通过渲染3D模型来学习不同方向下物体的外观,并从单张和自由视角的图像中估计物体方向
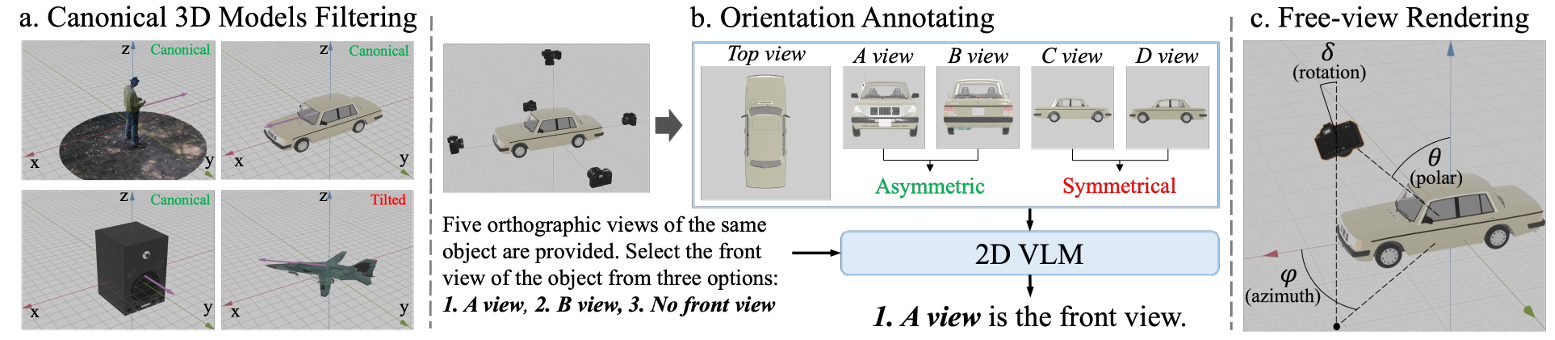
1. 数据生成:基于 3D 渲染构建大规模方向标注数据集
- 数据来源:
使用 Objaverse 数据库中的高质量 3D 模型,进行筛选和预处理。
- 筛选规范:
仅保留处于规范姿态的模型,过滤掉倾斜模型(通过 PCA 判断)。
- 方向标注流程:
-
渲染模型在 x/-x/y/-y 四个方向和俯视角;
-
利用先进视觉语言模型(如 Gemini-1.5-pro)判断哪个角度是"正面";
-
结合对称性分析避免错误(通过图像结构相似性计算);
-
对于对称物体,标记为"无方向"。
- 渲染过程:
-
使用球坐标(θ 极角,φ 方位角,δ 相机旋转角)定义方向;
-
每个模型从随机角度渲染 40 张图像,图像大小 512x512;
-
共构建包含200万张带方向注释图像的数据集。
2. 学习目标:方向概率分布拟合(核心创新)
背景问题:
直接使用 L2 回归预测角度难以收敛,且分类忽略了相邻角度间的关系。
核心方法:
将角度预测转化为概率分布拟合问题,分别建模三种角度(极角θ、方位角φ、旋转角δ):
-
将 360° 或 180° 区间离散为每度一类;
-
构建高斯分布(极角)或环形高斯分布(方位角、旋转角)作为目标;
-
使用交叉熵损失函数对分布进行拟合训练。
推理策略:
-
输出三个分布;
-
使用最大概率对应角度作为预测值;
-
若模型判断该物体为"无方向",则不输出具体角度。
3. 合成到真实迁移策略(Synthetic-to-Real Transfer)
为解决模型从渲染图像迁移到真实图像的困难,作者引入两种策略:
(1)模型初始化:
-
采用 DINOv2(在真实图像上预训练,感知精细)作为视觉编码器初始化;
-
明显优于 MAE、CLIP 等方案。
(2)数据增强:
-
使用随机裁剪模拟物体遮挡;
-
在推理时,使用分割掩码裁剪目标,减少干扰;
-
增强合成图像与真实图像之间的风格一致性。