1. 数据集的准备
猫狗识别的数据集依旧可以从Kaggle上下载,数据集下载链接:
https://www.kaggle.com/c/dogs-vs-cats
下载后解压,得到如下的文件夹

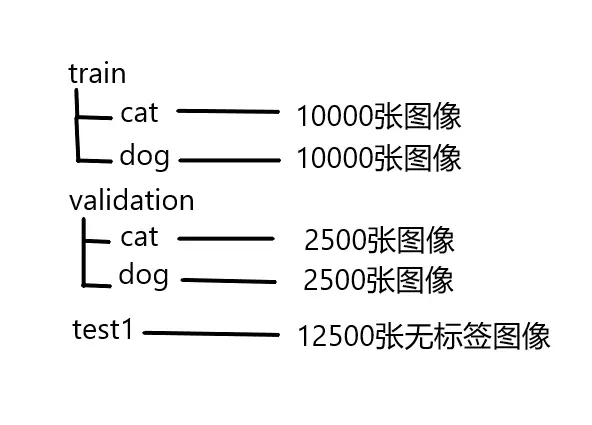
文件夹train里面放着25000张图像,猫和狗的图像分别都是12500张,图像名称上都有标明类别。文件夹test1里面放的是测试集,里面有12500张图像,都没有标签,要自己来预测分类。
把数据集目录整理成如下的形式

文件夹test1不变,新建一个文件夹validation,在文件夹train中分别拿出猫和狗的图像各2500张,存到文件夹validation中。文件夹train和validation内都要新建文件夹cat和dog,分别把猫和狗的图像都存到对应文件夹中。

这时候数据集目录结构如下
2. 数据集的导入
在训练前,先导入训练集和验证集。使用keras.preprocessing.image.ImageDataGenerator()做图像增强的数据预处理设置,再使用flow_from_directory()从文件路径中导入数据集,并设置图像大小、batch_size和是否shuffle等参数。
python
train_datagen = keras.preprocessing.image.ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(width, height),
batch_size=batch_size,
seed=7,
shuffle=True,
class_mode='categorical'
)
valid_datagen = keras.preprocessing.image.ImageDataGenerator(
rescale=1. / 255,
)
valid_generator = valid_datagen.flow_from_directory(
valid_dir,
target_size=(width, height),
batch_size=valid_batch_size,
seed=7,
shuffle=False,
class_mode="categorical"
)3. 编写神经网络结构
编写一个非常基础的卷积神经网络
model = keras.models.Sequential([
keras.layers.Conv2D(filters=32, kernel_size=3,
padding='same', activation='relu',
input_shape=[width, height, channel]),
keras.layers.Conv2D(filters=32, kernel_size=3,
padding='same', activation='relu'),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Conv2D(filters=64, kernel_size=3,
padding='same', activation='relu'),
keras.layers.Conv2D(filters=64, kernel_size=3,
padding='same', activation='relu'),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Conv2D(filters=128, kernel_size=3,
padding='same', activation='relu'),
keras.layers.Conv2D(filters=128, kernel_size=3,
padding='same', activation='relu'),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(num_classes, activation='softmax')
])
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
model.summary()优化器使用adam,损失函数使用'categorical_crossentropy' ,metrics参数填入accuracy,评估模型在训练和测试过程中的准确率。
4. 模型训练
训练模型,设置callbacks,使用model.fit() 开始训练。
python
callbacks = [
keras.callbacks.TensorBoard(logdir),
keras.callbacks.ModelCheckpoint(output_model_file,
save_best_only=True,
save_weights_only=True),
keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3)
]
history = model.fit(
train_generator,
epochs=epochs,
validation_data = valid_generator,
callbacks = callbacks
)训练100步,看看效果。

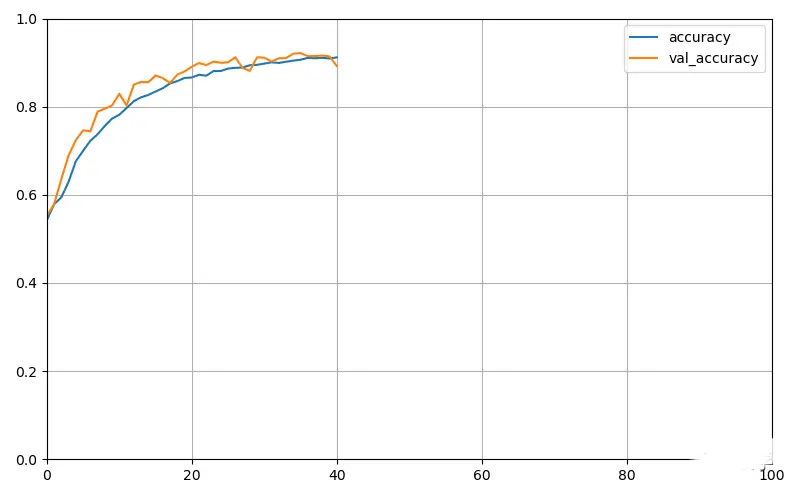
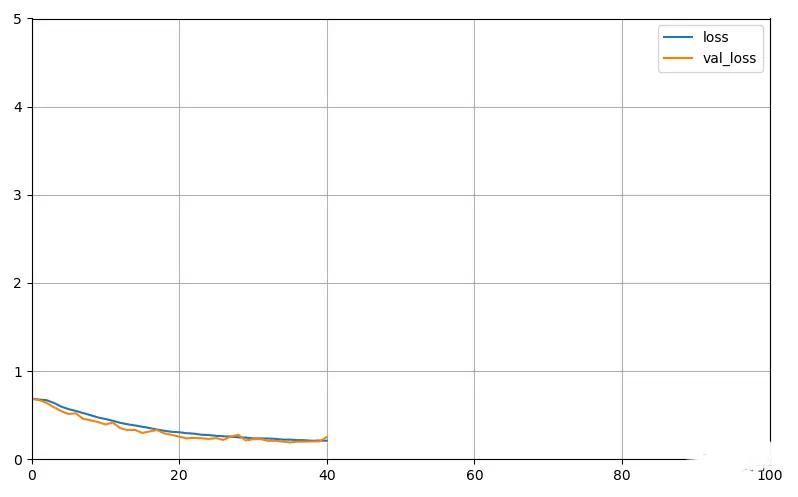
由于使用了EarlyStopping,当准确率在几个epochs内都没有提高超过一定幅度的话就会停止训练。由图可以看出,训练到40个epoch左右验证集的准确率达到90%多了。下面是训练过程的准确率和损失值变化曲线!
5.预测和分类
先读取文件夹test1中的图像,使用 model.predict() 进行预测,再根据预测结果把图像进行分类,分别存储到 猫 和 狗 的文件夹中。
 分类为猫的图像
分类为猫的图像
 分类为狗的图像
分类为狗的图像
预测的图像一共12500张,分类之后两个文件夹内分别都是6000多张,几乎持平,分类效果还是不错的。
项目源码+资料包↓
