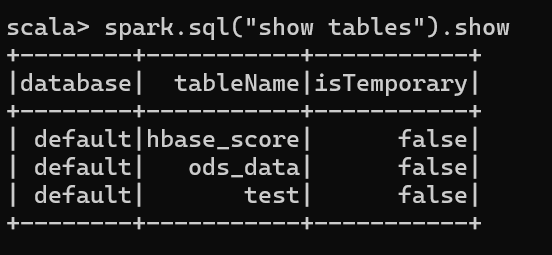
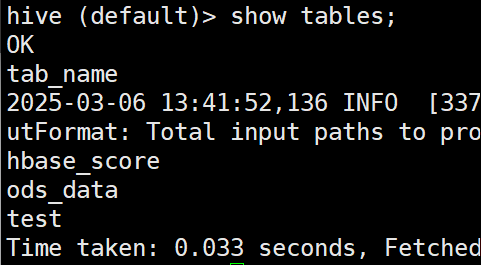
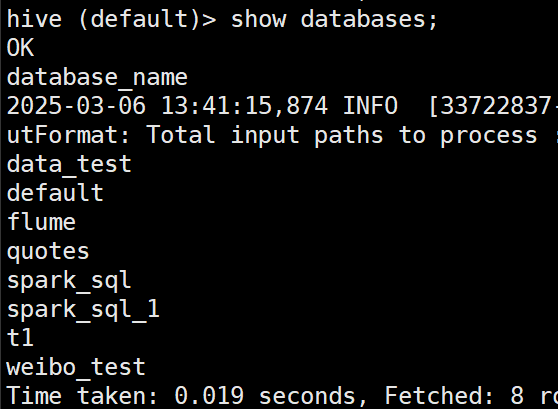
本节课学习了spark连接hive数据,在 spark-shell 中,可以看到连接成功
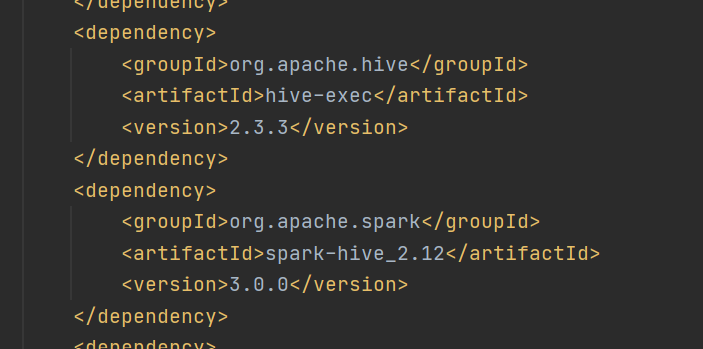
将依赖放进pom.xml中
运行代码

创建文件夹 spark-warehouse
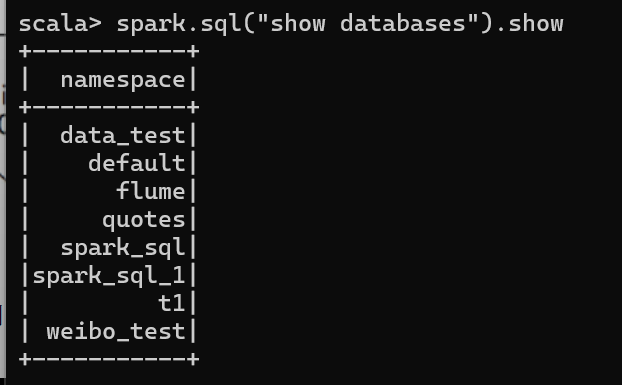
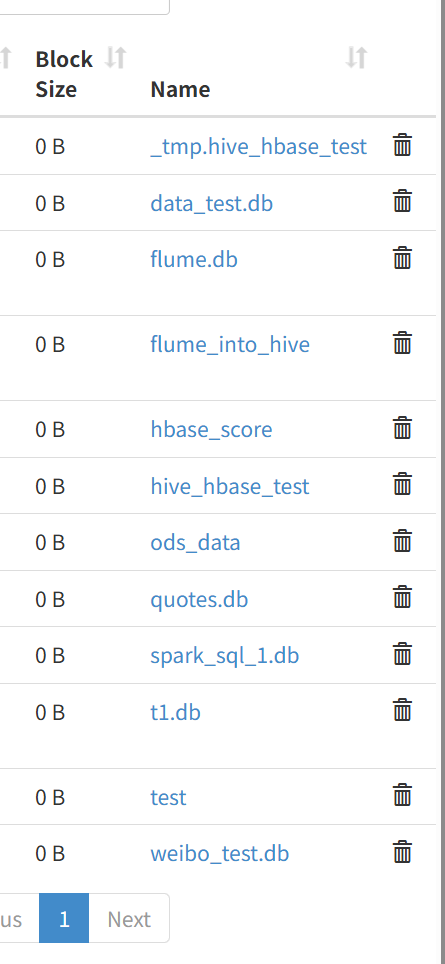
为了使在 node01:50070 中查看到数据库,需要添加如下代码,就可以看到新创建的数据库 spark-sql_1
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object HiveSupport {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("hql")
val spark = SparkSession.builder().enableHiveSupport()
.config("spark.sql.warehouse.dir", "hdfs://node01:9000/user/hive/warehouse")
.config(sparkConf).getOrCreate()
if (!spark.catalog.databaseExists("spark_sql_1")) {
spark.sql("create database spark_sql_1")
}
spark.sql("use spark_sql_1")
// 创建表
spark.sql(
"""
|create table json(data string)
|row format delimited
|""".stripMargin)
spark.sql("load data local inpath 'Spark-SQL/input/movie.txt' into table json")
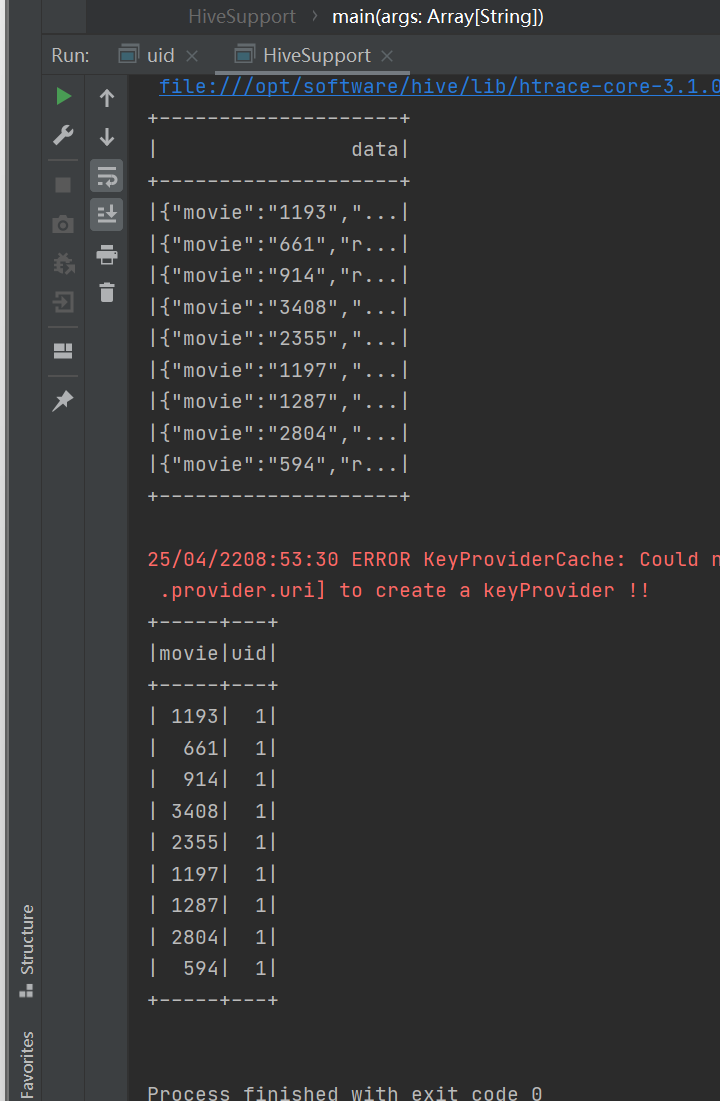
spark.sql("select * from json").show()
spark.sql(
"""
|create table movie_info
|as
|select get_json_object(data,'$.movie') as movie,
|get_json_object(data,'$.uid') as uid
|from json
|""".stripMargin)
spark.sql("select * from movie_info").show()
spark.stop()
}
}
可以使用提取数据
运行结果
实验报告
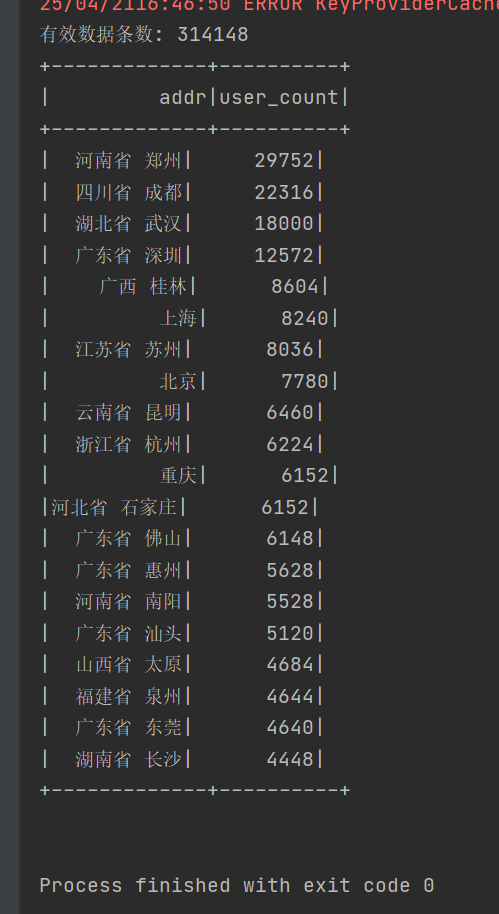
将数据放进input中,并运行如下代码,用于输出统计有效数据条数 及用户数量最多的前二十个地址
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object uid {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("JsonDataAnalysis")
val spark = SparkSession.builder().enableHiveSupport()
.config("spark.sql.warehouse.dir", "hdfs://node01:9000/user/hive/warehouse")
.config(sparkConf).getOrCreate()
// 使用spark-sql_1数据库
spark.sql("use spark_sql_1")
// 创建表用于存储原始JSON数据-uid
spark.sql(
"""
|create table if not exists data_set(data string)
|row format delimited
|""".stripMargin)
// 加载json数据到uid表中
spark.sql("load data local inpath 'D:/school/workspace/workspace-IJ/Spark/Spark-SQL/input/user_login_info.json' into table data_set")
// 判断filter_data表是否存在,若存在则删除(可根据实际需求调整此处逻辑,比如不删除直接使用等)
if (spark.catalog.tableExists("spark_sql_1.filter_data")) {
spark.sql("drop table filter_data")
}
// 筛选数据(不是null的)并创建filter_data表
spark.sql(
"""
|create table filter_data
|as
|select
| get_json_object(data, '$.uid') as uid,
| get_json_object(data, '$.phone') as phone,
| get_json_object(data, '$.addr') as addr
|from
| data_set
|where
| get_json_object(data, '$.uid') is not null
| and get_json_object(data, '$.phone') is not null
| and get_json_object(data, '$.addr') is not null
|""".stripMargin)
// 统计有效数据条数
val validDataCount = spark.sql("select count(*) from filter_data").collect()(0)(0).toString.toLong
println(s"有效数据条数: $validDataCount")
// 统计每个地址的用户数量并排序,取前20
spark.sql(
"""
|select
| addr,
| count(*) as user_count
|from
| filter_data
|group by
| addr
|order by
| user_count desc
|limit 20
|""".stripMargin).show()
spark.stop()
}
}运行结果: