本博客来源于CSDN机器鱼,未同意任何人转载。
更多内容,欢迎点击本专栏,查看更多内容。
目录
[2. 网络搭建](#2. 网络搭建)
[3. 完整代码](#3. 完整代码)
[4. 结语](#4. 结语)
0.引言
在【博客】中,我们基于tensorflow2.x深度学习框架搭建了transformer模型用于时间序列预测,博客里较为详细的构建了位置编码、自注意力等模块。而从2017年发展到现在,因为tansformer大火,Pytorch已经将大部分基础模块写进了库函数中,因此我们可以用简单的几句程序搭建一个transformer。
主要用到的函数torch.nn.TransformerEncoderLayer。网上搜这个函数,可以看到内部集成了需要用到的多头注意力、LayerNorm等函数。同理Pytorch内部也集成了decoder,可以搜torch.nn.TransformerDecoderLayer。因此我们搭建一个transformer网络可以很简单。
1.数据准备
这次的数据两列的时间序列,如下所示。我们采用前n时刻的平均风速与平均功率,预测第n+1:n+m时刻的平均功率值。
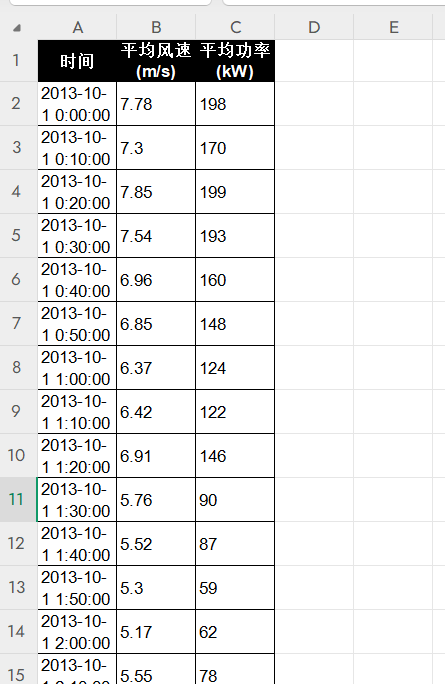
数据拆分的代码如下:
数据含有2个特征,采用滚动序列建模的方法,生成输入数据与输出数据。具体为:设定输入时间步m与输出时间步n,然后取第1到m时刻的所有数据作为输入,取第m+1到第m+n时刻的功率作为输出,作为第一个样本;然后取第2到m+1时刻的所有数据作为输入,取第m+2到第m+n+1时刻的功率作为输出,作为第二个样本。。。依次类推,通过这种滚动的方法获得输入输出数据。举个例子,当m取10,n取3时,则输入层的维度为None,10,2,输出层的维度为None,3,模型训练好后,只需要输入过去10个时刻的所有数据,就能预测得到未来3个时刻的功率预测值。最后不要忘记了对数据进行归一化或者标准化
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler,StandardScaler
def create_inout_sequences(input_data, input_window,output_window):
in_seq,out_seq = [],[]
L = len(input_data)
for i in range(L-input_window-output_window+1):
train_seq = input_data[i:i+input_window,:]
train_label = input_data[i+input_window:i+input_window+output_window,-1]
in_seq.append(train_seq)
out_seq.append(train_label)
in_seq=np.array(in_seq).reshape(len(in_seq), -1)
out_seq=np.array(out_seq).reshape(len(out_seq), -1)
return in_seq,out_seq
# In[] 生成数据
input_window = 100 # number of input steps
output_window = 1 # number of prediction steps
series = pd.read_excel('数据.xlsx').iloc[:,1:]
seriesdata=series.values#第一列是风速 第二列是功率
# 我们用前input_window个时刻的是风速与功率值预测output_window时刻的功率值
data,label = create_inout_sequences(seriesdata,input_window,output_window)
# 数据划分 前70%训练 后30%测试
n=np.arange(data.shape[0])
m=int(0.7*data.shape[0])
train_data=data[n[0:m],:]
train_label=label[n[0:m]]
test_data=data[n[m:],:]
test_label=label[n[m:]]
# 归一化
ss_X = StandardScaler().fit(train_data)
ss_Y = StandardScaler().fit(train_label)
# ss_X=MinMaxScaler(feature_range=(0,1)).fit(train_data)
# ss_Y=MinMaxScaler(feature_range=(0,1)).fit(train_label)
train_data = ss_X.transform(train_data).reshape(train_data.shape[0],input_window,-1)
train_label = ss_Y.transform(train_label)
test_data = ss_X.transform(test_data).reshape(test_data.shape[0],input_window,-1)
test_label = ss_Y.transform(test_label)
feature_size=train_data.shape[-1]
out_size=train_label.shape[-1]2. 网络搭建
与【博客】一致,我们仅搭建一个encoder,直接将encoder的输出flatten成向量,然后输入进dense实现回归预测。网络构建部分的主要代码如下所示:
import torch
import torch.nn as nn
import numpy as np
#torch.manual_seed(0)
#np.random.seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class PositionalEncoding(nn.Module):
#https://zhuanlan.zhihu.com/p/389183195
def __init__(self, d_model, max_len=5000,dropout=0.1):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
self.dropout = nn.Dropout(p=dropout)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
#pe.requires_grad = False
self.register_buffer('pe', pe)
def forward(self, x):
x= x + self.pe[:x.size(0), :]
return self.dropout(x)
class TransAm(nn.Module):
def __init__(self,feature_size=2,out_size=1,embedding_size=250,num_layers=1,dropout=0.1,nhead=10):
super(TransAm, self).__init__()
self.src_mask = None
self.embedding= nn.Linear(feature_size,embedding_size)
self.pos_encoder = PositionalEncoding(embedding_size)
self.encoder_layer = nn.TransformerEncoderLayer(d_model=embedding_size, nhead=nhead, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
self.decoder = nn.Linear(embedding_size,out_size)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self,src):
src=self.embedding(src)
if self.src_mask is None or self.src_mask.size(0) != len(src):
device = src.device
mask = self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask = mask
src = self.pos_encoder(src)
output = self.transformer_encoder(src,self.src_mask)#, self.src_mask)
output = self.decoder(output)
# print(output.size())
return output
def _generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask首先,我们用一个全连接层作为embed层,我们的数据特征是2维【平均风速与平均功率】,经过embedding升维至d_model维度。然后加上位置编码,最后将编码后的数据送至num_layer个transformerlayer构成的encoder中,并将encoder的结果输入dense实现预测输出,网络搭建就这么几句.
值得注意的是nn.TransformerEncoder接受的数据格式seq_len,batchsize,d_model,输出也是seq_len,batchsize,d_model。并且可以不输入src_mask,用None替代也行。
3. 完整代码
有了数据、模型之后,搭配上损失函数,训练步骤就可以了,完整的代码如下:
import torch
import torch.nn as nn
import numpy as np
import math
import matplotlib.pyplot as plt
from sklearn.metrics import r2_score
from sklearn.preprocessing import MinMaxScaler,StandardScaler
import pandas as pd
#torch.manual_seed(0)
#np.random.seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#device = torch.device("cpu")
# In[] 此函数用于最后计算各种指标
def result(real,pred,name):
# ss_X = MinMaxScaler(feature_range=(-1, 1))
# real = ss_X.fit_transform(real).reshape(-1,)
# pred = ss_X.transform(pred).reshape(-1,)
real=real.reshape(-1,)
pred=pred.reshape(-1,)
# mape
test_mape = np.mean(np.abs((pred - real) / real))
# rmse
test_rmse = np.sqrt(np.mean(np.square(pred - real)))
# mae
test_mae = np.mean(np.abs(pred - real))
# R2
test_r2 = r2_score(real, pred)
print(name,'的mape:%.4f,rmse:%.4f,mae:%.4f,R2:%.4f'%(test_mape ,test_rmse, test_mae, test_r2))
#位置编码
class PositionalEncoding(nn.Module):
#https://zhuanlan.zhihu.com/p/389183195
def __init__(self, d_model, max_len=5000,dropout=0.1):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
self.dropout = nn.Dropout(p=dropout)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
#pe.requires_grad = False
self.register_buffer('pe', pe)
def forward(self, x):
x= x + self.pe[:x.size(0), :]
return self.dropout(x)
#主网络
class TransAm(nn.Module):
def __init__(self,feature_size=2,out_size=1,embedding_size=250,num_layers=1,dropout=0.1,nhead=10):
super(TransAm, self).__init__()
self.src_mask = None
self.embedding= nn.Linear(feature_size,embedding_size)
self.pos_encoder = PositionalEncoding(embedding_size)
self.encoder_layer = nn.TransformerEncoderLayer(d_model=embedding_size, nhead=nhead, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
self.decoder = nn.Linear(embedding_size,out_size)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self,src):
src=self.embedding(src)
if self.src_mask is None or self.src_mask.size(0) != len(src):
device = src.device
mask = self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask = mask
src = self.pos_encoder(src)
output = self.transformer_encoder(src,self.src_mask)#, self.src_mask)
output = self.decoder(output)
# print(output.size())
#nn.TransformerEncoder的输入与输出都是(seqlen,batchsize,d_model)
#这里经过self.decoder之后变成了(seqlen,batchsize,out_size)
#由于数据处理里面我只预测了未来一个时刻的,所以这里取了[-1]
return output[-1]
def _generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def create_inout_sequences(input_data, input_window,output_window):
in_seq,out_seq = [],[]
L = len(input_data)
for i in range(L-input_window-output_window+1):
train_seq = input_data[i:i+input_window,:]
train_label = input_data[i+input_window:i+input_window+output_window,-1]
in_seq.append(train_seq)
out_seq.append(train_label)
in_seq=np.array(in_seq).reshape(len(in_seq), -1)
out_seq=np.array(out_seq).reshape(len(out_seq), -1)
return in_seq,out_seq
def get_batch(source,target, i,batch_size):
## transformer 只能输入 seqlenth x batch x dim 形式的数据。
#所以这里做一下转换
seq_len = min(batch_size, len(source) - 1 - i)
input_ = source[i:i+seq_len]
input_=torch.FloatTensor(input_).to(device)
target_ = target[i:i+seq_len]
target_=torch.FloatTensor(target_).to(device)
input_ = torch.stack(input_.chunk(input_window,1))
# target_ = torch.stack(target_.chunk(input_window,1))
input_=input_.squeeze(2)
# target_=target_.unsqueeze(2)
return input_, target_
def evaluate(eval_model, data_source,data_target):
eval_model.eval() # Turn on the evaluation mode
total_loss = 0.
eval_batch_size = 64
with torch.no_grad():
for i in range(0, len(data_source) - 1, eval_batch_size):
source, targets = get_batch(data_source,data_target, i,eval_batch_size)
output = eval_model(source)
total_loss += len(data[0])* criterion(output, targets).cpu().item()
return total_loss / len(data_source)
# In[] 生成数据
input_window = 100 # number of input steps
output_window = 1 # number of prediction steps
series = pd.read_excel('数据.xlsx').iloc[:,1:]
seriesdata=series.values#第一列是风速 第二列是功率
# 我们用前input_window个时刻的是风速与功率值预测input_window时刻的功率值
data,label = create_inout_sequences(seriesdata,input_window,output_window)
# 数据划分 前70%训练 后30%测试
n=np.arange(data.shape[0])
m=int(0.7*data.shape[0])
train_data=data[n[0:m],:]
train_label=label[n[0:m]]
test_data=data[n[m:],:]
test_label=label[n[m:]]
# 归一化
ss_X = StandardScaler().fit(train_data)
ss_Y = StandardScaler().fit(train_label)
# ss_X=MinMaxScaler(feature_range=(0,1)).fit(train_data)
# ss_Y=MinMaxScaler(feature_range=(0,1)).fit(train_label)
train_data = ss_X.transform(train_data).reshape(train_data.shape[0],input_window,-1)
train_label = ss_Y.transform(train_label)
test_data = ss_X.transform(test_data).reshape(test_data.shape[0],input_window,-1)
test_label = ss_Y.transform(test_label)
feature_size=train_data.shape[-1]
out_size=train_label.shape[-1]
# In[]
model = TransAm(feature_size=feature_size,out_size=out_size,embedding_size=250,num_layers=1,dropout=0.1,nhead=10).to(device)
criterion = nn.MSELoss()
lr = 0.005
batch_size = 64
epochs = 100
#optimizer = torch.optim.SGD(model.parameters(), lr=lr)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
best_val_loss = float("inf")
best_model = None
train_all_loss,val_all_loss=[],[]
for epoch in range(1, epochs + 1):
model.train() # Turn on the train mode \o/
for batch, i in enumerate(range(0, len(train_data) - 1, batch_size)):
source, targets = get_batch(train_data,train_label, i,batch_size)
optimizer.zero_grad()
output = model(source)
loss = criterion(output, targets)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.7)
optimizer.step()
model.eval()
train_loss=evaluate(model, train_data,train_label)
val_loss=evaluate(model, test_data,test_label)
val_all_loss.append(val_loss)
train_all_loss.append(train_loss)
print('| end of epoch {:3d} | train loss {:5.5f} | valid loss {:5.5f}'.format(
epoch, train_loss, val_loss))
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model=model
torch.save(best_model, 'model/best_model0.pth')
scheduler.step()
torch.save(model, 'model/last_model0.pth')
plt.figure
plt.plot(train_all_loss,label='train_loss')
plt.plot(val_all_loss,label='valid_loss')
plt.legend()
plt.title('loss curve')
plt.savefig('model/loss.jpg')
plt.show()
# In[] 预测
# 预测并画图
model=torch.load('model/best_model0.pth', map_location=device).to(device)
model.eval()
eval_batch_size = 64
truth,test_result=np.zeros((0,test_label.shape[-1])),np.zeros((0,test_label.shape[-1]))
for i in range(0, len(test_data) - 1, eval_batch_size):
data, targets = get_batch(test_data,test_label, i,eval_batch_size)
output = model(data)
output=output.cpu().detach().numpy()
targets=targets.cpu().detach().numpy()
test_result = np.vstack([test_result, output])
truth = np.vstack([truth, targets])
predict = ss_Y.inverse_transform(test_result)
truth = ss_Y.inverse_transform(truth)
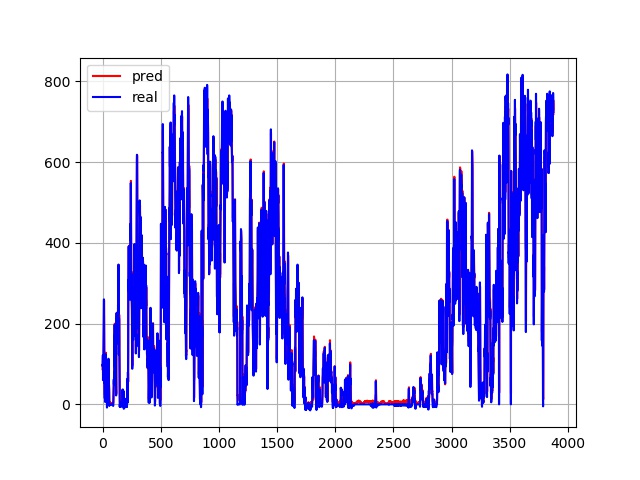
result(truth,predict,'Transformer')
plt.figure()
plt.plot(predict,color="red",label='pred')
plt.plot(truth,color="blue",label='real')
plt.grid(True, which='both')
plt.legend()
plt.savefig('model/result.jpg')
plt.show()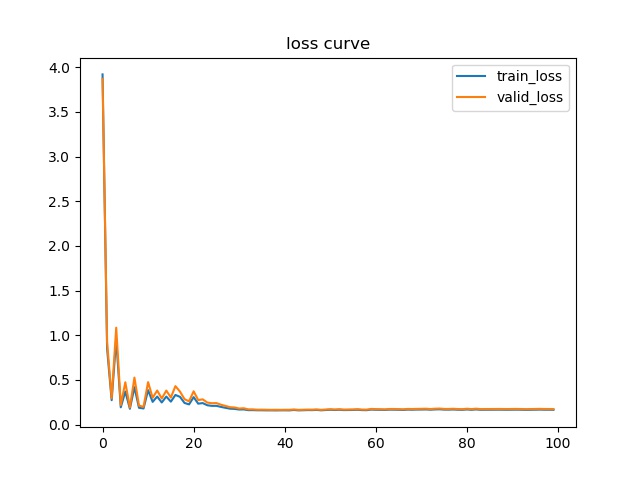
4. 结语
获取更多内容请点击【专栏】,您的点赞与收藏是我持续更新【Python神经网络1000个案例分析】的动力