scheme:id:permission"格式的ACL请求信息
(1)权限模式(scheme):授权的策略。
(2)权限对象(id):授权的对象。
(3)权限(permission):授予的权限。
5.1 权限模式(Scheme)
权限模式(scheme):授权的策略
|--------|--------------------------------------------------|
| 模式 | 描述 |
| world | 这种模式方法的授权对象只有一个anyone,代表登录到服务器的所有客户端都能对该节点执行某种权限 |
| ip | 对连接的客户端使用IP地址认证方式进行认证 |
| auth | 使用以添加认证的用户进行认证 |
| digest | 使用 用户:密码方式验证 |
5.2 权限类型(permission)
权限(permission):授予的权限:
|--------|-------|-----------------|
| 类型 | ACL简写 | 描述 |
| read | r | 读取节点及显示子节点列表的权限 |
| write | w | 设置节点数据的权限 |
| create | c | 创建子节点的权限 |
| delete | d | 删除子节点的权限 |
| admin | a | 设置该节点ACL权限的权限 |
5.3 授权的命令
授权的命令:
|---------|----------------------|----------------|
| 命令 | 用法 | 描述 |
| getAcl | getAcl path | 读取节点的ACL |
| setAcl | setAcl path acl | 设置节点的ACL |
| create | create path data acl | 创建节点时设置acl |
| addAuth | addAuth scheme auth | 添加认证用户,类似于登录操作 |
生成授权ID
在xshell中生成
echo -n <user>:<password> | openssl dgst -binary -sha1 | openssl base64
示例:
echo -n angel:123456 | openssl dgst -binary -sha1 | openssl base64
返回的结果是:5qPtfHTjrZrZ4DGSxBY8+G6AhiM=
5.4 设置ACL(两种方式)
方案一:
创建设置ACL
create -s -e -c path data acl
示例
./zkCli.sh
create /test1 'hello' digest:angel:5qPtfHTjrZrZ4DGSxBY8+G6AhiM=:cdrwa
方案二:
或者直接使用setAcl 设置(属于另一种方案)
setAcl /test1 digest:angel:5qPtfHTjrZrZ4DGSxBY8+G6AhiM=:cdrwa
访问 /test1,会出现权限不足
zk: localhost:2181(CONNECTED) 1 get /test1
Insufficient permission : /test1
访问前需要添加授权信息
|----------------------------------------------------------------------------------------------------------------------|
| addauth digest angel:123456 |
| zk: localhost:2181(CONNECTED) 2 addauth digest angel:123456 zk: localhost:2181(CONNECTED) 3 get /test1 hello |
5.4.1 明文授权
另一种授权模式: auth 明文授权
使用之前需要先注册用户信息
addauth digest username:password
注册用户信息,后续可以直接用明文授权
|----------------------------------------------------------------------------------------------------|
| zk: localhost:2181(CONNECTED) 4 addauth digest wuqian:123456 |
| zk: localhost:2181(CONNECTED) 5 create /test2 'hello2' auth:wuqian:123456:cdwra Created /test2 |
| zk: localhost:2181(CONNECTED) 6 get /test2 |
5.4.2 IP授权模式
方式1:setAcl /test3 ip:192.168.0.106:cdwra
方式2:create /test data ip:192.168.0.106:cdwra
5.5关闭ACL
可以通过系统参数zookeeper.skipACL=yes进行配置,默认是no,可以配置为true, 则配置过的ACL将不再进行权限检测
编辑配置启动文件 vim bin/zkServer.sh,然后添加启动参数-D:
53 ZOOMAIN="-Dzookeeper.skipACL=yes -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=$JMXLOCALONLY org.apache.zookeeper.server.quor um.QuorumPeerMain"
重启zkServer,关闭ACL访问控制
./zkServer.sh restart