前期几个工作提到,基于OCR的文档解析+RAG的方式进行知识库问答,受限文档结构复杂多样,各个环节的解析泛化能力较差,无法完美的对文档进行解析。因此出现了一些基于多模态大模型的RAG方案。如下:
下面再来看一个新的RAG框架VDocRAG,用于解决视觉文档问答问题。
视觉文档问答概述
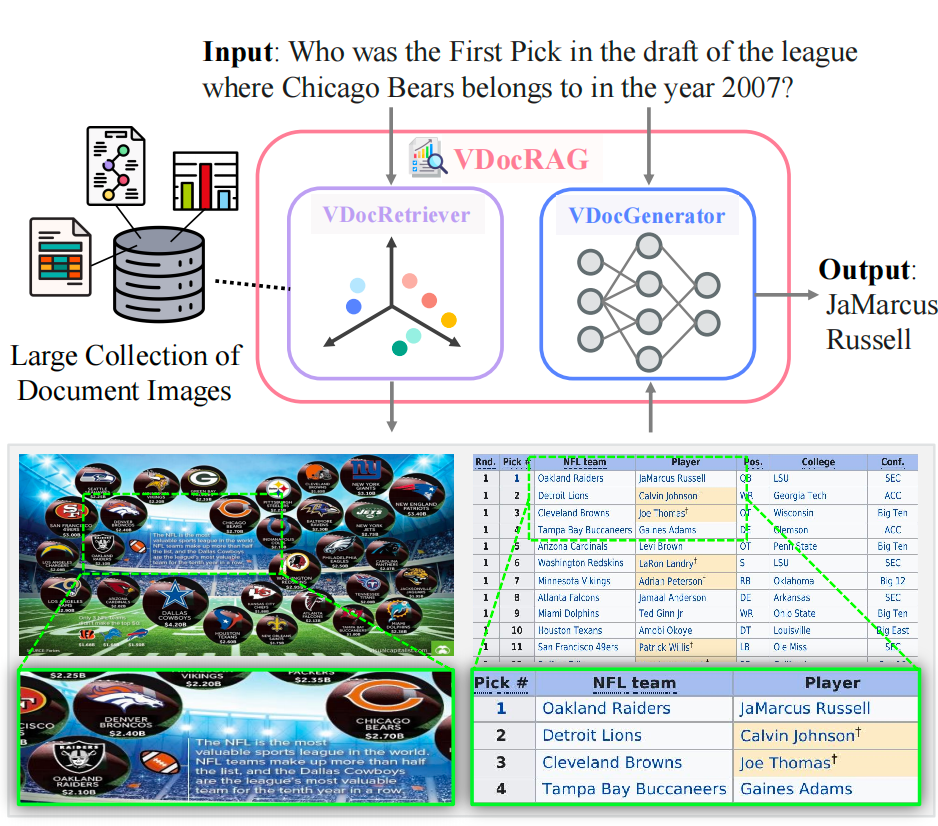
OpenDocVQA任务的目标是给定一个文档图像集合和一个问题,通过找到相关的文档图像来输出答案。任务分为两个阶段:
-
视觉文档检索(Visual Document Retrieval):
- 输入:一个查询问题 Q Q Q 和一个文档图像集合 I \mathcal{I} I。
- 输出:从集合中检索出与问题相关的 k k k 个文档图像 I ^ \hat{\mathcal{I}} I^,其中 k ≪ N k \ll N k≪N(即 k k k 远小于文档集合的大小)。
- 目标:通过检索相关的文档图像来帮助生成答案。
-
文档视觉问答(DocumentVQA):
- 输入:查询问题 Q Q Q 和检索到的文档图像 I ^ \hat{\mathcal{I}} I^。
- 输出:生成一个答案 A A A。
- 目标:利用检索到的文档图像来生成准确的答案。
方法架构
VDocRAG由两个主要组件组成:VDocRetriever和VDocGenerator,下面来看看这两个组件。
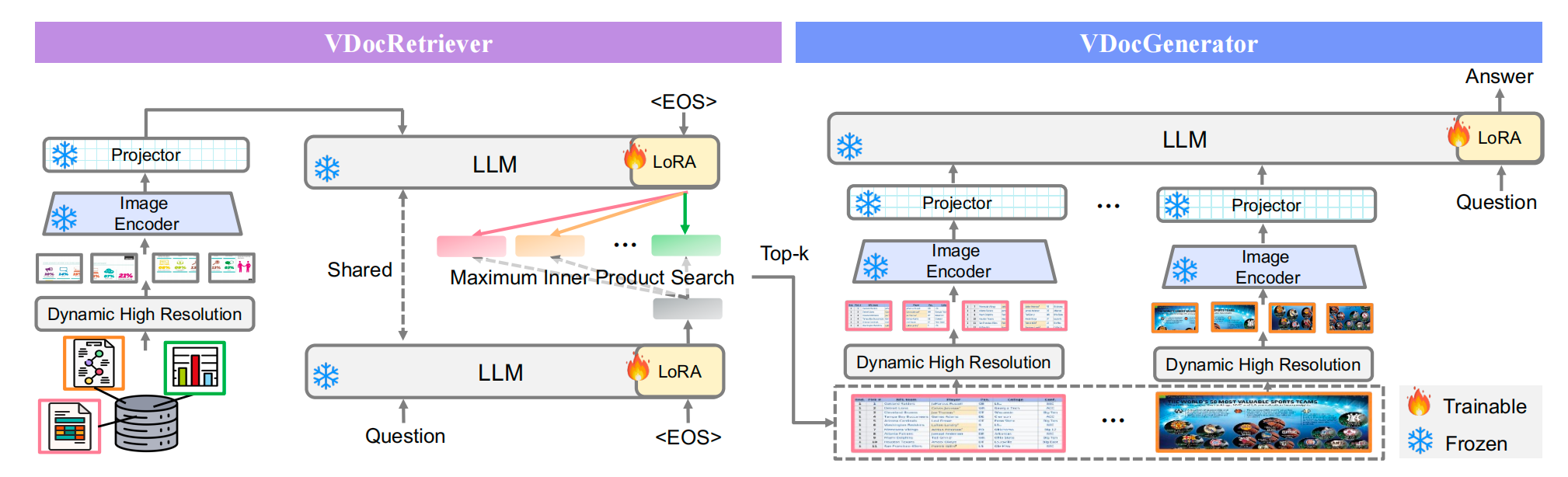
VDocRetriever(检索器)
VDocRetriever基于LVLM的双编码器架构,用于检索与查询问题相关的文档图像。
-
动态高分辨率图像编码 :使用动态裁剪将高分辨率图像分割成较小的patch,每个patch大小为 336 × 336 336 \times 336 336×336 像素。将这些patch作为单独的输入传递给图像编码器,并将其转换为视觉文档特征 z d z_d zd。
-
编码过程 :在VDocRetriever中,问题和视觉文档特征被独立编码。在问题的末尾添加一个 ⟨ E O S ⟩ \langle EOS \rangle ⟨EOS⟩(End of Sequence)标记,并将其与视觉文档特征一起输入到LVLM中。通过取最后一个 ⟨ E O S ⟩ \langle EOS \rangle ⟨EOS⟩ 向量来获得问题和视觉文档的嵌入 h q h_q hq 和 h d h_d hd。
-
相似度计算 :使用最大内积搜索计算问题和视觉文档嵌入之间的相似度分数:
SIM ( h q , h d ) = h q ⊤ h d ∥ h q ∥ ∥ h d ∥ \operatorname{SIM}(h_q, h_d) = \frac{h_q^{\top} h_d}{\|h_q\| \|h_d\|} SIM(hq,hd)=∥hq∥∥hd∥hq⊤hd -
检索过程 :根据相似度分数检索与问题最相关的 k k k 个文档。
VDocGenerator(生成器)
VDocGenerator使用VDocRetriever检索到的文档图像来生成答案。
-
编码过程:编码检索结果后,将问题和编码后的结果连接起来,并将其输入到LVLM中。
-
生成过程:LVLM根据输入生成答案。
自监督预训练
预训练的目标是迁移 LVLM 强大的理解和生成能力,以促进其在视觉文档检索中的应用。为此,提出了两个新的自监督预训练任务,将整个图像表示压缩为输入图像末尾的 EOS 令牌。我们的预训练过程传递文档图像,并将其提取的 OCR 文本用作伪目标。完整的预训练目标定义为损失之和,如下所示。
通过检索进行表示压缩 (RCR)
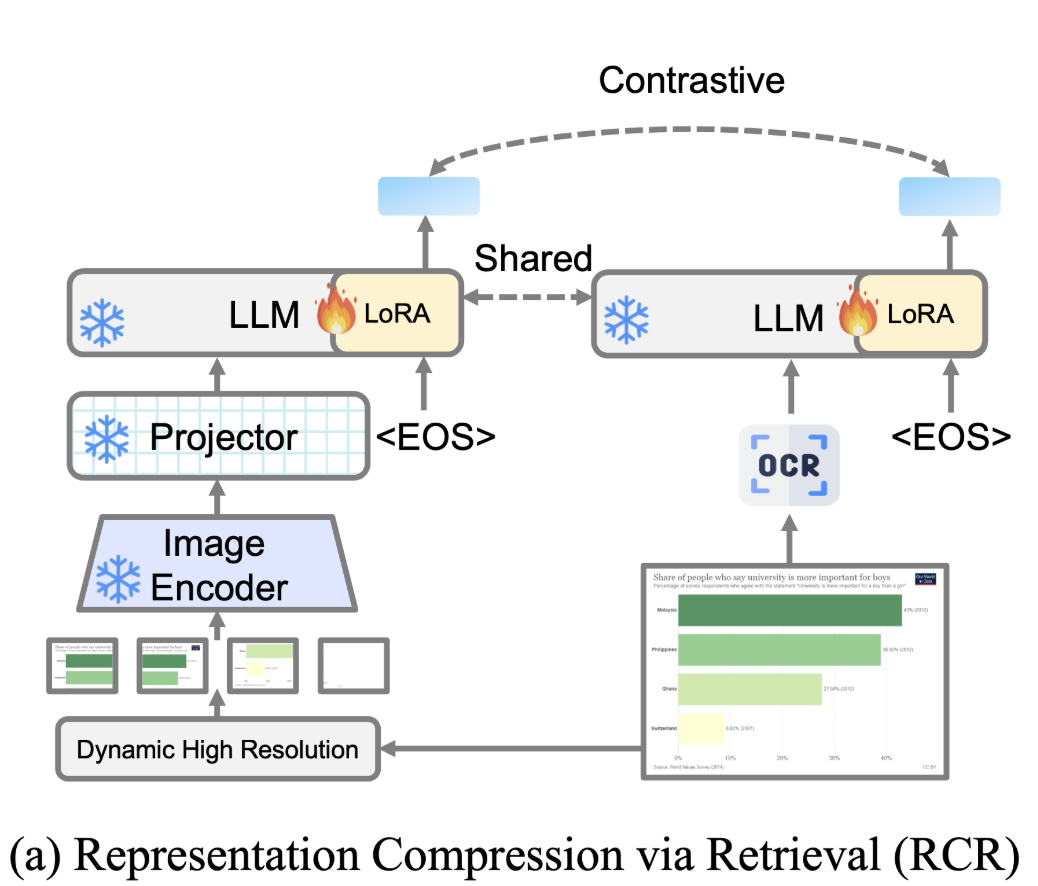
使用对比学习任务通过检索与OCR文本相关的图像来压缩图像表示。构建正样本OCR文本-图像对,并使用InfoNCE损失函数计算对比损失:
L R C R = − log exp ( SIM ( h o , h d + ) / τ ) ∑ i ∈ B exp ( SIM ( h o , h d i ) / τ ) \mathcal{L}{RCR} = -\log \frac{\exp(\operatorname{SIM}(h_o, h{d^{+}}) / \tau)}{\sum_{i \in \mathcal{B}} \exp(\operatorname{SIM}(h_o, h_{d_i}) / \tau)} LRCR=−log∑i∈Bexp(SIM(ho,hdi)/τ)exp(SIM(ho,hd+)/τ)
其中 τ \tau τ 是一个温度超参数, B \mathcal{B} B 表示批量大小。
通过生成进行表示压缩 (RCG)
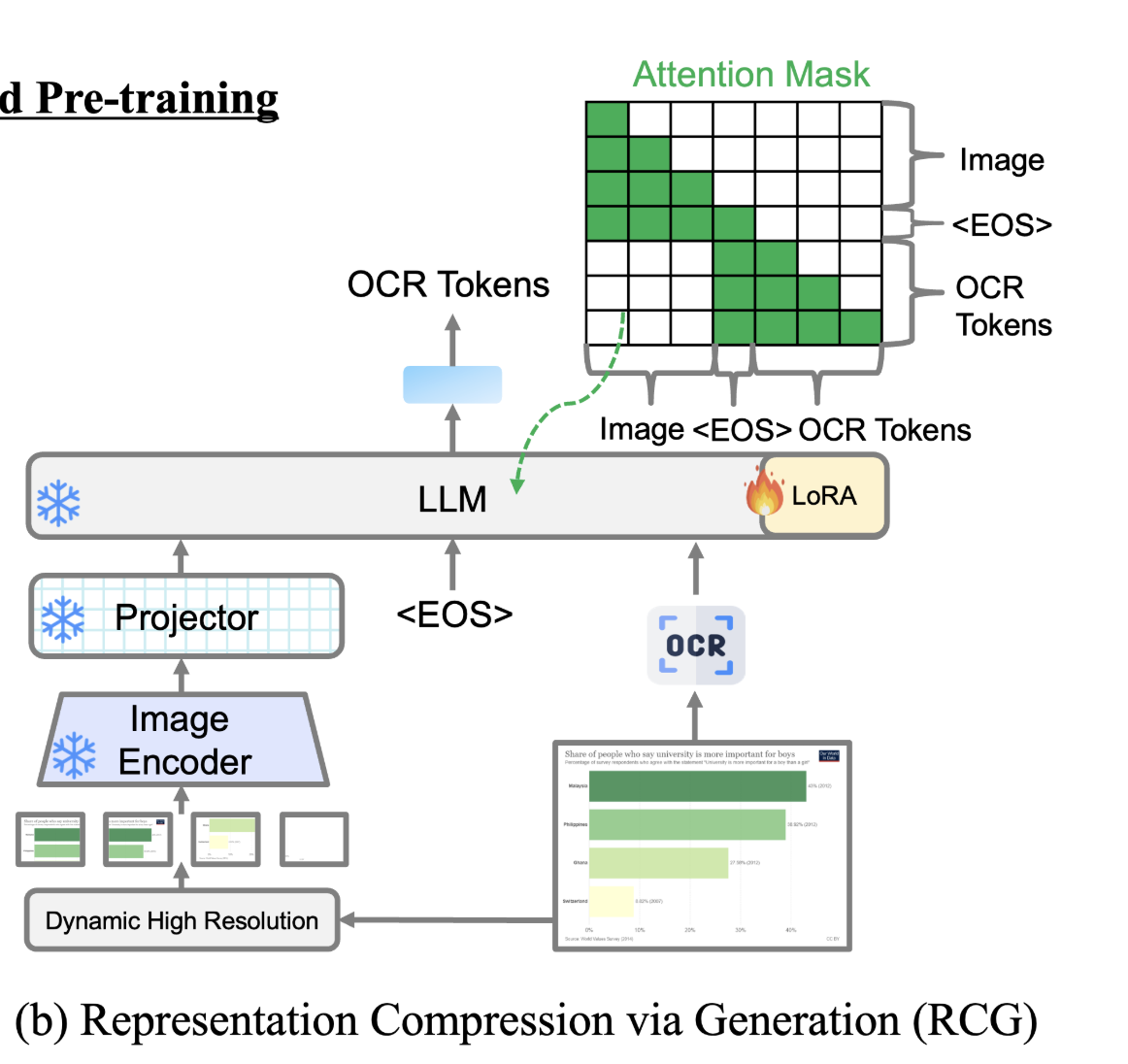
使用自定义的注意力掩码矩阵来利用LVLM的生成能力。对图像标记的表示进行掩码,仅允许 ⟨ E O S ⟩ \langle EOS \rangle ⟨EOS⟩ 标记和前面的OCR标记的注意力。通过标准自回归过程获取图像标记的表示,并将它们压缩到 ⟨ E O S ⟩ \langle EOS \rangle ⟨EOS⟩ 标记中。定义损失函数:
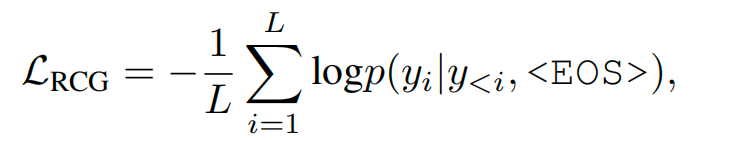
其中 y i y_i yi 表示OCR的第 i i i 个标记。
实验表现
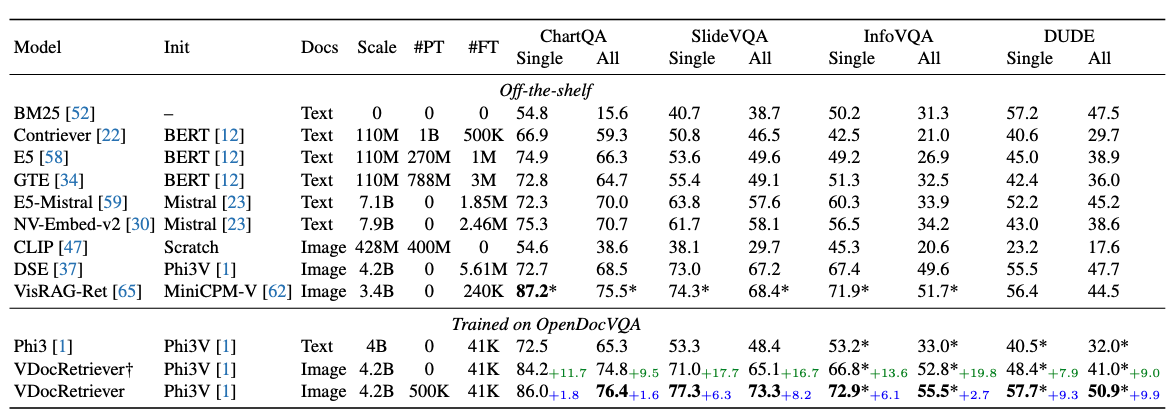
检索结果
VDocRetriever 在未见数据集 ChartQA 和 SlideVQA 上表现出卓越的零样本泛化能力,优于现成的文本检索器和最先进的视觉文档检索模型。
RAG 结果
即使所有模型都采用相同的初始化,VDocRAG 在 DocumentVQA 任务上的表现也明显优于闭卷 LLM 和基于文本的 RAG。
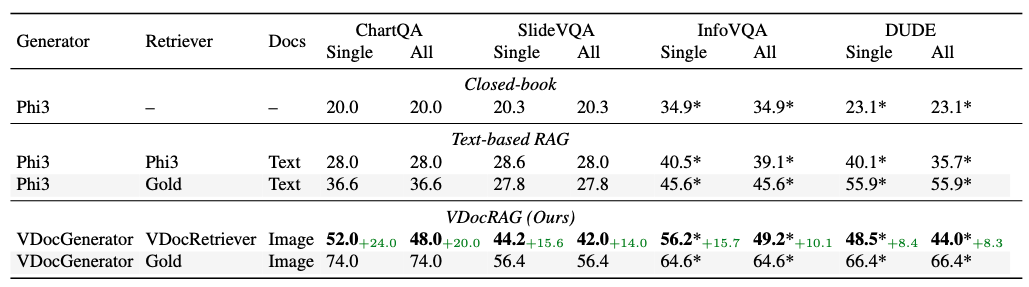

VDocRAG 在理解布局和可视化内容(例如表格、图表、图形和示意图)方面展现出显著的性能优势。这些发现凸显了将文档表示为图像对于提升 RAG 框架性能的关键作用。
参考文献:https://arxiv.org/abs/2504.09795,VDocRAG: Retrieval-Augmented Generation over Visually-Rich Documents