当AI成为文学研究员:Agentic DraCor如何用MCP解锁戏剧数据分析
论文信息
- 原标题:Agentic DraCor and the Art of Docstring Engineering: Evaluating MCP-empowered LLM Usage of the DraCor API
- 主要作者:Peer Trilcke, Ingo Börner, Henny Sluyter-Gäthje, Daniil Skorinkin, Frank Fischer, Carsten Milling
- 研究机构:1University of Potsdam, Germany;2Freie Universität Berlin, Germany
- 引文格式(APA):Trilcke, P., Börner, I., Sluyter-Gäthje, H., Skorinkin, D., Fischer, F., & Milling, C. (2025). Agentic DraCor and the Art of Docstring Engineering: Evaluating MCP-empowered LLM Usage of the DraCor API. Preprint submitted to the 2nd Workshop on Computational Drama Analysis at DraCor Summit 2025, Berlin, Germany.
一段话总结
本文实现并评估了DraCor平台的Model Context Protocol(MCP)服务器,该服务器能让大型语言模型(LLM)自主调用DraCor的API工具进行戏剧数据分析。通过定性实验,研究团队评估了LLM在工具选择、使用正确性、效率和可靠性方面的表现,发现"Docstring Engineering"(文档字符串工程)------即通过精心设计工具文档优化LLM与工具的交互------至关重要。这项研究不仅展示了智能体AI在计算文学研究中的潜力,也为数字人文领域的可靠基础设施建设提供了方向。
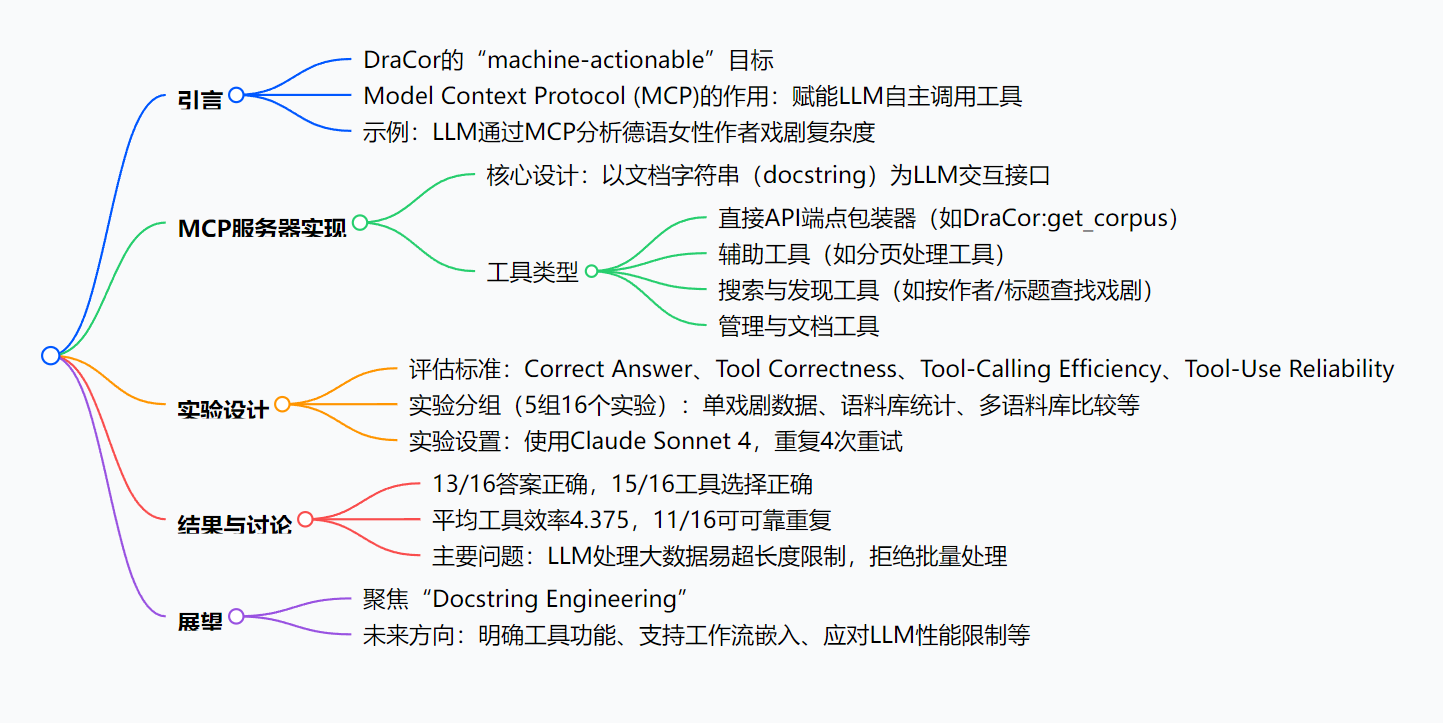
思维导图(核心架构)
研究背景
想象一下,如果你问AI:"10世纪以来,德语女性剧作家写的最复杂的戏剧是哪部?"传统的ChatGPT或Claude可能会根据训练数据中的印象回答,比如提名某部知名作品,但结论可能缺乏实证支持------因为它们没有真正"分析"过戏剧文本的数据。
这正是计算文学研究(Computational Literary Studies)面临的痛点:文学语料库(如戏剧、小说)虽已数字化,但机器难以自主、精准地调用数据进行分析。DraCor(戏剧语料库平台)早就想解决这个问题,它推出了Python(pydracor)和R(rdracor)工具包,让研究者能通过代码调用API分析戏剧数据,但这需要编程能力,且无法让AI自主完成。
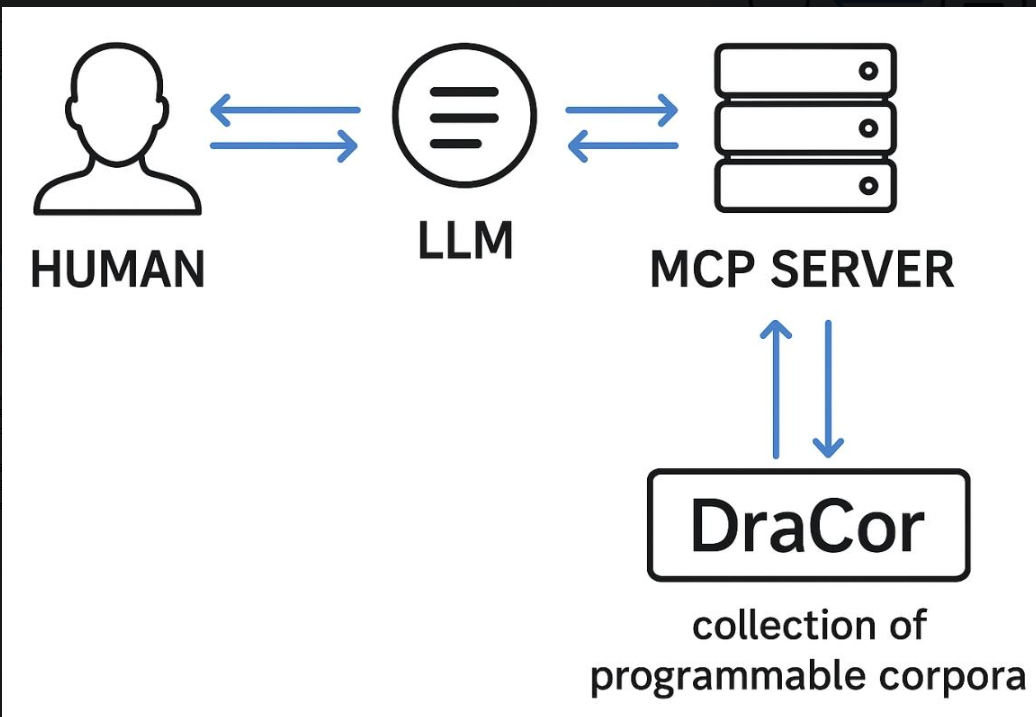
随着"智能体AI"(Agentic AI)的兴起,情况有了转机。Anthropic提出的"模型上下文协议(MCP)"允许LLM通过服务器自主调用"工具"(如API接口),就像人用软件完成任务一样。于是,研究者们想到:给DraCor加一个MCP服务器,让LLM能自己调用工具获取数据、分析问题,不就能让AI成为真正的"文学研究员"吗?
创新点
- 首个计算文学研究的MCP服务器:首次为DraCor实现MCP服务器,让LLM能自主调用其API,填补了AI与文学语料库自主交互的空白。
- 提出"Docstring Engineering"概念:发现工具的文档字符串(docstring)是LLM理解如何使用工具的核心,通过精心设计文档(而非仅优化代码)可显著提升LLM工具调用的准确性。
- 定性评估框架:针对LLM工具使用设计了"工具正确性""调用效率""使用可靠性"三维评估标准,为智能体AI在人文研究中的应用提供了评估范式。
研究方法和思路
1. 实现DraCor MCP服务器
- 技术基础 :基于Python的
fastmcp框架,将DraCor API功能封装为"工具"(每个工具是一个带@mcp.tool()装饰器的函数)。 - 工具分类 :
- 直接API包装器:如
get_play_characters(获取剧本角色),直接对应DraCor API端点。 - 辅助工具:如分页工具
get_corpus_metadata_paged_helper,解决LLM处理大数据时的长度限制。 - 搜索发现工具:如
get_plays_in_corpus_by_author_helper,支持按作者、标题检索剧本。 - 文档工具:如
get_api_feature_list,让LLM了解系统功能。
- 直接API包装器:如
2. 实验设计
- 目标:测试LLM(Claude Sonnet 4)使用工具处理文学研究问题的能力。
- 实验场景:设计16个查询,覆盖4类场景(单剧本、语料库、多语料库、文学概念应用),并通过"术语差异"(如"角色数"vs"dramatis personae")、"DraCor特异性"(如用"GerDraCor"指代德语语料库)等维度变化查询。
- 评估标准 :
- 正确答案:结果是否与人工计算一致。
- 工具正确性:是否选用了合适的工具。
- 调用效率:是否用最短路径完成任务(1-5分,5分为最优)。
- 使用可靠性:5次重复实验中,工具选择和结果的一致性(5/5为最优)。
主要成果和贡献
核心发现(实验结果)
| 评估维度 | 关键结果 |
|---|---|
| 正确答案 | 13/16实验正确,错误多因数据长度限制 |
| 工具正确性 | 15/16实验选用了正确工具 |
| 调用效率 | 均值4.375,8/16实验达最优(5分) |
| 使用可靠性 | 11/16实验结果稳定(≥3/5) |
贡献
- 技术贡献:提供了可复用的MCP服务器实现,代码开源(见下方链接),为其他人文语料库接入智能体AI提供了模板。
- 方法贡献 :证明LLM可通过工具调用实现实证性文学分析(而非依赖训练数据),如通过
get_play_metrics计算角色网络复杂度。 - 概念贡献:提出"Docstring Engineering"------通过优化工具文档(如明确参数、使用场景),可显著提升LLM工具调用的准确性,为智能体AI的工具设计提供了指导原则。
开源资源
- DraCor MCP服务器代码:https://github.com/dracor-org/dracor-mcp
- 实验文档:https://github.com/dracor-org/dracor-mcp-evaluation
关键问题
-
什么是MCP?它如何让LLM与DraCor交互?
MCP(模型上下文协议)是Anthropic提出的协议,允许LLM通过服务器调用"工具"。在DraCor中,MCP服务器将API功能封装为工具,LLM通过阅读工具的docstring自主选择并调用,实现数据获取和分析。
-
为什么Docstring如此重要?
LLM主要通过工具的docstring理解其功能、参数和使用场景。例如,
get_corpus_metadata_paged_helper的docstring明确说明"处理大数据时用此工具分页获取",能引导LLM避开长度限制。 -
LLM在处理文学问题时表现如何?
对简单问题(如"某剧本有多少角色")表现稳定(正确率100%,可靠性5/5);但处理大数据(如"哪个语料库时间跨度最广")时易出错,因受限于LLM的上下文长度。
-
这项研究对文学研究者有何意义?
无需编程能力,研究者可通过自然语言让AI调用工具分析戏剧数据(如角色网络、性别分布),加速实证性文学研究;同时,Docstring设计为工具易用性提供了标准。
总结
本文通过实现DraCor的MCP服务器,首次让LLM能自主调用戏剧语料库API进行分析,并提出"Docstring Engineering"概念优化这一过程。实验表明,LLM在工具使用的正确性和效率上表现良好,但受限于数据处理能力。这项研究不仅为计算文学研究提供了新工具,也为智能体AI在人文领域的可靠应用指明了方向------未来,精心设计的文档可能比复杂的代码更能释放AI的潜力。