作者:来自 Elastic Jeffrey Rengifo
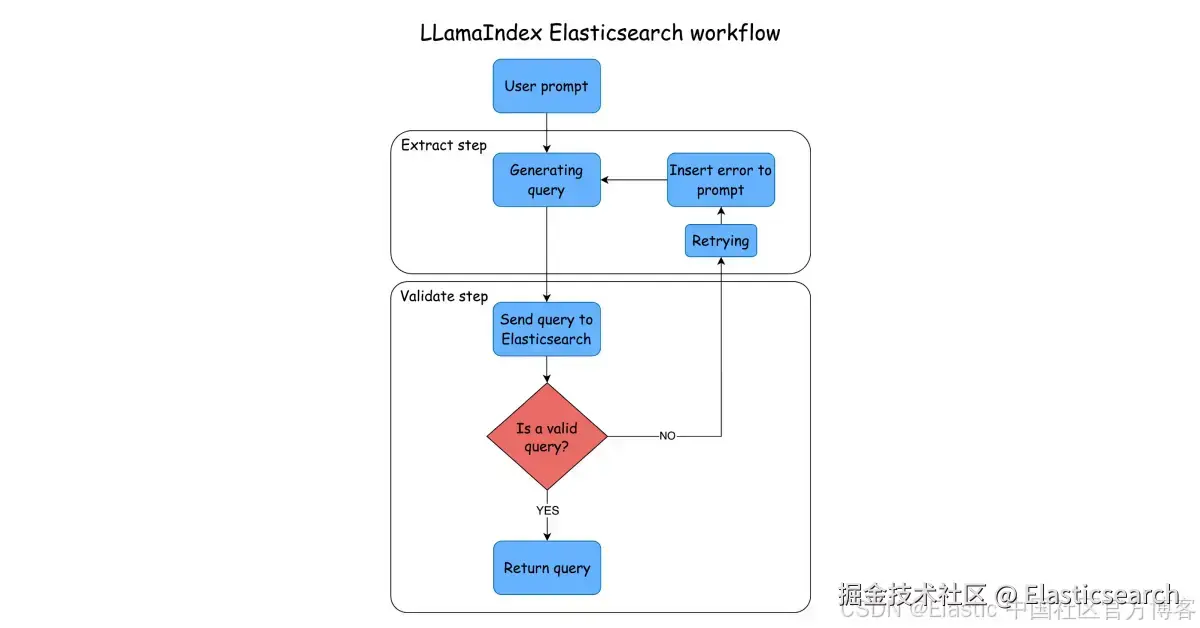
在本文中,你将学习如何利用 LlamaIndex Workflows 与 Elasticsearch 快速构建一个使用 LLM 的自过滤搜索应用程序。
LlamaIndex Workflows 提出了一种不同的方式来处理将任务拆分给不同 agent 的问题,它引入了一个步骤与事件的架构 。这种架构相比于基于 DAG(Directed Acyclic Graph - 有向无环图)的方法,例如 LangGraph,简化了设计。如果你想进一步了解关于 agent 的内容,推荐你阅读这篇文章。

 Image Source:
Image Source: LlamaIndex 的一项主要功能是能够在执行过程中轻松创建循环。循环可以帮助我们完成自动纠错任务,因为我们可以重复某个步骤,直到获得预期结果或达到设定的重试次数。
为了测试这一功能,我们将构建一个流程,使用 LLM 根据用户的问题生成 Elasticsearch 查询,并在生成的查询无效时启用自动纠错机制。如果在设定次数内 LLM 无法生成有效查询,我们将切换模型并继续尝试,直到超时为止。
为了优化资源使用,我们可以先使用更快且更便宜的模型生成初始查询,如果生成仍然失败,则改用更昂贵的模型。
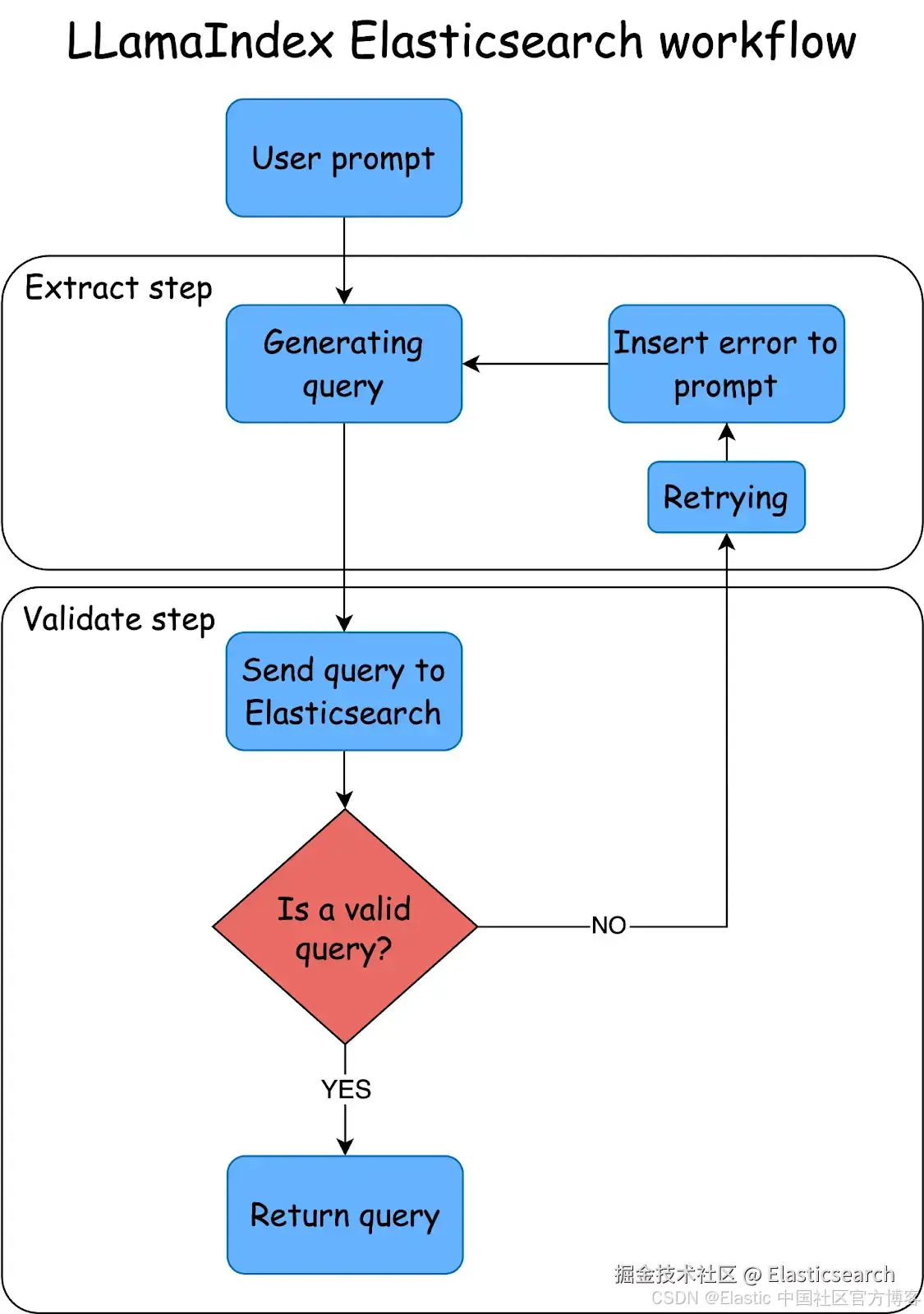
理解步骤与事件
步骤是通过代码函数运行的操作。它接收一个事件以及一个上下文,该上下文可以被所有步骤共享。基础事件有两种类型:
-
StartEvent,是启动流程的事件
-
StopEvent,用于停止事件的执行
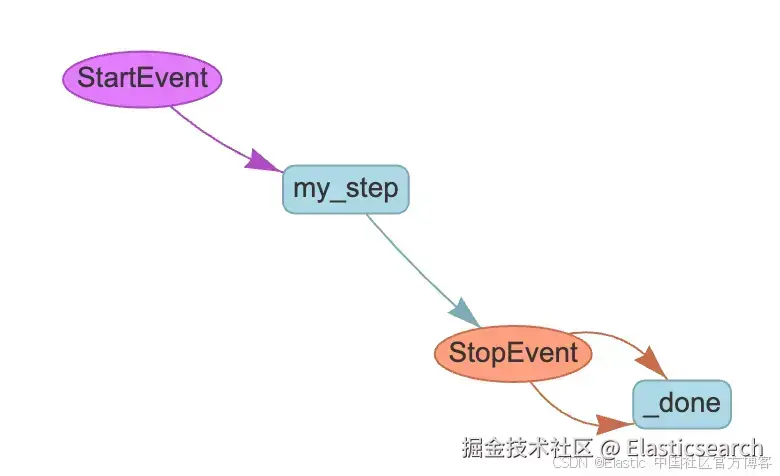
一个 Workflow 是一个包含所有步骤与交互的类,用于将它们组合在一起。
我们将创建一个 Workflow 来接收用户请求、展示映射和可筛选字段、生成查询语句,然后通过循环修复无效的查询。对于 Elasticsearch 来说,查询可能无效的原因包括:生成的 JSON 不合法,或语法错误。
为了展示其工作原理,我们将使用一个实际案例:搜索酒店房间。通过 workflow 提取值,根据用户的搜索来构建查询。
完整示例可在这个 Notebook 中查看。
步骤
-
安装依赖并导入包
-
准备数据
-
LlamaIndex workflows
-
执行 workflow 任务
安装依赖并导入包
我们将使用 mistral-saba-24b 和 llama3-70b Groq 模型,因此除了 elasticsearch 和 llama-index,还需要安装 llama-index-llms-groq 包来处理与 LLM 的交互。
Groq 是一个推理服务,允许我们使用来自 Meta、Mistral 和 OpenAI 等提供商的多个开源模型。在本示例中,我们将使用它的免费层 。你可以在此处获取稍后使用的 API KEY。
下面是所需依赖项的安装:Elasticsearch、LlamaIndex 核心库以及 LlamaIndex 的 Groq LLM 包。
ini
`pip install elasticsearch==8.17 llama-index llama-index-llms-groq`AI写代码我们首先导入一些依赖项,用于处理环境变量(os)和管理 JSON 数据。
然后,我们导入 Elasticsearch 客户端,并使用 bulk helper 来通过 bulk API 进行索引。最后,我们导入 LlamaIndex 中的 Groq 类,以便与模型交互,并导入创建 workflow 所需的组件。
markdown
`
1. import os
2. import json
3. from getpass import getpass
5. from elasticsearch import Elasticsearch
6. from elasticsearch.helpers import bulk
8. from llama_index.llms.groq import Groq
9. from llama_index.core.workflow import (
10. Event,
11. StartEvent,
12. StopEvent,
13. Workflow,
14. step,
15. )
`AI写代码- 准备数据
设置密钥
我们设置 Groq 和 Elasticsearch 所需的环境变量。getpass 库允许我们通过提示输入密钥,并且不会显示输入的内容。
scss
`
1. os.environ["GROQ_API_KEY"] = getpass("Groq Api key: ")
2. os.environ["ELASTIC_ENDPOINT"] = getpass("Elastic Endpoint: ")
3. os.environ["ELASTIC_API_KEY"] = getpass("Elastic Api key: ")
`AI写代码Elasticsearch 客户端
Elasticsearch 客户端负责与 Elasticsearch 进行连接,并允许我们使用 Python 库与 Elasticsearch 进行交互。
ini
`
1. _client = Elasticsearch(
2. os.environ["ELASTIC_ENDPOINT"],
3. api_key=os.environ["ELASTIC_API_KEY"],
4. )
`AI写代码将数据导入 Elasticsearch
我们将以酒店房间为例创建一个索引:
go
`INDEX_`AI写代码映射
我们将使用文本类型字段(text)用于需要执行全文搜索的属性;使用 "keyword" 类型用于需要应用筛选或排序的字段,使用 "byte/integer" 类型用于数字。
python
`
1. try:
2. _client.indices.create(
3. index=INDEX_NAME,
4. body={
5. "mappings": {
6. "properties": {
7. "room_name": {"type": "text"},
8. "description": {"type": "text"},
9. "price_per_night": {"type": "integer"},
10. "beds": {"type": "byte"},
11. "features": {"type": "keyword"},
12. }
13. }
14. },
15. )
17. print("index created successfully")
18. except Exception as e:
19. print(
20. f"Error creating inference endpoint: {e.info['error']['root_cause'][0]['reason'] }"
21. )
`AI写代码将文档导入 Elasticsearch
我们将导入一些酒店房间和设施,以便用户可以提问,我们可以将这些问题转化为针对文档的 Elasticsearch 查询。
ini
`
1. documents = [
2. {
3. "room_name": "Standard Room",
4. "beds": 1,
5. "description": "A cozy room with a comfortable queen-size bed, ideal for solo travelers or couples.",
6. "price_per_night": 80,
7. "features": ["air conditioning", "wifi", "flat-screen TV", "mini fridge"]
8. },
9. {
10. "room_name": "Deluxe Room",
11. "beds": 1,
12. "description": "Spacious room with a king-size bed and modern amenities for a luxurious stay.",
13. "price_per_night": 120,
14. "features": ["air conditioning", "wifi", "smart TV", "mini bar", "city view"]
15. },
16. {
17. "room_name": "Family Room",
18. "beds": 2,
19. "description": "A large room with two queen-size beds, perfect for families or small groups.",
20. "price_per_night": 150,
21. "features": ["air conditioning", "wifi", "flat-screen TV", "sofa", "bath tub"]
22. },
23. {
24. "room_name": "Suite",
25. "beds": 1,
26. "description": "An elegant suite with a separate living area, offering maximum comfort and luxury.",
27. "price_per_night": 200,
28. "features": ["air conditioning", "wifi", "smart TV", "jacuzzi", "balcony"]
29. },
30. {
31. "room_name": "Penthouse Suite",
32. "beds": 1,
33. "description": "The ultimate luxury experience with a panoramic view and top-notch amenities.",
34. "price_per_night": 350,
35. "features": ["air conditioning", "wifi", "private terrace", "jacuzzi", "exclusive lounge access"]
36. },
37. {
38. "room_name": "Single Room",
39. "beds": 1,
40. "description": "A compact and comfortable room designed for solo travelers on a budget.",
41. "price_per_night": 60,
42. "features": ["wifi", "air conditioning", "desk", "flat-screen TV"]
43. },
44. {
45. "room_name": "Double Room",
46. "beds": 1,
47. "description": "A well-furnished room with a queen-size bed, ideal for couples or business travelers.",
48. "price_per_night": 100,
49. "features": ["air conditioning", "wifi", "mini fridge", "work desk"]
50. },
51. {
52. "room_name": "Executive Suite",
53. "beds": 1,
54. "description": "A high-end suite with premium furnishings and exclusive business amenities.",
55. "price_per_night": 250,
56. "features": ["air conditioning", "wifi", "smart TV", "conference table", "city view"]
57. },
58. {
59. "room_name": "Honeymoon Suite",
60. "beds": 1,
61. "description": "A romantic suite with a king-size bed, perfect for newlyweds and special occasions.",
62. "price_per_night": 220,
63. "features": ["air conditioning", "wifi", "hot tub", "romantic lighting", "balcony"]
64. },
65. {
66. "room_name": "Presidential Suite",
67. "beds": 2,
68. "description": "A luxurious suite with separate bedrooms and a living area, offering first-class comfort.",
69. "price_per_night": 500,
70. "features": ["air conditioning", "wifi", "private dining area", "personal butler service", "exclusive lounge access"]
71. }
72. ]
`AI写代码我们将 JSON 文档解析为一个 bulk Elasticsearch 请求。
python
`
1. def build_data():
2. for doc in documents:
3. yield {"_index": INDEX_NAME, "_source": doc}
6. try:
7. success, errors = bulk(_client, build_data())
8. print(f"{success} documents indexed successfully")
9. if errors:
10. print("Errors during indexing:", errors)
12. except Exception as e:
13. print(f"Error: {str(e)}")
`AI写代码- LlamaIndex Workflows
我们需要创建一个类,包含将 Elasticsearch 映射发送到 LLM、运行查询并处理错误所需的函数。
python
`
1. class ElasticsearchRequest:
2. @staticmethod
3. def get_mappings(_es_client: Elasticsearch):
4. """
5. Get the mappings of the Elasticsearch index.
6. """
8. return _es_client.indices.get_mapping(index=INDEX_NAME)
10. @staticmethod
11. async def do_es_query(query: str, _es_client: Elasticsearch):
12. """
13. Execute an Elasticsearch query and return the results as a JSON string.
14. """
16. try:
17. parsed_query = json.loads(query)
19. if "query" not in parsed_query:
20. return Exception(
21. "Error: Query JSON must contain a 'query' key"
22. ) # if the query is not a valid JSON return an error
24. response = _es_client.search(index=INDEX_NAME, body=parsed_query)
25. hits = response["hits"]["hits"]
27. if not hits or len(hits) == 0:
28. return Exception(
29. "Query has not found any results"
30. ) # if the query has no results return an error
32. return json.dumps([hit["_source"] for hit in hits], indent=2)
34. except json.JSONDecodeError:
35. return Exception("Error: Query JSON no valid format")
36. except Exception as e:
37. return Exception(str(e))
`AI写代码Workflow 提示
EXTRACTION_PROMPT 将提供用户的问题,并将索引映射传递给 LLM,以便它返回一个 Elasticsearch 查询。
然后,REFLECTION_PROMPT 将帮助 LLM 在出现错误时进行修正,方法是提供来自 EXTRACTION_PROMPT 的输出以及查询引起的错误。
ini
`
1. EXTRACTION_PROMPT = """
2. Context information is below:
3. ---------------------
4. {passage}
5. ---------------------
7. Given the context information and not prior knowledge, create a Elasticsearch query from the information in the context.
8. The query must return the documents that match with query and the context information and the query used for retrieve the results.
9. {schema}
11. """
13. REFLECTION_PROMPT = """
14. You already created this output previously:
15. ---------------------
16. {wrong_answer}
17. ---------------------
19. This caused the error: {error}
21. Try again; the response must contain only valid Elasticsearch queries. Do not add any sentence before or after the JSON object.
22. Do not repeat the query.
23. """
`AI写代码Workflow 事件
我们创建了类来处理提取和查询验证事件:
python
`
1. class ExtractionDone(Event):
2. output: str
3. passage: str
6. class ValidationErrorEvent(Event):
7. error: str
8. wrong_output: str
9. passage: str
`AI写代码Workflow
现在,让我们把一切结合起来。首先,我们需要将最大尝试次数设置为 3 次,以便更换模型。
接下来,我们将使用在 workflow 中配置的模型进行 extraction。我们验证事件是否为 StartEvent;如果是,我们捕获模型和问题(段落)。
然后,我们运行 validation 步骤,即尝试在 Elasticsearch 中运行提取的查询。如果没有错误,我们生成一个 StopEvent 并停止流程。否则,我们发出 ValidationErrorEvent 并重复第 1 步,提供错误信息以进行修正,然后返回验证步骤。如果在 3 次尝试后仍然没有有效查询,我们更换模型并重复此过程,直到达到 60 秒的超时运行时间参数。
python
`
1. class ReflectionWorkflow(Workflow):
2. model_retries: int = 0
3. max_retries: int = 3
5. @step()
6. async def extract(
7. self, ev: StartEvent | ValidationErrorEvent
8. ) -> StopEvent | ExtractionDone:
10. print("\n=== EXTRACT STEP ===\n")
12. if isinstance(ev, StartEvent):
13. model = ev.get("model")
14. passage = ev.get("passage")
16. if not passage:
17. return StopEvent(result="Please provide some text in input")
19. reflection_prompt = ""
20. elif isinstance(ev, ValidationErrorEvent):
21. passage = ev.passage
22. model = ev.model
24. reflection_prompt = REFLECTION_PROMPT.format(
25. wrong_answer=ev.wrong_output, error=ev.error
26. )
28. llm = Groq(model=model, api_key=os.environ["GROQ_API_KEY"])
30. prompt = EXTRACTION_PROMPT.format(
31. passage=passage, schema=ElasticsearchRequest.get_mappings(_client)
32. )
33. if reflection_prompt:
34. prompt += reflection_prompt
36. output = await llm.acomplete(prompt)
38. print(f"MODEL: {model}")
39. print(f"OUTPUT: {output}")
40. print("=================\n")
42. return ExtractionDone(output=str(output), passage=passage, model=model)
44. @step()
45. async def validate(self, ev: ExtractionDone) -> StopEvent | ValidationErrorEvent:
47. print("\n=== VALIDATE STEP ===\n")
49. try:
50. results = await ElasticsearchRequest.do_es_query(ev.output, _client)
51. self.model_retries += 1
53. if self.model_retries > self.max_retries and ev.model != "llama3-70b-8192":
54. print(f"Max retries for model {ev.model} reached, changing model\n")
55. model = "llama3-70b-8192" # if the some error occurs, the model will be changed to llama3-70b-8192
56. else:
57. model = ev.model
59. print(f"Elasticsearch results: {results}")
61. if isinstance(results, Exception):
62. print("STATUS: Validation failed, retrying...\n")
63. print("===================\n")
65. return ValidationErrorEvent(
66. error=str(results),
67. wrong_output=ev.output,
68. passage=ev.passage,
69. model=model,
70. )
72. # print("results: ", results)
73. except Exception as e:
74. print("STATUS: Validation failed, retrying...\n")
75. print("===================\n")
77. return ValidationErrorEvent(
78. error=str(e),
79. wrong_output=ev.output,
80. passage=ev.passage,
81. model=model,
82. )
84. return StopEvent(result=ev.output)
`AI写代码- 执行 workflow 任务
我们将进行以下搜索:具有智能电视、wifi、按摩浴缸且每晚价格低于 300 的房间。我们将首先使用 mistral-saba-24b 模型,并根据需要按照我们的流程切换到 llama3-70b-8192。

ini
`
1. w = ReflectionWorkflow(timeout=60, verbose=True)
3. user_prompt = "Rooms with smart TV, wifi, jacuzzi and price per night less than 300"
5. result = await w.run(
6. passage=f"I need the best possible query for documents that have: {user_prompt}",
7. model="mistral-saba-24b",
8. )
10. print(result)
`AI写代码结果
(格式化以便于阅读)
=== EXTRACT STEP ===
MODEL: mistral-saba-24b
OUTPUT:
json
`
1. {
2. "query": {
3. "bool": {
4. "must": [
5. { "match": { "features": "smart TV" }},
6. { "match": { "features": "wifi" }},
7. { "match": { "features": "jacuzzi" }},
8. { "range": { "price_per_night": { "lt": 300 }}}
9. ]
10. }
11. }
12. }
`AI写代码Step extract produced event ExtractionDone
Running step validate
=== VALIDATE STEP ===
Max retries for model mistral-saba-24b reached, changing model
Elasticsearch 结果:
yaml
`
1. Error: Query JSON no valid format
2. STATUS: Validation failed, retrying...
`AI写代码Step validate produced event ValidationErrorEvent
Running step extract
=== EXTRACT STEP ===
MODEL: llama3-70b-8192
OUTPUT:
css
`
1. {
2. "query": {
3. "bool": {
4. "filter": [
5. { "term": { "features": "smart TV" }},
6. { "term": { "features": "wifi" }},
7. { "term": { "features": "jacuzzi" }},
8. { "range": { "price_per_night": { "lt": 300 }}}
9. ]
10. }
11. }
12. }
`AI写代码Step extract produced event ExtractionDone
Running step validate
=== VALIDATE STEP ===
Elasticsearch 结果:
css
`
1. [2. {3. "room_name": "Suite",4. "beds": 1,5. "description": "An elegant suite with a separate living area, offering maximum comfort and luxury.",6. "price_per_night": 200,7. "features": [8. "air conditioning",9. "wifi",10. "smart TV",11. "jacuzzi",12. "balcony"13. ]
14. }
15. ]
`AI写代码Step validate produced event StopEvent
css
`
1. {
2. "query": {
3. "bool": {
4. "filter": [
5. { "term": { "features": "smart TV" }},
6. { "term": { "features": "wifi" }},
7. { "term": { "features": "jacuzzi" }},
8. { "range": { "price_per_night": { "lt": 300 }}}
9. ]
10. }
11. }
12. }
`AI写代码在上面的示例中,查询失败是因为 mistral-saba-24b 模型返回的结果是 Markdown 格式,开始时添加了 json,结尾处有 。而 llama3-70b-8192 模型直接返回了使用 JSON 格式的查询。根据我们的需求,我们可以捕获、验证并测试不同的错误,或在多次尝试后构建回退机制。
结论
LlamaIndex workflows 提供了一种有趣的替代方案,可以通过事件和步骤开发 agentic 流程。通过仅几行代码,我们成功创建了一个能够通过可互换模型进行自动纠错的系统。
我们如何改进这个流程?
-
除了映射外,我们可以将可能的确切过滤器值发送给 LLM,从而减少由于拼写错误的过滤器导致的无结果查询。为此,我们可以对特性进行 terms 聚合并将结果展示给 LLM。
-
添加对常见问题的代码修正,例如我们遇到的 Markdown 问题,以提高成功率。
-
添加处理有效查询但没有结果的方式。例如,移除某个过滤器并重新尝试,向用户提供建议。LLM 可以根据上下文选择要移除的过滤器。
-
向提示中添加更多上下文信息,如用户偏好或之前的搜索,以便我们可以在 Elasticsearch 结果的基础上提供定制化的建议。
你想尝试其中一个吗?
想要获得 Elastic 认证吗?了解下一期 Elasticsearch 工程师培训的时间!
Elasticsearch 拥有许多新特性,帮助你为特定用例构建最佳搜索解决方案。深入探索我们的示例笔记本,了解更多内容,开始免费云试用,或立即在本地机器上尝试 Elastic。
原文:Using LlamaIndex Workflows with Elasticsearch - Elasticsearch Labs