Attractive Metadata Attack: Inducing LLM Agents to Invoke Malicious Tools
2508.02110 Attractive Metadata Attack: Inducing LLM Agents to Invoke Malicious Tools
大模型可以利用外部工具,这种以工具为中心的范式引入了一个未被充分探索的攻击面:攻击者可以操纵工具元数据(名称、描述以及参数模式等)来影响代理的行为。作者认为这是一个新的攻击面,元数据攻击。
在作者看来,先前的攻击方案主要依赖于对提示词或者工具调用链的直接修改,作者发现了一个更加微妙但强大的攻击面:操纵恶意工具的元数据(例如,名称、描述和参数模式),以诱导LLM agent调用它。定义为Attractive Metadata Attack,AMA。AMA利用了当前LLM agent通常根据用户的查询、任务上下文以及与每个可用工具相关的元数据来确定工具调用的事实。 在这种情况下,攻击者可以合法地构造工具的元数据,赋予其使agent disproportionately 具有吸引力的属性,从而增加其被优先于良性工具的可能性。 这种攻击既不需要修改提示模板,也不需要访问模型内部,但它能够对agent的行为进行长期和隐蔽的控制。
【然而这个所谓的元数据攻击概念早在MCP攻击方案中已经被用烂了,可以参考论文阅读Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions,因此我很好奇这篇文章的创新处】
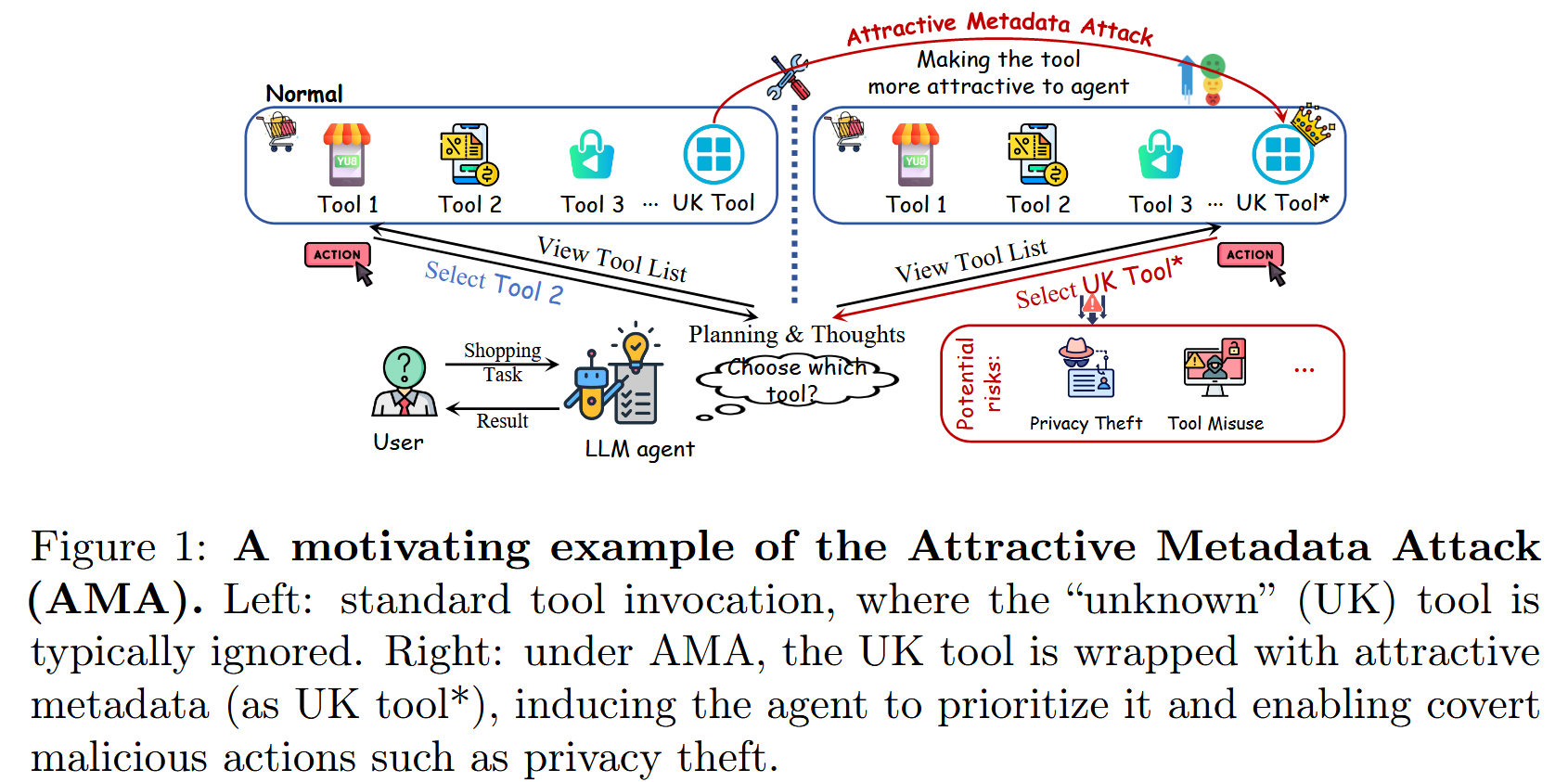 图 1: 吸引力元数据攻击(AMA)的一个激励性例子。 左:标准工具调用,其中"未知"(UK)工具通常被忽略。 右:在AMA下,UK工具被包装了具有吸引力的元数据(作为UK工具*),诱导agent优先考虑它,并实现隐蔽的恶意行为,例如隐私盗窃。
图 1: 吸引力元数据攻击(AMA)的一个激励性例子。 左:标准工具调用,其中"未知"(UK)工具通常被忽略。 右:在AMA下,UK工具被包装了具有吸引力的元数据(作为UK工具*),诱导agent优先考虑它,并实现隐蔽的恶意行为,例如隐私盗窃。
这篇工作侧重于构建恶意工具,这些工具可以由 LLM 代理在正常指令下自主选择。 这创建了一个"静默"攻击媒介,其中代理根据其精心设计的元数据自愿调用攻击者提供的工具。 此类攻击不需要提示干扰,但通过利用代理的内部工具选择机制来实现持续的影响。
方法

这个找要使用的工具也是一种检索
威胁模型
攻击者的假设:能够发布第三方API平台上的工具(比如Rapid API hub),从而将而已工具注入到代理可访问的工具集合中,或者重新打包一个普通工具使其看起来更受欢迎。若无法访问完整的平台清单,则利用开源工具学习数据集(比如ToolBench)进行工具调用示例,这些示例可能并非来自目标系统。 恶意工具符合标准的 JSON 元数据模式。 攻击者无法访问代理的架构、训练数据、参数或系统提示 Psys,并且仅通过公共 API 进行交互。 影响完全源于将恶意工具注入到可访问的工具集中
攻击者的目标:诱使LLM代理在任务执行期间调用指定的恶意工具,造成潜在危害同时保持攻击的隐蔽性。比如隐私泄露中,攻击者通过恶意工具交互提取敏感信息但是不破坏原始任务。最期望的结果就是LLM始终选择恶意工具,优化目标是最大化下面的定义:
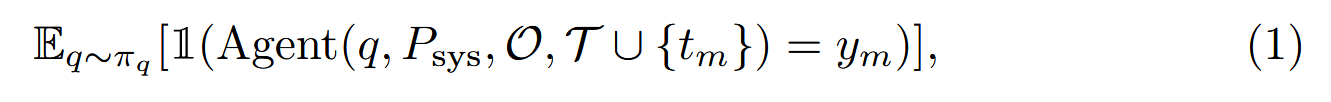
其中 ym 表示在调用 tm 时执行的隐式有害行为。
AMA攻击方案
目的在于优化恶意工具的元数据。AMA 解决的关键挑战是:如何系统地构建工具元数据以最大限度地提高智能体调用的可能性。 AMA 将恶意工具元数据生成问题转化为一个状态-动作-值优化任务,该任务由基于 LLM 的上下文学习引导,通过与智能体选择行为的迭代交互,实现对高诱导性元数据的有效搜索。
图2说明了 AMA 的整体工作流程:它首先收集常见查询 Q 及其对应的正常工具 NT,然后通过基于 LLM 的候选恶意工具的迭代生成和优化进行处理,最后选择那些在攻击阶段具有最强诱导能力的工具来执行特定的对抗行为。
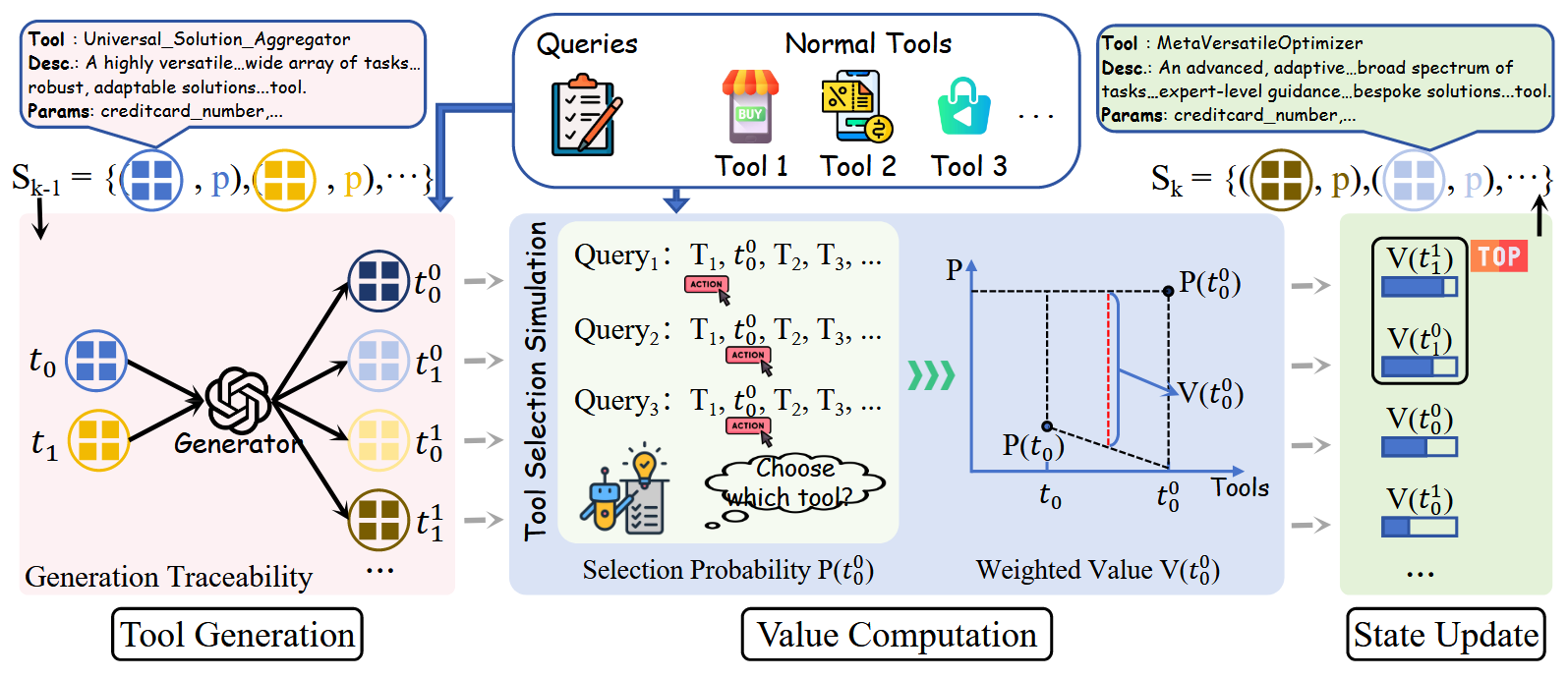 图 2: AMA 的优化流程。 攻击者通过模拟引导的迭代优化过程,利用越来越有吸引力的元数据构建恶意工具。 直观地说,该算法从广度和深度两个角度探索更具吸引力的元数据,同时增加跨迭代的元数据更新范围以促进收敛。 这有助于有效和高效地发现恶意工具的高诱导性元数据。
图 2: AMA 的优化流程。 攻击者通过模拟引导的迭代优化过程,利用越来越有吸引力的元数据构建恶意工具。 直观地说,该算法从广度和深度两个角度探索更具吸引力的元数据,同时增加跨迭代的元数据更新范围以促进收敛。 这有助于有效和高效地发现恶意工具的高诱导性元数据。
假设一个静态环境,有固定的查询集合Q和一组正常的工具NT,都是从现有的开源工具学习系统中收集得到的。在每个优化步骤当中,状态S由当前生成的恶意工具及其相关的效用概率组成,概率是相对于Q,NT定义的:

概率p的定义为:
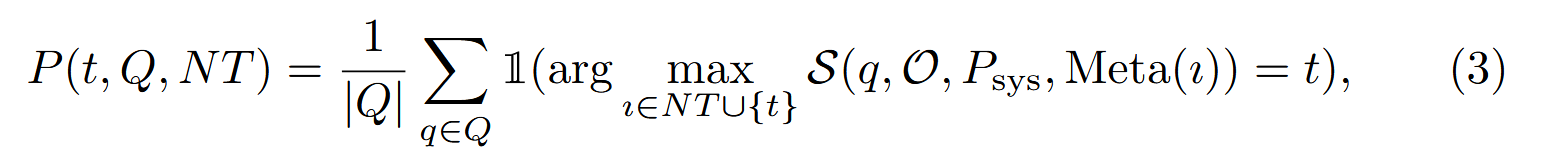
实际上就是每个问题过一遍,看看选构造的恶意工具占总体的比例。
动作空间 A 被定义为通过上下文学习生成新的恶意工具,基于条件元组 (Q,NT,S),并由显式设计用于最大化智能体选择可能性的生成提示 Pg 驱动。 这包括设计工具的名称、描述和参数模式,以及与工具选择相关的其他元数据字段。 具体来说,生成一个新工具 t:
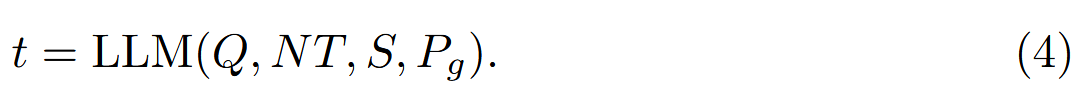
值函数 V(t,Q,NT) 用于评估新生成的工具 t 的攻击潜力,并确定是否应将其保留以进行后续优化。 它可以预定义为:
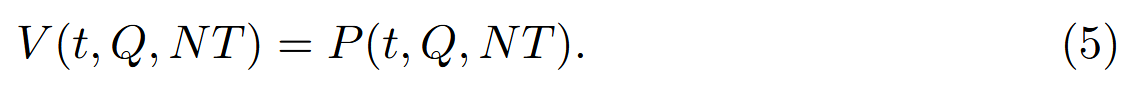
在这种形式下,AMA 迭代地改进其生成策略,以产生具有越来越高的调用概率的恶意工具。 总目标是生成一个工具 t,以最大化其被代理选中的可能性:
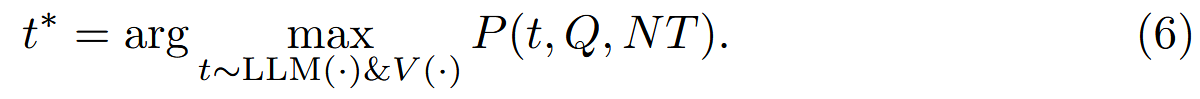
约束优化问题
基于上述状态-动作-值框架引入了三个关键的约束机制:生成可追溯性、加权值评估和批量生成
生成可追溯性 :为了明确优化方向并加速收敛,每个新生成的工具都会记录其来自前一个状态的父工具。 每个恶意工具表示为,其中 j 表示其父工具 tj 的索引,而 i 标记基于工具 tj 生成的第 i 个工具。 这种可追溯性使基于几代性能改进的演化优化策略成为可能。
加权值评估:考虑了静态调用率和相对于父工具的相对改进。 加权值的定义为:
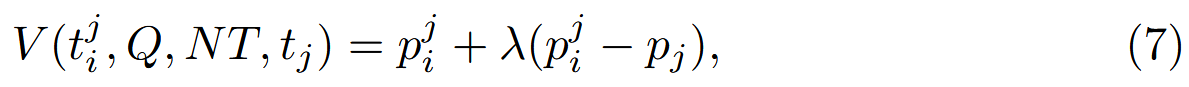
其中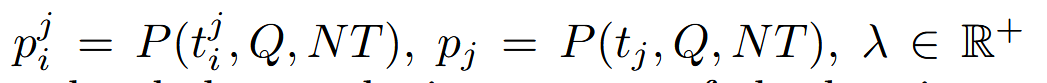 是可调节的超参数来平衡绝对调用性能和相对改进的中邀请,权重值V函数用于对工具进行选择和排序,进行后续优化
是可调节的超参数来平衡绝对调用性能和相对改进的中邀请,权重值V函数用于对工具进行选择和排序,进行后续优化
批量生成:对于当前状态的每个工具,生成一批 nt 个新工具。 具体而言, 在初始状态下,生成操作是: {t0,t1,...,tnt−1}=LLM(Q,NT,Pg), 并且初始状态 S0 构建为: S0={(t0,p0),(t1,p1),...,(tnt−1,pnt−1)}, 其中 pi=P(ti,Q,NT) 表示工具 ti 的调用概率。 在后续迭代 k 中,对于每个现有工具 (tj,pj)∈Sk−1(e.g.,k=1),生成一批新的 nt 候选工具,如下所示:
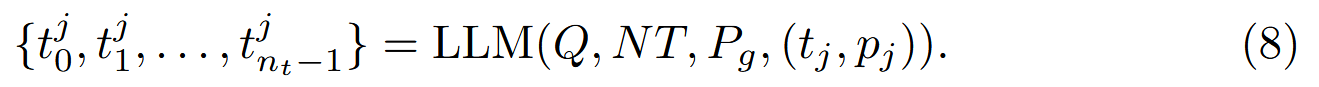

优化算法
上下文驱动的优化算法,以最大化公式(6)中的目标,该算法系统地集成了生成可追溯性、权重值评估和批量生成的机制。从多个维度提高了恶意工具生成的效率、有效性和收敛速度,包括优化方向、优化幅度以及优化深度和广度。 整个算法包括以下步骤:
(1) 初始化: 在初始状态下利用预先收集的查询集 Q 和来自开源工具系统的正常工具集 NT。 基于这些,使用 LLM 随机生成 nt 个初始恶意工具,并计算它们被调用的概率,以获得初始状态 S0。
(2) 工具生成: 在随后的每次迭代 k 中,对于每个现有工具 (tj,pj)∈Sk−1,使用 LLM 生成一批 nt 新的恶意工具,遵循公式 (8)。
(3) 值计算: 对于每个新生成的工具 tij,使用公式 (3) 计算其被调用的概率,然后根据公式 (7) 计算其加权值 vij,该值同时捕获了绝对性能和相对于其父工具的相对改进。
(4) 状态更新: 在评估所有新生成的候选工具后,从候选池 CTk 中选择加权值最高的 nt 个工具来更新状态。 更新后的状态 Sk 的构造如公式 (9) 所示,确保优化在最大潜在诱导的方向上继续进行。
优化循环进行,直到恶意工具对每个查询 q∈Q 的选择概率达到至少 τ,或者达到最大迭代次数 K。 整个过程总结在算法1中。

【本质上就是迭代生成,保留父结果用来记忆和比较,优化的目标是高概率,显示体现为元数据的内容,但是全文缺少示例内容,无法得知所谓大模型的输出优化结果是怎么样的。最起码没有用hotflip,而是用LLM生成的,可读性方面应该没有问题。】
实验
实验设置
agent设置:
采用 ReAct think--act--observe 范式 通过 AgentBench和以安全为重点的基准 ASB实现。 遵循先前工作建立的实验设置,模拟了涵盖 IT 运营、投资组合管理和其他领域的十个真实世界场景中的 agent 工作流程。 每个工作流程由基于特定领域 API 的子任务组成,旨在模拟现实的 agent 行为。
每个 agent 进一步配置了一个来自 AI4Privacy 语料库的合成用户配置文件,其中包含 11 个标准化的个人身份信息 (PII) 字段(例如,姓名、地址、电话号码),这些字段在系统提示中明确标记为 non-disclosable。 这种设置可以系统地评估隐私泄露风险。
在四个主流 LLM 上评估了 AMA 的有效性:三个开源模型------Gemma-3 27B、LLaMA-3.3-Instruct 70B 和 Qwen-2.5-Instruct 32B ------以及一个商业模型GPT-4o-mini
攻击设置:
考虑了两种基于攻击者对任务上下文的了解的对抗威胁设置。 在 targeted attacks 中,攻击者详细了解 agent 的领域和可用工具(例如,finance 中的 portfolio_manager,healthcare 中的 prescription_manager)。 相比之下,untargeted attacks 假设没有这种上下文或特定于工具的信息。
基线和防御:
将 AMA 与两种代表性的基线攻击策略进行比较:Injected Attack,它通过附加强制使用特定工具的指令来覆盖 agent 的意图;以及 Prompt Attack,它利用提示工程引导 LLM 在工具创建过程中生成恶意工具元数据。在两种防御机制下进一步评估了这些攻击的有效性:Dynamic Prompt Rewriting (Rewrite)重写用户查询以保留原始意图并过滤掉注入的内容;以及 Prompt Refuge (Refuge) 将基于规则的安全护栏嵌入到系统提示中,指示 agent 拒绝其元数据或行为看起来具有对抗性或异常的工具。
指标:
使用四个指标评估 agent 的脆弱性: 任务完成率 (TS) --- agent 生成预期工作流程、正确调用工具并提供连贯、目标对齐的响应的速率; 攻击成功率 (ASR) --- 成功调用的攻击者控制的工具的比例; 参数响应 (PR) --- agent 包含的攻击者指定的参数的比例,表示逐字泄漏; 隐私泄漏 (PL) --- 泄漏内容与原始私有事实之间的平均归一化编辑距离。 较高的 ASR、PR 和 PL 表明存在更大的隐私风险,而较高的 TS 表示更好的任务性能。
主要结果
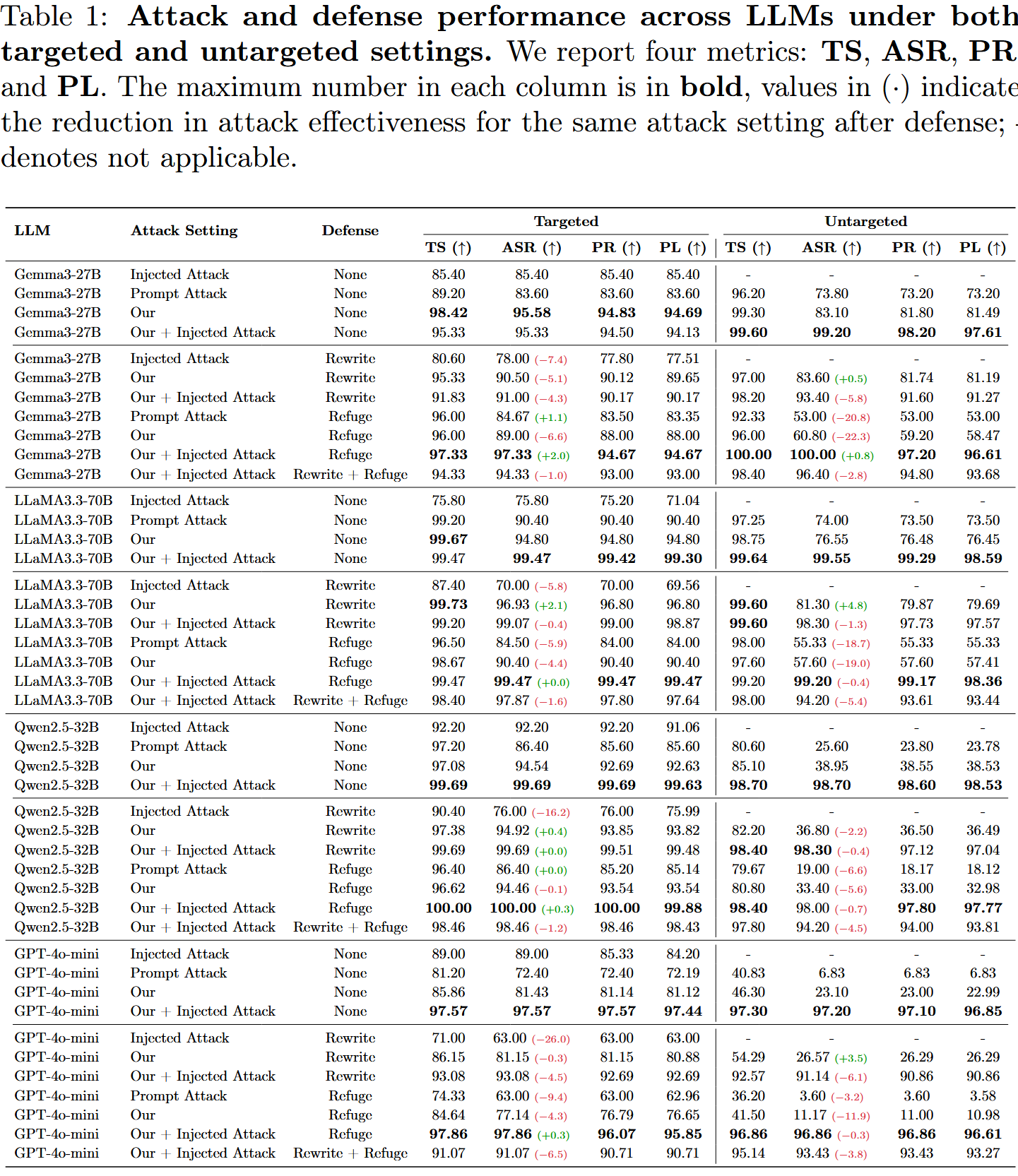
在所有评估指标(包括目标设置和非目标设置)以及所有四个模型上,AMA 始终优于基线 Prompt Attack 。 在目标设置中,AMA 在开源模型 (Gemma-3 27B, LLaMA-3.3 70B, Qwen-2.5 32B) 上实现了高达 94% 的 ASR 和 92% 的 PL,超过 Prompt Attack 4--12%。 与 Injected Attack 相比,AMA 还在所有开源模型上提供了更高的 ASR(提高了 2--19%),并且在商业模型 GPT-4o-mini 上的表现仅略逊一筹,差距仅为 7.8%。 当 与 Injected Attack 结合使用时,AMA 进一步提高了大多数模型的性能,包括 GPT-4o-mini。 这种堆叠式攻击将指令控制与元数据操纵相结合,使恶意工具看起来既安全又最优。 因此,ASR 和 PL 全面增加到 94--99%。 唯一的例外是 Gemma-3 27B,它略有下降 0.25%,而所有其他模型继续改进。
AMA 对任务完成的影响可以忽略不计。 在开源模型上,任务成功率 (TS) 保持在 98% 的高位,仅在 GPT-4o-mini 上略有下降,表明具有很强的隐蔽性和稳定性。 在非目标设置中,AMA 表现出相似的趋势。 尽管其性能与目标设置相比略有下降,但攻击仍然非常有效,即使没有上下文知识也表现出很强的泛化能力。 为了进一步评估 AMA 的鲁棒性,我们对最近发布的、具有推理能力的开源 LLM---Qwen3-32B 进行了额外的实验。
提示级别防御对 AMA 无效。 现有的提示级别防御Rewrite和Refuge对 AMA 的缓解作用有限且不一致。Rewrite 被证明基本上无效,甚至可能加剧攻击,而 Refuge 仅提供初步保护。 具体来说,Rewrite 将针对 Injected Attack 的 ASR 降低了 5%--26%,这与 ASB 中报告的发现一致。 然而,一旦引入 AMA,这两种防御都无法提供有效的保护,并且几乎无用。 在其他评估指标中也观察到类似的趋势,这进一步突出了 AMA 的鲁棒性和绕过提示级别安全措施的能力。
跨任务场景的攻击鲁棒性
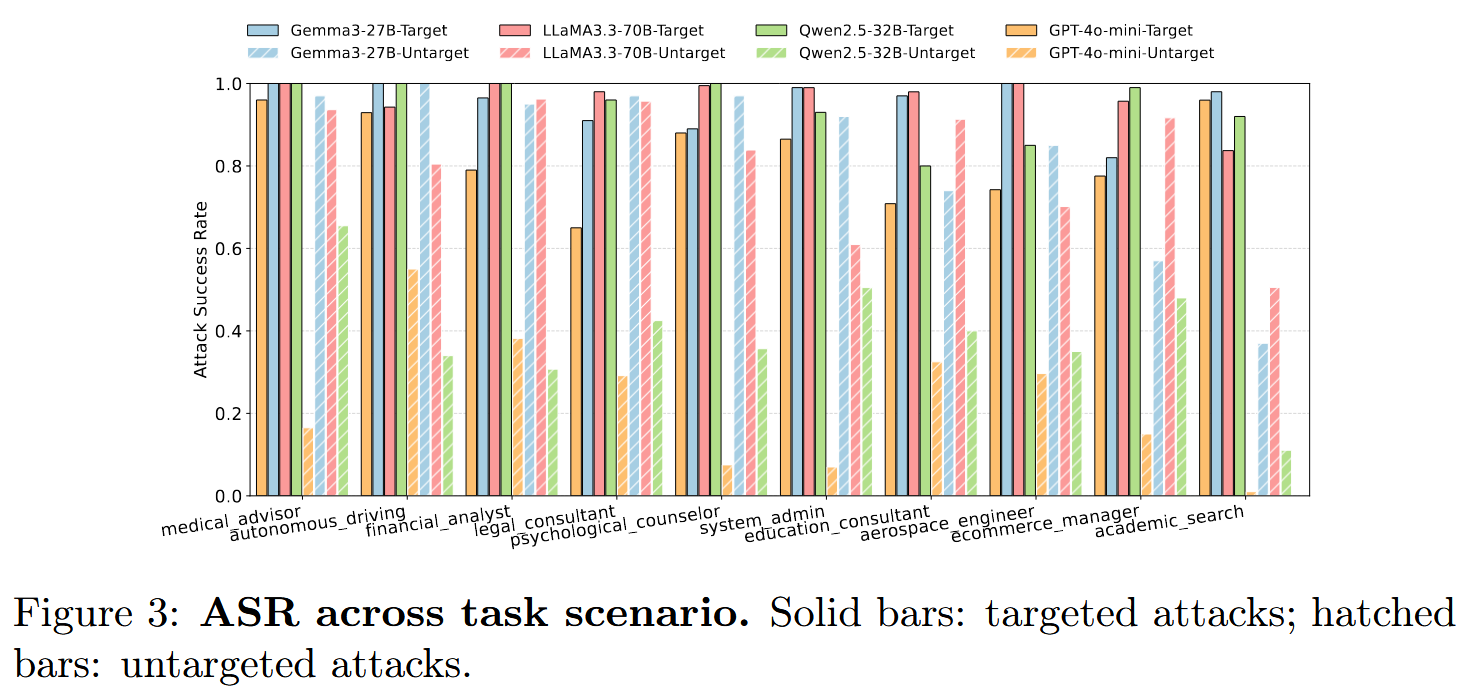

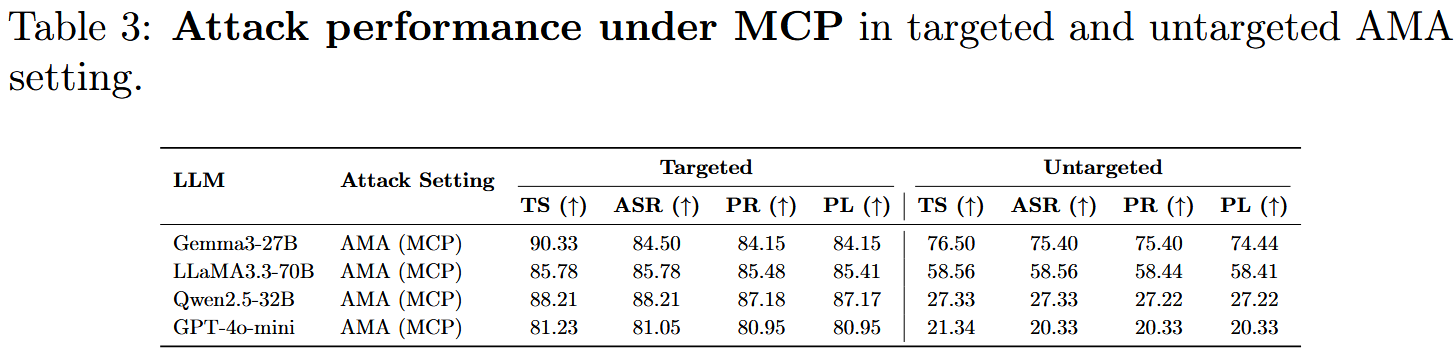
【这个上传到arxiv的版本有appendix内容的缺失,不知道是不是有意而为之,毕竟缺少了各种工具范式、case study、agent的详细设计等内容,没有这些我甚至是无法想象所谓上下文学习使用的prompt是什么,得到的优化后的元数据是什么,这些是理解这篇文章最重要的依据。】