UNIKGQA: UNIFIED RETRIEVAL AND REASONING FOR SOLVING MULTI-HOP QUESTION ANSWERING OVER KNOWLEDGE GRAPH(ICLR 2023)
Introduction
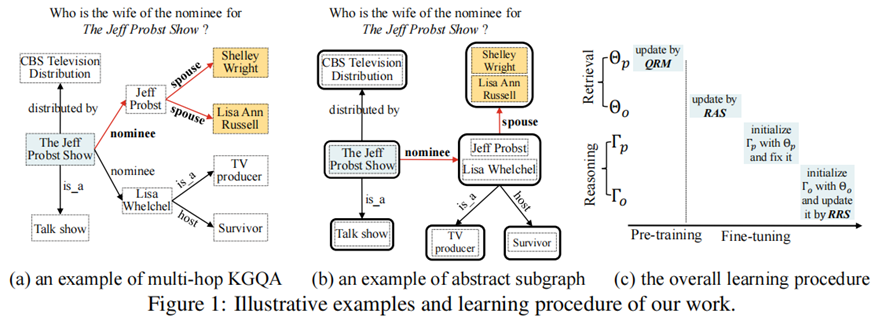
知识图上的多跳问题回答(KGQA)的目的是在大规模知识图谱(KG)上找到自然语言问题中提到的主题实体,然后进行多跳推理得到答案实体。
现有方法局限性
为了应对庞大的搜索空间,现有的工作通常采用两阶段的方法:首先检索与问题相关的相对较小的子图,然后对子图进行推理,以准确地找到答案实体。虽然这两个阶段是高度相关的,但以前的工作采用了非常不同的技术解决方案来开发检索和推理模型,而忽略了它们在任务本质上的相关性。
UniKGQA
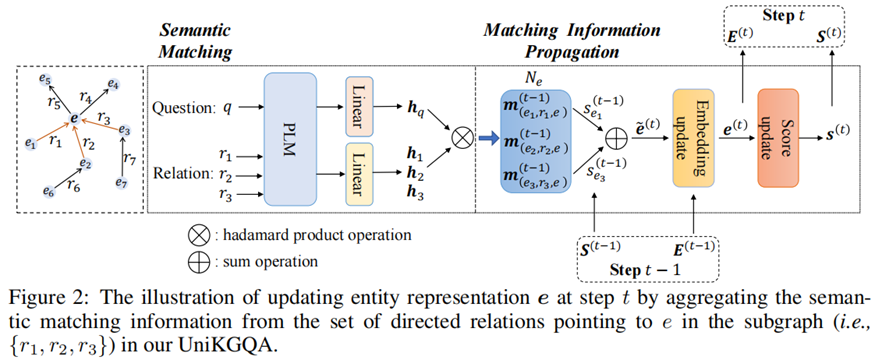
在本文中,我们提出了一种新的UniKGQA方法,该方法通过将检索和推理模型统一在模型架构和参数学习中,使得两个阶段更加紧密相关。具体来说,UniKGQA采用了基于预训练语言模型的语义匹配模块和匹配信息传播模块,并设计了共享预训练任务和检索、推理导向的微调策略。实验结果表明,UniKGQA在三个基准数据集上表现出了很好的效果。
Methodology
统一模型体系结构
Semantic Matching (SM)
语义匹配模块旨在生成问题与知识图谱中三元组的语义匹配特征。
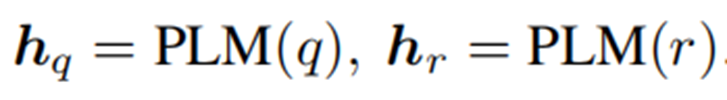
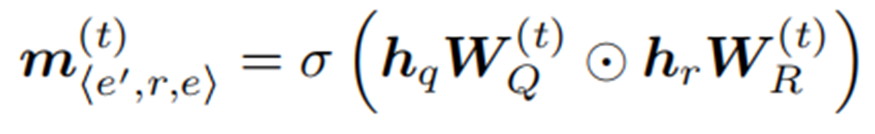
Matching Information Propagation (MIP)
MIP模块基于生成的语义匹配特征,首先对其进行聚合,更新实体表示,然后利用其获得实体匹配得分。
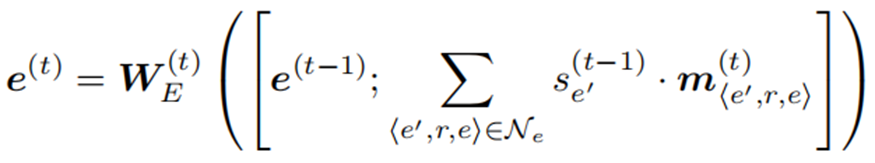
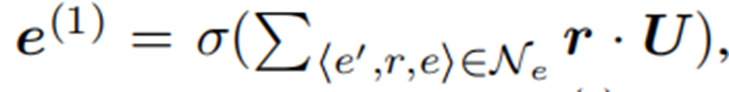
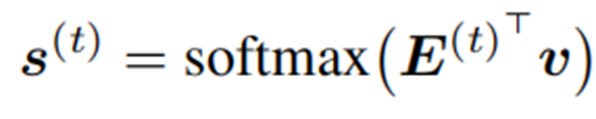
训练
多跳KGQA的两个阶段有检索模型和推理模型。由于这两个模型采用相同的架构,我们引入Θ和Γ来分别表示用于检索和推理阶段的模型参数。
模型体系结构包含两组参数,即底层的PLM和其他用于匹配和传播的参数。因此,Θ和Γ可以分解为: Θ = {Θp,Θo}和Γ = {Γp,Γo},其中下标p和o分别表示PLM参数和我们的架构中的其他参数。为了学习这些参数,我们设计了基于统一体系结构的预训练(即问题-关系匹配)和微调(即面向检索和推理的学习)策略。
Pre-training with Question-Relation Matching(QRM)
给定一个问题q,主题实体Tq和答案实体Aq,从整个KG中提取所有从Tq到Aq的最短路径,这些最短路径所包含的关系可以认为是与q相关的,将其集合表示为R+。在训练前,对于每个问题q,我们随机抽取一个相关的关系r+∈R+,利用对比学习损失进行预训练:
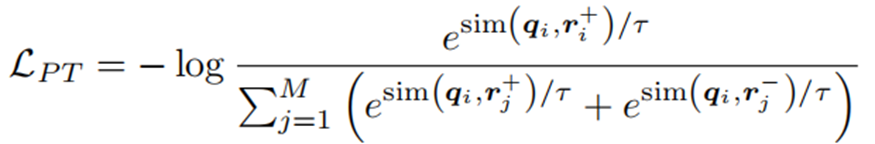
Fine-tuning for Retrieval on Abstract Subgraphs (RAS)
SA为抽象子图中的抽象结点的得分,如果抽象结点包括答案实体,将S*A=1赋给抽象节点。
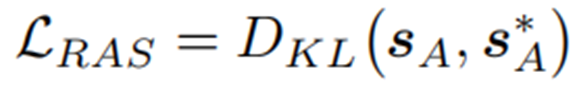
在对RAS损失进行微调后,可以有效地学习检索模型。进一步利用它来检索给定问题q的子图,根据匹配分数选择排名前k的节点。只有与主题实体保持合理距离内的节点才会被选择到子图中。
Fine-tuning for Reasoning on Retrieved Subgraphs (RRS)
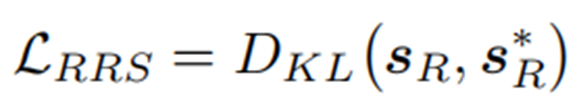
在对RRS损失进行微调后,可以利用学习到的推理模型,根据匹配分数选择排名前n位的实体作为答案列表。
Experiments
数据集

评价指标
子图提取评估标准:answer coverage rate (%)
推理评估标准:Hits@1,F1
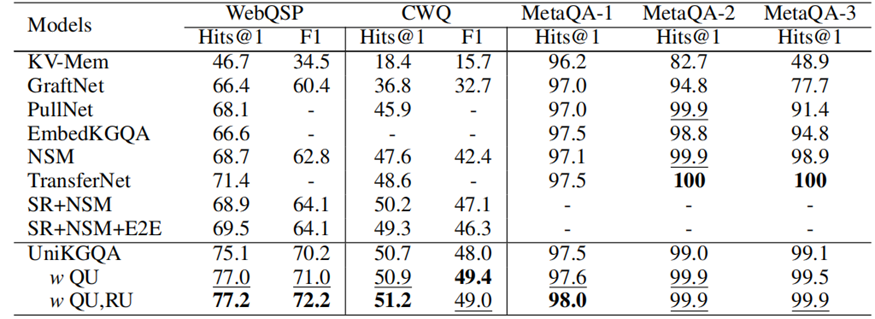
结果
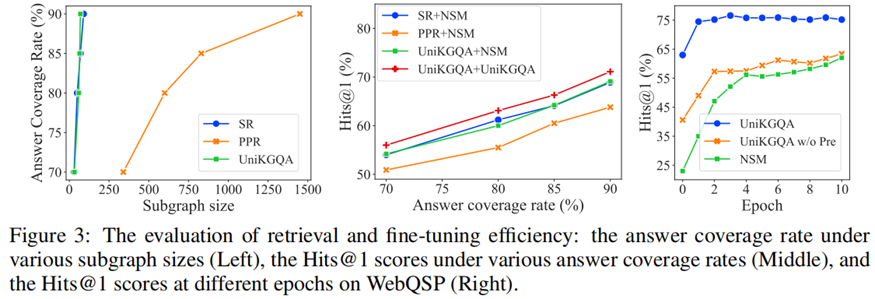
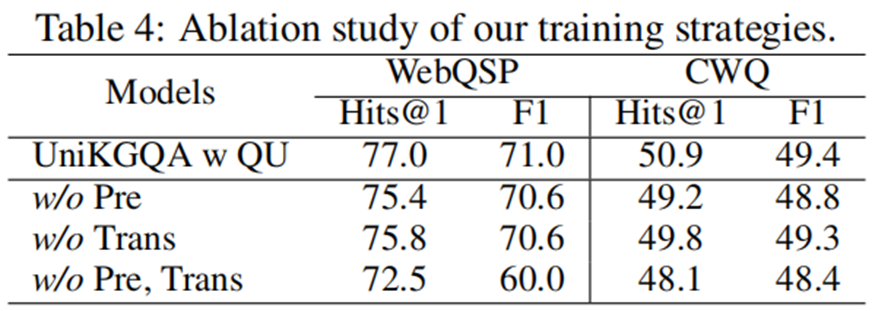
消融实验
Conclusion
提出了一种新的统一模型架构,可以同时处理多跳KGQA任务中的检索和推理阶段。使用抽象子图来减少检索阶段中节点的数量,从而提高效率。设计了有效的学习方法,包括预训练和微调策略,以利用两个阶段之间的共享信息,并提高了性能。在三个基准数据集上进行了广泛的实验,并取得了比现有最佳基线更好的结果。
方法创新点
创新地提出了一个统一的模型架构,将KGQA任务的检索和推理阶段紧密联系起来,以便更好地共享和传递相关信息。引入了抽象子图的概念,通过合并具有相同前缀(即相同的头部实体和关系)的尾部实体来减少检索阶段中节点的数量,从而提高了效率。设计了有效的学习方法,包括预训练和微调策略,以利用两个阶段之间的共享信息,并提高了性能。
未来展望
该研究为多跳KGQA提供了一个更加统一和简化的方法,但仍需要进一步探索如何更好地处理不同规模的数据分布以及如何更有效地分享和转移信息。可以考虑使用更多的预训练技术来进一步提高模型的性能。未来的研究还可以探索如何将这种方法扩展到其他类型的自然语言问答任务中。